 能遵循instruction的句向量模型
能遵循instruction的句向量模型
1 簡介
句向量技術是將連續的文本轉化為固定長度的稠密向量,將句子映射到同一個向量空間中,從而應用到各種下游任務,例如分類,聚類,排序,檢索,句子相似度判別,總結等任務,一種優異的句向量技術可以明顯提升諸多下游任務的性能。關于如何利用語言模型輸出文本的句向量,在21年底的時候寫過一篇基于Bert的句向量文章,里面介紹了諸多種基于encoder-only的Bert相關方法Bert系列之句向量生成。
但是之前的句向量技術,泛化能力相對有限,當遷移到新任務或者新領域后,總需要進一步的訓練才能保證效果。最近發現了一種新的句向量技術,在輸入中加入跟任務跟領域相關的instruction,來指導語言模型生成適配下游任務的句向量,而不需要進行額外的訓練,在MTEB榜單的表現可以媲美openai最新的text-embedding-ada-002模型。為了更好地理解Instructor,在這里梳理了Instructor的一個技術演化過程,從Sentence-T5到GTR,再到Instructor,這幾種模型都在MTEB榜單上有不錯的表現,有興趣的讀者可以自行查詢。
2 Sentence-T5?????????
Encoder-decoder結構的T5雖然在seq2seq的任務中表現優異,但是如何從T5中獲取合適的句向量依舊未知。于是就有研究嘗試了幾種從T5中獲取句向量的方式,具體如圖所示,
a)Encoder-only first,利用T5 最后一層encoder第一個token的特征輸出作為句向量。不同于Bert,T5模型沒有CLS 的token。所以拿第一個token的輸出來當句向量看起來就不靠譜。
b)Encoder-only mean,利用T5最后一層encoder所有token的特征輸出平均值作為句向量。
c)Encoder-Decoder first,利用T5最后一層decoder的第一個token的輸出作為句向量。為了獲得這個token的輸出,需要將input文本輸入encoder,還需要將代表start的token喂給decoder。
