 AGIEval:準確考察基礎模型類人能力的基準評估工具
AGIEval:準確考察基礎模型類人能力的基準評估工具
對基礎模型在處理人類任務時的一般能力做出準確評估,已經成為通用人工智能(AGI)開發和應用領域的一大重要問題。基于人工數據集的傳統基準往往無法準確反映模型能力是否達到人類水平。
近日,微軟的一個華人研究團隊發布了一項新型基準測試 AGIEval,這項基準測試專門用于對基礎模型的類人能力做準確考察(涵蓋高考、法學入學考試、數學競賽和律師資格考試等)。
該研究團隊使用此項基準評估了當前最先進的多個基礎模型,包括 GPT-4、ChatGPT 和 Text-Davinci-003 等。
令人印象深刻的是,GPT-4 在 SAT、LSAT 和數學競賽中的表現均超過人類平均水平,在 SAT 數學測試中達成 95% 的準確率,在中國高考英語測試中準確率亦達到 92.5%,證明了當代基礎模型的非凡性能。
與之對應,研究人員發現 GPT-4,在需要復雜推理或涉及特定領域知識的任務中表現尚不理想。
通過對模型能力(理解、知識、推理和計算等)的全面分析,有助于揭示這些模型的優勢和局限性,為增強其通用能力的未來發展方向提供支持。通過測試涉及人類認知和決策能力的任務,AGIEval 能夠對基礎模型在現實場景中的性能做出更可靠、更有意義的評估。
測試中的全部數據、代碼和模型輸出均通過此 https URL(https://github.com/microsoft/AGIEval)發布。
AGIEval 項目介紹
AGIEval 是一項考察基礎模型類人能力的基準測試,專門用于評估基礎模型在人類認知和問題解決相關任務中表現出的一般能力。
該基準選取 20 種面向普通人類考生的官方、公開、高標準往常和資格考試,包括普通大學入學考試(中國高考和美國 SAT 考試)、法學入學考試、數學競賽、律師資格考試、國家公務員考試等等。
關于此基準的完整描述,請參閱論文《AGIEval:準確考察基礎模型類人能力的基準評估工具》(https://arxiv.org/pdf/2304.06364.pdf)。
任務與數據
AGIEval v1.0 包含 20 項任務,具體為 2 項完形填空任務(高考數學)和 18 項多選題回答任務。在選擇題部分,高物理和 JEC-QA 部分對應一個或多個正確答案,其余任務則僅有一個正確答案。
下表所示,為測試題目的完整列表。
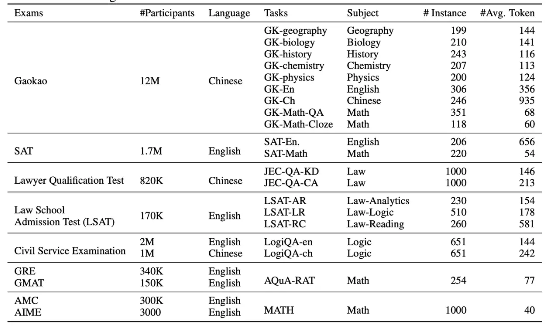
可以在 data/v1 文件夾內下載到除 JEC-QA 以外的所有后處理數據。關于 JEC-QA 部分,請前往 JEC-QA 網站獲取數據。
使用 JEC-QA 訓練數據的前 1000 個實例作為測試集。所有數據集的數據格式如下:
{
"passage": null,
"question": "設集合 $A=\{x \mid x \geq 1\}, B=\{x \mid-1-1\}$",
"(B)$\{x \mid x \geq 1\}$",
"(C)$\{x \mid-1
其中高考語言、高考英語、兩科 logiqa、全部 LSAT 和 SAT 均可使用 passage 字段。多選任務的答案保存在 label 字段內。完形填空任務的答案保存在 answer 字段內。
我們還在 data/v1/few_shot_prompts 文件中提供了小樣本學習的提示詞。
基線系統
我們在 AGIEval v1.0 上評估了基準系統的性能。基線系統基于以下模型:text-davinci-003、ChatGPT (gpt-3.5-turbo) 和 GPT-4。您可以按照以下步驟重現測試結果:
1.在 openai_api.py 文件中填寫您的 OpenAI API 密鑰。
2.運行 run_prediction.py 文件以獲取結果。
模型輸出
?您可以在 Onedrive 鏈接(https://1drv.ms/u/s!Amt8n9AJEyxcg8YQKFm1rSEyV9GU_A?e=VEfJVS)中下載到基線系統的零樣本、零樣本思維鏈、少樣本和少樣本思維鏈輸出。請注意,我們修復了 SAT-en 實例中的 52 處拼寫錯誤,并將很快發布更新后的數據集輸出。?
評估
您可以運行 post_process_and_evaluation.py 文件來獲取評估結果。
引用
如果您需要在研究中使用 AGIEval 數據集或代碼,請引用論文:
@misc{zhong2023agieval,
title={AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models},
author={Wanjun Zhong and Ruixiang Cui and Yiduo Guo and Yaobo Liang and Shuai Lu and Yanlin Wang and Amin Saied and Weizhu Chen and Nan Duan},
year={2023},
eprint={2304.06364},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
在使用時,請務必在您的論文中引用所有獨立數據集。我們提供以下引用信息:
@inproceedings{ling-etal-2017-program,
title = "Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems",
author = "Ling, Wang and
Yogatama, Dani and
Dyer, Chris and
Blunsom, Phil",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P17-1015",
doi = "10.18653/v1/P17-1015",
