 多方位玩轉“地平線新發布AIoT開發板——旭日X3派(Sunrise X3 Pi)” 插電!開機!輕松秒殺!
多方位玩轉“地平線新發布AIoT開發板——旭日X3派(Sunrise X3 Pi)” 插電!開機!輕松秒殺!
一 整體結構
下面給出了這個開發板的整體的一個接口示意圖,固定孔位、尺寸和整體結構的布局與樹莓派是極為相似的。個人感覺,旭日3派最想拉過來樹莓派用戶,希望吸引更多Jetson Nano用戶。

如何去理解這個開發板,最直觀的比方,可以說是:旭日3派≈樹莓派+神經計算棒。它不像NVIDIA那樣有nvcc來開發CUDA相關程序,沒有那么高的靈活度。但是它相比于樹莓派,多了5TOPS的深度學習計算能力。這對Jetson用戶來說可能有點幼稚,但對樹莓派用戶來說剛剛好(????)。
旭日X3派開發板,為SoC系統級芯片,中心處理器采用的是ARM A53,其他ISP(圖像信號處理器)和BPU(人工智能處理器單元)均為自研,2GB的內存,存儲使用TF卡,其他的一些參數去官網查看具體配置即可。

前面已介紹,該開發板三點大優勢算力/功耗比高、重量輕、價格低。對于算力/功耗比,2.5W的基礎功耗提供了5TOPS的算力,下表給出一些同類型的一些邊緣計算設備的一些配置。值得注意的是,神經計算棒必須搭配其他開發板使用。
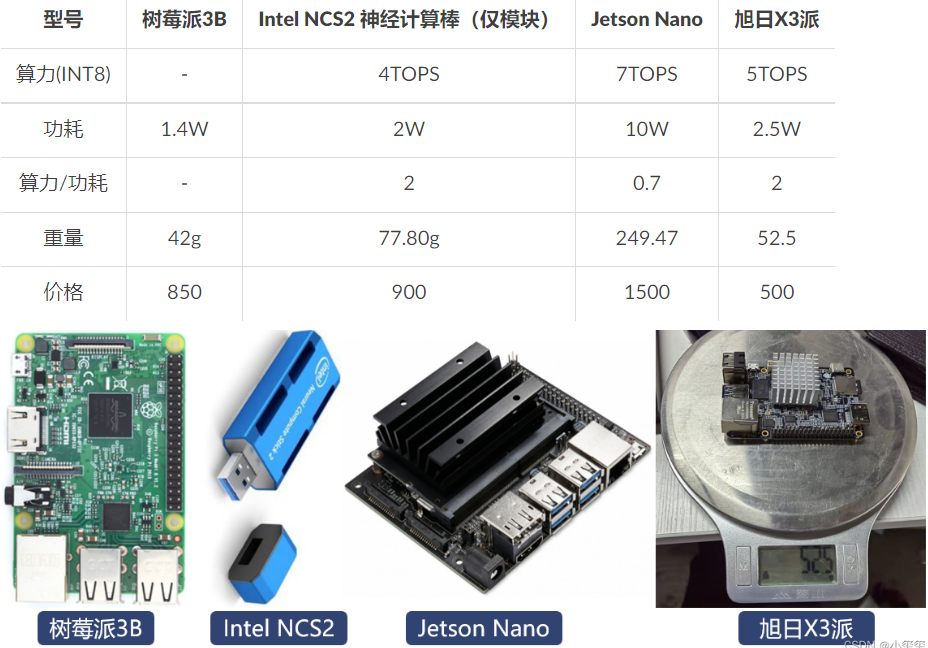
這個表有幾點需要說明下:
- Jetson Nano查不到TOPS數據,考慮到Nano的核心數是NX的1/3,因此根據NX的數據除以3作為Nano的TOPS數據。
- 功耗一般為基礎功耗,非峰值功耗。
- 價格為參考價。
- 具體參數細節以個人使用為主哈,這里只是參考。
在項目應用中,如果其中檢測識別等相關處理算法,對實時要求不高,且對CPU要求不大的話,非常可以試一下旭日開發板。下面給出主要接口的說明:
- Type C電源口:該開發板可接入USB Type C線來供電,實際使用時可使用5V/2A的手機充電頭來用(充電頭功率高點能穩定使用,低功率頭似乎無法提供穩定的5V電壓)。
- TF卡:開發板系統需要從TF卡加載并運行,用戶在使用開發板前,需要先完成TF卡鏡像制作。推薦使用至少8GB容量的TF存儲卡,以便滿足Ubuntu操作系統及相關功能包的安裝要求。
