

摘要
本文主要評估了ChatGPT這種大型語言模型在信息提取方面的能力,作者使用了7個細粒度的信息提取任務來評估ChatGPT的性能、可解釋性、校準度和可信度。
作者發現,在標準信息提取設置下,ChatGPT的性能較差,但在開放式信息提取設置下表現出色,且其決策的解釋具有高質量和可信度。
不過,ChatGPT存在過度自信的問題,導致其校準度較低。此外,ChatGPT在大多數情況下對原始文本的忠實度很高。
最后,作者手動注釋并發布了7個細粒度信息提取任務的測試集,包含14個數據集,以進一步促進研究。
主要思路
ChatGPT是最近非常流行的對話大模型,可以與用戶進行流暢和高效的交流。但是由于ChatGPT的訓練細節和數據沒有完全公開,并且ChatGPT的輸出會帶有一些觀點和偏向,這些觀點都可能會影響用戶對事物的判斷和決策,甚至對用戶造成負面作用[1-4]。
因此,對于ChatGPT的評測方面,不止需要關注給定下游任務的性能評測,同時還需要考慮到使用大模型過程中用戶可能需要的一些方面,如ChatGPT對決策判斷的可解釋、預測自信程度和對于輸入原文的忠實程度等。
基于以上分析,本文希望在ChatGPT性能的基礎上,通過更多的維度對ChatGPT模型的能力進行全方位的評估。
具體來說,我們希望通過以下4個方面來評估ChatGPT的綜合性能:
1)性能(Performance)。我們研究的一個重要方面是全面評估ChatGPT在各種任務上的整體性能,如準確率和F1值等。并將其與其他熱門模型進行比較。通過從不同角度考察其性能,我們旨在提供對ChatGPT在下游信息提取任務方面能力的詳細理解。
2)可解釋性(Explainability)。ChatGPT的可解釋性對于其在現實場景中應用是至關重要的[5-7],因為用戶希望在獲取模型輸出的同時,讓模型給出合理的預測理由和判斷依據。在我們的研究中,我們將同時衡量ChatGPT的自我檢查和人工檢查的可解釋性,重點關注其為人類提供有用和準確的推理過程解釋的能力。
3)校準性(Calibration)。測量“calibration”有助于評估模型的預測不確定性[8,9]。校準度高的分類器應該具有準確反映正確性概率的預測分數[10,11]。鑒于深度神經網絡在其預測中表現出過度自信的傾向,我們期望識別ChatGPT的潛在不確定性或過度自信現象。
4)忠誠度(Faithfulness)。模型對預測解釋的忠誠度對于用戶而言非常重要[12,13]。我們嘗試評估ChatGPT提供的解釋是否與輸入內容一致。
基于以上四個方面,我們設計了15個不同的評測指標,其中10個為ChatGPT自動輸出的指標,5個為多位領域專家人工標注的指標。具體指標如下:
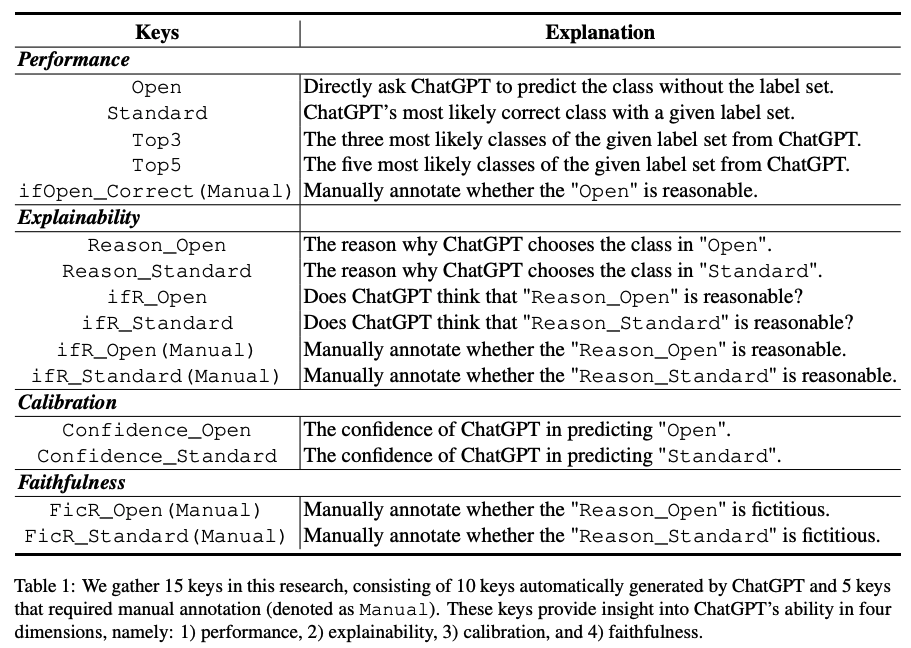
任務數據集及實驗設置