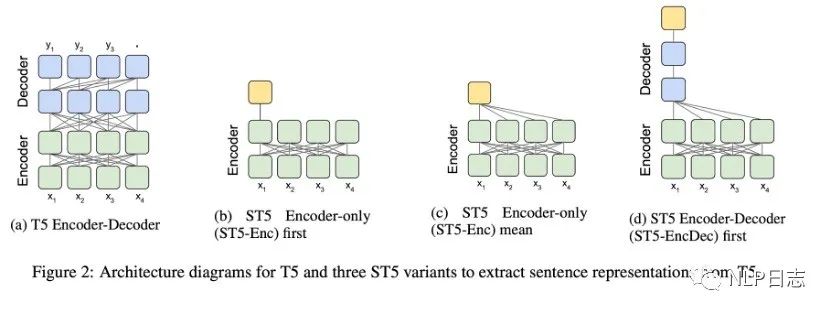
圖2: T5模型結構跟3種句向量變體
利用的前面提及的幾種句向量變種可以獲得固定長度的句子表征,在加上一個全連接層跟Normalization層就可以得到歸一化的句向量。訓練采用的是雙塔模型結構,但是左右兩邊共用同一個模型跟參數。
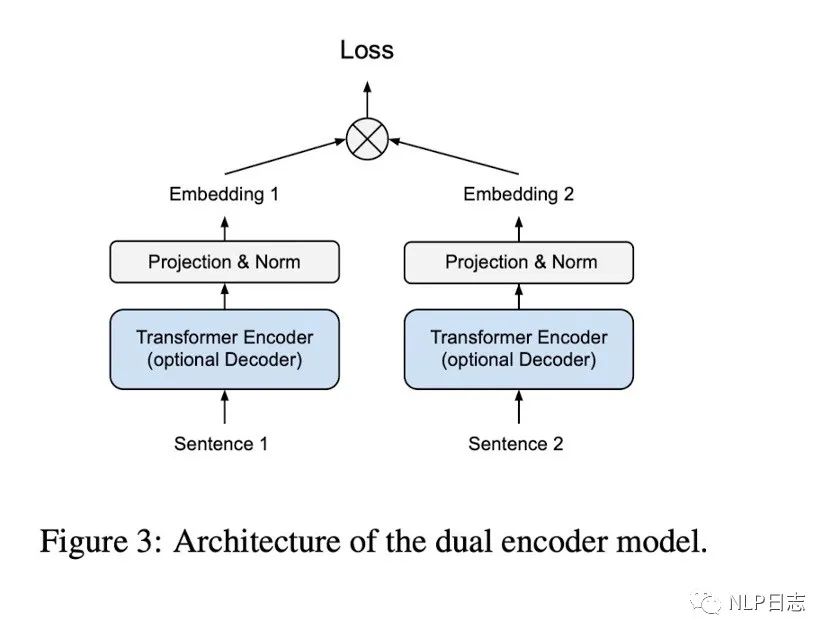
圖3: dual encoder結構
訓練方法采用的是常見的對比學習,同一個batch內,希望同個instance(sentence1, sentence2)的兩個相關句子之間的距離足夠接近(分子部分),不同instance里的不相關句子之間的距離足夠疏遠。如果同個instance還有強不相關的sentence,也希望不相關的句子之間距離足夠疏遠。同時了,為了研究增加額外訓練數據的影響,采用了兩階段的訓練方式,第一個階段現在通用領域的問答數據訓練(Community QA),第二階段才在人工標注的數據(NLI)訓練。
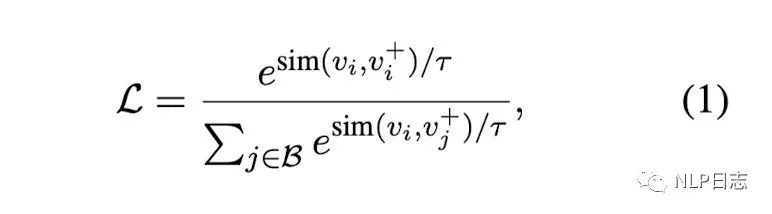
圖4: 損失函數
部分實驗結論
a)T5 Encoder-only mean的效果明顯優于BERT系列,大部分數據集上也優于其余兩種T5句向量變體,在更多數據上finetune能給模型帶來巨大的提升,從而解決模型T5的句向量坍塌問題。(作者猜測encoder-decoder結構里,encoder更傾向于生成通用性的表征,更具泛化能力,而decoder更聚焦于針對下游任務優化。
b)在大部分任務上,增加T5模型的規模可以進一步提升性能。
c)除此之外,還發現了實驗中訓練過程使用了巨大的batch size,第一階段的batch size是2048,第二階段的batch size是512,遠超simcse實驗中的最佳參數配置64。
