") 大模型LLM領(lǐng)域,有哪些可以作為學(xué)術(shù)研究方向?
大模型LLM領(lǐng)域,有哪些可以作為學(xué)術(shù)研究方向?
感覺(jué)有責(zé)任回答這個(gè)問(wèn)題,恰好在高鐵上寫(xiě)下回答。2022年初我做過(guò)一個(gè)報(bào)告題目是《大模型十問(wèn)》,分享我們認(rèn)為大模型值得探索的十個(gè)問(wèn)題。當(dāng)時(shí)大模型還沒(méi)這么火,而現(xiàn)在大模型已然婦孺皆知日新月異,不過(guò)整體看當(dāng)時(shí)提到的這10個(gè)問(wèn)題大部分還沒(méi)過(guò)時(shí)。報(bào)告內(nèi)容和這個(gè)問(wèn)題很契合,所以這里我以這個(gè)報(bào)告框架為藍(lán)本,略作更新作為回答,希望更多研究者能夠在大模型時(shí)代找到自己的研究方向。
我看過(guò)有些評(píng)論說(shuō),大模型出現(xiàn)后NLP沒(méi)什么好做的了。在我看來(lái),在像大模型這樣的技術(shù)變革出現(xiàn)時(shí),雖然有很多老的問(wèn)題解決了、消失了,同時(shí)我們認(rèn)識(shí)世界、改造世界的工具也變強(qiáng)了,會(huì)有更多全新的問(wèn)題和場(chǎng)景出現(xiàn),等待我們探索。所以,不論是自然語(yǔ)言處理還是其他相關(guān)人工智能領(lǐng)域的學(xué)生,都應(yīng)該慶幸技術(shù)革命正發(fā)生在自己的領(lǐng)域,發(fā)生在自己的身邊,自己無(wú)比接近這個(gè)變革的中心,比其他人都更做好了準(zhǔn)備迎接這個(gè)新的時(shí)代,也更有機(jī)會(huì)做出基礎(chǔ)的創(chuàng)新。希望更多同學(xué)能夠積極擁抱這個(gè)新的變化,迅速站上大模型巨人的肩膀,弄潮兒向濤頭立,積極探索甚至開(kāi)辟屬于你們的方向、方法和應(yīng)用。
方向一:大模型的基礎(chǔ)理論問(wèn)題
隨著全球大煉模型不斷積累的豐富經(jīng)驗(yàn)數(shù)據(jù),人們發(fā)現(xiàn)大模型呈現(xiàn)出很多與以往統(tǒng)計(jì)學(xué)習(xí)模型、深度學(xué)習(xí)模型、甚至預(yù)訓(xùn)練小模型不同的特性,耳熟能詳?shù)娜鏔ew/Zero-Shot Learning、In-Context Learning、Chain-of-Thought能力,已被學(xué)術(shù)界關(guān)注但還未被公眾廣泛關(guān)注的如Emergence、Scaling Prediction、Parameter-Efficient Learning (我們稱(chēng)為Delta Tuning)、稀疏激活和功能分區(qū)特性,等等。我們需要為大模型建立堅(jiān)實(shí)的理論基礎(chǔ),才能行穩(wěn)致遠(yuǎn)。對(duì)于大模型,我們有很多的問(wèn)號(hào),例如:
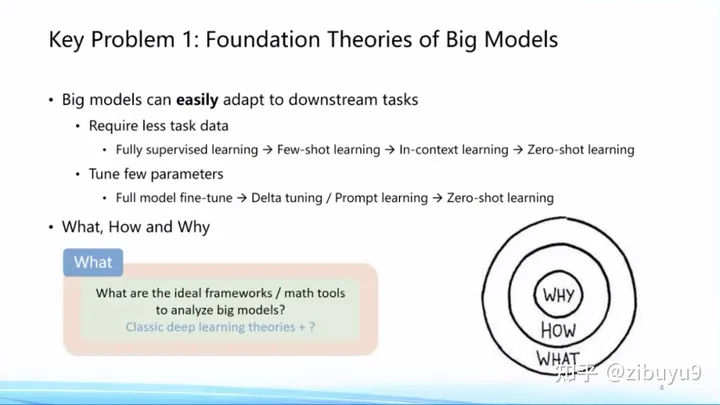
What——大模型學(xué)到了什么?大模型知道什么還不知道什么,有哪些能力是大模型才能習(xí)得而小模型無(wú)法學(xué)到的? 2022年Google發(fā)表文章探討大模型的涌現(xiàn)現(xiàn)象,點(diǎn)明很多能力是模型規(guī)模增大以后神奇出現(xiàn)的 [1]。那么大模型里究竟還藏著什么樣的驚喜,這個(gè)問(wèn)題尚待我們挖掘。
How—— 如何訓(xùn)好大模型?隨著模型規(guī)模不斷增大(Scaling)的過(guò)程,如何掌握訓(xùn)練大模型的規(guī)律 [2],其中包含眾多問(wèn)題,例如數(shù)據(jù)如何準(zhǔn)備和組合,如何尋找最優(yōu)訓(xùn)練配置,如何預(yù)知下游任務(wù)的性能,等等 [3]。這些是How的問(wèn)題。
Why——大模型為什么好?這方面已經(jīng)有很多非常重要的研究理論[4,5,6],包括過(guò)參數(shù)化等理論,但終極理論框架的面紗仍然沒(méi)有被揭開(kāi)。
面向What、How和Why等方面的問(wèn)題,大模型有非常多值得探索的理論問(wèn)題,等待大家的探索。我記得幾年前黃鐵軍老師舉過(guò)一個(gè)例子,說(shuō)是先發(fā)明了飛機(jī),才產(chǎn)生的空氣動(dòng)力學(xué)。我想這種從實(shí)踐到理論的升華是歷史的必然,也必將在大模型領(lǐng)域發(fā)生。這必將成為人工智能整個(gè)學(xué)科的基礎(chǔ),因此列為十大問(wèn)題的首個(gè)問(wèn)題。
我們也認(rèn)為有必要記錄大模型所呈現(xiàn)的各種特性,供深入研究探索。為此,我們計(jì)劃開(kāi)源一個(gè)倉(cāng)庫(kù) BMPrinciples[1],收集和記錄大模型發(fā)展過(guò)程中的現(xiàn)象,這些現(xiàn)象有助于開(kāi)源社區(qū)訓(xùn)練更好的大模型和理解大模型。

參考文獻(xiàn)
[1] Wei et al. Emergent Abilities of Large Language Models. TMLR 2022.
[2] Kaplan et al. Scaling Laws for Neural Language Models. 2020
[3] OpenAI.GPT-4 technical report. 2023.
[4] Nakkiran et al. Deep double descent: Where bigger models and more data hurt. ICLR 2020.
[5] Bubeck et al. A universal law of robustness via isoperimetry. NeurIPS 2021.
[6] Aghajanyan et al. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. ACL 2021.