- HDMI接口:這個接口主要用于查看可視化結果,無鼠標,因為系統不具有桌面可視化能力,系統自己開發了個功能,可以通過代碼將圖像數據輸出到HDMI方便查看。
- 串口(用于登錄):接入串口線,即可直接用遠程的方式進行登錄。
- USB2.0/3.0:開發板通過USB Hub、硬件開關電路擴展了多路USB接口,滿足用戶多路USB設備接入的需求。無法確定是否全部來自于一個USB,對于高吞吐量的設備比如Intel Realsense深度相機,可能存在丟幀問題,有待后續適配測試。
- MIPI接口:開發板提供1路MIPI CSI接口,可實現MIPI攝像頭的接入
- 有線網口:千兆以太網接口,需要用命令行配置
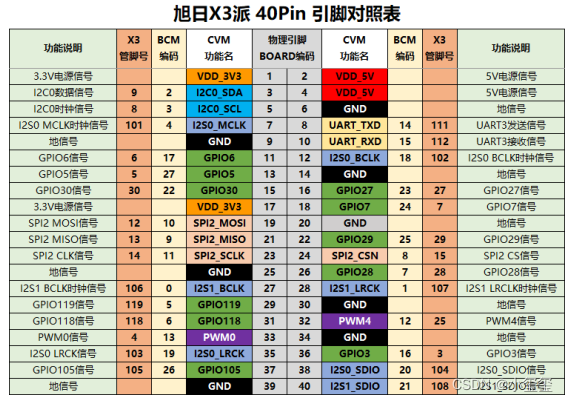
- 40PIN標準接口:開發板提供40PIN標準接口,方便進行外圍擴展,其中數字IO采用3.3V電平設計。40PIN接口定義如下,有相關需求的可以測試一下。
二 啟動系統
下面,將完成系統的配置,完成系統的啟動。
2.1 制作系統鏡像
開發板目前支持Ubuntu 20.04 Server、Desktop兩個版本。注意,由于X3芯片不支持GPU硬件加速,因此使用Ubuntu Desktop版本時,可能會因CPU渲染圖形桌面而造成系統負載過大,如對系統性能有較高要求,推薦使用不帶圖形桌面的Ubuntu Server版本,下面我就帶各位來使用Server版本的系統。
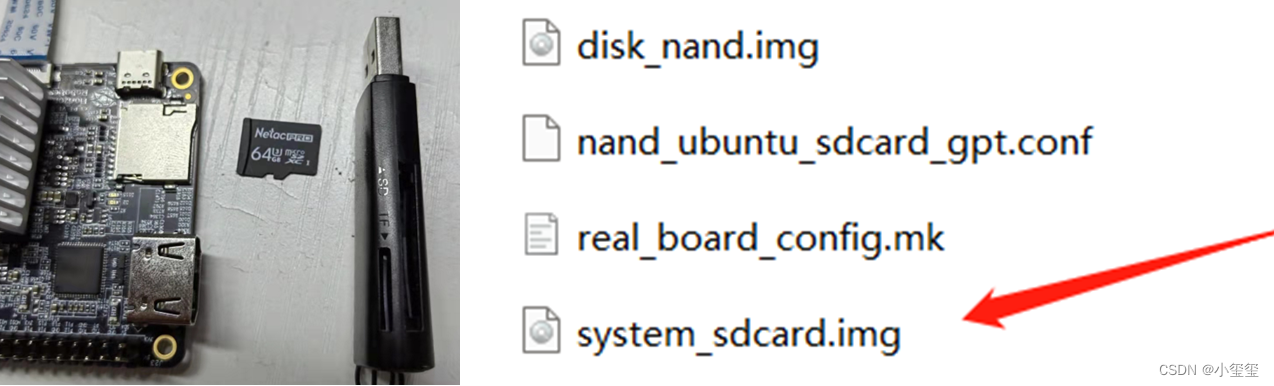
首先,準備好一個TF卡(16G以上),和一個讀卡器,插到自己的筆記本上。我試用時候,提供了一個鏡像包x3pi_ubuntu_disk.tar.gz,解壓它得到一組文件,其中system_sdcard.img就是我們要刷的系統文件鏡像。
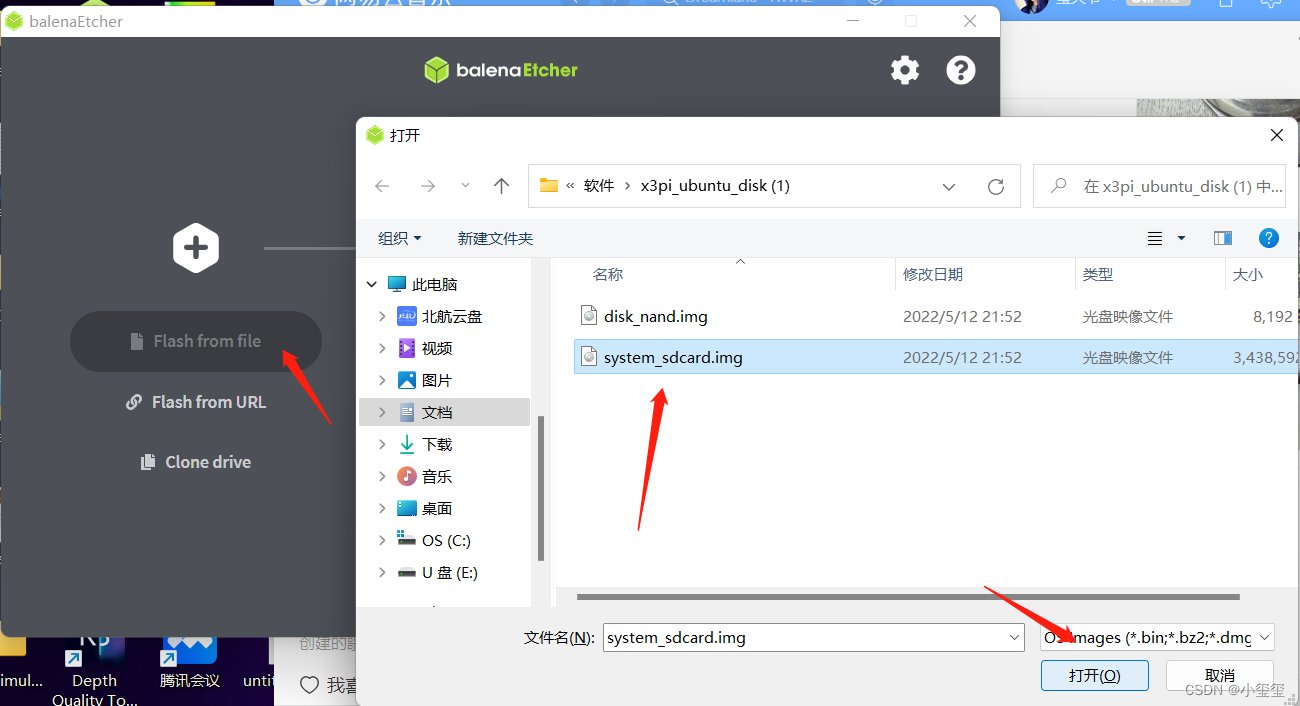
鏡像刷錄我使用的是balenaEtcher工具,它是一款支持Windows/Mac/Linux等多平臺的啟動盤制作工具,下載安裝好就可以進行刷錄啦。
※第一步:選擇鏡像
※第二步:選擇TF卡。
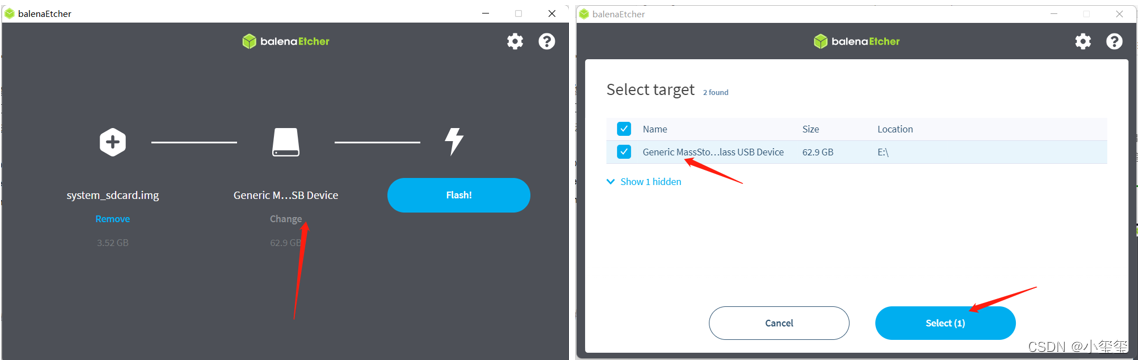
※第三步:刷機!!