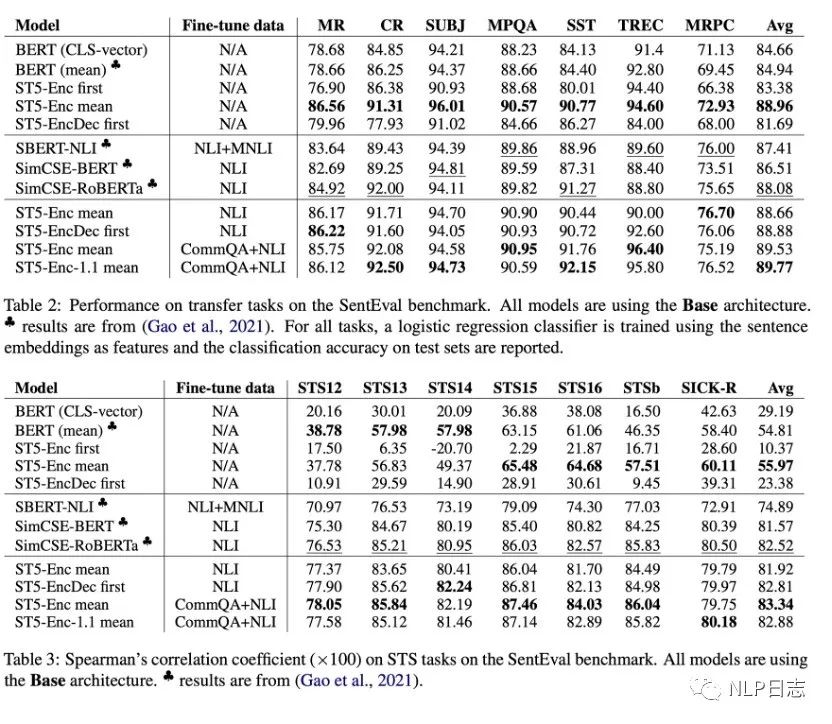
圖5: Sentence T5實驗效果對比
3 GTR????????
還是sentence T5的那批人,發現T5的encoder-only mean產生的句向量效果還不錯后,就繼續在這上面做進一步研究,進一步探索這種句向量模型在檢索任務上的遷移能力。模型沒變,訓練數據把第二階段換成了另外的檢索相關的數據集,MS Macro(Bing的搜索數據)跟Natural Questions(常用于檢索的問答數據集)。
訓練方法雖然還是用的對比學習,但是具體計算過程跟simcse有所差異,由于每一個instance都包含(query, pos, neg),pos跟neg分別是query對應的相關文檔positive跟強不相關文檔hard negative,對應的對比學習的損失由兩部分,
a)同一個instance里的query跟pos是正樣本,query跟同個batch里的所有neg之間都是負樣本。
b)同一個instance里的pos跟query是正樣本,pos跟同個batch里其他instance的query之間都是負樣本。
部分實驗結論
a)隨著模型規模的增加,在領域外的性能提升明顯,換言之,更大的模型具有更強大的泛化能力。同時,也發現GTR對于數據的利用非常高效,在MS Macro數據集上只使用10%的數據也能達到很不錯的效果。
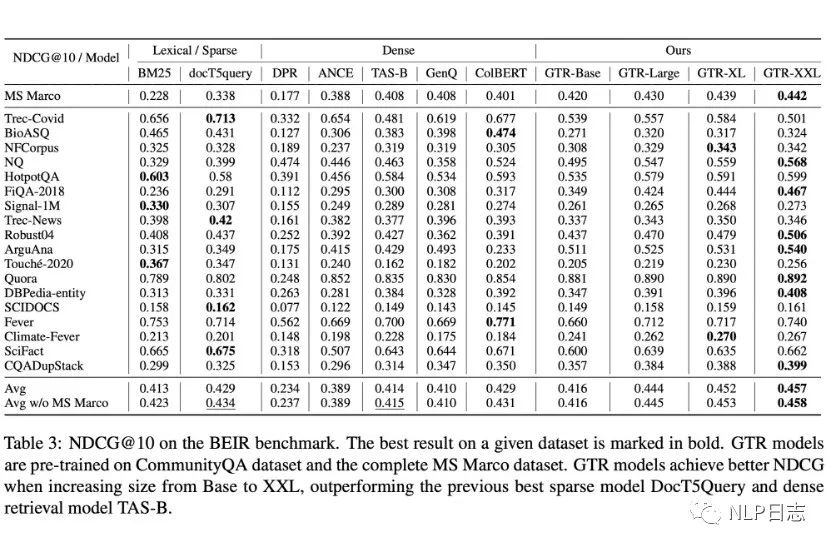
圖6: GTR在BEIR榜的表現
b)做完兩階段訓練的GTR強于只做第一階段或者第二階段訓練的模型,在領域內跟領域外的表現都比較一致,隨著模型規模增加也有一定的提升,同時也說明了第二階段的高質量數據對于模型的幫助。