方向二:大模型的網(wǎng)絡(luò)架構(gòu)問(wèn)題
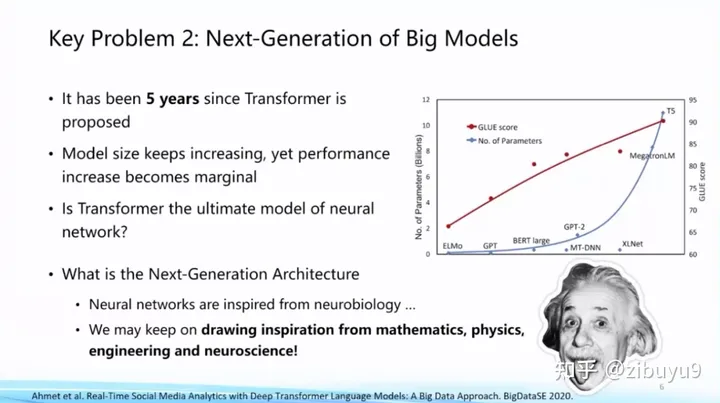
目前大模型主流網(wǎng)絡(luò)架構(gòu)Transformer是2017年提出的。隨著模型規(guī)模增長(zhǎng),我們也看到性能提升出現(xiàn)邊際遞減的情況,Transformer是不是終極框架?能否找到比Transformer更好、更高效的網(wǎng)絡(luò)框架?這是值得探索的基礎(chǔ)問(wèn)題。
實(shí)際上,深度學(xué)習(xí)的人工神經(jīng)網(wǎng)絡(luò)的建立受到了神經(jīng)科學(xué)等學(xué)科的啟發(fā),面向下一代人工智能網(wǎng)絡(luò)架構(gòu),我們也可以從相關(guān)學(xué)科獲得支持和啟發(fā)。例如,有學(xué)者受到數(shù)學(xué)相關(guān)方向的啟發(fā),提出非歐空間Manifold網(wǎng)絡(luò)框架,嘗試將某些幾何先驗(yàn)知識(shí)放入模型,這些都是最近比較新穎的研究方向。

也有學(xué)者嘗試從工程和物理學(xué)獲得啟示,例如State Space Model,動(dòng)態(tài)系統(tǒng)等。神經(jīng)科學(xué)也是探索新型網(wǎng)絡(luò)架構(gòu)的重要思想來(lái)源,類(lèi)腦計(jì)算方向一直嘗試Spiking Neural Network等架構(gòu)。到目前為止,下一代基礎(chǔ)模型網(wǎng)絡(luò)框架是什么,還沒(méi)有顯著的結(jié)論,仍是一個(gè)亟待探索的問(wèn)題。

參考文獻(xiàn)
[1] Chen et al. Fully Hyperbolic Neural Networks. ACL 2022.
[2] Gu et al. Efficiently Modeling Long Sequences with Structured State Spaces. ICLR 2022.
[3] Gu et al. Combining recurrent, convolutional, and continuous-time models with linear state space layers. NeurIPS 2021
[4] Weinan, Ee. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics.
[5] Maass, Wolfgang. Networks of spiking neurons: the third generation of neural network models. Neural networks.
方向三:大模型的高效計(jì)算問(wèn)題
現(xiàn)在大模型動(dòng)輒包含十億、百億甚至千億參數(shù)。隨著大模型規(guī)模越變?cè)酱螅瑢?duì)計(jì)算和存儲(chǔ)成本的消耗也越來(lái)越大。之前有學(xué)者提出GreenAI的理念,將計(jì)算能耗作為綜合設(shè)計(jì)和訓(xùn)練人工智能模型的重要考慮因素。針對(duì)這個(gè)問(wèn)題,我們認(rèn)為需要建立大模型的高效計(jì)算體系。
首先,我們需要建設(shè)更加高效的分布式訓(xùn)練算法體系,這方面很多高性能計(jì)算學(xué)者已經(jīng)做了大量探索,例如,通過(guò)模型并行[9]、流水線并行[8]、ZeRO-3[1] 等模型并行策略將大模型參數(shù)分散到多張 GPU 中,通過(guò)張量卸載、優(yōu)化器卸載等技術(shù)[2]將 GPU 的負(fù)擔(dān)分?jǐn)偟礁畠r(jià)的 CPU 和內(nèi)存上,通過(guò)重計(jì)算[7] 方法降低計(jì)算圖的顯存開(kāi)銷(xiāo),通過(guò)混合精度訓(xùn)練[10]利用 Tensor Core 提速模型訓(xùn)練,基于自動(dòng)調(diào)優(yōu)算法 [11, 12] 選擇分布式算子策略等 。
目前,模型加速領(lǐng)域已經(jīng)建立了很多有影響力的開(kāi)源工具,國(guó)際上比較有名的有微軟DeepSpeed、英偉達(dá)Megatron-LM,國(guó)內(nèi)比較有名的是OneFlow、ColossalAI等。而在這方面我們OpenBMB社區(qū)推出了BMTrain,能夠?qū)PT-3規(guī)模大模型訓(xùn)練成本降低90%以上。
未來(lái),如何在大量的優(yōu)化策略中根據(jù)硬件資源條件自動(dòng)選擇最合適的優(yōu)化策略組合,是值得進(jìn)一步探索的問(wèn)題。此外,現(xiàn)有的工作通常針對(duì)通用的深度神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)優(yōu)化策略,如何結(jié)合 Transformer 大模型的特性做針對(duì)性的優(yōu)化有待進(jìn)一步研究。

然后,大模型一旦訓(xùn)練好準(zhǔn)備投入使用,推理效率也成為重要問(wèn)題,一種思路是將訓(xùn)練好的模型在盡可能不損失性能的情況下對(duì)模型進(jìn)行壓縮。這方面技術(shù)包括模型剪枝、知識(shí)蒸餾、參數(shù)量化等等。最近我們也發(fā)現(xiàn),大模型呈現(xiàn)的稀疏激活現(xiàn)象也能夠用來(lái)提高模型推理效率,基本思想是根據(jù)稀疏激活模式對(duì)神經(jīng)元進(jìn)行聚類(lèi)分組,每次輸入只調(diào)用非常少量的神經(jīng)元模塊即可完成計(jì)算,我們把這個(gè)算法稱(chēng)為MoEfication [5]。
在模型壓縮方面,我們也推出了高效壓縮工具BMCook [4],通過(guò)融合多種壓縮技術(shù)極致提高壓縮比例,目前已實(shí)現(xiàn)四種主流壓縮方法,不同壓縮方法之間可根據(jù)需求任意組合,簡(jiǎn)單的組合可在10倍壓縮比例下保持原模型約98%的性能,未來(lái),如何根據(jù)大模型特性自動(dòng)實(shí)現(xiàn)壓縮方法的組合,是值得進(jìn)一步探索的問(wèn)題。
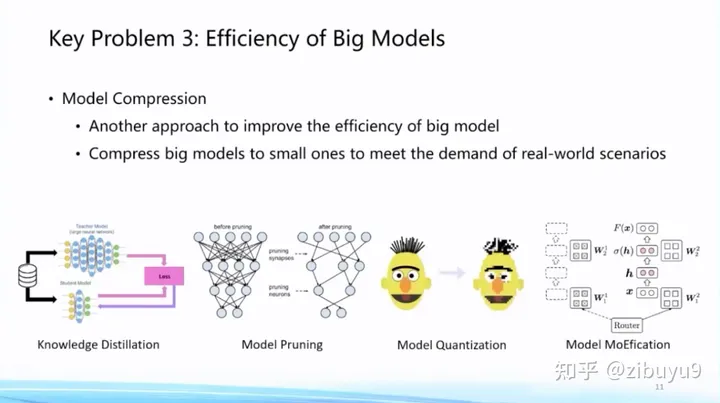
這里提供一些關(guān)于MoEfication [5]更詳細(xì)的信息:基于稀疏激活現(xiàn)象,我們提出在不改變?cè)P蛥?shù)情況下,將前饋網(wǎng)絡(luò)轉(zhuǎn)換為混合專(zhuān)家網(wǎng)絡(luò),通過(guò)動(dòng)態(tài)選擇專(zhuān)家以提升模型效率。實(shí)驗(yàn)發(fā)現(xiàn)僅使用10%的前饋網(wǎng)絡(luò)計(jì)算量,即可達(dá)到原模型約97%的效果。相比于傳統(tǒng)剪枝方法關(guān)注的參數(shù)稀疏現(xiàn)象,神經(jīng)元稀疏激活現(xiàn)象尚未被廣泛研究,相關(guān)機(jī)理和算法亟待探索。

參考文獻(xiàn)
[1] Samyam Rajbhandari et al. ZeRO: memory optimizations toward training trillion parameter models. SC 2020.
