") 生成式AI帶火的不止GPU,網(wǎng)絡(luò)芯片迎來下一輪大戰(zhàn)
生成式AI帶火的不止GPU,網(wǎng)絡(luò)芯片迎來下一輪大戰(zhàn)
電子發(fā)燒友網(wǎng)報道(文/周凱揚)在生成式AI的熱度之下,橫向擴展AI訓(xùn)練與推理性能成了每個云服務(wù)廠商、數(shù)據(jù)中心以及互聯(lián)網(wǎng)廠商追求的目標(biāo),這點從前段時間的GPU搶購潮就能看出來,龐大的GPU基數(shù)在當(dāng)下幾乎可以和強大的AI算力畫上等號。
然而,真正將這些GPU連接起來的,還是靠以太網(wǎng)交換機、路由這類網(wǎng)絡(luò)芯片。隨著數(shù)據(jù)中心解耦趨勢愈發(fā)明顯,相繼認識到這一點的網(wǎng)絡(luò)芯片廠商都開始新一輪的軍備競賽,諸如博通、美滿和思科等廠商都已經(jīng)加快了新品推出的節(jié)奏。
博通Tomahawk
作為在數(shù)據(jù)中心網(wǎng)絡(luò)芯片耕耘了12年以上的博通,從640G的Trident系列到25.6T的Tomahawk4系列,已經(jīng)完成了多次設(shè)計迭代,顯著提高了網(wǎng)絡(luò)芯片的帶寬。今年三月,博通終于發(fā)布了Tomahawk 5系列網(wǎng)絡(luò)芯片,也是市面上首個量產(chǎn)51.2Tbps交換帶寬的芯片。
新的Tomahawk 5系列無疑是在暴漲的AI需求下誕生的,我們從其設(shè)計中也能看出。由于做到了更高的端口密度,Tomahawk 5可以實現(xiàn)256高性能AI/ML加速器之間的單跳連接,且每個都能做到200Gbps的網(wǎng)絡(luò)帶寬。這對于數(shù)據(jù)中心的AI訓(xùn)練和推理的負載來說,無疑提高了吞吐效率,尤其是日益流行且愈發(fā)復(fù)雜的生成式AI模型。
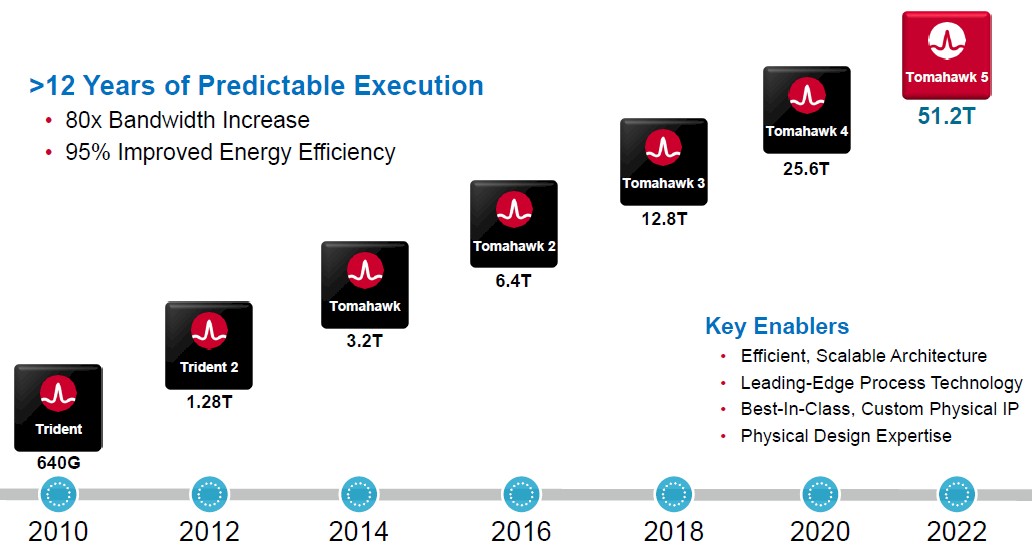
Trident和Tomahawk芯片路線圖 / 博通
在物理設(shè)計上,Tomahawk 5采用了如今已經(jīng)趨近成熟的共封裝光學(xué)(CPO)方案,相較過去的光模塊在前端面板插拔的方案,CPO選擇將網(wǎng)絡(luò)交換芯片和光模塊封裝在一起。這一封裝方案結(jié)合5nm的芯片工藝,將功耗進一步降低了30%。
另外值得一提的是,博通的第三條網(wǎng)絡(luò)芯片產(chǎn)品線,Jericho,也在近期迎來了新品Jericho3-AI。相比以高帶寬為重心的Tomahawk產(chǎn)品線,和主打更多功能性的Trident產(chǎn)品線,Jericho往往以較低帶寬、深度緩存和高可編程性著稱。
而Jericho3-AI雖然確實是28.8T的以太網(wǎng)交換機芯片,卻針對AI訓(xùn)練負載做了特殊的優(yōu)化,更高的端口密度使得Jericho3-AI可以在單個集群中連接32000個GPU,并做到800Gbps的連接帶寬表現(xiàn)。博通甚至將其與英偉達自己的InfiniBand方案對比,Jericho3-AI在完成時間上有著10%左右的優(yōu)勢。這也是Jericho系列獨有的優(yōu)勢,實現(xiàn)標(biāo)準(zhǔn)以太網(wǎng)芯片無法實現(xiàn)卻在AI或HPC應(yīng)用上被看重的靈活功能。
