

主要貢獻
文本提出了一個全新的隨機Dropping方法,該方法在消息傳遞的過程中直接對被傳遞的消息進行dropping操作,統一了圖神經網絡的隨機dropping架構。
第一章 摘要
圖神經網絡是圖表示學習的重要工具。但盡管圖神經網絡的研究發展迅速,我們依然面臨著很多挑戰,例如:過擬合、過平滑和低魯棒性這些問題。以前的工作表明這些問題可以通過隨機droppping方法得到緩解,即通過隨機遮掩掉部分輸入來將增強數據喂給模型。然而,在圖神經網絡上應用隨機dropping方法仍有很多問題待被解決。首先,考慮到不同數據集和模型的差異,找到一種適用于所有情況的通用方法是很困難的。其次,在圖神經網絡中引入增強數據會導致參數覆蓋不完全和訓練過程不穩定的現象。第三,現今沒有在理論層面上分析隨機dropping方法在圖神經網絡上的有效性。
在本文,我們提出了一個全新的隨機droppping方法——DropMessage,該方法在消息傳遞過程中直接對被傳遞的消息進行dropping操作。更重要的是,我們發現DropMessage為大多數現有的隨機dropping方法提供了一個統一的框架,并在此基礎上我們還對其有效性進行了理論分析,以進一步闡述了DropMessage的優越性:它通過減小樣本方差來穩定訓練過程;從信息論的角度來看,它保持了信息的多樣性,這使其成為其他方法的理論上限。為了評估所提出的DropMessage方法,我們在五個公共數據集和兩個工業數據集上進行了多個任務的實驗。實驗結果表明:DropMessage有效性且泛化性強,能夠顯著緩解上述提到的問題。
第二章 簡介及背景
圖在現實世界里面無處不在,被用于在許多領域中呈現各種事物之間的復雜關系,圖神經網絡更是研究圖表示學習的重要工具。圖神經網絡使用信息傳遞的方法并可以應用到大量的下游任務中。其中消息傳遞就是圖神經網絡在每個卷積層中的各個節點都會聚合其鄰居信息的行為。
但是圖神經網絡的訓練面臨著很多挑戰。因為與其他數據形式相比,為圖數據收集標簽是昂貴的并且會有必然的偏差,這限制了圖神經網絡的泛化能力。此外,由于遞歸地聚合來自其鄰居的信息,圖神經網絡中不同節點的表示往往變得越來越相似。
使用隨機dropping方法可以緩解上述問題,但是摘要中所提到的三大問題依然存在著。在本文,我們提出的全新的隨機Dropping方法DropMessage可以有效解決這些問題。
第三章 數學符號和預備知識
第一節 符號
1. 表示圖
2. ={}表示圖中的節點
3. 表示邊
4. 結點特征表示為矩陣,其中是結點的特征向量,是結點特征的維數
5. 鄰接矩陣表示為 ,其中表示鄰接矩陣的第行,表示結點和之間的關系
6. 結點的度表示為 ,其中表示為連接到結點的度權重之和 7. 信息傳遞矩陣表示為,其中是消息的維數
第二節 消息傳遞的圖神經網絡
圖神經網絡大多采用信息傳遞框架,消息在結點及其鄰居之間傳遞。在傳遞的過程中,結點的表示不斷更新,下面是它的更新公式: 其中表示結點在第 1 層的特征表示;表示結點的鄰居; 和是可微分的函數;AGG代表聚合操作。從信息傳遞的角度來看,我們可以將所有傳播的消息集合到一個消息矩陣中,其表示為:
第四章 方法
第一節DropMessage第一小節 算法描述
不同于現有的隨機dropping方法,DropMessage在消息矩陣上工作而不是鄰接矩陣,即DropMessage直接在消息矩陣M上以概率執行drop操作。具體來說,我們會根據伯努利分布生成一個和消息矩陣同大小的掩碼矩陣,消息矩陣中的每個元素由對應位置的掩碼矩陣中的值來決定以多大的程度被drop,drop之后的消息矩陣表示為:
