 NVIDIA AI Enterprise 提供了簡化端到端人工智能管道的軟件
NVIDIA AI Enterprise 提供了簡化端到端人工智能管道的軟件
隨著人工智能計劃的進展,為企業提供可信、可擴展的支持模型的需求對于確保人工智能項目保持正軌至關重要。為了支持構建人工智能應用程序, NVIDIA AI Enterprise 提供了簡化端到端人工智能管道的軟件,從數據準備到模型訓練,再到模擬和大規模部署。
NVIDIA AI Enterprise 是 NVIDIA 人工智能平臺的軟件層,包括:
優化以在加速的基礎架構上運行,從而實現性能、生產效率和成本節約。
企業級支持、安全性和 API 穩定性。
人工智能工作流程和預先訓練的模型,以加快生產時間。
直接在 Snowflake 數據云上啟用 AI 工作流
數據是生成型人工智能的燃料,而為企業人工智能用例提供燃料的數據就存在于 Snowflake 中。 Snowpark Container Services 現在提供了 NVIDIA AI 平臺,客戶可以在不犧牲安全性、性能或易用性的情況下將數據投入使用。
通過 Snowpark Container Services 使用 NVIDIA AI Enterprise 加速基礎設施和計算庫,開發人員和數據科學家可以輕松構建加速的 AI 工作流程。
使用 Snowpark,企業可以安全地部署和處理用于人工智能和 ML 的 Python 代碼。開發人員還可以擴展加速的 ML 工作負載,并在已存儲數據的地方運行復雜的人工智能模型,如 LLM 。這樣可以減少潛在的安全風險和延遲,特別是當移動大量數據時。
以下工作流程展示了數據科學家如何實現從數據處理到實時推理的每個階段,作為新合作伙伴關系的一部分。本工作流程和示例用例中概述的技術,包括 NVIDIA RAPIDS 、 NVIDIA / Merlin 、 NVIDIA TensorRT 和 NVIDIA SGG2 ,都包含在 NVIDIA AI Enterprise 中,并可在 Snowpark Container Services 上獲得。
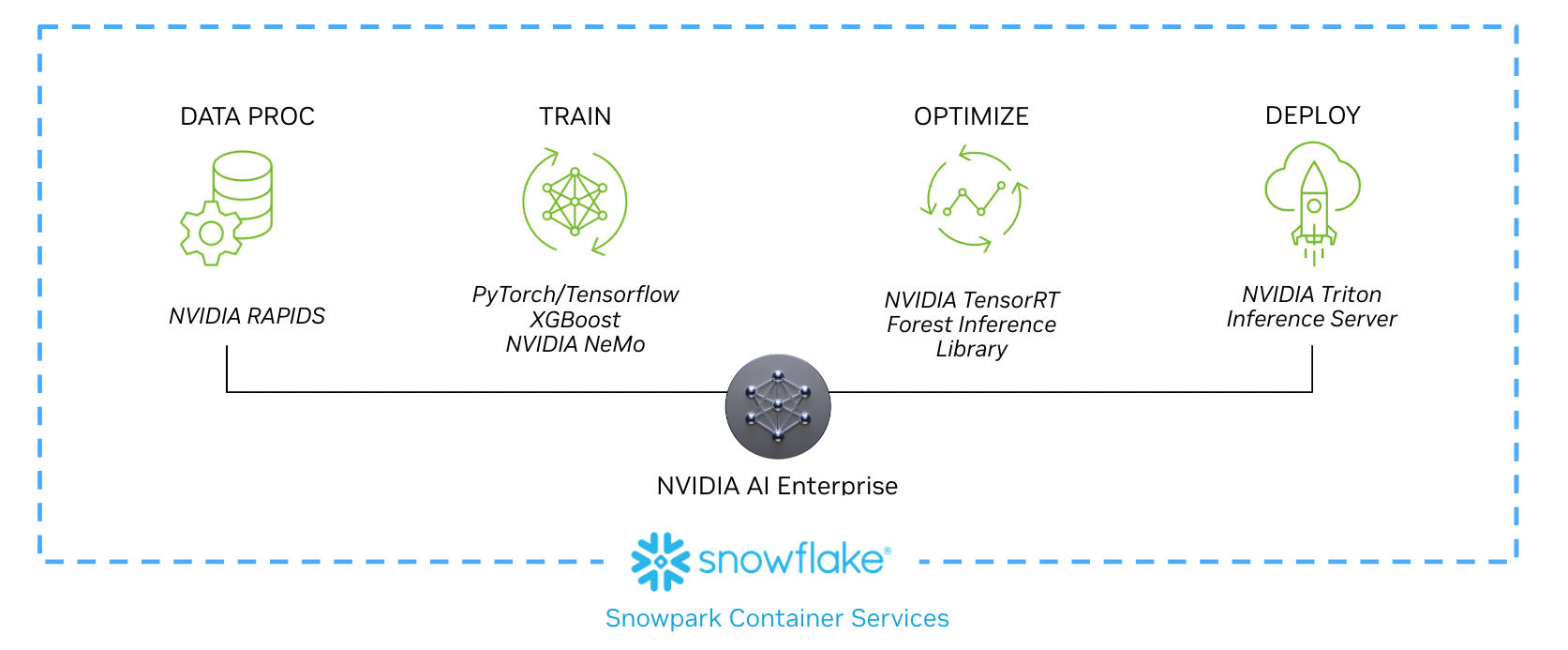
圖 1 。使用 NVIDIA AI Enterprise 從 Snowpark Container Services 中存儲的數據構建 AI 模型的示例工作流
示例用例:訓練推薦模
基于會話的推薦系統在內容豐富的應用程序中變得越來越重要,這些應用程序旨在提供更相關的下一個項目預測。訓練這些模型首先要加載數據,并使用 Snowpark Python 庫進行初始 SQL 和 DataFrame 預處理。