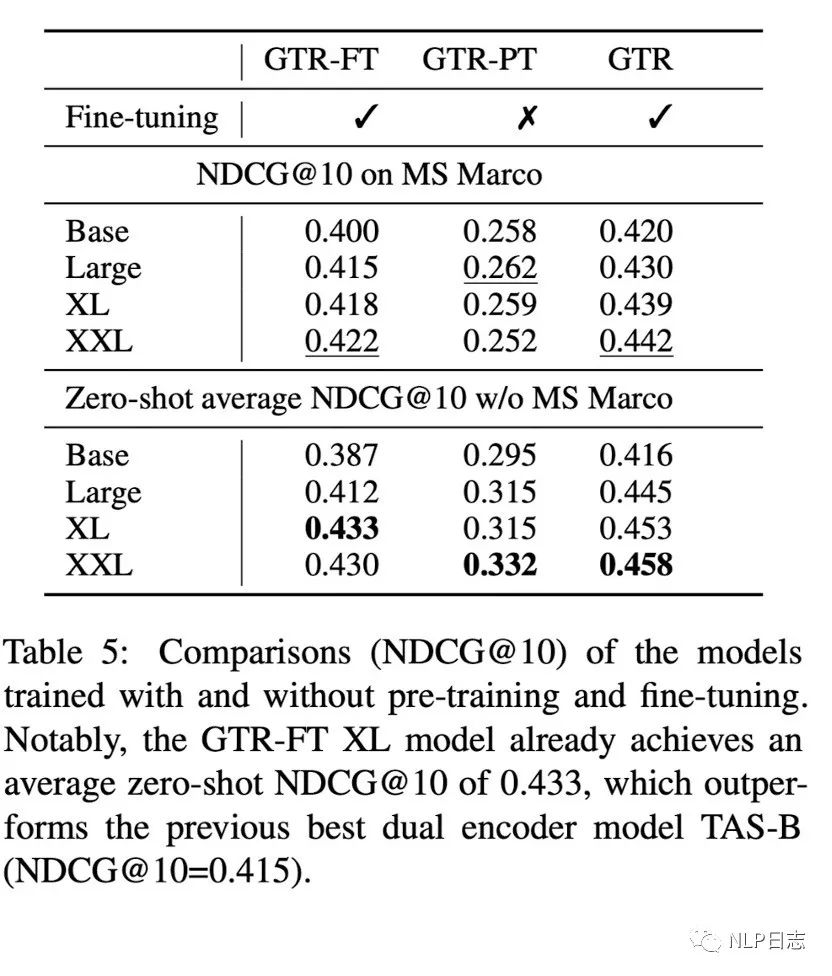
圖7: 不同訓練階段的GTR效果對比(GTR- FT跟GTR- PT分別是只進行第二階段跟第一階段訓練的模型)
c)隨著模型規模的增加,召回的文檔長度也有增加的趨勢。
d)依舊巨大的batch size,兩個階段的訓練batch size都是2048。
4 Instructor?????????
目前的大模型,在給定instruction后會按照指令生成相應的內容,那么對于句向量模型而言,同樣一句話,可以通過給定模型不同的instruction,讓模型生成適合下游任務的句向量嘛?instructor就實現了這個設想。
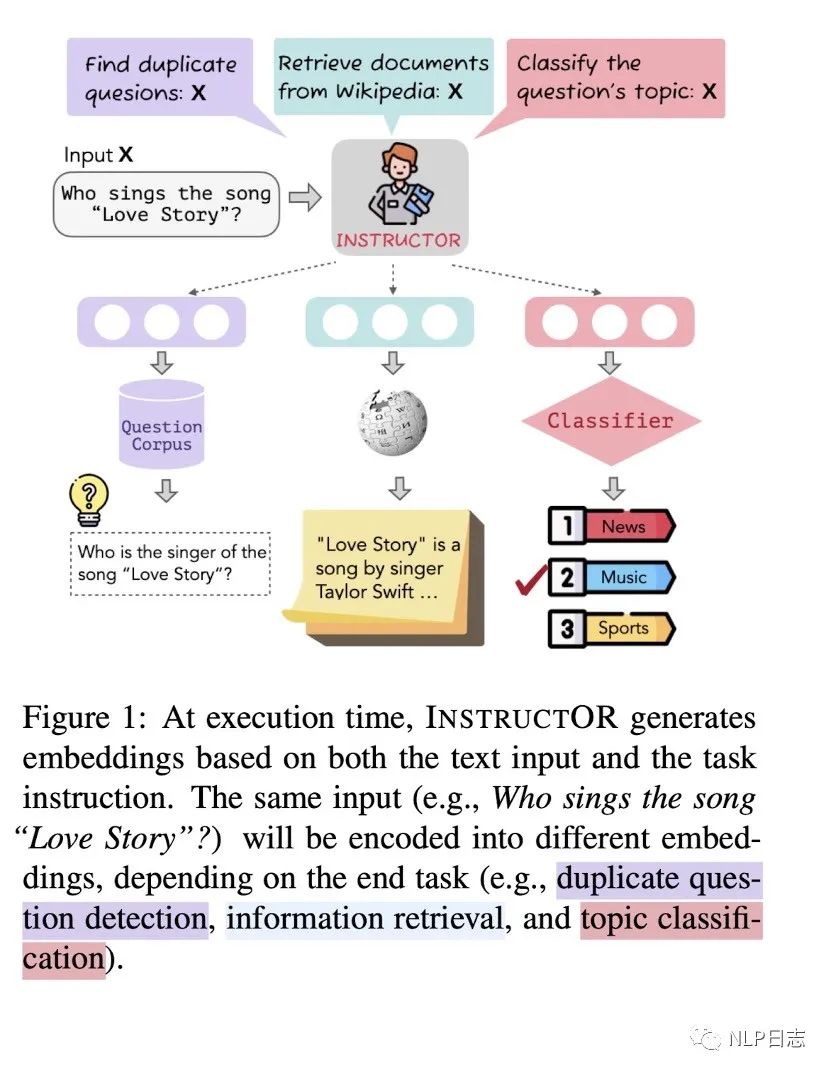
圖8: Instructor
Instructor采用了前面的GTR作為初始模型,訓練方法也依舊保持,只是原本的模型接受文本作為輸入,instructor同時接受instruction跟文本作為輸入,從而生成符合指令的句向量
Instructor的訓練數據是一個數據集集合MEDI,里面包含330個來自SuperNaturalInstructions的數據集跟30個現存的用于句向量訓練的數據集。每個數據集都包括對應的instruction,數據集中的每個instance都是如下格式,
Instance = {“query”: [instruction_1, sentence_1],
“pos”:[instruction_2, sentence_2],
“neg”:[Instruction_2, sentence_3]}