第二小節 具體實現
在具體實現的過程中,我們不需要額外的時間或空間復雜度來執行DropMessage,因為消息矩陣中的每一行都表示圖中的一條不同的有向邊,并且DropMessage方法可以獨立地在每個有向邊上執行。這個特性使得DropMessage可以有效地并行化。
第三小節 統一隨機dropping方法
引理1 Dropout DropEdge DropNode DropMessage都依據著各自的規則在消息矩陣上執行隨機掩碼對于Dropout方法,Dropping在特征矩陣中的元素等價于遮掩掉消息矩陣中的元素,其中表示所對應的特征矩陣中的那個元素。
對于DropEdge方法,Dropping在鄰接矩陣中的元素等價于遮掩掉消息矩陣中元素,其中表示所對應的邊。
對于DropNode方法,Dropping在特征矩陣X中的元素等價于遮掩掉消息矩陣中的元素,其中表示所對應的特征矩陣中那一行。
那么根據以上的描述,我們發現DropMessage是對消息矩陣進行了最細粒度的屏蔽,這使得它成為最靈活的dropping方法,并且其他方法可以看作是DropMessage的一種特殊形式。
第四小節 DropMessage有效性的理論分析
理論1 圖神經網絡中無偏的隨機dropping將一個額外的正則化項引入到了目標函數中,這使得模型更加魯棒。
證明:為了簡化分析,我們假設下游任務是一個二分類任務,并且我們應用一個簡單的圖卷積神經網絡層,其中是消息矩陣,是轉移矩陣,表示那些應被每個結點聚合的消息且是規模化之后的形式。最后,我們采用一個sigmoid作為激活函數來生成分類的預測結果。并使用交叉熵損失
作為目標函數,于是目標函數的公式如下:
當我們使用隨機dropping的時候,被擾動的代替了原來的消息矩陣。此時目標函數的期望為:
正如上述公式所示,在圖上的隨機dropping方法引入了一個額外的正則化項,這使得模型預測的結果趨近于0或1,因此會有更加清晰的分類判斷。通過減小的方差,隨機dropping方法激勵模型提取更重要的高級表示以提升模型的魯棒性。
第二節 DropMessage的優勢第一小節 減小樣本方差
所有的隨機dropping方法都面臨著訓練不穩定的問題。現有的工作表明,不穩定是由每個訓練輪次的時候引入的隨機噪聲導致的,這些噪聲增加了參數覆蓋的難度和訓練的不穩定性。一般來說,樣本方差被用來衡量穩定程度。而相比于其他方法,DropMessage可以有效減少樣本方差。
理論2 在現有的隨機dropping方法中以相同概率進行drop的情況下,DropMessage表現出最小的樣本方差
證明:隨機dropping方法的樣本方差可以通過計算消息矩陣的范數來衡量。在不失一般性的前提下,我們假設原始的消息矩陣是,即每個元素都是1。因此,我們可以通過消息矩陣的1-范數來計算其樣本方差。
我們認為消息傳遞的GNN沒有結點sampler和邊sampler,這意味著每個有向邊都等價于消息矩陣M中的一個行向量。為了簡化分析,我們假設圖是無向圖,每個結點的度都是。在本例中,消息矩陣的總行數為。所有的隨機dropping方法都可以看作多個獨立的伯努利采樣。整個過程是符合二項分布的,因此我們可以計算出的方差。