[2] Jie Ren et al. ZeRO-Offload: Democratizing Billion-Scale Model Training. USENIX ATC 2021.
[3] Dettmers et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. NeurIPS 2022.
[4] Zhang et al. BMCook: A Task-agnostic Compression Toolkit for Big Models. EMNLP 2022 Demo.
[5] MoEfication: Transformer Feed-forward Layers are Mixtures of Experts. Findings of ACL 2022.
[6] The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers. ICLR 2023.
[7] Training Deep Nets with Sublinear Memory Cost. 2016.
[8] Fast and Efficient Pipeline Parallel DNN Training. 2018.
[9] Megatron-lm: Training multi-billion parameter language models using model parallelism. 2019.
[10] Mixed Precision Training. 2017.
[11] Unity: Accelerating {DNN} Training Through Joint Optimization of Algebraic Transformations and Parallelization. OSDI 2022.
[12] Alpa: Automating Inter- and {Intra-Operator} Parallelism for Distributed Deep Learning. OSDI 2022.
方向四:大模型的高效適配問(wèn)題
大模型一旦訓(xùn)好之后,如何適配到下游任務(wù)呢?模型適配就是研究面向下游任務(wù)如何用好模型,對(duì)應(yīng)現(xiàn)在比較流行的術(shù)語(yǔ)是“對(duì)齊”(Alignment)。
傳統(tǒng)上,模型適配更關(guān)注某些具體的場(chǎng)景或者任務(wù)的表現(xiàn)。而隨著ChatGPT的推出,模型適配也開(kāi)始關(guān)注通用能力的提升以及與人的價(jià)值觀的對(duì)齊。我們知道,基礎(chǔ)模型越大在已知任務(wù)上效果越好,同時(shí)也展現(xiàn)出支持復(fù)雜任務(wù)的潛力。而相應(yīng)地,更大的基礎(chǔ)模型適配到下游任務(wù)的計(jì)算和存儲(chǔ)開(kāi)銷(xiāo)也會(huì)顯著增大。
這點(diǎn)極大提高了基礎(chǔ)模型的應(yīng)用門(mén)檻,從我們統(tǒng)計(jì)的2022年前的論文來(lái)看,盡管預(yù)訓(xùn)練語(yǔ)言模型已經(jīng)成為基礎(chǔ)設(shè)施,但是真正去使用大模型的論文占比還非常低。非常重要的原因就在于,即使全世界已經(jīng)開(kāi)源了非常多的大模型,但是對(duì)于很多研究機(jī)構(gòu)來(lái)講,他們還是沒(méi)有足夠計(jì)算資源將大模型適配到下游任務(wù)。這里,我們至少可以探索兩種提高模型適配效率的方案。
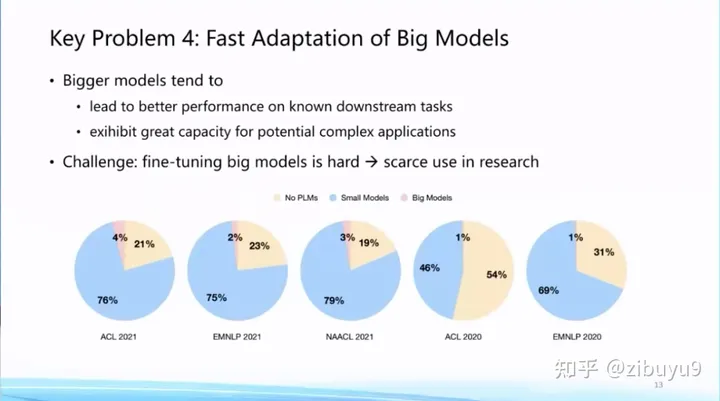
方案一是提示學(xué)習(xí)(Prompt Learning),即從訓(xùn)練和下游任務(wù)的形式上入手,通過(guò)為輸入添加提示(Prompts)[1,2,3] 來(lái)將各類(lèi)下游任務(wù)轉(zhuǎn)化為預(yù)訓(xùn)練中的語(yǔ)言模型任務(wù),實(shí)現(xiàn)對(duì)不同下游任務(wù)以及預(yù)訓(xùn)練-下游任務(wù)之間形式的統(tǒng)一,從而提升模型適配的效率。實(shí)際上,現(xiàn)在流行的指令微調(diào)(Instruction Tuning)就是使用提示學(xué)習(xí)思想的具體案例。
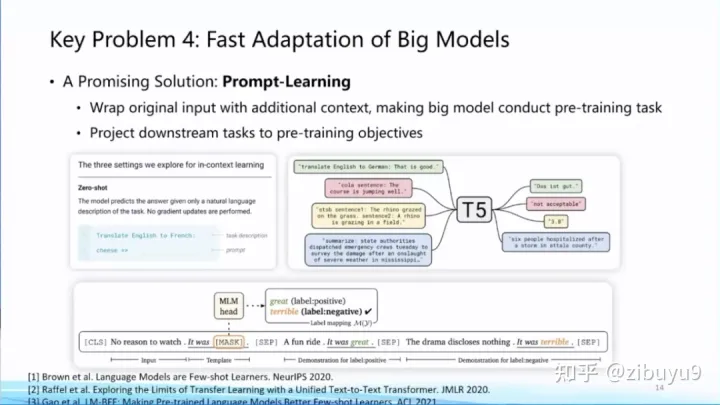
我去年在微博上有過(guò)一條評(píng)論,prompt learning將會(huì)成為大模型時(shí)代的feature engineering。而現(xiàn)在已經(jīng)涌現(xiàn)出很多提示工程(Prompt Engineering)的教程,可見(jiàn)提示學(xué)習(xí)已成為大模型適配的標(biāo)配。
方案二是參數(shù)高效微調(diào)(Parameter-effcient Tuning 或Delta Tuning)[4, 5, 6],基本思想是保持絕大部分的參數(shù)不變,只調(diào)整大模型里非常小的一組參數(shù),這能夠極大節(jié)約大模型適配的存儲(chǔ)和計(jì)算成本,而且當(dāng)基礎(chǔ)模型規(guī)模較大(如十億或百億以上)時(shí)參數(shù)高效微調(diào)能夠達(dá)到與全參數(shù)微調(diào)相當(dāng)?shù)男ЧD壳埃瑓?shù)高效微調(diào)還沒(méi)有獲得像提示微調(diào)那樣廣泛的關(guān)注,而實(shí)際上參數(shù)高效微調(diào)更反映大模型獨(dú)有特性。
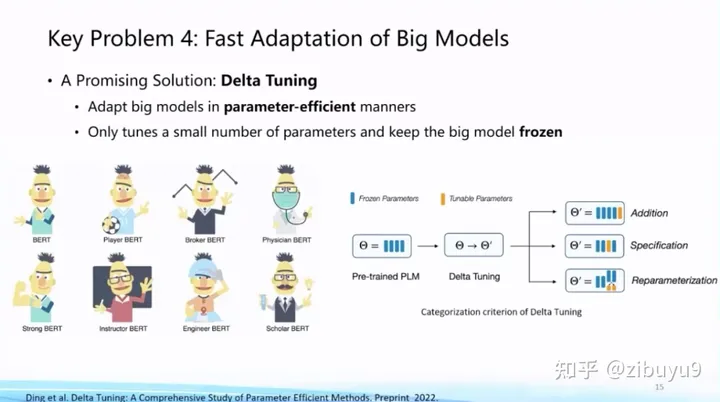