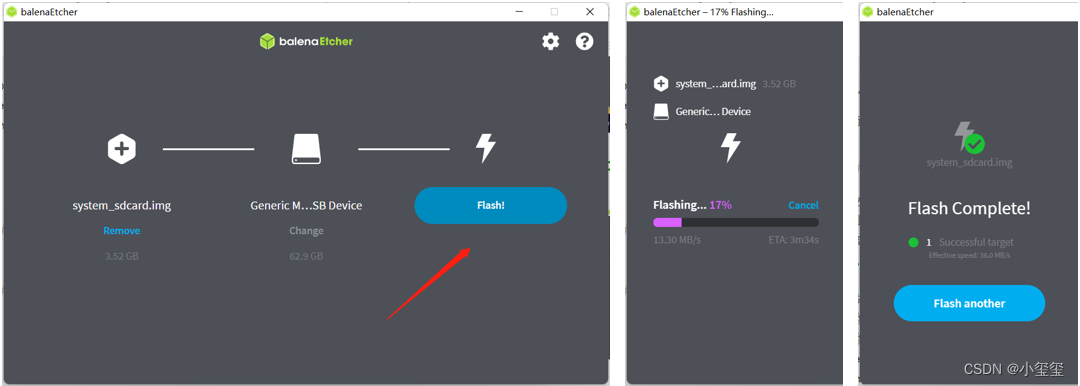
這幾步完成后,我們就完成了刷機工作,相當簡單吧φ(゜▽゜*)?。
2.2 進入系統
刷完系統后,我們就可以把這張TF卡插回開發板里面了。下面,我們要嘗試進入系統。如果是刷機后第一次進入系統,一定要利用開發板自帶的串口連接開發板,配置好網絡后,后續可以不再利用串口登錄(如果網絡IP變了,那就重新用串口連接,查看下IP地址)。
※第零步:基礎準備.
- 將HDMI連接到一個1080P顯示器上(僅用于顯示圖像,無用戶操作)。我在實驗中,使用了一個HDMI采集卡,可通過USB接到筆記本上,利用VLC來查看輸出圖像信息。
- 將MIPI相機連接到開發板上。
- 將串口線的一段插在開發板上。

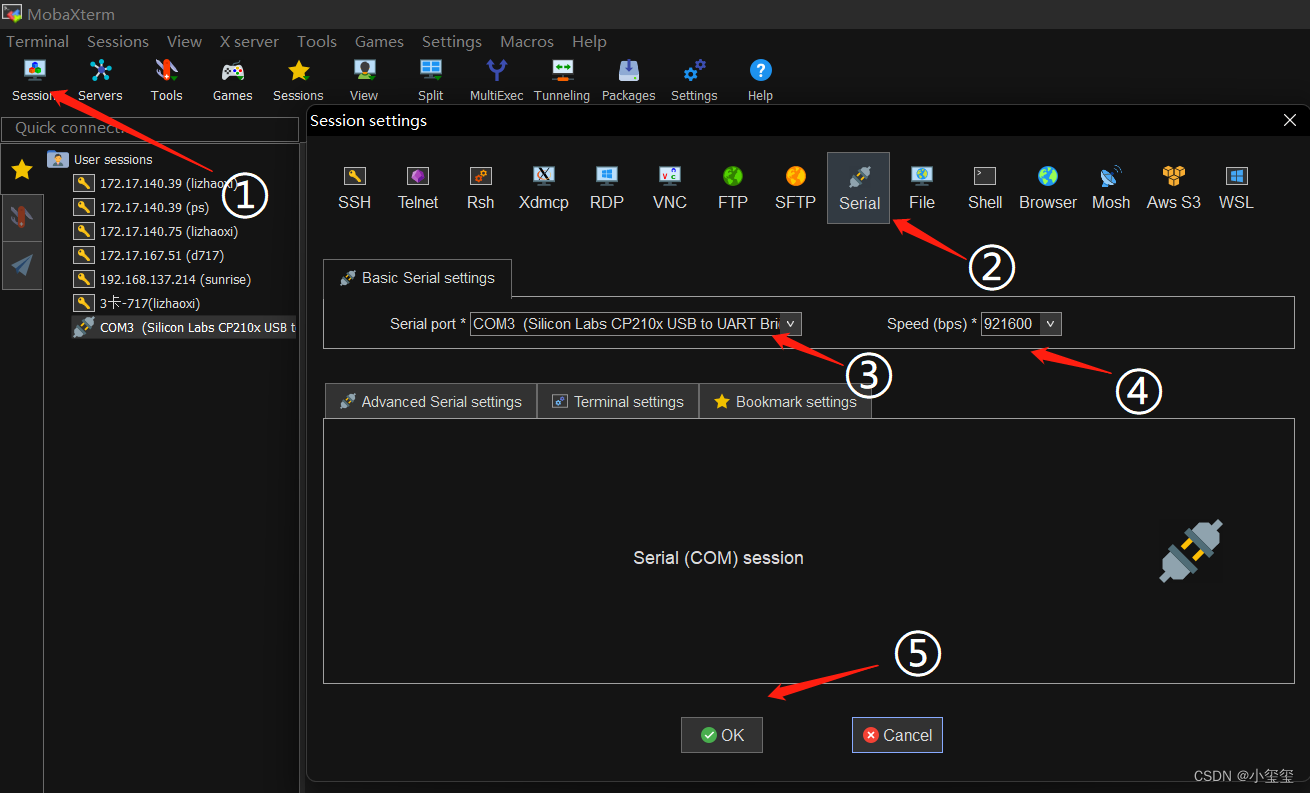
※第一步:串口連接系統
將串口線的另一端連接到筆記本上,看下設備管理器,若提示未知USB設備時,說明PC機未安裝串口驅動,驅動程序可從地平線開發者社區發布頁面https://developer.horizon.ai/resource獲取。驅動安裝完成后,設備管理器可正常識別串口板端口。

使用 MobaXterm 工具按照如下方式進行配置,打開后,由于設備沒插電,所以空白。
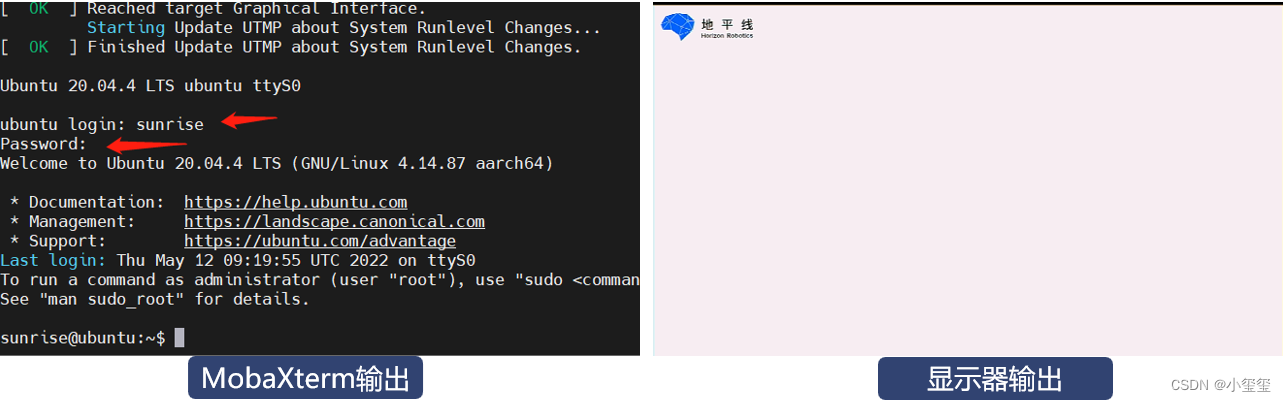
下面,將USB Type C電源線,插入開發板。這時候,控制臺就會輸出一堆文件,到最后,會需要輸入用戶名和密碼,默認賬戶和密碼均為sunrise。如果開發板HDMI正常顯示開機畫面(Server系統顯示地平線logo、Desktop版本顯示系統桌面),說明TF卡系統制作正確。
※第二步:BPU測試
開發板已經連接了一個MIPI相機,下面使用官方示例來測試BPU模塊是否有效。先進入示例程序文件夾cd /app/ai_inference/03_mipi_camera_sample/,然后輸入sudo python3 mipi_camera.py,注意一定要加sudo,調用BPU模塊需要管理員權限。
這時候,控制臺就會輸出一些檢測信息,對應可視化效果由顯示器顯示。
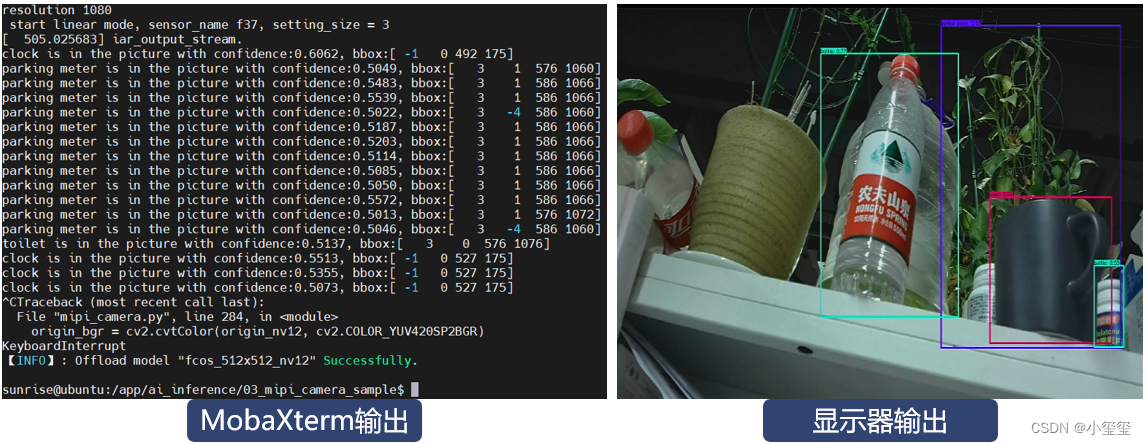
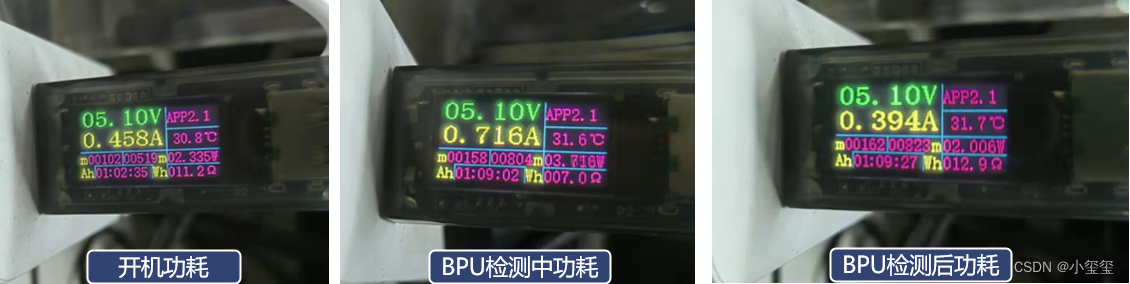
※后話:功耗分析
我分別對開機時,BPU檢測中,和檢測后的功耗進行了分析。開機后的功率在2.3W左右,利用BPU執行了一個檢測示例,功耗升到3.6左右,結束后,功耗降為2.0W,這個原因比較詭異,可能是中止項目后,關閉了顯示輸出使得功耗下降。
至此,開發板啟動起來了,我們happy的進行使用了。

2.3 網絡配置
用串口來操作開發板的話,有幾個致命問題:無法傳文件、命令過長有bug、Vim使用不方便。因此,非常有必要把網絡配置好來進行后續的調試開發。
開發板本身自帶無線模塊,同時也可以插網線以獲得更快的速度。下面給出這兩種模式的一個配置。
2.3.1 以太網配置
① 利用sudo nmcli dev查看網絡設備。輸入ifconfig發現IP地址是192.168.1.10,翻閱手冊發現開發板以太網默認采用靜態IP地址(192.168.1.10),以方便固定網絡環境下的使用,例如開發板與PC機直連場景。但是,對于我來說,我需要動態分配,因為校園網整體就是局域網,不需要網絡環境僅局限在電腦、開發板之間。
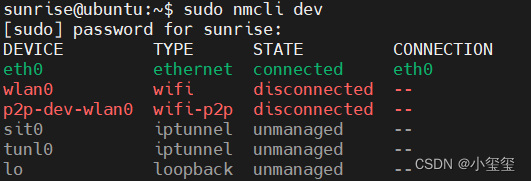
以下的配置,是想讓開發板的IP地址由學校路由器分配得到,不需要靜態IP
② 創建一個新的以太網鏈接
考慮到串口連接,輸入的命令不能過長,則先利用sudo -i切換為root(操作完后利用su sunrise切換回去),然后在命令行中輸入nmcli con add con-name "ethdhcp" type ethernet ifname eth0,這樣可以使用dhcp獲取網絡,其中"ethdhcp"為網絡名,用戶可以自定義。這時候,我們發現,CONNECTION部分已經變了,且IP地址變為自動分配的了。
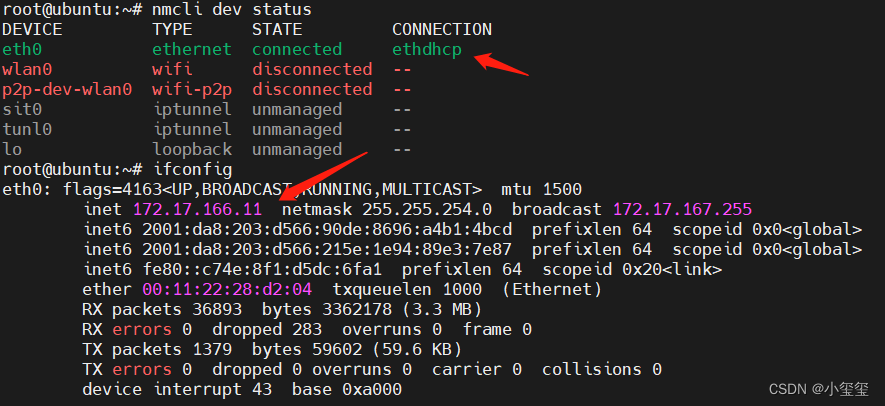
以太網有個大問題,就是連接校園網時候,由于沒有用戶界面,因此賬號的登錄,可能需要利用Python腳本去完成,或者讓校園網插在路由器上完成中轉,如果是個人路由器的話,這種問題一般不存在。
2.3.2 無線網配置
無線網絡的連接參考博客《Linux命令行連接WiFi(全網最簡單的方法)》。
① 利用sudo nmcli radio wifi on開啟wifi。
② 利用sudo nmcli dev wifi掃描wifi。其中,nova 9 Pro 為個人用手機開的熱點
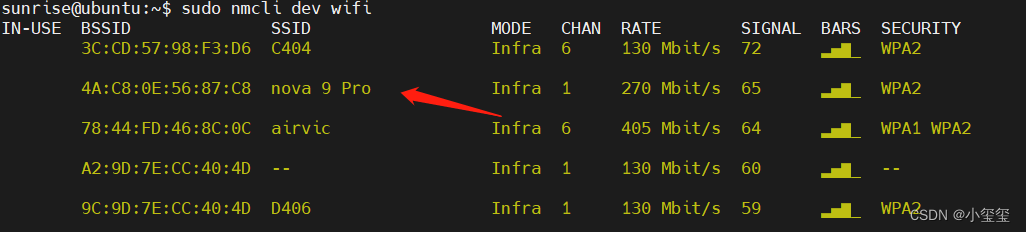
③ 利用sudo nmcli dev wifi connect "wifi名" password "密碼"連接WIFI。將wifi的賬號密碼套在這個命令里,即可成功連接上Wifi。
