") PyTorch教程-11.4. Bahdanau 注意力機制
PyTorch教程-11.4. Bahdanau 注意力機制
當(dāng)我們在10.7 節(jié)遇到機器翻譯時,我們設(shè)計了一個基于兩個 RNN 的序列到序列 (seq2seq) 學(xué)習(xí)的編碼器-解碼器架構(gòu) ( Sutskever et al. , 2014 )。具體來說,RNN 編碼器將可變長度序列轉(zhuǎn)換為固定形狀的上下文變量。然后,RNN 解碼器根據(jù)生成的標(biāo)記和上下文變量逐個標(biāo)記地生成輸出(目標(biāo))序列標(biāo)記。
回想一下我們在下面重印的圖 10.7.2 (圖 11.4.1)以及一些額外的細(xì)節(jié)。通常,在 RNN 中,有關(guān)源序列的所有相關(guān)信息都由編碼器轉(zhuǎn)換為某種內(nèi)部固定維狀態(tài)表示。正是這種狀態(tài)被解碼器用作生成翻譯序列的完整和唯一的信息源。換句話說,seq2seq 機制將中間狀態(tài)視為可能作為輸入的任何字符串的充分統(tǒng)計。

圖 11.4.1序列到序列模型。編碼器生成的狀態(tài)是編碼器和解碼器之間唯一共享的信息。
雖然這對于短序列來說是相當(dāng)合理的,但很明顯這對于長序列來說是不可行的,比如一本書的章節(jié),甚至只是一個很長的句子。畢竟,一段時間后,中間表示中將根本沒有足夠的“空間”來存儲源序列中所有重要的內(nèi)容。因此,解碼器將無法翻譯又長又復(fù)雜的句子。第一個遇到的人是 格雷夫斯 ( 2013 )當(dāng)他們試圖設(shè)計一個 RNN 來生成手寫文本時。由于源文本具有任意長度,他們設(shè)計了一個可區(qū)分的注意力模型來將文本字符與更長的筆跡對齊,其中對齊僅在一個方向上移動。這反過來又利用了語音識別中的解碼算法,例如隱馬爾可夫模型 (Rabiner 和 Juang,1993 年)。
受到學(xué)??習(xí)對齊的想法的啟發(fā), Bahdanau等人。( 2014 )提出了一種沒有單向?qū)R限制的可區(qū)分注意力模型。在預(yù)測標(biāo)記時,如果并非所有輸入標(biāo)記都相關(guān),則模型僅對齊(或關(guān)注)輸入序列中被認(rèn)為與當(dāng)前預(yù)測相關(guān)的部分。然后,這用于在生成下一個令牌之前更新當(dāng)前狀態(tài)。雖然在其描述中相當(dāng)無傷大雅,但這種Bahdanau 注意力機制可以說已經(jīng)成為過去十年深度學(xué)習(xí)中最有影響力的想法之一,并催生了 Transformers (Vaswani等人,2017 年)以及許多相關(guān)的新架構(gòu)。
import torch from torch import nn from d2l import torch as d2l
from mxnet import init, np, npx from mxnet.gluon import nn, rnn from d2l import mxnet as d2l npx.set_np()
import jax from flax import linen as nn from jax import numpy as jnp from d2l import jax as d2l
import tensorflow as tf from d2l import tensorflow as d2l
11.4.1。模型
我們遵循第 10.7 節(jié)的 seq2seq 架構(gòu)引入的符號 ,特別是(10.7.3)。關(guān)鍵思想是,而不是保持狀態(tài),即上下文變量c將源句子總結(jié)為固定的,我們動態(tài)更新它,作為原始文本(編碼器隱藏狀態(tài))的函數(shù)ht) 和已經(jīng)生成的文本(解碼器隱藏狀態(tài)st′?1). 這產(chǎn)生 ct′, 在任何解碼時間步后更新 t′. 假設(shè)輸入序列的長度T. 在這種情況下,上下文變量是注意力池的輸出:
(11.4.1)ct′=∑t=1Tα(st′?1,ht)ht.
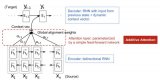
我們用了st′?1作為查詢,和 ht作為鍵和值。注意 ct′然后用于生成狀態(tài) st′并生成一個新令牌(參見 (10.7.3))。特別是注意力權(quán)重 α使用由 ( 11.3.7 )定義的附加注意評分函數(shù)按照 (11.3.3)計算。這種使用注意力的 RNN 編碼器-解碼器架構(gòu)如圖 11.4.2所示。請注意,后來對該模型進(jìn)行了修改,例如在解碼器中包含已經(jīng)生成的標(biāo)記作為進(jìn)一步的上下文(即,注意力總和確實停止在T而是它繼續(xù)進(jìn)行t′?1). 例如,參見Chan等人。( 2015 )描述了這種應(yīng)用于語音識別的策略。