如果是類似句子相似度的對稱類任務,那就只有一個instruction,示例中的instruction_1跟instruction_2就是同一個,如果是類似檢索的非對稱任務,那么query跟doc都各有一個instruction,instruction_1跟instruction_2就是兩個不同的instruction。Sentence_2表示是跟sentence_1相關的文本,而sentence_3則是不相關的文本。
通過這種數據集構造,可以保證每個instance都有自身的hard negative,以及同個batch內其他instance充當簡單負樣本。在訓練過程過程,為了提高難度,會保證同個batch里所有instance都來自于同個數據集。
部分結論如下:
a)Instructor在三個榜單的平均表現最佳,在多個不同任務上的呈現出強大的通用能力。
b)加上instruction的模型訓練,讓模型在對稱類任務跟非對稱類任務上都取得明顯提升。
c)訓練數據加入了330來自SUPERNATURALINSTRUCTION數據集的多個instruction使得模型具備處理不同類型跟風格的instruction的能力,幫助模型更好的能泛化到新領域。同時,instruction的內容越詳細豐富,instructor效果越好。
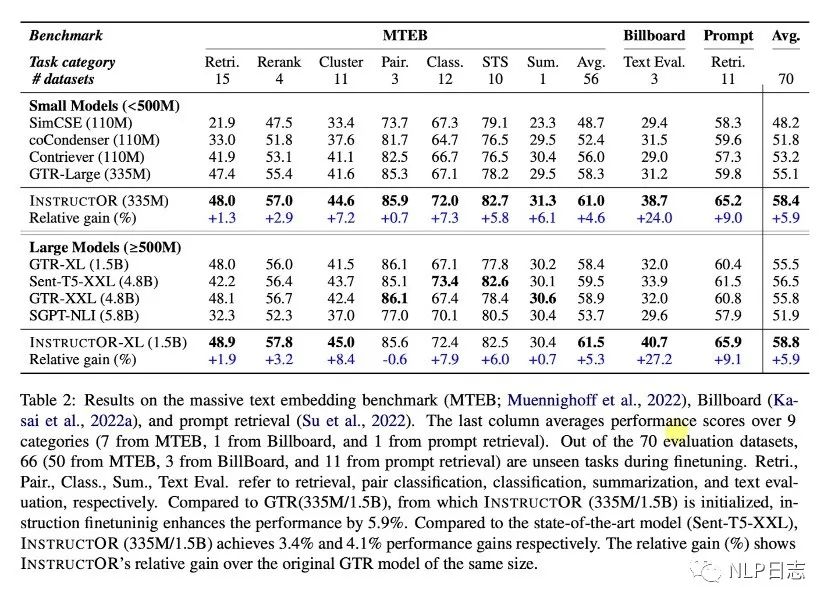
圖9:三個榜單的模型表現比較
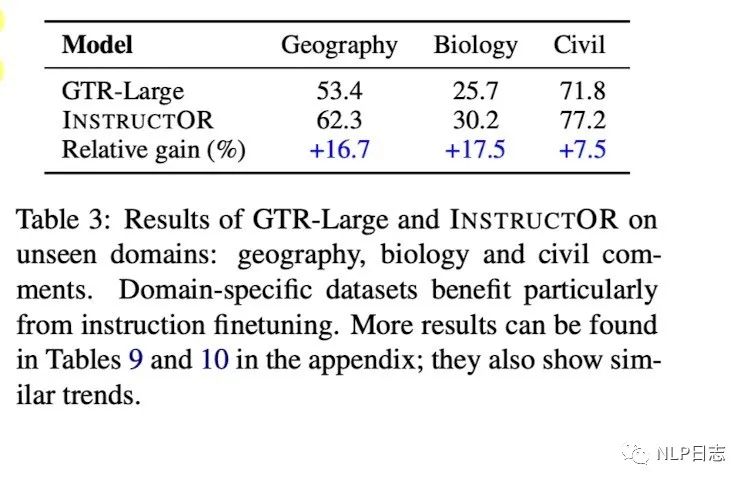
圖10: instructor在新領域的表現
5 總結?????????????
