 RISC-V處理器優化,不可依賴于放之四海而皆準的方法
RISC-V處理器優化,不可依賴于放之四海而皆準的方法
隨著對高性能處理器的需求不斷增長,半導體的縮放定律不斷顯示其極限,對處理器的優化需求變得不可避免。正如我在之前的博客中解釋的那樣,RISC-V的設計就是為了實現這一點。然而,在處理器優化方面沒有一個放之四海而皆準的方法。由于每個工作負載和應用程序都有自己的要求,因此優化方法也因個體而異。我們可以在不同的層面上修改處理器IP,每一種都有自己的優勢。在這篇博文中,讓我們來定義和探索處理器優化的不同層次。從配置到定制,如何使用它們來創建滿足特定要求的優化過的品質處理器。
首先定義三個不同級別的處理器優化,它們有著不同的優勢和使用場景。所有三個級別不但不相互排斥,還可以將三者結合起來,以實現PPA目標。

3 levels of processor customization. Source: Codasip
配置:將標準內核的RTL參數設置為預先定義的值
每個處理器IP都有一套可調整的、預先定義的參數。它們在交付時有一個默認值,該默認值可以修改并設置為特定用例所需的值。大家通常可以在RTL級別設置并輕松修改這些參數。這種級別的優化在業界非常普遍,而且廣泛傳播。這些參數可能包括中斷次數,是否存在簡單的功能或緩存的大小等。
在RTL級別的調整對于任何處理器IP來說都是可以預期的,并且可以通過Codasip以RTL形式提供的標準Codasip RISC-V核來實現。該IP是經過完全驗證的,簡化后的集成,但是參數的范圍和可能的值是有限的,探索空間也相對有限。
雖然這些參數是必要的,但不足以為特定需求創造一個真正獨特的差異化產品。原因是它們既是有限的選項集,同時也是在RTL層面的實現的,而RTL級別的實現是難以參數化的,這在業界眾所周知。因此,配置只能給予對最終設計的有限控制。
高級配置:結構性變化以適應設計
除了配置之外,還有高級配置可以運用。在高級別配置上,這個概念看起來很相似。但我們的想法是啟用更大、更復雜的參數,從而得到明顯差異化的RTL 。配置選項的例子包括:
1. 緩存和TCM的增加
2. 浮點單元的存在
3. 或分支預測器的存在
這種靈活性對于處理器IP來說雖然不太常見,但是可以使用Codasip IP來實現。所有的Codasip RISC-V內核都是用一種叫做CodAL的高級語言設計的,并且可以用Codasip Studio設計自動化進行配置。只需從配置器GUI中選擇高級參數,該工具就會自動生成只包含自定義優化配置的RTL。
處理器的CodAL源代碼可向用戶提供所有選項。然后,Codasip Studio工具將CodAL合成為RTL。
Codasip提供大量的CodAL配置選項,也意味著客戶不需要任何關于CodAL的具體知識(盡管這種類似C語言的編程語言很簡單和直接)。這中方法為實現特定應用定制產品提供了保證。并完全可以從同一個源代碼中同時優化硬件和軟件。
定制:更深層次的處理器IP優化
更深層次的IP優化實際上是設計師對IP的修改,以便為目標應用獲得更高的效率性能。這是定制計算的領域,也是Codasip提供的具有競品優勢的解決方案。其他IP供應商可能會宣稱處理器也可以進行定制,但如果沒有自動化設計流程,這種期待只能停留在理論上,而且可定制范圍非常有限。
Codasip RISC-V內核的定制意味著對IP進行細粒度的修改,能夠在架構和微架構層面上修改需要的任何東西。可以增加或刪除指令,改變寄存器集或增加全新的功能或接口,而不僅僅是修改現有的參數。CodAL語言的使用使這些修改變得快速而簡單。Codasip Studio的分析功能指出了需要改進的潛在領域,并能非常快速地反饋應用程序在這些修改后的表現,這對快速迭代和獲得最佳結果至關重要。
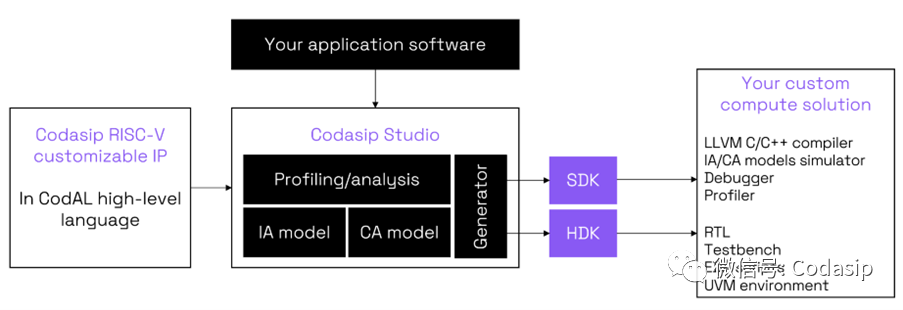