對于Dropout來說,執行次的伯努利采樣,在特征矩陣中遮掩一個元素會遮掩消息矩陣中的個元素,方差為
對于DropEdge來說,執行nc次的伯努利采樣,在鄰接矩陣中遮掩一個元素會遮掩消息矩陣中的個元素,方差為
對于DropNode來說,執行n次的伯努利采樣,在邊集合中遮掩一個元素會遮掩消息矩陣中的個元素,方差為
對于DropMessage來說,執行次的伯努利采樣,在消息矩陣中遮掩一個元素會遮掩消息矩陣中的1個元素,方差為
綜上,DropMessage的方差最小。
直覺上,DropMessage獨立地決定了在消息矩陣中的元素掩碼與否,這恰好是隨機dropping消息矩陣的最小伯努利跡。通過減小樣本方差,DropMessage減小了不同訓練輪次的消息矩陣差異,這穩定了訓練并加快了收斂速度。DropMessage具有最小樣本方差的原因是它是GNN模型中最細粒度的隨機dropping方法。在應用DropMessage時會獨立判斷每個元素是否需要屏蔽。
第二小節 保持信息多樣性
我們將從信息論的角度比較不同隨機dropping方法損失信息多樣性的程度。
定義1 信息多樣性包含特征多樣性和拓撲多樣性。我們定義特征多樣性為,這里,指的是對應于來自的邊的行號的切片。信息多樣性定義為,這里,表示信息矩陣,表示集合中元素的個數。
換而言之,特征多樣性被定義為來自不同源結點的保留特征維度的總數;拓撲多樣性被定義為傳播至少一個維度消息的有向邊的總數。根據上述的定義,我們認為只有在隨機dropping后特征多樣性和拓撲多樣性都不減少的方法才具有保持信息多樣性的能力。
引理2 Dropout DropEdge DropNode 都不具有保持信息多樣性的能力
根據定義1,當我們drop掉特征矩陣X中的一個元素時,所有在消息矩陣中對應的元素都會被遮掩掉并且特征多樣性降低1. 當我們drop掉鄰接矩陣中的一條邊時,對應的在消息矩陣無向圖的兩行也會被遮掩掉并且拓撲多樣性降低2.同理,當drop掉一個結點時特征多樣性和拓撲多樣性都會降低。
理論3 當drop率小于等于時,DropMessage可以保持信息多樣性。其中是結點的出度,是特征維度。
證明:DropMessage直接對消息矩陣進行隨機丟棄。為了保持拓撲多樣性,我們期望消息矩陣中每一行至少保留一個元素:
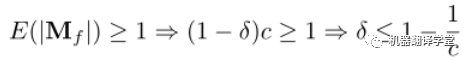
為了保持特征多樣性,我們期望對于特征矩陣中的每個元素,消息矩陣中至少保留一個其對應的元素:
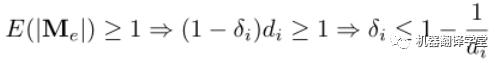
因此,為了滿足上述兩式以保持信息多樣性的drop比例應滿足: 從信息論的角度來看,具有保持信息多樣性能力的隨機dropping方法比沒有這種能力的能保存更多的信息,并在理論分析上其性能也更好。因此,這也解釋了為什么DropMessage比現有的其他方法都要好。實際上,我們只為整個圖設置了一個drop率參數,沒有為每個結點都設置。雖然這樣會使DropMessage損失更多信息,但DropMessage仍然比具有相同drop率的其他方法能保留更多信息。
第五章 實驗
我們在不同的圖神經網絡和不同數據集中比較DropMessage和其他方法,我們主要想驗證:
DropMessage是否在圖神經網絡中優于其他drop方法?
DropMessage是否提升了魯棒性,并讓圖神經網絡的訓練更高效?
定義1中所描述的信息多樣性在圖神經網絡中重要嗎?