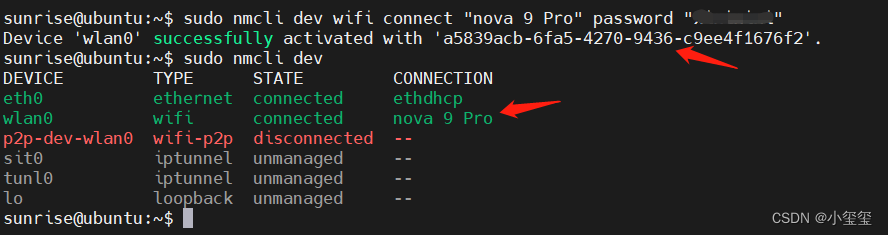
無線網最大的問題就是它的速度真的太慢了,我手上的這個版本速度約為300KB/s,自己外加個天線能夠減低遠程操作的延遲,這個問題已反饋,據說發布后的板子不存在這個問題。
三 CPU項目測試
無論什么開發板,基于CPU相關的程序的穩定性至關重要。因此,非常有必要去測試USB、串口、Wifi等相關的有效性以及穩定性。該部分的測試,一是測試項目的一些基本功能,其次是測試自己做項目中使用的一些算法,來分析整體系統的一個性能。
由于刷機時選擇的是Ubuntu Server,所以帶有界面相關的程序均無法使用。如果想在Server上部署界面端,40PIN接口上有SPI接口,可以購置SPI液晶屏來開發。
3.1 使用注意事項
- 第一次使用記得要sudo apt-get update,默認清華源速度還是可以的。
- VSCode可以使用但不建議(占用600M左右的內存,總共內存在2G)。
- 通過arch指令,可查得當前系統的架構為aarch64。
- 系統自帶了個輕量版OpenCV但不夠用,還是得通過指令sudo apt-get install libopencv-dev安裝個完整的OpenCV。
- 通過指令sudo apt-get install mlocate安裝locate,方便用來查找某些文件的地址。
- 系統默認沒有git,通過sudo apt-get install git來方便下載代碼
- 利用htop可以查看CPU和內存的利用情況
3.2 HDMI可視化圖像數據
由于系統里面并不包含圖形界面,因此如果動態地看算法的檢測效果的話,就需要將圖像數據輸出到HDMI來顯示,系統自帶的python包里面有個類libsrcampy.Display就是來完成這樣的工作的。
為了方便各位后續可視化自己的算法,我將這個功能封裝為一個class

class ImageShow(object):
# 初始化,screen_w和screen_h表示HDMI輸出支持的顯示器分辨率
def __init__(self, screen_w = 1920, screen_h = 1080):
super().__init__()
self.screen_w = screen_w
self.screen_h = screen_h
self.disp = srcampy.Display()
self.disp.display(0, screen_w, screen_h)
# 結束顯示
def close(self):
self.disp.close()
# 顯示圖像,輸入image即可
def show(self, image, wait_time=0):
imgShow = self.putImage(image, self.screen_w, self.screen_h)
imgShow_nv12 = self.bgr2nv12_opencv(imgShow)
self.disp.set_img(imgShow_nv12.tobytes())
# 私有函數,將圖像數據轉換為用于HDMI輸出的數據
@classmethod
def bgr2nv12_opencv(cls, image):
height, width = image.shape[0], image.shape[1]
area = height * width
yuv420p = cv2.cvtColor(image, cv2.COLOR_BGR2YUV_I420).reshape((area * 3 // 2,))
y = yuv420p[:area]
uv_planar = yuv420p[area:].reshape((2, area // 4))
uv_packed = uv_planar.transpose((1, 0)).reshape((area // 2,))
nv12 = np.zeros_like(yuv420p)
nv12[:height * width] = y
nv12[height * width:] = uv_packed
return nv12
# 圖像數據在顯示器最大化居中
@classmethod
def putImage(cls, img, screen_width, screen_height):
if len(img.shape) == 2:
imgT = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
else:
imgT = img
irows, icols = imgT.shape[0:2]
scale_w = screen_width * 1.0/ icols
scale_h = screen_height * 1.0/ irows
final_scale = min([scale_h, scale_w])
final_rows = int(irows * final_scale)
final_cols = int(icols * final_scale)
print(final_rows, final_cols)
