 為k近鄰機器翻譯領域自適應構建可解釋知識庫
為k近鄰機器翻譯領域自適應構建可解釋知識庫
01
摘要
通過為神經機器翻譯(Neural Machine Translation,NMT)模型配備額外的符號化知識庫(symbolic datastore),k近鄰機器翻譯(k-nearest-neighbor machine translation, kNN-MT)[1] 框架展示了一種全新的領域自適應范式。但是,在構建知識庫時通常需要將平行語料中所有的目標語言詞語都存儲進知識庫,這樣不僅會導致知識庫規模過于龐大,也會導致知識庫中存在大量冗余條目(entry)。為了克服以上問題,本文從“NMT模型需要什么樣的額外知識”這一本質問題出發,對知識庫構建過程的可解釋性展開了深入的研究。最終,我們提出局部準確性(local correctness)這一新概念作為解釋角度,它描述了NMT模型在一個條目及其鄰域空間內的翻譯準確性。從局部準確性出發,我們建立了NMT模型與知識庫之間的聯系,確定了NMT模型容易犯錯并依賴額外知識的情況。基于局部準確性,我們也提出了一種簡單有效的知識庫剪枝方案。在兩個語言對,六個目標領域上的實驗結果表明,根據局部準確性進行知識庫剪枝能夠為kNN-MT系統構建一個更加輕量、可解釋的知識庫。
該工作發表在ACL Findings,由南京大學自然語言處理組獨立完成。
本文的預印本發布在arXiv:https://arxiv.org/pdf/2211.04052.pdf
相關代碼發布在Github:https://github.com/NJUNLP/knn-box
02
NMT模型能力分析
鑒于NMT模型可以不依賴于知識庫完成目標領域的部分翻譯內容,我們推測NMT模型是掌握目標領域的部分雙語知識的。但是,目前的知識庫構建過程卻忽略了這一點,導致知識庫中存儲了冗余知識。直覺上,知識庫中只需要存儲能夠修復NMT模型缺陷的知識。
為了找到NMT模型的潛在缺陷,構建更加可解釋的知識庫,我們提出以局部準確性這一新概念作為分析角度。其中,局部準確性又包含兩個子概念:條目準確性(entry correctness)和鄰域準確性(neighborhood correctness)。基于這些分析工具,我們成功找到了NMT模型的潛在缺陷。以下是對這些概念和分析過程的具體介紹:
條目準確性:NMT模型在目標領域的翻譯能力很難直接描述,但是檢查NMT模型在每一個知識庫條目上的翻譯準確性是相對容易可行的。因此我們首先根據條目準確性,判斷NMT模型的翻譯能力。條目準確性的判定過程是:針對知識庫中的每一個條目,我們檢查NMT模型能否根據隱層表示預測出目標語言詞語。若可以,則判定該條目為NMT模型掌握的知識(known entry);若不可以,則判定該條目為NMT模型沒有掌握的知識(unknown entry)。
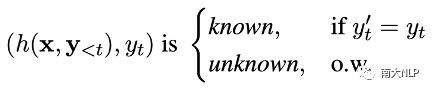
鄰域準確性:但是,我們注意到僅靠條目準確性并不能完全反映NMT模型的全部缺陷。因為即使對于known條目,NMT模型仍然會在面對相似上下文時出現翻譯錯誤。因此,為了更加全面地衡量NMT模型的能力,我們基于條目準確性提出鄰域準確性的概念,它描述了NMT模型在一個鄰域空間內的翻譯準確性。為了量化評估鄰域準確性這一概念,我們進一步提出知識邊界(knowledge margin,km)指標。它的具體定義如下:給定條目(h, y),它的鄰域空間由該位置的k近鄰條目所描述,該位置的知識邊界值km(h)的計算方式為:
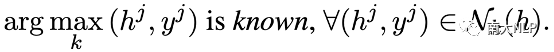
值得注意的是,知識邊界的計算方式可以推廣到表示空間中的任意一點,因此可以被用來考察NMT模型在表示空間中任意一點的能力。