Automated approach to custom compute. Source: Codasip
而從一個經過完整驗證的RISC-V內核開始,也使這個定制過程變得更快,并可以大大減少驗證工作,而驗證環節通常是設計項目中最耗時的任務。在Codasip Studio中用CodAL對Codasip RISC-V內核進行全面優化,是為應用獲得定制計算的一種實用方法。它最大的優勢在于整個設計流程是自動化的,而且該工具會自動生成一個SDK和HDK,這些SDK和HDK并已知與定制內核相匹配的相關。而不需要手動來創建一切!
處理器優化案例
可以想象一下,如果想為特定的機器學習工作負載優化一個處理器,以卷積神經網絡(CNN)為例。
隨著向設備級人工智能處理的重要轉變,在為物聯網應用選擇SoC或MC時,運行人工智能/機器學習任務的能力成為必須具備的條件。但是嵌入式設備通常受到資源限制,因此很難在嵌入式平臺上運行人工智能算法。
使用Codasip L31 RISC-V內核和Codasip Studio,我們可以探索和定制處理器設計,以提高其運行機器學習算法時的效率。Codasip Studio中包含的剖析工具使設計者能夠比較標準內核和優化內核的性能,突出神經網絡定制指令的好處。
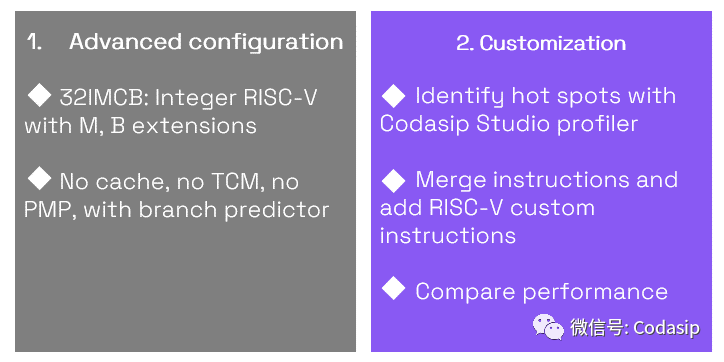
Our approach to processor optimization for ML workloads (use case). Source: Codasip
Codasipde的方法是在不同的層次上對處理器進行調整:
我們為ML工作負載優化處理器的Codasip方法(使用案例):高級配置和定制
通過對圖像識別的基準應用進行分析,我們用Codasip Studio工具證實,圖像卷積是一個主要的瓶頸,占用了89%以上的CPU時間。不到200行的CodAL代碼足以實現一個緊密集成在Codasip L31內核的卷積加速器。在對最大頻率影響不到10%的情況下,這種修改提供了大于5倍的性能提升和小于3倍的能耗。Codasip Studio自動生成一個優化的編譯器,在不改變軟件的情況下實現了效率的提高!
如果您對神經網絡加速器技術白皮書感興趣,請移步該鏈接下載英文原版:https://codasip.com/papers/compact-nn-accelerator-in-codal-technical-paper/
各種處理器優化方法相結合以求最佳結果
正如我們所說,在處理器優化方面沒有一個放之四海而皆準的方法。處理器IP修改可以在不同層面進行,每個層面都可以帶來不同的優勢。這種組合的相結合則能協助客戶在開發獨特產品時實現最佳的PPA目標。

審核編輯 :李倩
-
處理器
+關注
關注
68文章
19349瀏覽量
230293 -
內核
+關注
關注
3文章
1377瀏覽量
40326 -
RISC-V
+關注
關注
45文章
2300瀏覽量
46252
原文標題:RISC-V處理器優化,不可依賴于放之四海而皆準的方法。
文章出處:【微信號:Codasip 科達希普,微信公眾號:Codasip 科達希普】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
晶心科技推出突破性的RISC-V 27系列處理器及向量擴展指令處理器
開放性與碎片化,RISC-V能否撼動處理器架構的格局?
關于RISC-V和開源處理器的一些解讀
學習RISC-V入門 基于RISC-V架構的開源處理器及SoC研究
RISC-V開源處理器核介紹
優化的關鍵,RISC-V中的性能監控
RISC-V工具鏈簡介
香山處理器 RISC-V的典范
RISC-V是通用RISC處理器還是可定制的處理器?
美國芯片企業開發出全球最快的64位Risc-V處理器
基于形式驗證的高效RISC-V處理器驗證方法
基于形式的高效 RISC-V 處理器驗證方法





 工商網監
工商網監
評論