imgT = cv2.resize(imgT, (final_cols, final_rows))
diff_rows = screen_height - final_rows
diff_cols = screen_width - final_cols
img_show = np.zeros((screen_height, screen_width, 3), dtype=np.uint8)
img_show[diff_rows//2:(diff_rows//2+final_rows), diff_cols//2:(diff_cols//2+final_cols), :] = imgT
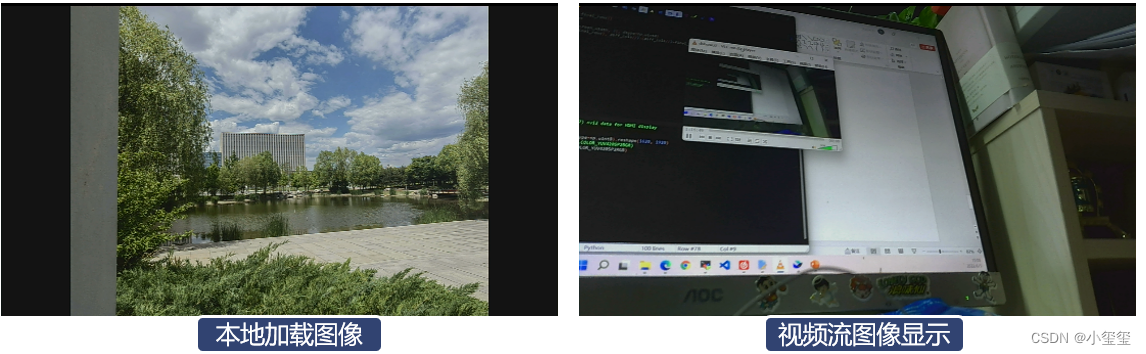
return img_show下面給出視頻和圖像的測試方法,相機用的是MIPI相機
def test_show_image():
img = cv2.imread('00000160.png') # 加載本地圖片
im_show = ImageShow() # 初始化顯示
im_show.show(img) # 顯示圖像
time.sleep(1)
im_show.close()
def test_mipi_camera():
im_show = ImageShow()
cam = srcampy.Camera() # 定義相機類型
cam.open_cam(0, 1, 30, 1920, 1080) # 設置相機采集所用的參數
while True:
origin_image = cam.get_img(2, 1920, 1080) # 獲取相機數據流
origin_nv12 = np.frombuffer(origin_image, dtype=np.uint8).reshape(1620, 1920)
# origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2BGR)
# 圖像雖然是RGB實際上是BGR,問題已反饋
origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2RGB)
im_show.show(origin_bgr)
im_show.close()對這兩個函數分別測試,這時候顯示屏就會出現對應可視化結果,這樣就完成數據可視化所需的一些工作(視頻流圖像顯示這部分,功耗占了1W,CPU占用30%左右,顯示這部分的代碼還是有點冗余)。
3.3 QT項目測試——串口轉Wifi
之前有個項目,要求無人機與地面站直接的通信由之前的數傳改為wifi,搜了一圈,很多都屬于手工調試,而且包含復雜的界面。然而實際需求要求穩定,自動化。因此為了滿足這個需求只能是自己開發一個小工具。該項目的細節部分參考博客串口轉wifi —— 兩個串口之間通過網絡進行通信。
該工具可測試板子的串口模塊和Wifi模塊的穩定性。
① 利用minicom測試串口。第一次使用可利用命令sudo apt-get install minicom安裝相關工具,將開發板的4-5針頭,也就是串口的收發接頭短接。這樣接收到的信息又會發送出去。

② 編譯uart2net工具。按順序執行以下相關代碼:
sudo apt-get install qt5-default
sudo apt-get install libqt5serialport5-dev
git clone https://github.com/Li-Zhaoxi/uart2net
cd uart2net
qmake uart2net.pro
make all -j4③ 配置uart2net.ini文件。注意串口和IP地址的相關配置。
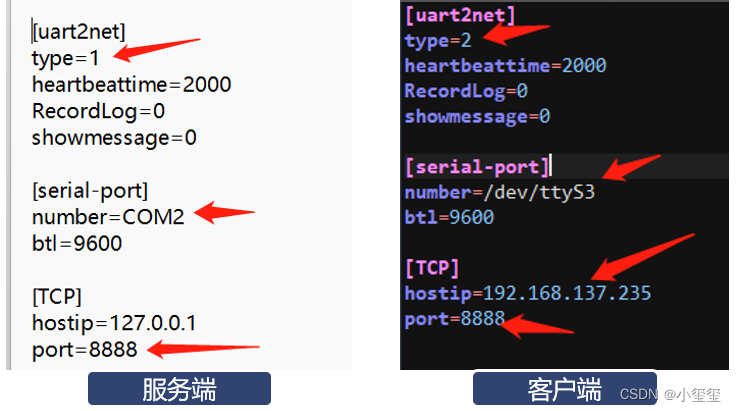
④ 啟動uart2net。
- 服務端為個人筆記本,使用了串口調試助手+虛擬串口模擬串口數據的輸入。
- 客戶端為旭日3派板子,由于/dev/ttyS3收發已短接,因此,接收到什么數據就會發送出去。
最后測試數據的輸出與博客串口轉wifi —— 兩個串口之間通過網絡進行通信是一樣的這里就不再進行敘述了。
測試時候發現個問題,由于Wifi傳輸有一定的延遲,如果每10ms就發送幾十個字節的數據的話,會造成大量數據的阻塞,后續在應用時候注意數據傳輸不要過快,過多,否則會造成幾秒的延遲。
3.4 C++項目測試——圓形結構檢測
部分項目應用中需要檢測場景中的橢圓目標,因此將算法移植到這個板子上,以方便測試檢測效果與實時性,通過命令git clone https://github.com/Li-Zhaoxi/AAMED下載橢圓檢測代碼。
① 編譯python代碼模塊aamed.so。按照下面的方式配置好setup.py文件之后,cd python進入python文件夾,執行python3 setup.py build_ext --inplace編譯算法模塊。需要修改代碼的部分如下所示,直接替換即可。
opencv_include = "/usr/include/opencv4/"