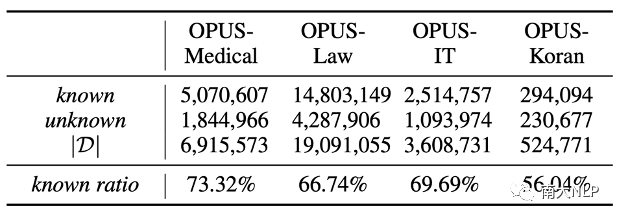
分析實驗:下面我們將基于以上概念,以OPUS數據集為例,分析NMT模型與知識庫之間的關系,揭露NMT模型的潛在缺陷。首先,我們統計了在不同領域知識庫中,known條目和unknown條目的占比情況。統計結果顯示:知識庫中56%-73%的條目都是NMT模型所掌握的(表格1),這也意味著知識庫確實存在極大的冗余。
表格 1 條目準確性統計結果
接著,我們衡量了NMT模型在各知識庫條目上的鄰域準確性,并繪制了知識邊界值分布圖(圖1)。在四個OPUS領域上,知識邊界值的分布情況相似:大多數unknown條目的知識邊界值很低,而known條目的知識邊界值則數值分布差異較大。這說明鄰域準確性與條目準確性總體上是一致的,但是鄰域準確性可以更好地展示known條目之間的差異。
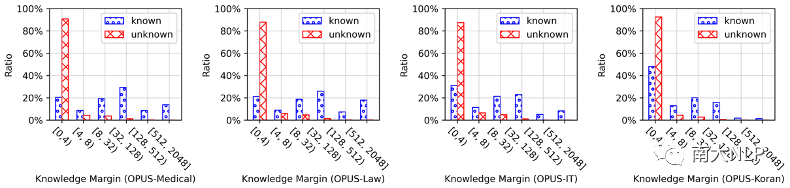
圖 1 知識邊界值分布情況
為了進一步展示知識邊界值與NMT模型翻譯能力之間的聯系,我們在各個領域的驗證集上進行了實驗,展示NMT模型在每一個翻譯步上的翻譯準確率和知識邊界值之間的關系。從圖2中可以看出,對于知識邊界值較大的翻譯步,NMT模型的翻譯準確率高達95%,但是對于知識邊界值較小的翻譯步,NMT模型的翻譯準確率只有50%左右。這說明NMT模型在知識邊界值小時是非常容易出現翻譯錯誤的,這些位置也是NMT模型的缺陷所在。
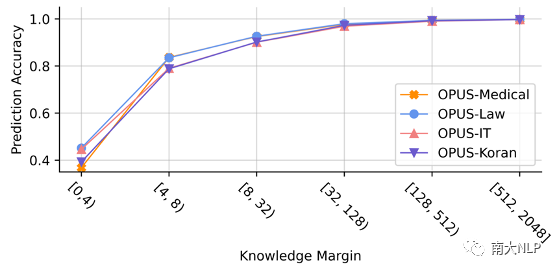
圖 2 翻譯準確率與知識邊界值之間的關系
03
基于局部準確性構建可解釋知識庫
鑒于局部準確性可以準確地反映NMT模型的能力強弱,我們也使用其來衡量知識庫條目對于NMT模型的價值。基于這種價值判斷,我們提出了一種新穎的知識庫剪枝算法PLAC(Pruning with LocAl Correctness)。該算法的核心思路是去除知識庫中知識邊界值大的條目,因為在這些位置NMT模型本身的能力很強,這些位置的知識庫條目對于NMT模型的價值較小。PLAC方法的具體算法流程如圖3。該剪枝算法實現簡單,不需要訓練任何額外神經網絡,剪枝后的知識庫也可以在不同kNN-MT系統中使用。

圖 3 PLAC剪枝算法偽代碼
04
實驗設定
數據集:我們在眾多機器翻譯領域自適應數據集上進行了知識庫剪枝實驗,包括四個德語-英語OPUS數據集 [2] 和兩個中文-英語UM數據集 [3]。各數據集的具體規模如表格2所示。
表格 2 數據集統計信息
NMT模型:在德語-英語實驗中,我們使用WMT19德語-英語新聞翻譯任務的冠軍模型[4]作為預訓練NMT模型。在中文-英語實驗上,我們使用自己在CWMT17中文-英語數據上訓練的NMT模型作為預訓練NMT模型。
05
實驗結果
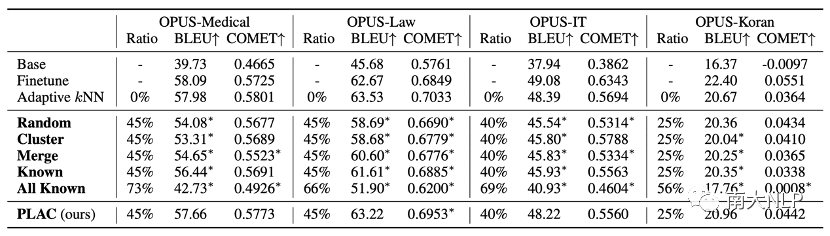
使用PLAC進行知識庫剪枝是安全可靠的:從OPUS數據集上的剪枝實驗結果可以看出(表格3),PLAC可以在保持翻譯性能不變的情況下,去除25%-45%的知識庫條目。尤其是在OPUS-Medical和OPUS-Law這兩個所需知識庫最龐大的領域上,我們的方法成功去除了45%的知識庫條目。出色的剪枝效果說明使用局部準確性確實可以衡量NMT模型的能力以及判斷知識庫條目的價值。
在基線剪枝方法中,Cluster[5]和Merge[6]都造成了巨大的翻譯性能損失,這說明即使一部分條目對應相同的目標語言詞語,這些條目對于NMT模型的價值也是不同的。另外,從Known和All Known兩種方法的結果來看,僅根據條目準確性進行剪枝也會造成性能損失。這說明在判斷條目價值時,綜合考慮條目準確性和鄰域準確性是非常必要的。