我們選擇了自然語言處理中十分重要的研究任務——信息抽取,作為任務載體,對ChatGPT的以上度量指標進行全方位的評估。信息抽取(information extraction, IE)涉及異構結構提取、事實知識使用和多樣化的目標,因此此類任務是評估ChatGPT能力的理想場景。本文中,我們選擇了7個信息抽取任務共14個數據集進行測試,包括是實體識別,關系抽取和事件抽取等。
在實驗過程中,我們采用了2種設置,即標準信息抽取(Standard-IE)和開放式信息抽取(OpenIE)。Standard-IE設置通常用于以前的工作中,它使用特定于任務的數據集與監督式學習范式對模型進行微調。對于ChatGPT,由于我們無法直接微調參數,因此我們評估ChatGPT從一組候選標簽中選擇最合適答案的能力。具體而言,這種設置基于包括任務描述、輸入文本、提示和標簽集的指示。任務描述描述了具體的IE任務,提示包括引導ChatGPT輸出所需特征(即上述15個特征中的一個或多個),而標簽集基于每個數據集包含所有候選標簽。OpenIE設置是比Standard-IE設置更高級和具有挑戰性的情境。在此設置中,我們不會向ChatGPT提供任何候選標簽,僅依賴其理解任務描述、提示和輸入文本的能力來生成預測。我們的目標是評估ChatGPT生成合理事實知識的能力。實驗結果對比的模型包括BERT、RoBERTa和每個任務的SOTA模型。
實驗結果及結論
1)Standard-IE設置
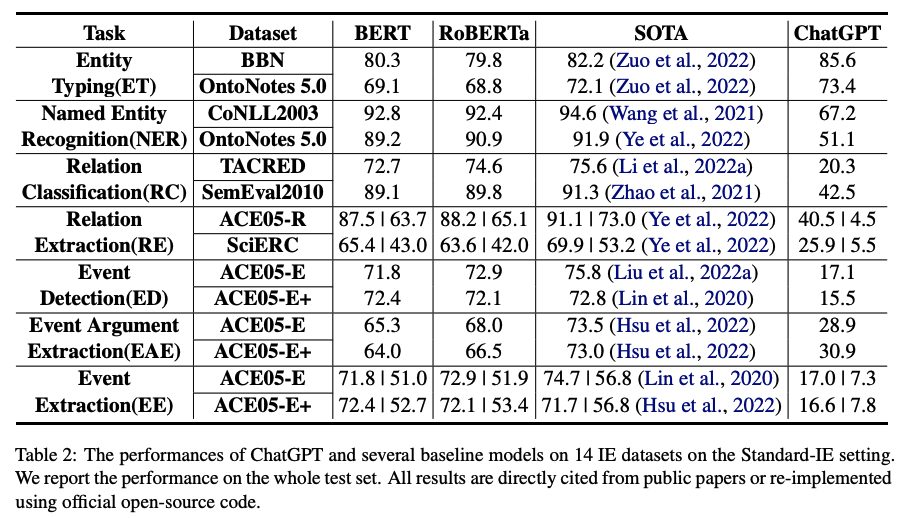
主要結論:
1)在大部分情況下,ChatGPT的性能與BERT類模型和SOTA模型的性能差距較大;
2)在簡單任務,如entity typing和relation classification問題下,ChatGPT的性能較好。
2)Open-IE設置
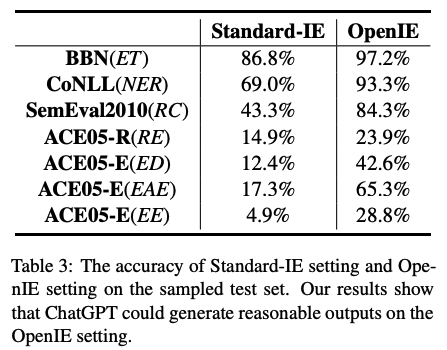
主要結論:
ChatGPT在開放式信息抽取設置下,輸出的結果較為令人滿意,在很多任務上能夠在大多數情況下輸出人類認可的結果。這說明ChatGPT已經學習了很多正確且可以合理輸出的常識知識。
3)可解釋性
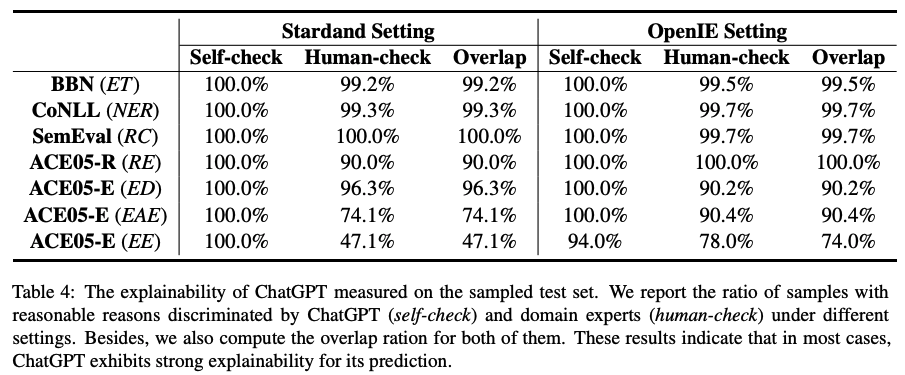
主要結論:
通過ChatGPT和人工對給出的判斷理由進行標注,我們發現ChatGPT輸出的解釋非常可靠,絕大多數情況下,人類與ChatGPT都認為給出的理由是合理的。以上數據表明,ChatGPT對于自己預測的解釋可信度較高。
4)校準度
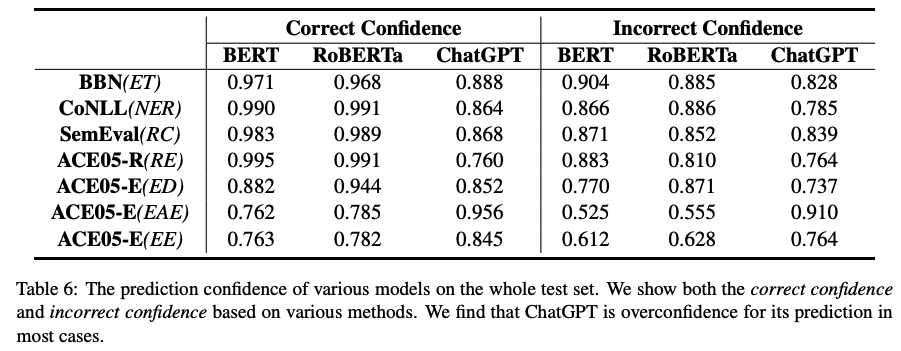
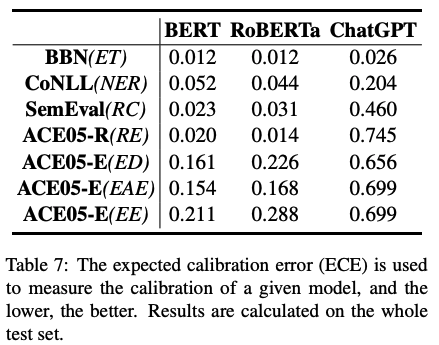
主要結論:
1)表6展示的是各個模型預測的置信度,可以看出,BERT類模型和ChatGPT對于自己的預測都十分自信,均給出了很高的置信度。相比而言,因為ChatGPT在Standard-IE中其性能不佳,所以給出這么高的置信度表明模型有很嚴重的過度自信傾向。同時,模型對于預測錯誤的樣本,置信度明顯較低。也就是說,當模型給出的預測置信度較低時,應該對預測結果進行校驗。
2)表7通過評估校準度的指標ECE,我們可以明顯看出ChatGPT有最低的校準度,即預測置信度偏高,過度自信問題嚴重。
5)忠實度
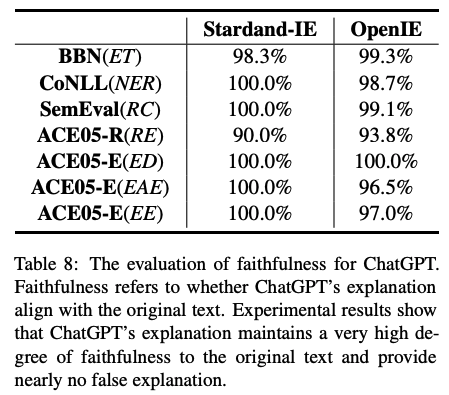
主要結論:
通過領域專家對模型輸出解釋和輸入原文的對比,進行了人工的忠實度度量。我們發現,ChatGPT的解釋是非常忠實于原文的,基本沒有在給定上下文的情況下,通過編造理由進行預測的行為。
總結
本文聚焦于ChatGPT在各種信息抽取任務上的系統性評測。針對于7個細粒度信息抽取任務和14個數據集,從模型性能、可解釋性、校準度和忠實度這四個角度,設計了15個指標(10個從ChatGPT自動獲取的指標,5個領域專家標注的指標),對ChatGPT進行了全面評估。實驗結果表明,ChatGPT在標準IE設置下,性能與有監督模型有很大差距。
但是,ChatGPT在OpenIE的場景下輸出非常符合人類預期。同時,通過領域專家標注表明,ChatGPT可以對自己的預測結果給出可靠的解釋,這表明ChatGPT有極強的解釋能力。但是ChatGPT會對自己的預測過度自信,給出非常高的預測置信度,從而導致較低的校準度。
最后,本文還驗證了ChatGPT的決策非常忠實于原文,即不會通過虛構來解決或者解釋問題。本文說明,ChatGPT在信息抽取領域仍然有很多的改進角度和提升空間。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3448瀏覽量
49707 -
數據集
+關注
關注
4文章
1218瀏覽量
25158 -
ChatGPT
+關注
關注
29文章
1584瀏覽量
8568
原文標題:通過準確性、可解釋性、校準度和忠實度,對ChatGPT的能力進行全面評估
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的評測
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
關于頻率變化的正弦波幅值信息提取
NLPIR在文本信息提取方面的優勢介紹
不到1分鐘開發一個GPT應用!各路大神瘋狂整活,網友:ChatGPT就是新iPhone
基于VB6.0的點陣字模信息提取方法
GPS定位信息提取及應用
基于FPGA的圖像信息提取設計及仿真

ChatGPT在電磁領域的能力到底有多強?






 工商網監
工商網監

評論