圖 11.4.2具有 Bahdanau 注意機制的 RNN 編碼器-解碼器模型中的層。
11.4.2。用注意力定義解碼器
要實現(xiàn)帶有注意力的 RNN 編碼器-解碼器,我們只需要重新定義解碼器(從注意力函數(shù)中省略生成的符號可以簡化設(shè)計)。讓我們通過定義一個意料之中的命名類來開始具有注意力的解碼器的基本接口 AttentionDecoder。
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError
我們需要在Seq2SeqAttentionDecoder 類中實現(xiàn) RNN 解碼器。解碼器的狀態(tài)初始化為(i)編碼器最后一層在所有時間步的隱藏狀態(tài),用作注意力的鍵和值;(ii) 編碼器在最后一步的所有層的隱藏狀態(tài)。這用于初始化解碼器的隱藏狀態(tài);(iii) 編碼器的有效長度,以排除注意力池中的填充標(biāo)記。在每個解碼時間步,解碼器最后一層的隱藏狀態(tài),在前一個時間步獲得,用作注意機制的查詢。注意機制的輸出和輸入嵌入都被連接起來作為 RNN 解碼器的輸入。
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(d2l.init_seq2seq)
def init_state(self, enc_outputs, enc_valid_lens):
# Shape of outputs: (num_steps, batch_size, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# Shape of enc_outputs: (batch_size, num_steps, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# Shape of context: (batch_size, 1, num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# Concatenate on the feature dimension
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# Reshape x as (1, batch_size, embed_size + num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After fully connected layer transformation, shape of outputs:
# (num_steps, batch_size, vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
self.initialize(init.Xavier())
def init_state(self, enc_outputs, enc_valid_lens):
# Shape of outputs: (num_steps, batch_size, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.swapaxes(0, 1), hidden_state, enc_valid_lens)
def forward(self, X, state):
# Shape of enc_outputs: (batch_size, num_steps, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X).swapaxes(0, 1)
outputs, self._attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = np.expand_dims(hidden_state[-1], axis=1)
# Shape of context: (batch_size, 1, num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# Concatenate on the feature dimension
x = np.concatenate((context, np.expand_dims(x, axis=1)), axis=-1)
# Reshape x as (1, batch_size, embed_size + num_hiddens)
out, hidden_state = self.rnn(x.swapaxes(0, 1), hidden_state)
hidden_state = hidden_state[0]
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After fully connected layer transformation, shape of outputs:
# (num_steps, batch_size, vocab_size)
outputs = self.dense(np.concatenate(outputs, axis=0))
return outputs.swapaxes(0, 1), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
class Seq2SeqAttentionDecoder(nn.Module):
vocab_size: int
embed_size: int
num_hiddens: int
num_layers: int
dropout: float = 0
def setup(self):
self.attention = d2l.AdditiveAttention(self.num_hiddens, self.dropout)
self.embedding = nn.Embed(self.vocab_size, self.embed_size)
self.dense = nn.Dense(self.vocab_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout=self.dropout)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# Shape of outputs: (num_steps, batch_size, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
# Attention Weights are returned as part of state; init with None
return (outputs.transpose(1, 0, 2), hidden_state, enc_valid_lens)
@nn.compact
def __call__(self, X, state, training=False):
# Shape of enc_outputs: (batch_size, num_steps, num_hiddens).
# Shape of hidden_state: (num_layers, batch_size, num_hiddens)
# Ignore Attention value in state
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X).transpose(1, 0, 2)
outputs, attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = jnp.expand_dims(hidden_state[-1], axis=1)
# Shape of context: (batch_size, 1, num_hiddens)
context, attention_w = self.attention(query, enc_outputs,
enc_outputs, enc_valid_lens,
training=training)
# Concatenate on the feature dimension
x = jnp.concatenate((context, jnp.expand_dims(x, axis=1)), axis=-1)
# Reshape x as (1, batch_size, embed_size + num_hiddens)
out, hidden_state = self.rnn(x.transpose(1, 0, 2), hidden_state,
training=training)
outputs.append(out)
attention_weights.append(attention_w)
# Flax sow API is used to capture intermediate variables
self.sow('intermediates', 'dec_attention_weights', attention_weights)
# After fully connected layer transformation, shape of outputs:
# (num_steps, batch_size, vocab_size)
outputs = self.dense(jnp.concatenate(outputs, axis=0))
return outputs.transpose(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens,
num_hiddens, dropout)
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = tf.keras.layers.RNN(tf.keras.layers.StackedRNNCells(
[tf.keras.layers.GRUCell(num_hiddens, dropout=dropout)
for _ in range(num_layers)]), return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def init_state(self, enc_outputs, enc_valid_lens):
# Shape of outputs: (batch_size, num_steps, num_hiddens).
# Length of list hidden_state is num_layers, where the shape of its
# element is (batch_size, num_hiddens)
outputs, hidden_state = enc_outputs
return (tf.transpose(outputs, (1, 0, 2)), hidden_state,
enc_valid_lens)
def call(self, X, state, **kwargs):
# Shape of output enc_outputs: # (batch_size, num_steps, num_hiddens)
# Length of list hidden_state is num_layers, where the shape of its
# element is (batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Shape of the output X: (num_steps, batch_size, embed_size)
X = self.embedding(X) # Input X has shape: (batch_size, num_steps)
X = tf.transpose(X, perm=(1, 0, 2))
outputs, self._attention_weights = [], []
for x in X:
# Shape of query: (batch_size, 1, num_hiddens)
query = tf.expand_dims(hidden_state[-1], axis=1)
# Shape of context: (batch_size, 1, num_hiddens)
context = self.attention(query, enc_outputs, enc_outputs,
enc_valid_lens, **kwargs)
# Concatenate on the feature dimension
x = tf.concat((context, tf.expand_dims(x, axis=1)), axis=-1)
out = self.rnn(x, hidden_state, **kwargs)
hidden_state = out[1:]
outputs.append(out[0])
self._attention_weights.append(self.attention.attention_weights)
# After fully connected layer transformation, shape of outputs:
# (batch_size, num_steps, vocab_size)
outputs = self.dense(tf.concat(outputs, axis=1))
return outputs, [enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
在下文中,我們使用 4 個序列的小批量測試實施的解碼器,每個序列有 7 個時間步長。
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
X = torch.zeros((batch_size, num_steps), dtype=torch.long)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
X = np.zeros((batch_size, num_steps))
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
X = jnp.zeros((batch_size, num_steps), dtype=jnp.int32)
state = decoder.init_state(encoder.init_with_output(d2l.get_key(),
X, training=False)[0],
None)
(output, state), _ = decoder.init_with_output(d2l.get_key(), X,
state, training=False)
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
X = tf.zeros((batch_size, num_steps))
state = decoder.init_state(encoder(X, training=False), None)
output, state = decoder(X, state, training=False)
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
11.4.3。訓(xùn)練
現(xiàn)在我們指定了新的解碼器,我們可以類似于 第 10.7.6 節(jié)進(jìn)行:指定超參數(shù),實例化一個常規(guī)編碼器和一個帶有注意力的解碼器,并訓(xùn)練這個模型進(jìn)行機器翻譯。
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005, training=True)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
with d2l.try_gpu():
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1)
trainer.fit(model, data)