opencv_lib_dirs = "/usr/lib/aarch64-linux-gnu/"
ext_modules = [
Extension(
"pyAAMED",
["../src/adaptApproximateContours.cpp",
"../src/adaptApproxPolyDP.cpp",
"../src/Contours.cpp",
"../src/EllipseNonMaximumSuppression.cpp",
"../src/FLED.cpp",
"../src/FLED_drawAndWriteFunctions.cpp",
"../src/FLED_Initialization.cpp",
"../src/FLED_PrivateFunctions.cpp",
"../src/Group.cpp",
"../src/LinkMatrix.cpp",
"../src/Node_FC.cpp",
"../src/Segmentation.cpp",
"../src/Validation.cpp",
"aamed.pyx"],
include_dirs = [numpy_include,'FLED', opencv_include],
language='c++',
libraries=['opencv_core', 'opencv_highgui', 'opencv_imgproc', 'opencv_imgcodecs', 'opencv_flann'],
library_dirs=[opencv_lib_dirs]
),
]② 調用MIPI攝像頭實現檢測。我在測試時候出現了一個錯誤cannot allocate memory in static TLS block Python,把python頭文件的順序調整了下就OK了。下面給出我的測試代碼。
我在顯示屏上放上了待檢測的照片,讓mipi相機去拍顯示器完成檢測過程
from hobot_vio import libsrcampy as srcampy
import cv2
import numpy as np
import time
from pyAAMED import pyAAMED
# 這里把前面的HDMI可視化部分的代碼貼上
# 復制類class ImageShow(object)
# 檢測主程序
def test_mipi_camera():
im_show = ImageShow()
cam = srcampy.Camera()
cam.open_cam(0, 1, 30, 1920, 1080)
aamed = pyAAMED(550, 970)
aamed.setParameters(3.1415926/3, 3.4,0.77) # 閾值設置,如果假橢圓過多,可適當調高0.77
while True:
origin_image = cam.get_img(2, 1920, 1080)
origin_nv12 = np.frombuffer(origin_image, dtype=np.uint8).reshape(1620, 1920)
origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2RGB)
imgG = cv2.resize(cv2.cvtColor(origin_bgr, cv2.COLOR_BGR2GRAY), (960, 540))
imgGC = cv2.cvtColor(imgG, cv2.COLOR_GRAY2BGR)
t1 = cv2.getTickCount()
res = aamed.run_AAMED(imgG) # 檢測部分代碼
t2 = cv2.getTickCount()
print('time consumption(ms):', (t2 - t1) * 1000 / cv2.getTickFrequency())
for each_elp in res:
cv2.ellipse(imgGC, ((each_elp[1], each_elp[0]), (each_elp[3], each_elp[2]), -each_elp[4]), (0, 0, 255), 2)
im_show.show(imgGC)
im_show.close()
test_mipi_camera()下面是檢測耗時和效果圖,檢測的圖像分辨率為960×540,這個時耗幾乎在37ms左右,也能滿足一些基本的算法需求。
time consumption(ms): 36.989471
time consumption(ms): 37.507962
time consumption(ms): 36.99551
time consumption(ms): 43.346158
time consumption(ms): 37.378966
time consumption(ms): 38.764665
time consumption(ms): 38.915905
time consumption(ms): 25.642136
time consumption(ms): 49.384246