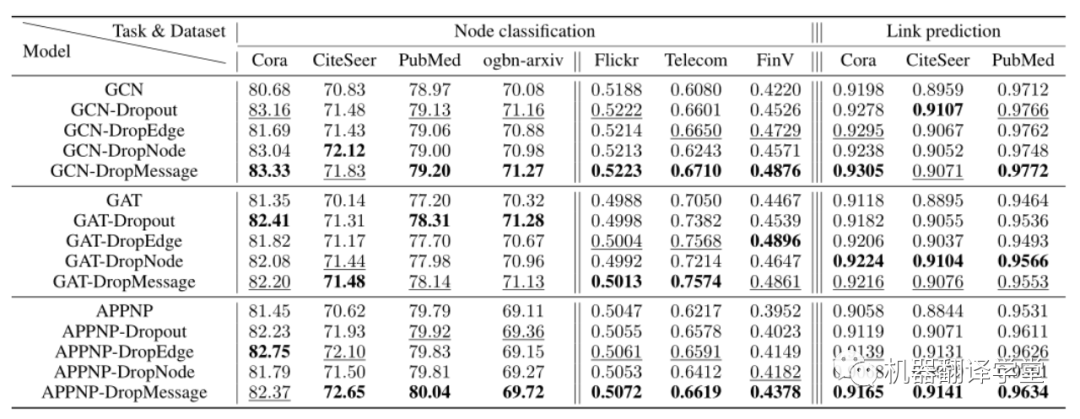
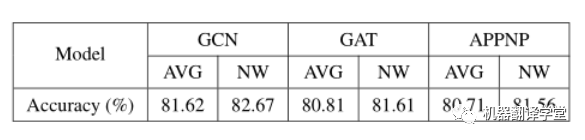
如圖所示,我們使用了三種圖神經網絡(GCN、GAT、APPNP),每種神經網絡都被應用了Dropout、DropEdge、DropNode、DropMessage這四種隨機dropping方法。
通過上述實驗,我們得出以下結論:
DropMessage優于其他隨機dropping方法。在結點分類任務下的21個實驗設置中DropMessage在15個設置中取得最好的實驗結果,在剩下6個設置中取得次好的實驗結果;在鏈路預測任務下的9個實驗設置中DropMessage在5個設置中取得最好的實驗結果,在剩下4個設置中取得次好的實驗結果。
DropMessage 在不同的數據集中的表現十分穩定。而以DropEdge為反例,我們可以看出其在工業數據集(FinV和Telecom)上表現出色,但在其余的公開數據集上表現差勁。我們認為是得益于DropMessage細粒度的drop策略使其有更小的歸納偏置,也因此更適用于大多數的場景。
除了上述實驗,我們還做了更多的實驗分析:
一、 魯棒性分析
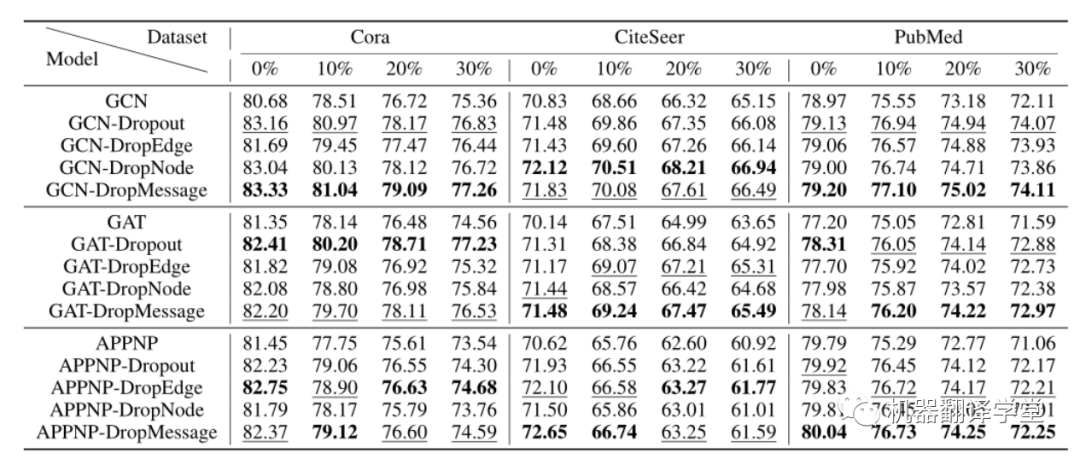
我們通過測量隨機dropping方法處理每個擾動圖的能力來研究它的魯棒性。為了保證初始數據相對干凈,我們在Cora、CiteSeer和PubMed這三個數據集上進行了實驗。我們在這些數據集中隨機添加一定比例的邊,并進行節點分類任務。我們發現,當擾動率從0%增加到30%時,所有的隨機掉落方法都有正向的效果。與沒有攝動的情況相比,在30%擾動的情況下,平均提高了37%,這表明隨機掉落方法增強了圖神經網絡模型的魯棒性。此外,我們所提出的DropMessage顯示了它的通用性,并優于其他方法。
二、 過平滑分析