模型訓(xùn)練完成后,我們用它來將幾個英語句子翻譯成法語并計算它們的 BLEU 分?jǐn)?shù)。
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .'] fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .'] preds, _ = model.predict_step( data.build(engs, fras), d2l.try_gpu(), data.num_steps) for en, fr, p in zip(engs, fras, preds): translation = [] for token in data.tgt_vocab.to_tokens(p): if token == '': break translation.append(token) print(f'{en} => {translation}, bleu,' f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['je', "l'ai", '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['', '!'], bleu,0.000 i lost . => ['j’ai', 'payé', '.'], bleu,0.000 he's calm . => ['je', 'suis', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .'] fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .'] preds, _ = model.predict_step( trainer.state.params, data.build(engs, fras), data.num_steps) for en, fr, p in zip(engs, fras, preds): translation = [] for token in data.tgt_vocab.to_tokens(p): if token == '': break translation.append(token) print(f'{en} => {translation}, bleu,' f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['', '.'], bleu,0.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['je', 'suis', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['', '!'], bleu,0.000 i lost . => ["j'ai", 'compris', '.'], bleu,0.000 he's calm . => ['il', 'est', 'mouillé', '.'], bleu,0.658 i'm home . => ['je', 'suis', 'parti', '.'], bleu,0.512
讓我們想象一下翻譯最后一個英語句子時的注意力權(quán)重。我們看到每個查詢都在鍵值對上分配了不均勻的權(quán)重。它表明在每個解碼步驟中,輸入序列的不同部分被選擇性地聚集在注意力池中。
_, dec_attention_weights = model.predict_step( data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True) attention_weights = torch.cat( [step[0][0][0] for step in dec_attention_weights], 0) attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps)) # Plus one to include the end-of-sequence token d2l.show_heatmaps( attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(), xlabel='Key positions', ylabel='Query positions')