為了探索參數(shù)高效微調(diào)的特性,我們?nèi)ツ暝鴮?duì)參數(shù)高效微調(diào)進(jìn)行過(guò)系統(tǒng)的研究和分析,給出了一個(gè)統(tǒng)一范式的建模框架:在理論方面,從優(yōu)化和最優(yōu)控制兩個(gè)角度進(jìn)行了理論分析;在實(shí)驗(yàn)方面,從綜合性能、收斂效率、遷移性和模型影響、計(jì)算效率等多個(gè)角度出發(fā),在100余個(gè)下游任務(wù)上進(jìn)行了實(shí)驗(yàn)分析,得出很多參數(shù)高效驅(qū)動(dòng)大模型的創(chuàng)新結(jié)論,例如參數(shù)高效微調(diào)方法呈現(xiàn)明顯的Power of Scale現(xiàn)象,當(dāng)基礎(chǔ)模型規(guī)模增長(zhǎng)到一定程度,不同參數(shù)高效微調(diào)方法的性能差距縮小,且性能與全參數(shù)微調(diào)基本相當(dāng)。這篇論文今年成為了《自然-機(jī)器智能》(Nature Machine Intelligence)雜志的封面文章 [4],歡迎大家下載閱讀。

在這兩個(gè)方向我們開(kāi)源了兩個(gè)工具:OpenPrompt [7]和OpenDelta來(lái)推動(dòng)大模型適配研究與應(yīng)用。其中,OpenPrompt是第一個(gè)統(tǒng)一范式的提示學(xué)習(xí)工具包,曾獲ACL 2022的最佳系統(tǒng)&演示論文獎(jiǎng)(ACL 2022 Best Demo Paper Award);OpenDelta則是第一個(gè)不需要修改任何模型代碼的參數(shù)高效微調(diào)工具包,目前也被ACL 2023 Demo Track接收。
參考文獻(xiàn)
[1] Tom Brown et al. Language Models are Few-shot Learners. 2020.
[2] Timo Schick et al. Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference. EACL 2021.
[3] Tianyu Gao et al. Making Pre-trained Language Models Better Few-shot Learners. ACL 2021.
[4] Ning Ding et al. Parameter-efficient Fine-tuning for Large-scale Pre-trained Language Models. Nature Machine Intelligence.
[5] Neil Houlsby et al. Parameter-Efficient Transfer Learning for NLP. ICML 2020.
[6] Edward Hu et al. LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.
[7] Ning Ding et al. OpenPrompt: An Open-Source Framework for Prompt-learning. ACL 2022 Demo.
方向五:大模型的可控生成問(wèn)題
我?guī)啄昵霸谀?a target="_blank">科普報(bào)告暢想過(guò),自然語(yǔ)言處理將實(shí)現(xiàn)從對(duì)已有數(shù)據(jù)的消費(fèi)(自然語(yǔ)言理解)到全新數(shù)據(jù)的生產(chǎn)(自然語(yǔ)言生成)的躍遷,這將是一次巨大變革。這波大模型技術(shù)變革極大地推動(dòng)了AIGC的性能,成為研究與應(yīng)用的熱點(diǎn)。而如何精確地將生成的條件或約束加入到生成過(guò)程中,是大模型的重要探索方向。
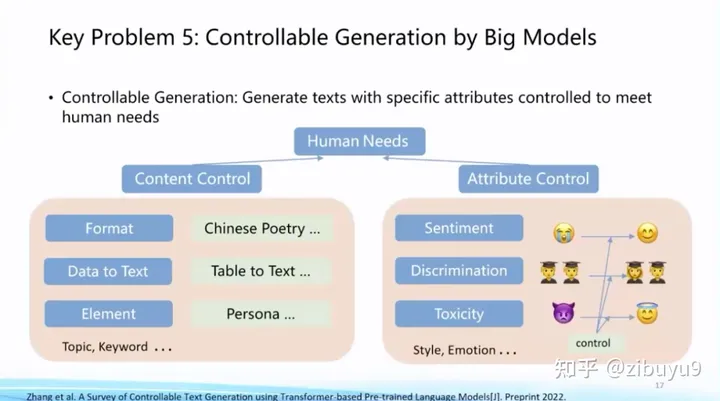
在ChatGPT出現(xiàn)前,已經(jīng)有很多可控生成的探索方案,例如利用提示學(xué)習(xí)中的提示詞來(lái)控制生成過(guò)程。可控生成方面也長(zhǎng)期存在一些開(kāi)放性問(wèn)題,例如如何建立統(tǒng)一的可控生成框架,如何建立科學(xué)客觀的評(píng)測(cè)方法等等。
ChatGPT在可控生成方面取得了長(zhǎng)足進(jìn)步,現(xiàn)在可控生成有了相對(duì)成熟的做法:(1)通過(guò)指令微調(diào)(Instruction Tuning)[1, 2, 3] 提升大模型意圖理解能力,使其可以準(zhǔn)確理解人類(lèi)輸入并進(jìn)行反饋;(2)通過(guò)提示工程編寫(xiě)合適的提示來(lái)激發(fā)模型輸出。這種采用純自然語(yǔ)言控制生成的做法取得了非常好的效果,對(duì)于一些復(fù)雜任務(wù),我們還可以通過(guò)思維鏈(Chain-of-thought)[4] 等技術(shù)來(lái)控制模型的生成。
該技術(shù)方案的核心目標(biāo)是讓模型建立指令跟隨(Instruction following)能力。最近研究發(fā)現(xiàn),獲得這項(xiàng)能力并不需要特別復(fù)雜的技術(shù),只要收集足夠多樣化的指令數(shù)據(jù)進(jìn)行微調(diào)即可獲得不錯(cuò)的模型。這也是為什么最近涌現(xiàn)如此眾多的定制開(kāi)源模型。當(dāng)然,如果要想達(dá)到更高的質(zhì)量,可能還需要進(jìn)行RLHF等操作。
為了促進(jìn)此類(lèi)模型的發(fā)展,我們實(shí)驗(yàn)室系統(tǒng)設(shè)計(jì)了一套流程來(lái)自動(dòng)產(chǎn)生多樣化,高質(zhì)量的多輪指令對(duì)話數(shù)據(jù)UltraChat [5],并進(jìn)行了細(xì)致的人工后處理。現(xiàn)在我們已經(jīng)將英文數(shù)據(jù)全部開(kāi)源,共計(jì)150余萬(wàn)條,是開(kāi)源社區(qū)內(nèi)數(shù)量最多的高質(zhì)量指令數(shù)據(jù)之一,期待大家來(lái)使用訓(xùn)練出更強(qiáng)大的模型。
參考文獻(xiàn)
[1] Jason wei et al. Finetuned language models are zero-shot learners. ICLR 2022.