pages = "158--167",
abstract = "Solving algebraic word problems requires executing a series of arithmetic operations{---}a program{---}to obtain a final answer. However, since programs can be arbitrarily complicated, inducing them directly from question-answer pairs is a formidable challenge. To make this task more feasible, we solve these problems by generating answer rationales, sequences of natural language and human-readable mathematical expressions that derive the final answer through a series of small steps. Although rationales do not explicitly specify programs, they provide a scaffolding for their structure via intermediate milestones. To evaluate our approach, we have created a new 100,000-sample dataset of questions, answers and rationales. Experimental results show that indirect supervision of program learning via answer rationales is a promising strategy for inducing arithmetic programs.",
}
@inproceedings{hendrycksmath2021,
title={Measuring Mathematical Problem Solving With the MATH Dataset},
author={Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt},
journal={NeurIPS},
year={2021}
}
@inproceedings{Liu2020LogiQAAC,
title={LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning},
author={Jian Liu and Leyang Cui and Hanmeng Liu and Dandan Huang and Yile Wang and Yue Zhang},
booktitle={International Joint Conference on Artificial Intelligence},
year={2020}
}
@inproceedings{zhong2019jec,
title={JEC-QA: A Legal-Domain Question Answering Dataset},
author={Zhong, Haoxi and Xiao, Chaojun and Tu, Cunchao and Zhang, Tianyang and Liu, Zhiyuan and Sun, Maosong},
booktitle={Proceedings of AAAI},
year={2020},
}
@article{Wang2021FromLT,
title={From LSAT: The Progress and Challenges of Complex Reasoning},
author={Siyuan Wang and Zhongkun Liu and Wanjun Zhong and Ming Zhou and Zhongyu Wei and Zhumin Chen and Nan Duan},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
year={2021},
volume={30},
pages={2201-2216}
}
審核編輯 :李倩
-
人工智能
+關注
關注
1796文章
47643瀏覽量
239984 -
數據集
+關注
關注
4文章
1209瀏覽量
24803 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
8006
原文標題:AGIEval:準確考察基礎模型類人能力的基準評估工具
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
兩大AI模型性能提升 登上國際榜單

SPEC ML基準測試新增模算效率指標
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
阿里云開源Qwen2.5-Coder代碼模型系列

如何評估 ChatGPT 輸出內容的準確性
如何評估AI大模型的效果
【每天學點AI】人工智能大模型評估標準有哪些?

怎么判斷電源的最大負載能力?帶載測試方式助您準確評估
NVIDIA文本嵌入模型NV-Embed的精度基準
Al大模型機器人
商湯小浣熊榮獲中國信通院代碼大模型能力評估“三好生”

【大語言模型:原理與工程實踐】大語言模型的評測
Aigtek:衡量基準電壓源的技術指標有哪些






 工商網監
工商網監
評論