思科Silicon One
其實早在2019年思科首次推出Silicon One網(wǎng)絡(luò)芯片時,博通CEO霍克·譚就表示:“思科在該市場的參與,恰巧驗證了我們推進的這一行業(yè)趨勢,也就是數(shù)據(jù)中心的解耦。我們很高興自己再次押對了,也歡迎更多的競爭。”要知道,之前的思科可是博通的優(yōu)質(zhì)客戶之一,如今身份的轉(zhuǎn)變已經(jīng)對網(wǎng)絡(luò)芯片的市場格局產(chǎn)生了不小的影響。

Silicon One芯片路線圖 / 思科
在第一代自研芯片Silicon One發(fā)布三年半之后,思科在近日終于推出了該產(chǎn)品線的第四代產(chǎn)品,以太網(wǎng)交換機芯片G200和G202。其中G200專注于統(tǒng)一架構(gòu)和基于以太網(wǎng)的AI/ML應(yīng)用部署,這個采用 5nm工藝打造的芯片,基于512個112Gbps SerDes打造,同樣可以做到51.2Tbps的交換帶寬。
而G202則是針對想要繼續(xù)使用50G SerDes的客戶打造的,同樣基于5nm的工藝,G202采用了512x56Gbps SerDes的配置,其特性與G200完全一致,只不過交換性能只有G200的一半。
根據(jù)思科的說法,由于單設(shè)備512個100GE以太網(wǎng)端口的超高端口密度,客戶可以在一個雙層網(wǎng)絡(luò)上構(gòu)建由32000個400G GPU組成的AI/ML集群。借助G200打造這樣一個龐大的網(wǎng)絡(luò),卻依然可以省去50%的光學(xué)組件、40%左右的交換機,極大減少這類集群的碳足跡,每年最高可以省下900萬kWh的耗能。據(jù)了解,G200已經(jīng)送樣給六大云服務(wù)商中的五家進行測試了。
美滿Teralynx
在收購由幾位前博通高管打造的芯片初創(chuàng)公司Innovium后,美滿也開始了他們的網(wǎng)絡(luò)芯片逆襲。同樣是在今年3月,美滿也推出了自己的51.2Tbps交換機芯片,Teralynx 10。相比其他兩家,美滿為Teralynx 10選擇的定位是超低延遲的可編程交換機芯片,這也是此前Innovium的設(shè)計目標(biāo)。
不過直至目前為止,美滿并沒有將Teralynx并入自己的Prestera產(chǎn)品線內(nèi),看來Prestera應(yīng)該還是主打企業(yè)與邊緣數(shù)據(jù)中心市場,而面向云端數(shù)據(jù)中心的Teralynx系列繼續(xù)沿用原來的產(chǎn)品線名稱。
除了用到業(yè)界頂級的112G SerDes IP和先進的工藝實現(xiàn)低功耗的系統(tǒng)設(shè)計以外,美滿電子宣稱Teralynx 10可以提供1.7倍的延遲優(yōu)勢,這對于生成式AI這種看重完成時間和網(wǎng)絡(luò)傳輸時間的應(yīng)用來說至關(guān)重要。
企業(yè)與數(shù)據(jù)中心的交換芯片方案 / 美滿
還有一點與其他兩家不同的是,Teralynx 10可以驅(qū)動128個400Gbps端口、64個800Gbps端口和32個1.6Tbps端口,1.6Tbps的端口驅(qū)動能力可以說是放眼未來了,這也意味著Teralynx 10可以直接在1RU大小的機柜中實現(xiàn)51.2Tbps的性能。