_, dec_attention_weights = model.predict_step( data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True) attention_weights = np.concatenate( [step[0][0][0] for step in dec_attention_weights], 0) attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps)) # Plus one to include the end-of-sequence token d2l.show_heatmaps( attention_weights[:, :, :, :len(engs[-1].split()) + 1], xlabel='Key positions', ylabel='Query positions')

_, (dec_attention_weights, _) = model.predict_step(
trainer.state.params, data.build([engs[-1]], [fras[-1]]),
data.num_steps, True)
attention_weights = jnp.concatenate(
[step[0][0][0] for step in dec_attention_weights], 0)
attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps))
# Plus one to include the end-of-sequence token
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1],
xlabel='Key positions', ylabel='Query positions')

_, dec_attention_weights = model.predict_step(
data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True)
attention_weights = tf.concat(
[step[0][0][0] for step in dec_attention_weights], 0)
attention_weights = tf.reshape(attention_weights, (1, 1, -1, data.num_steps))
# Plus one to include the end-of-sequence token
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1],
xlabel='Key positions', ylabel='Query positions')

11.4.4。概括
在預(yù)測標(biāo)記時,如果并非所有輸入標(biāo)記都相關(guān),則具有 Bahdanau 注意力機制的 RNN 編碼器-解碼器會選擇性地聚合輸入序列的不同部分。這是通過將狀態(tài)(上下文變量)視為附加注意力池的輸出來實現(xiàn)的。在 RNN encoder-decoder 中,Bahdanau attention 機制將前一個時間步的解碼器隱藏狀態(tài)視為查詢,將所有時間步的編碼器隱藏狀態(tài)視為鍵和值。
11.4.5。練習(xí)
實驗中用 LSTM 替換 GRU。
修改實驗以用縮放的點積替換附加注意力評分函數(shù)。對訓(xùn)練效率有何影響?
-
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13252
發(fā)布評論請先 登錄
相關(guān)推薦
深度分析NLP中的注意力機制
注意力機制的誕生、方法及幾種常見模型
注意力機制或?qū)⑹俏磥頇C器學(xué)習(xí)的核心要素
基于注意力機制的深度學(xué)習(xí)模型AT-DPCNN

計算機視覺中的注意力機制

PyTorch教程11.4之Bahdanau注意力機制
PyTorch教程11.6之自注意力和位置編碼
PyTorch教程16.5之自然語言推理:使用注意力
PyTorch教程-11.5。多頭注意力






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論