instruction的引入,使得句向量模型能更好地遷移到新的任務跟領域,而不需要額外的訓練。從Instructor的演化進程,不難看出從encoder-deocder模型中選擇Encoder-only mean方法,生成的句向量效果明顯優于Bert系列的方案,猜測這是由于其中的encoder更傾向于生成更通用的特征,而不是針對下游任務。同時也可以看到雖然還是沿用的對比學習方案,但是訓練數據也逐漸從之前的(query,pos)pair對轉換為(query, pos, neg)的三元組,通過設置較大的batch,既能保證訓練難度,也能保證訓練效率。
Instructor看起來還是蠻吸引人的,不由聯想到語言模型的instruction tuning工作,有點異曲同工之意。本文提及的這三種方案是循序漸進的,雖然模型都已經開源,但遺憾的是都不支持中文。最近也看到一個中文的句向量開源方案,采用跟instructor類似的訓練思路。
審核編輯:劉清
-
CLS
+關注
關注
0文章
9瀏覽量
9720 -
GTR
+關注
關注
1文章
19瀏覽量
11158
原文標題:Instructor: 能遵循instruction的句向量模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
介紹支持向量機與決策樹集成等模型的應用
構建詞向量模型相關資料分享
智能N維向量的空間模型
什么是KNI/Instruction Issue/Instr
基于支持向量回歸的交易模型的穩健性策略
支持向量機的故障預測模型
基于支持向量回歸機的三維回歸模型
如何使用智能支持向量機的回歸模型進行金融數據的預測
基于支持向量機的壓力傳感器校正模型
一種緩解負采樣偏差的對比學習句表示框架DCLR
大模型如何快速構建指令遵循數據集?

大模型如何快速構建指令遵循數據集






 工商網監
工商網監
評論