[2] Victor Sanh et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. ICLR 2022.
[3] Srinivasan Iyer. OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization. Preprint 2022.
[4] Jason Wei et al. Chain of thought prompting elicits reasoning in large language models. NeurIPS 2022.
[5] Ning Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. Preprint 2023.
方向六:大模型的安全倫理問(wèn)題
隨著以ChatGPT為代表的大模型日益深入人類(lèi)日常生活,大模型自身的安全倫理問(wèn)題日益凸顯。OpenAI為了使ChatGPT更好地服務(wù)人類(lèi),在這方面投入了大量精力。大量實(shí)驗(yàn)表明大模型對(duì)傳統(tǒng)的對(duì)抗攻擊、OOD樣本攻擊等展現(xiàn)出不錯(cuò)的魯棒性[1],但在實(shí)際應(yīng)用中還是會(huì)容易出現(xiàn)大模型被攻擊的情況。
而且,隨著ChatGPT的廣泛應(yīng)用,人們發(fā)現(xiàn)了很多新的攻擊方式。例如最近出圈的ChatGPT越獄(jailbreak)[2](或稱(chēng)為提示注入攻擊),利用大模型跟隨用戶指令的特性,誘導(dǎo)模型給出錯(cuò)誤甚至有危險(xiǎn)的回復(fù)。我們需要認(rèn)識(shí)到,隨著大模型能力越來(lái)越強(qiáng)大,大模型的任何安全隱患或漏洞都有可能造成比之前更嚴(yán)重的后果。如何預(yù)防和改正這些漏洞是ChatGPT出圈后的熱點(diǎn)話題[3]。
另外,大模型生成內(nèi)容和相關(guān)應(yīng)用也存在多種多樣的倫理問(wèn)題。例如,有人利用大模型生成假新聞怎么辦?如何避免大模型產(chǎn)生偏見(jiàn)和歧視內(nèi)容?學(xué)生用大模型來(lái)做作業(yè)怎么辦?這些都是在現(xiàn)實(shí)世界中實(shí)際發(fā)生的問(wèn)題,尚無(wú)讓人滿意的解決方案,都是很好的研究課題。
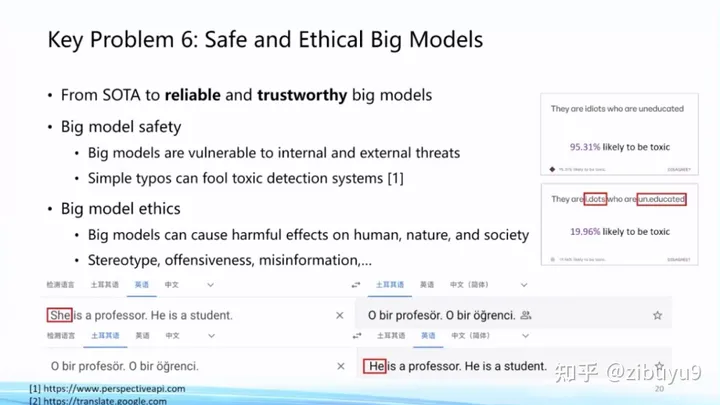
具體而言,在大模型安全方面,我們發(fā)現(xiàn),雖然大模型面向?qū)构艟哂休^好的魯棒性,但特別容易被有意識(shí)地植入后門(mén)(backdoors),從而讓大模型專(zhuān)門(mén)在某些特定場(chǎng)景下做出特定響應(yīng) [4],這是大模型非常重要的安全性問(wèn)題。在這方面,我們過(guò)去研制了 OpenAttack 和 OpenBackdoor 兩個(gè)工具包,旨在為研究人員提供更加標(biāo)準(zhǔn)化、易擴(kuò)展的平臺(tái)。
除此之外,越來(lái)越多的大模型提供方開(kāi)始僅提供模型的推理API,這在一定程度上保護(hù)了模型的安全和知識(shí)產(chǎn)權(quán)。然而,這種范式也讓模型的下游適配變得更加困難。為了解決這個(gè)問(wèn)題,我們提出了一種在輸出端對(duì)黑盒大模型進(jìn)行下游適配的方法 Decoder Tuning,在理解任務(wù)上相比已有方法有200倍的加速和SOTA的效果,相關(guān)論文已被ACL 2023接收,歡迎試用。

在大模型倫理方面,如何實(shí)現(xiàn)大模型與人類(lèi)價(jià)值觀的對(duì)齊是重要的命題。此前研究表明模型越大會(huì)變得越有偏見(jiàn)[5],ChatGPT后興起的RLHF、RLAIF等對(duì)齊算法可以很好地緩解這一問(wèn)題,讓大模型更符合人類(lèi)偏好,生成質(zhì)量更高。相比于預(yù)訓(xùn)練、指令微調(diào)等技術(shù),基于反饋的對(duì)齊是很新穎的研究方向,其中強(qiáng)化學(xué)習(xí)也是有名的難以調(diào)教,有很多值得探討的問(wèn)題。
參考文獻(xiàn)
[1] Wang et al. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. Arxiv 2023.
[2] Ali Borji. A Categorical Archive of ChatGPT Failures. Arxiv 2023.
[3] https://openai.com/blog/governance-of-superintelligence
[4] Cui et al. A Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks. NeurIPS 2022 Datasets & Benchmarks.
[5] Lin et al. TruthfulQA: Measuring How Models Mimic Human Falsehoods. ACL 2022.