客戶可以在 Snowpark Container Services 中運行的 Jupyter Notebook 中使用 NVIDIA RAPIDS 、 Merlin 和其他人工智能框架來增強數據處理和訓練模型。
NVTabular 是 Merlin 的一部分,是一個加速特征工程庫,旨在生成推薦系統模型訓練所需的關鍵特征。使用 NVTabular 準備數據后, Merlin 中的其他加速計算庫開始訓練人工智能工作流程。
在非常大的數據集上訓練模型的任務可能非常耗時。在訓練過程中,當計算核心處理數據集時,數據集通常會被分塊復制到內存中或從內存中復制出來。使用 GPU 訓練模型可以提供更高的吞吐量和更快的模型訓練,因為它們包括高帶寬內存,并利用越來越多的計算核心進行并行處理。
在 Snowpark 容器服務上運營導致在具有加速計算的預測模型的訓練期間提速20倍。這極大地提高了數據科學家在模型創建過程中的生產力,并通過在更短的時間內完成更多任務來降低總體擁有成本。
訓練完成后,使用樣本測試數據測試模型的準確性。接著,根據需要對模型進行優化和重新訓練。最后,將新訓練的模型發布到注冊表中,例如Snowpark 模型注冊表(私人預覽)。
經過培訓, NVIDIA AI Enterprise 提供了 TensorRT ,用于加速計算的優化。在工作流的最后階段,模型部署并開始執行推理任務。它在 Triton 推理服務器內運行,實時消耗數據并提供見解。
-
NVIDIA
+關注
關注
14文章
5025瀏覽量
103266 -
AI
+關注
關注
87文章
31155瀏覽量
269483 -
人工智能
+關注
關注
1792文章
47442瀏覽量
238996
發布評論請先 登錄
相關推薦
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
了解AI人工智能背后的科學?
AI智能芯片火熱,全芯片產業鏈都積極奔著人工智能去
全語音人工智能AI耳機,或將引爆智能耳機市場
人工智能:超越炒作
人工智能芯片是人工智能發展的
Arm Neoverse NVIDIA Grace CPU 超級芯片:為人工智能的未來設定步伐
《移動終端人工智能技術與應用開發》人工智能的發展與AI技術的進步
《移動終端人工智能技術與應用開發》+理論學習
VMware和Nvidia將聯手加速企業人工智能應用程序的開發
NVIDIA AI Enterprise 2.1版本亮點一覽
使用 NVIDIA AI Enterprise 3.0 優化生產級 AI 的性能和效率





 工商網監
工商網監
評論