為此,美滿也推出了Nova這一業(yè)界首個做到1.6Tbps的PAM4電光平臺,Nova基于美滿的200Gbps/lambda光DSP打造,足以為1.6Tbps的可插拔光模塊提供支持。由于DSP的帶寬翻倍,基于Nova的光模塊不僅減少了所需激光和相關(guān)光學(xué)組件的數(shù)量,相較其他的方案來說穩(wěn)定性也同樣加倍。雖然800Gbps的光模塊仍在普及中,但要想在下一代數(shù)據(jù)中心交換網(wǎng)絡(luò)中搶占先機,1.6Tbps的光模塊也該盡快提上日程了。
寫在最后
之所以這些廠商都能這么快推出下一代高性能網(wǎng)絡(luò)芯片,其實還是靠EDA/IP和封裝技術(shù)打好了第一波基礎(chǔ),廠商們先一步推出了完善的以太網(wǎng)IP和共封裝光學(xué)方案。不過這也意味著過去數(shù)據(jù)中心交換硬件很可能迎來新一波的換代,從目前來看應(yīng)該是只有大型云服務(wù)廠商有這個資本進行大規(guī)模替換。
但除了這些網(wǎng)絡(luò)芯片公司之間的斗爭之外,他們也需要提防英偉達這樣既有GPU業(yè)務(wù)又有網(wǎng)絡(luò)芯片業(yè)務(wù)的廠商。以上提到的這三家在推出的新品上都有劍指英偉達InfiniBand的意思,畢竟后者從一開始就是為了HPC和AI打造的通信標(biāo)準(zhǔn),而它們則是剛從Web Scaling轉(zhuǎn)向AI Scaling,從外部網(wǎng)絡(luò)交換轉(zhuǎn)為內(nèi)部網(wǎng)絡(luò)交換,仍需要不斷提升產(chǎn)品性能才能在這個競爭激烈的市場上存活下去。
不過這也可以看出AI帶來的熱度,因為無論是從軟件還是從硬件上,產(chǎn)品的迭代速度都有了成倍提升。800GbE時代的到來,也導(dǎo)致所有想在服務(wù)器市場創(chuàng)造增長的廠商紛紛趨之若鶩,好在這樣的趨勢恰恰是服務(wù)器市場急需的一劑強心劑。
-
gpu
+關(guān)注
關(guān)注
28文章
4768瀏覽量
129322 -
AI
+關(guān)注
關(guān)注
87文章
31493瀏覽量
270184 -
生成式AI
+關(guān)注
關(guān)注
0文章
514瀏覽量
536
發(fā)布評論請先 登錄
相關(guān)推薦
生成式AI帶飛,三大存儲產(chǎn)品齊漲價
Lunar Lake大戰(zhàn)Strix Point!AMD、英特爾掀起新一輪AI PC芯片“大躍進”
生成式AI推理技術(shù)、市場與未來

生成式AI工具好用嗎
雷諾下一代車載語音助手Reno將引入生成式AI技術(shù)
榮耀迎來新一輪投資,中國電信、中金資本等加入
生成式AI工具作用
生成式AI與神經(jīng)網(wǎng)絡(luò)模型的區(qū)別和聯(lián)系
亞馬遜云科技攜手SAP通過生成式AI解鎖創(chuàng)新潛力
原來這才是【生成式AI】!!

賽輪思與NVIDIA合作,利用生成式AI打造下一代車內(nèi)體驗
豐田、日產(chǎn)和本田將合作開發(fā)下一代汽車的AI和芯片
生成式AI如何重塑通信業(yè)?愛立信最新嘗試給出了答案
NPU是什么?為何它是開啟終端側(cè)生成式AI的關(guān)鍵?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論