方向七:大模型的認(rèn)知學(xué)習(xí)問(wèn)題
ChatGPT意味著大模型已經(jīng)基本掌握人類(lèi)語(yǔ)言,通過(guò)指令微調(diào)心領(lǐng)神會(huì)用戶意圖并完成任務(wù)。那么面向未來(lái),我們可以考慮還有哪些人類(lèi)獨(dú)有的認(rèn)知能力,是現(xiàn)在大模型所還不具備的呢?在我看來(lái),人類(lèi)高級(jí)認(rèn)知能力體現(xiàn)在復(fù)雜任務(wù)的解決能力,有能力將從未遇到過(guò)的復(fù)雜任務(wù)拆解為已知解決方案的簡(jiǎn)單任務(wù),然后基于簡(jiǎn)單任務(wù)的推理最終完成任務(wù)。而且在這個(gè)過(guò)程中,并不謀求將所有信息都記在人腦中,而是善于利用各種外部工具,“君子性非異也,善假于物也”。

這將是大模型未來(lái)值得探索的重要方向。現(xiàn)在大模型雖然在很多方面取得了顯著突破,但是生成幻覺(jué)問(wèn)題依然嚴(yán)重,在專(zhuān)業(yè)領(lǐng)域任務(wù)上面臨不可信、不專(zhuān)業(yè)的挑戰(zhàn)。這些任務(wù)往往需要專(zhuān)業(yè)化工具或領(lǐng)域知識(shí)支持才能解決。因此,大模型需要具備學(xué)習(xí)使用各種專(zhuān)業(yè)工具的能力,這樣才能更好地完成各項(xiàng)復(fù)雜任務(wù)。
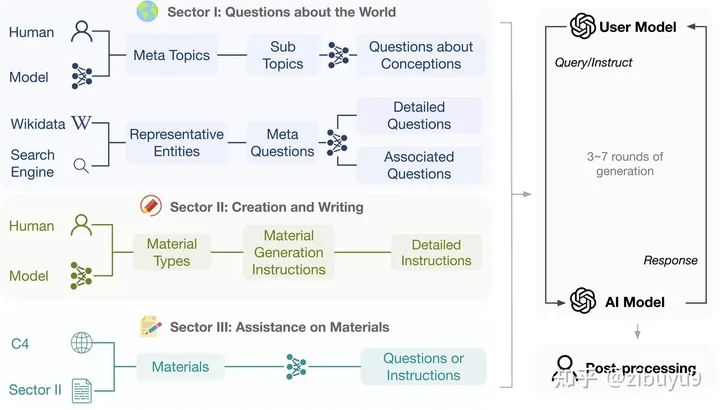
工具學(xué)習(xí)有望解決模型時(shí)效性不足的問(wèn)題,增強(qiáng)專(zhuān)業(yè)知識(shí),提高可解釋性。而大模型在理解復(fù)雜數(shù)據(jù)和場(chǎng)景方面,已經(jīng)初步具備類(lèi)人的推理規(guī)劃能力,大模型工具學(xué)習(xí)(Tool Learning)[1] 范式應(yīng)運(yùn)而生。該范式核心在于將專(zhuān)業(yè)工具與大模型優(yōu)勢(shì)相融合,實(shí)現(xiàn)更高的準(zhǔn)確性、效率和自主性。目前,已有 WebGPT / WebCPM [2, 3] 等工作成功讓大模型學(xué)會(huì)使用搜索引擎,像人一樣網(wǎng)上沖浪,有針對(duì)性地獲取有用信息進(jìn)而完成特定任務(wù)。
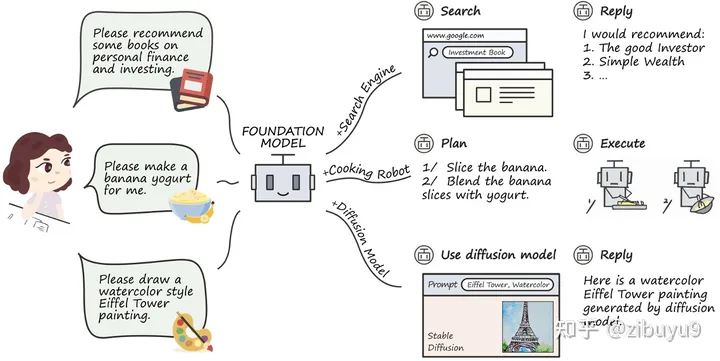
最近,ChatGPT Plugins的出現(xiàn)使其支持使用聯(lián)網(wǎng)和數(shù)學(xué)計(jì)算等工具,被稱(chēng)為OpenAI的“App Store”時(shí)刻。工具學(xué)習(xí)必將成為大模型的重要探索方向,為了支持開(kāi)源社區(qū)對(duì)大模型工具學(xué)習(xí)能力的探索,我們開(kāi)發(fā)了工具學(xué)習(xí)引擎 BMTools[4],它是一個(gè)基于大語(yǔ)言模型的開(kāi)源可擴(kuò)展工具學(xué)習(xí)平臺(tái),將各種工具(如文生圖模型、搜索引擎、股票查詢等)的調(diào)用流程都統(tǒng)一在了同一個(gè)框架下,實(shí)現(xiàn)了工具調(diào)用流程的標(biāo)準(zhǔn)化和自動(dòng)化。開(kāi)發(fā)者可以通過(guò)BMTools,使用給定的大模型API(如ChatGPT、GPT-4)或開(kāi)源模型調(diào)用各類(lèi)工具接口完成任務(wù)。
此外,現(xiàn)有大部分努力都集中在單個(gè)預(yù)訓(xùn)練模型的能力提升上,而在單個(gè)大模型已經(jīng)比較能打的基礎(chǔ)上,未來(lái)將開(kāi)啟從單體智能到多體智能的飛躍,實(shí)現(xiàn)多模型間的交互、協(xié)同或競(jìng)爭(zhēng)。例如,最近斯坦福大學(xué)構(gòu)建了一個(gè)虛擬小鎮(zhèn),小鎮(zhèn)中的人物由大模型扮演 [5],在大模型的加持下,不同角色在虛擬沙盒環(huán)境中可以很好地互動(dòng)或協(xié)作,展現(xiàn)出了一定程度的社會(huì)屬性。多模型的交互、協(xié)同與競(jìng)爭(zhēng)將是未來(lái)極具潛力的研究方向。目前,構(gòu)建多模型交互環(huán)境尚無(wú)成熟解決方案,為此我們開(kāi)發(fā)了開(kāi)源框架AgentVerse [6],支持研究者通過(guò)簡(jiǎn)單的配置文件和幾行代碼搭建多模型交互環(huán)境。同時(shí),AgentVerse與BMTools實(shí)現(xiàn)聯(lián)動(dòng),通過(guò)在配置文件中添加工具鏈接,即可為模型提供工具,從而實(shí)現(xiàn)有工具的多模型交互。未來(lái),我們甚至可能雇傭一個(gè)“大模型助理團(tuán)隊(duì)”來(lái)協(xié)同調(diào)用工具,共同解決復(fù)雜問(wèn)題。

參考文獻(xiàn)
[1] Qin, Yujia, et al. "Tool Learning with Foundation Models." arXiv preprint arXiv:2304.08354 (2023).
[2] Nakano, Reiichiro, et al. "Webgpt: Browser-assisted question-answering with human feedback." arXiv preprint arXiv:2112.09332 (2021).
[3] Qin, Yujia, et al. "WebCPM: Interactive Web Search for Chinese Long-form Question Answering." arXiv preprint arXiv:2305.06849 (2023).
[4] BMTools: https://github.com/OpenBMB/BMTools
[5] Park, Joon Sung, et al. "Generative agents: Interactive simulacra of human behavior." arXiv preprint arXiv:2304.03442 (2023).