3.5 小結
至此,開發板CPU的部分相關所需功能均已測試完畢,總體來說,基本能滿足大部分輕量型算法的需求,除了Wifi部分延遲較高,其余我覺得均已經足夠適應大部分的任務了。我個人非常喜歡操作HDMI顯示圖像的方式,降低帶有桌面系統帶來的性能損耗,極大的給算法留出更多的計算量。
四 BPU項目測試
開發板中的BPU部分為自研芯片,部分深度學習網絡層從硬件的角度進行了加速。因此,這個開發板核心在于部署。在前文進入系統部分中,通過cd /app/ai_inference/03_mipi_camera_sample/和sudo python3 mipi_camera.py已經展示了系統自帶的檢測效果。
4.1 基本操作
- 查看BPU使用率。?使用sudo watch -n 1 hrut_somstatus命令可以查看當前開發板的bpu使用率,在運行mipi_camera.py的時候,可執行該命令獲得BPU利用情況。
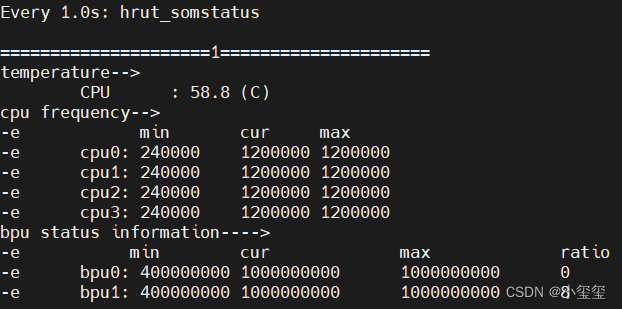
- 查看CPU使用率。盡管hrut_somstatus已經提供了CPU的利用率情況,但我還是覺得htop效果更直觀???。
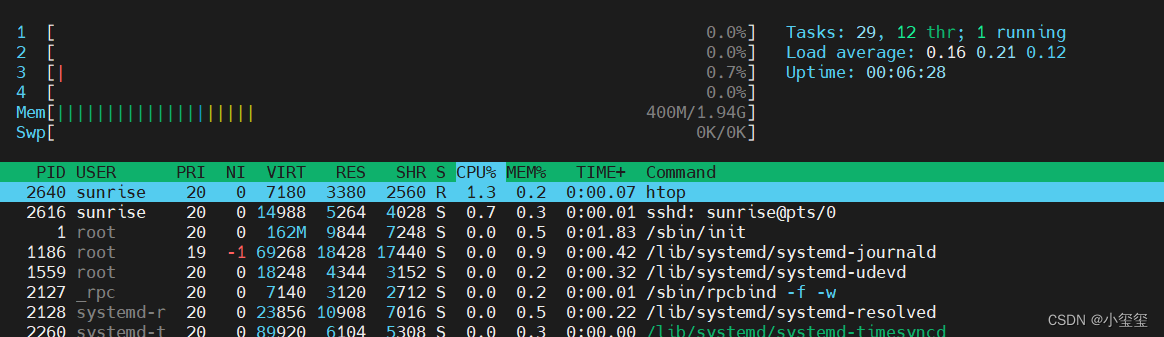
這些操作,主要是用來查看算法的資源占用率的,初級功能。后續非常期待官方出一個類似jetson的jtop工具,jtop的參考鏈接為jetson_stats。
4.2 已有模型測試
由于開發板的特殊性,利用pytorch訓練好的模型,是無法直接用在這個板子上的,官方將一堆常見的模型參數進行了轉換。在裝好的系統中,有兩個可直接使用的模型。fcos用于目標檢測,mobilenetv1用于目標分類。
在開發板的/app/ai_inference/01_basic_sample/路徑下,提供了一個示例test_mobilenetv1.py,下面對其中的主函數部分進行一個介紹,部分核心功能的解釋寫在代碼注釋里面了。這部分通過opencv的cv2.getTickCount()和cv2.getTickFrequency()可測出,耗時約為9ms!!
# 主函數代碼前面還包含如下子函數,用于數據轉換,參數輸出等。
# bgr2nv12_opencv、print_properties、get_hw
if __name__ == '__main__':
# 1. 加載模型,用于BPU加速計算的模型為一個*.bin文件,里面包含了模型的所有信息
models = dnn.load('../models/mobilenetv1_224x224_nv12.bin')
# 2. 輸出模型的Input和output信息
# ========== inputs[0] properties ==========
print("=" * 10, "inputs[0] properties", "=" * 10)
# 輸出模型的輸入信息,輸出信息如下
# tensor type: NV12_SEPARATE
# data type: uint8
# layout: NCHW
# shape: (1, 3, 224, 224)
# inputs[0] name is: data
print_properties(models[0].inputs[0].properties)
print("inputs[0] name is:", models[0].inputs[0].name)
# ========== outputs[0] properties ==========
print("=" * 10, "outputs[0] properties", "=" * 10)
# 這里輸出模型的輸出信息,輸出內容如下:
# tensor type: float32
# data type: float32
# layout: NCHW
# shape: (1, 1000, 1, 1)
# outputs[0] name is: prob
print_properties(models[0].outputs[0].properties)
print("outputs[0] name is:", models[0].outputs[0].name)
# 3. 加載圖像數據,前面已經輸出了模型需要的輸入數據尺寸和數據類型
# 因此,先利用cv2.resize將圖像轉換為目標大小尺寸
# 再利用bgr2nv12_opencv將圖像數據轉為NV12形式(個人理解是壓縮了圖像數據,減少了傳輸時間)。
img_file = cv2.imread('./zebra_cls.jpg')
h, w = get_hw(models[0].inputs[0].properties)
des_dim = (w, h)
resized_data = cv2.resize(img_file, des_dim, interpolation=cv2.INTER_AREA)
nv12_data = bgr2nv12_opencv(resized_data)