表格 3 剪枝實驗結果(OPUS數據集)
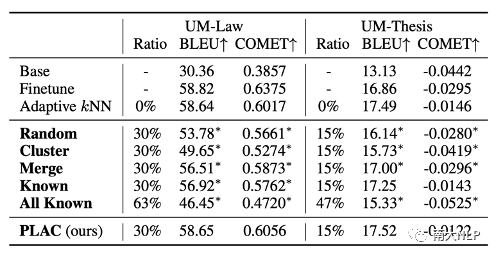
我們也在表格4中報告了UM數據集上的實驗結果。在不損害翻譯性能的情況下,在UM-Law數據集上知識庫規模可以被減少30%,在UM-Thesis數據集上知識庫規模可以被減少15%。其余的實驗結論與OPUS數據集上得出的實驗結論相似。
表格 4 剪枝實驗結果(UM數據集)
知識邊界閾值對剪枝效果的影響:在我們提出的方法中,知識邊界閾值在剪枝過程中起著重要作用。在圖4中,我們進一步展示了該閾值對剪枝效果的影響。我們發現在不同領域上,各剪枝方案的剪枝效果有著相同的變化趨勢:PLAC方法總是比其他剪枝方法有著更好的剪枝效果,并且在高剪枝率時也可以保持更加穩定的性能。從圖中還可以看出,知識邊界閾值的設定對BLEU分數和最大剪枝比例有著直接影響:知識邊界閾值越大,最大剪枝比例越小,翻譯性能損失也越小;知識邊界閾值越小,最大剪枝比例越大,但是可能造成的翻譯性能損失也會增大。
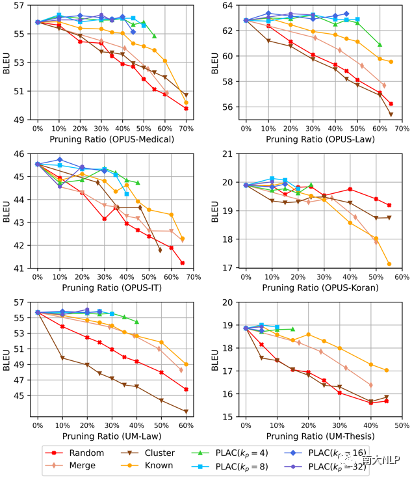
圖 4 不同剪枝方案的剪枝效果對比
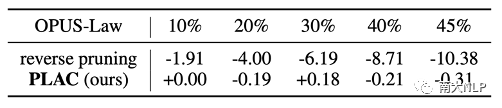
低知識邊界值知識條目十分重要:為了驗證低知識邊界值的條目對NMT模型的價值,我們采用反向剪枝策略:對低知識邊界值進行剪枝。表格5中展示了實驗結果。可以看出,即使在較小的剪枝比例下,反向剪枝策略都會對翻譯性能造成巨大的負面影響,這說明這部分知識庫條目確實對于NMT模型成功進行領域自適應非常重要。
表格 5 正反向剪枝策略的剪枝效果對比
剪枝后的知識庫占據的存儲空間明顯減少:在實際運行kNN-MT系統進行翻譯時,知識庫需要被載入到CPU和GPU上。因此,知識庫的規模將直接影響翻譯效率。表格6中展示了原始的完整知識庫和剪枝過的輕量知識庫之間的大小對比,可以看出我們提出的剪枝方法可以極大地減小知識庫所占用的存儲空間。
表格 6 完整知識庫與輕量知識庫的存儲占用對比

06
總結
在本文中,我們對神經機器翻譯模型和符號化知識庫之間的關系展開研究,提出根據局部準確性和知識邊界指標判斷NMT模型的潛在缺陷,并發現NMT模型在知識邊界值小的情況下常常出現翻譯錯誤。基于以上分析,我們進一步提出了一種安全可靠的知識庫剪枝算法PLAC。實驗結果表明,我們的剪枝算法可以在不損害翻譯性能的情況下,去除最多45%的知識庫條目。出色的剪枝效果也說明局部準確性能夠準確NMT模型的潛在缺陷和知識庫條目的價值。
-
cpu
+關注
關注
68文章
10882瀏覽量
212224 -
模型
+關注
關注
1文章
3268瀏覽量
48926 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14915
原文標題:ACL2023 | 為k近鄰機器翻譯領域自適應構建可解釋知識庫
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
面向對象的汽車制動系專家系統及其知識庫的構建
機器翻譯三大核心技術原理 | AI知識科普
機器翻譯三大核心技術原理 | AI知識科普 2
神經機器翻譯的方法有哪些?
基于知識庫的智能策略翻譯技術
一種基于解釋的知識庫綜合
本體知識庫的模塊與保守擴充
本體知識庫的構建
阿里巴巴機器翻譯在跨境電商場景下的應用和實踐
從冷戰到深度學習,機器翻譯歷史不簡單!
機器翻譯中細粒度領域自適應的數據集和基準實驗
機器翻譯研究進展





 工商網監
工商網監
評論