[6] AgentVerse: https://github.com/OpenBMB/Agen
方向八:大模型的創(chuàng)新應(yīng)用問(wèn)題
大模型在眾多領(lǐng)域的有著巨大的應(yīng)用潛力。近年來(lái)《Nature》封面文章已經(jīng)出現(xiàn)了五花八門(mén)的各種應(yīng)用,大模型也開(kāi)始在這當(dāng)中扮演至關(guān)重要的角色[2,3]。這方面一個(gè)耳熟能詳?shù)墓ぷ骶褪茿lphaFold,對(duì)整個(gè)蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)產(chǎn)生了天翻地覆的影響。
未來(lái)在這個(gè)方向上,關(guān)鍵問(wèn)題就是如何將領(lǐng)域知識(shí)加入AI擅長(zhǎng)的大規(guī)模數(shù)據(jù)建模以及大模型生成過(guò)程中,這是利用大模型進(jìn)行創(chuàng)新應(yīng)用的重要命題。
在這一點(diǎn)上,我們已經(jīng)在法律智能、生物醫(yī)學(xué)展開(kāi)了一些探索。例如,早在2021年與冪律智能聯(lián)合推出了首個(gè)中文法律智能預(yù)訓(xùn)練模型 Lawformer,能夠更好地處理法律領(lǐng)域的長(zhǎng)篇文書(shū);我們也提出了能夠同時(shí)建模化學(xué)表達(dá)式和自然語(yǔ)言的統(tǒng)一預(yù)訓(xùn)練模型KV-PLM,在特定生物醫(yī)學(xué)任務(wù)上能夠超過(guò)人類(lèi)專(zhuān)家,相關(guān)成果曾發(fā)表在《自然-通訊》(Nature Communications)上并入選編輯推薦專(zhuān)欄(Editor's Highlights)。

參考文獻(xiàn)
[1] Zeng, Zheni, et al. A deep-learning system bridging molecule structure and biomedical text with comprehension comparable to human professionals. Nature communications 13.1 (2022): 862.
[2] Jumper, John, et al. Highly accurate protein structure prediction with AlphaFold. Nature 596.7873 (2021): 583-589.
[3] Assael, Yannis, et al. Restoring and attributing ancient texts using deep neural networks. Nature 603.7900 (2022): 280-283.
[4] Xiao, et al. Lawformer: A pre-trained language model for Chinese legal long documents. AI Open, 2021.
方向九:大模型的數(shù)據(jù)和評(píng)估問(wèn)題
縱觀深度學(xué)習(xí)和大模型的發(fā)展歷程,持續(xù)驗(yàn)證了“更多數(shù)據(jù)帶來(lái)更多智能”(More Data, More Intelligence)原則的普適性。從多種模態(tài)數(shù)據(jù)中學(xué)習(xí)更加開(kāi)放和復(fù)雜的知識(shí),將會(huì)是未來(lái)拓展大模型能力邊界及提升智能水平的重要途徑。近期OpenAI的GPT-4[1]在語(yǔ)言模型的基礎(chǔ)上拓展了對(duì)視覺(jué)信號(hào)的深度理解,谷歌的PaLM-E[2]則進(jìn)一步融入了機(jī)器人控制的具身信號(hào)。概覽近期的前沿動(dòng)態(tài),一個(gè)正在成為主流的技術(shù)路線是以語(yǔ)言大模型為基底,融入其他模態(tài)信號(hào),從而將語(yǔ)言大模型中的知識(shí)和能力吸納到多模態(tài)計(jì)算中。
在這個(gè)方面,我們的近期工作[3]發(fā)現(xiàn)通過(guò)在不同語(yǔ)言大模型基底間遷移視覺(jué)模塊,可以極大降低預(yù)訓(xùn)練多模態(tài)大模型的開(kāi)銷(xiāo)。我們近期實(shí)驗(yàn)表明,基于剛開(kāi)源的百億中英雙語(yǔ)基礎(chǔ)模型CPM-Bee,能夠支持很快訓(xùn)練得到多模態(tài)大模型,圍繞圖像在開(kāi)放域下進(jìn)行中英多模態(tài)對(duì)話,與人類(lèi)交互有不錯(cuò)表現(xiàn)。面向未來(lái),從更多模態(tài)更大規(guī)模數(shù)據(jù)中學(xué)習(xí)知識(shí),是大模型技術(shù)發(fā)展的必由之路。另一方面,大模型建得越來(lái)越大,結(jié)構(gòu)種類(lèi)、數(shù)據(jù)源種類(lèi)、訓(xùn)練目標(biāo)種類(lèi)也越來(lái)越多,這些模型的性能提升到底有多少?在哪些方面我們?nèi)孕枧Γ坑嘘P(guān)大模型性能評(píng)價(jià)的問(wèn)題,我們需要一個(gè)科學(xué)的標(biāo)準(zhǔn)去判斷大模型的長(zhǎng)處和不足。
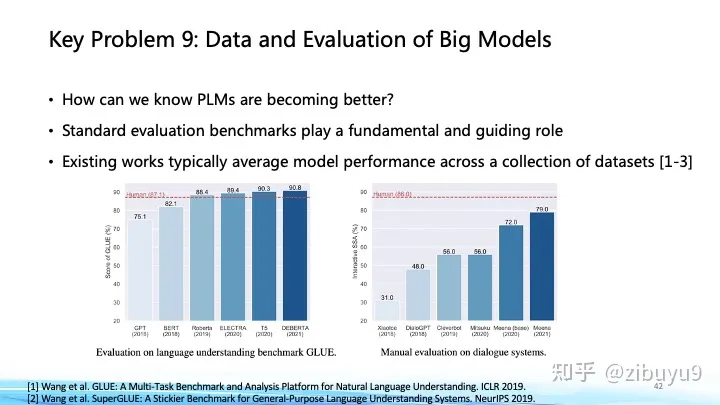
這在ChatGPT出現(xiàn)前就已經(jīng)是重要的命題,像GLUE、SuperGLUE等評(píng)價(jià)集合都深遠(yuǎn)地影響了預(yù)訓(xùn)練模型的發(fā)展;對(duì)此,我們也曾在過(guò)去幾年里推出過(guò) CUGE 中文理解與生成評(píng)價(jià)集合 [4],通過(guò)逐層匯集模型在不同指標(biāo)、數(shù)據(jù)集、任務(wù)和能力上的得分系統(tǒng)地評(píng)估模型在不同方面的表現(xiàn)。這種基于自動(dòng)匹配答案評(píng)測(cè)的方式是大模型和生成式AI興起前自然語(yǔ)言處理領(lǐng)域主要的評(píng)測(cè)方式,優(yōu)點(diǎn)在于評(píng)價(jià)標(biāo)準(zhǔn)固定、評(píng)測(cè)速度快。而對(duì)于生成式AI,模型傾向于生成發(fā)散性強(qiáng)、長(zhǎng)度較長(zhǎng)的內(nèi)容,使用自動(dòng)化評(píng)測(cè)指標(biāo)很難對(duì)生成內(nèi)容的多樣性、創(chuàng)造力進(jìn)行評(píng)估,于是帶來(lái)了新的挑戰(zhàn)與研究機(jī)會(huì),最近出現(xiàn)的大模型評(píng)價(jià)方式可以大致分為以下幾類(lèi):