# 4. 將圖像的NV12數據傳入模型中,完成了整體的推理過程
outputs = models[0].forward(nv12_data)
# 下面將模型預測信息打印輸出
# ========== Get output[0] numpy data ==========
# output[0] buffer numpy info:
# shape: (1, 1000, 1, 1)
# dtype: float32
# ========== Classification result ==========
# cls id: 340 Confidence: 0.991851
print("=" * 10, "Get output[0] numpy data", "=" * 10)
print("output[0] buffer numpy info: ")
print("shape: ", outputs[0].buffer.shape)
print("dtype: ", outputs[0].buffer.dtype)
# print("First 10 results:", outputs[0].buffer[0][:10])
print("=" * 10, "Classification result", "=" * 10)
assert np.argmax(outputs[0].buffer) == 340
print("cls id: %d Confidence: %f" % (np.argmax(outputs[0].buffer), outputs[0].buffer[0][np.argmax(outputs[0].buffer)]))其實要把模型裝板里,攏共分三步:
- 加載模型。模型格式為*.bin文件,需要利用地平線的天工開物平臺轉換得到。
- 加載圖像數據。圖像的加載利用opencv即可完成。獲取數據之后,轉換為目標尺寸、NV12數據即可直接輸入到加載好的模型中。
- 直接推理。outputs = models[0].forward(nv12_data)即可完成推理,這部分很簡單。
4.3 個人模型部署概述
上面介紹了如何將 大象 模型裝進BPU里→_→, 其實對個人來說,最難的就是如何獲得*.bin文件。這里我其實無法一步步的引導各位如何部署自己的模型,因為這里的部署過程需要利用地平線開發的天工開物工具鏈,部署教程參考文檔:Horizon AI Toolchain User Guide。對我來說,這部分東西太多,學習成本太大了,裝進這個博客里有點太多了(多寫個博客可以白嫖更多瀏覽量 )。
深度學習用的比較多的還是pytorch,模型可以轉換為onnx模型文件,這個模型文件我覺得還是非常通用的,tensorRT和Intel的神經計算棒都利用了這個文件。
模型轉換的目的就是檢查模型文件中的網絡層是否包含在BPU支持的層中(BPU本質上是從硬件的角度加速模型的計算,是一個專用工具),如果某些層不存在,這些層就需要利用CPU完成推理。
實際上,為了保證模型遷移的可靠性,整個上有以下幾個關鍵過程:
① 模型準備。這些模型一般都是基于公開深度學習訓練框架得到的, 需要將模型導出為開發板支持的格式,目前轉換工具支持的深度學習框架如下。Caffe導出的caffemodel是直接支持的(Caffe是基于C++的,代碼相當優美,非常適合硬件轉換); PyTorch、TensorFlow和MXNet是通過轉到ONNX實現間接支持。

② 模型驗證。用來確保提出的算法模型是符合BPU要求的,開發平臺提供了hb_mapper checker來完成模型的檢查。 不滿足遷移的層,就需要手動調整,最簡單的辦法就是這部分轉到CPU來跑(數據傳輸上存在大量時間浪費),因此還是盡可能將這部分轉到BPU上( ,科研和落地還是有很大差距的)。
③ 模型轉換。這個階段會將浮點模型轉為可用BPU使用的模型,利用函數hb_mapper makertbin完成轉換,轉換成功后,得到的模型就可以運行在開發板上了。
模型轉換,不一定就能保證一定就能跑起來,精度和性能都不敢說保證與開發中的結果是一樣的,因此需要進行驗證和調試。NVIDIA其實也有類似的工作,就是tensorRT,加速必有一定程度的損失,這些不可避免,這些其實涉及到數值分析的內容。這部分有需要的話,可以參考模型性能分析與調優和模型精度分析與調優。
原作者:小璽璽
原鏈接:原文詳見地平線開發者社區
-
測試
+關注
關注
8文章
5333瀏覽量
126768 -
嵌入式
+關注
關注
5087文章
19145瀏覽量
306123 -
人工智能
+關注
關注
1792文章
47425瀏覽量
238958
發布評論請先 登錄
相關推薦
Cadence推出Palladium Z3與Protium X3系統
光庭信息獲地平線堅實后盾獎
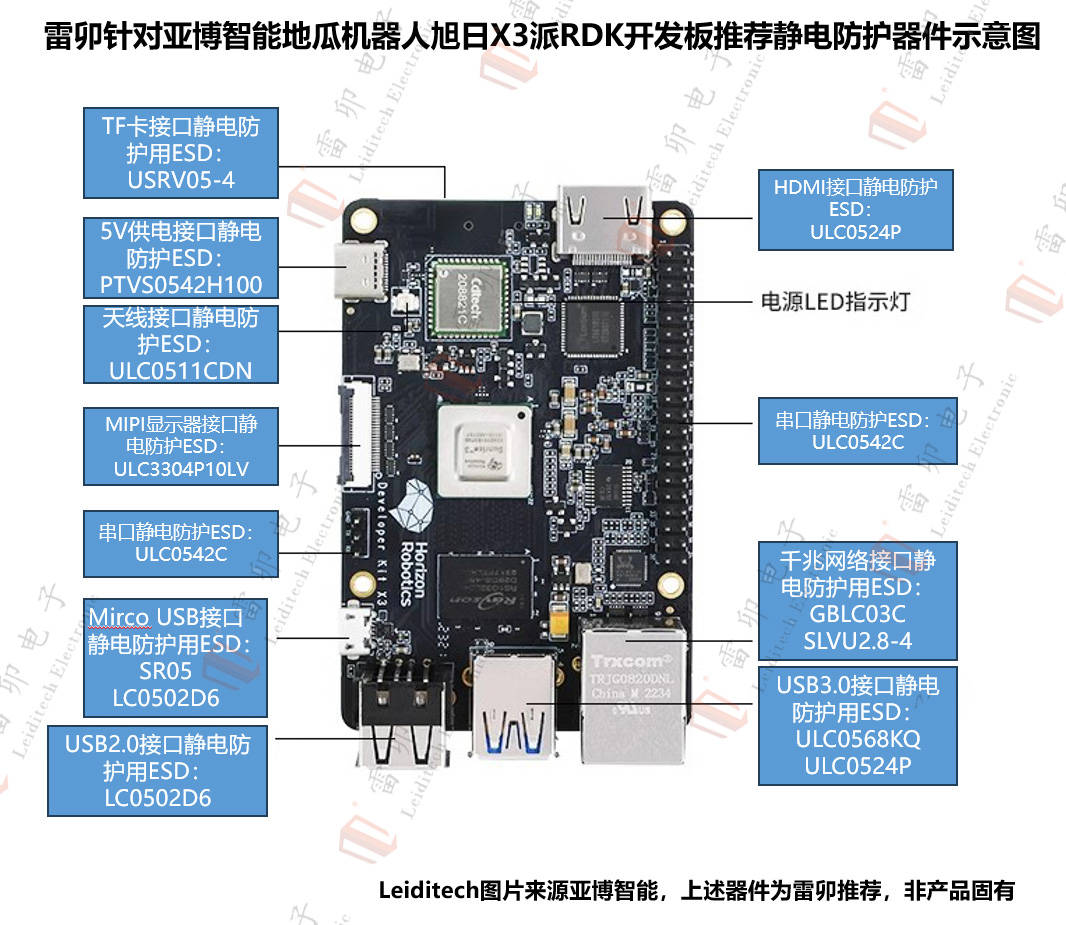
雷卯針對亞博智能旭日X3派RDK開發板開發板推薦靜電防護示意圖
智駕科技企業地平線登陸港交所
Banana Pi BPI-R3路由器開發板運行 OrayOS物聯網系統






 工商網監
工商網監
評論