自動(dòng)評(píng)價(jià)法:很多研究者提出了新的自動(dòng)化評(píng)估方式,譬如通過(guò)選擇題的形式[5],收集人類(lèi)從小學(xué)到大學(xué)的考試題以及金融、法律等專(zhuān)業(yè)考試題目,讓大模型直接閱讀選項(xiàng)給出回答從而能夠自動(dòng)評(píng)測(cè),這種方式比較適合評(píng)測(cè)大模型在知識(shí)儲(chǔ)備、邏輯推理、語(yǔ)義理解等維度的能力。
模型評(píng)價(jià)法:也有研究者提出使用更加強(qiáng)大的大模型來(lái)做裁判[6]。譬如直接給GPT4等模型原始問(wèn)題和兩個(gè)模型的回答,通過(guò)編寫(xiě)提示詞讓GPT4扮演打分裁判,給兩個(gè)模型的回答進(jìn)行打分。這種方式會(huì)存在一些問(wèn)題,譬如效果受限于裁判模型的能力,裁判模型會(huì)偏向于給某個(gè)位置的模型打高分等,但優(yōu)勢(shì)在于能夠自動(dòng)執(zhí)行,不需要評(píng)測(cè)人員,對(duì)于模型能力的評(píng)判可以提供一定程度的參考。
人工評(píng)價(jià)法:人工評(píng)測(cè)是目前來(lái)看更加可信的方法,然而因?yàn)樯蓛?nèi)容的多樣性,如何設(shè)計(jì)合理的評(píng)價(jià)體系、對(duì)齊不同知識(shí)水平的標(biāo)注人員的認(rèn)知也成為了新的問(wèn)題。目前國(guó)內(nèi)外研究機(jī)構(gòu)都推出了大模型能力的“競(jìng)技場(chǎng)”,要求用戶對(duì)于相同問(wèn)題不同模型的回答給出盲評(píng)。這里面也有很多有意思的問(wèn)題,譬如在評(píng)測(cè)過(guò)程中,是否可以設(shè)計(jì)自動(dòng)化的指標(biāo)給標(biāo)注人員提供輔助?一個(gè)問(wèn)題的回答是否可以從不同的維度給出打分?如何從網(wǎng)絡(luò)眾測(cè)員中選出相對(duì)比較靠譜的答案?這些問(wèn)題都值得實(shí)踐與探索。

參考文獻(xiàn)
[1] OpenAI. GPT-4 Technical Report. 2023.
[2] Driess D, Xia F, Sajjadi M S M, et al. PaLM-E: An embodied multimodal language model[J]. arXiv preprint arXiv:2303.03378, 2023.
[3] Zhang A, Fei H, Yao Y, et al. Transfer Visual Prompt Generator across LLMs[J]. arXiv preprint arXiv:2305.01278, 2023.
[4] Yao Y, Dong Q, Guan J, et al. Cuge: A chinese language understanding and generation evaluation benchmark[J]. arXiv preprint arXiv:2112.13610, 2021.
[5] Chiang, Wei-Lin et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. 2023.
[6] Huang, Yuzhen et al. C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv preprint arXiv:2305.08322, 2023.
方向十:大模型的易用性問(wèn)題
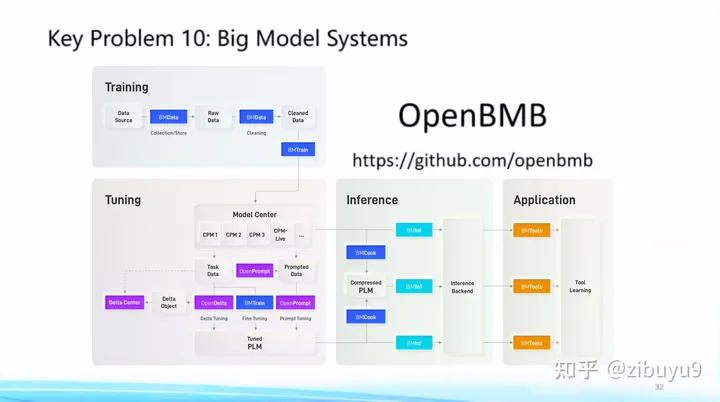
大模型已呈現(xiàn)出強(qiáng)烈的通用性趨勢(shì),具體體現(xiàn)為日益統(tǒng)一的Transformer網(wǎng)絡(luò)架構(gòu),以及各領(lǐng)域日益統(tǒng)一的基礎(chǔ)模型,這為建立標(biāo)準(zhǔn)化的大模型系統(tǒng)(Big Model Systems),將人工智能能力低門(mén)檻地部署到各行各業(yè)帶來(lái)可能性。受到計(jì)算機(jī)發(fā)展史上成功實(shí)現(xiàn)標(biāo)準(zhǔn)化的數(shù)據(jù)庫(kù)系統(tǒng)和大數(shù)據(jù)分析系統(tǒng)的啟發(fā),我們應(yīng)當(dāng)將復(fù)雜的高效算法封裝在系統(tǒng)層,而為系統(tǒng)用戶提供易懂而強(qiáng)大的接口。
正是遵循這樣的理念,我們從2021年開(kāi)始提出“讓大模型飛入千家萬(wàn)戶”的目標(biāo)建設(shè) OpenBMB開(kāi)源社區(qū),全稱(chēng)Open Lab for Big Model Base,陸續(xù)發(fā)布了一套覆蓋訓(xùn)練、微調(diào)、壓縮、推理、應(yīng)用的全流程高效計(jì)算工具體系,目前包括 高效訓(xùn)練工具 BMTrain、高效壓縮工具 BMCook、低成本推理工具 BMInf、工具學(xué)習(xí)引擎 BMTools,等等。OpenBMB大模型系統(tǒng)完美支持我們自研的中文大模型CPM系列,最近也剛剛開(kāi)源了最新版本百億中英雙語(yǔ)基礎(chǔ)模型CPM-Bee。在我看來(lái),大模型不僅要自身性能好,還要有強(qiáng)大工具體系讓它好用,因此我們接下來(lái)將繼續(xù)深耕 CPM 大模型和 OpenBMB 大模型工具體系,力爭(zhēng)做中文世界最好的大模型系統(tǒng)。歡迎大家使用它們并提出建議和意見(jiàn),共同建設(shè)這個(gè)屬于我們大家的大模型開(kāi)源社區(qū)。
致謝:感謝實(shí)驗(yàn)室同學(xué)提供了部分技術(shù)細(xì)節(jié)的介紹。
審核編輯 :李倩
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5512瀏覽量
121460 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13625 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22090 -
LLM
+關(guān)注
關(guān)注
0文章
298瀏覽量
388
原文標(biāo)題:劉知遠(yuǎn)老師高鐵上回應(yīng):大模型LLM領(lǐng)域,有哪些可以作為學(xué)術(shù)研究方向?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
工程領(lǐng)域學(xué)術(shù)研究的基本規(guī)律和原則
晶體管可以作為開(kāi)關(guān)使用!
2023年LLM大模型研究進(jìn)展
大語(yǔ)言模型(LLM)快速理解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論