過平滑指的是隨著網絡深度的增加,結點的表示越來越難以區分。在這一部分中,我們評估了各種隨機dropping方法對這個問題的影響,并通過MADGap測量了過度平滑的程度(Chenet al. 2020),其值越小結點的表示越難以區分。
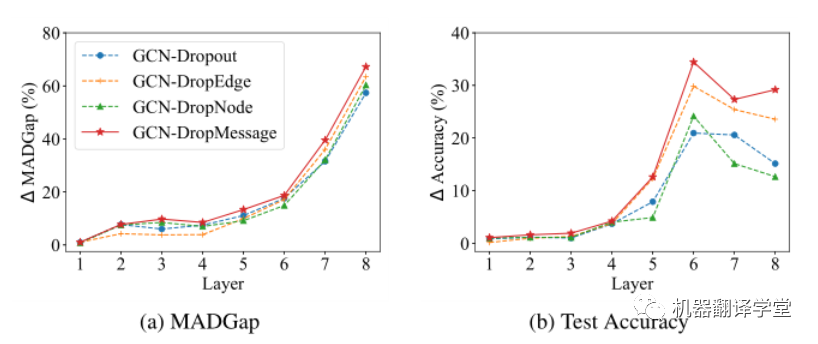
A圖表明隨著模型深度的增加,隨機dropping方法都可以增加MADGap值;B圖表明隨著模型深度的增加,隨機dropping方法都可以提高測試準確率。但是在這些隨機dropping方法DropMessage的表現是最佳的。當層數l≥3時,與其他隨機掉落方法相比,其MADGap值平均提高3.3%,測試準確率平均提高4.9%。這個結果可以說明DropMessage比其他方法生成了更多不同的消息,這在一定程度上阻止了節點收斂到相同的表示上。
三、 訓練過程分析
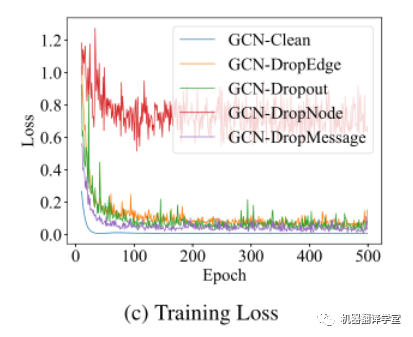
我們分析了不同隨機dropping方法在訓練過程中的損失變化。C圖是Cora數據集上不同隨機dropping方法應用于GCN網絡的損失曲線。這個實驗結果說明DropMessage有最小的樣本方差,因此收斂得更快且具有更穩定的性能表現。
四、 信息多樣性分析
我們用Cora數據集來驗證信息多樣性是否重要,Cora數據集有2708個結點,5429條邊,結點的平均度接近于4。根據之前在信息多樣性小節的分析,dropping率的上屆由結點的度和特征維度計算得來。在Cora數據集中特征維度為1433,它比結點的度大得多,因此上屆僅由度來決定。我們用兩個實驗設置來驗證信息多樣性。第一個是結點粒度實驗,它對每個結點應用其dropping率上屆大小的dropping率 。第二個是平均粒度實驗,所有結點的dropping率都是。根據實驗,我們發現結點粒度的效果好于平均粒度,這也就驗證了信息多樣性的重要性。
第六章 結論
本文,我們提出DropMessage,一種更泛化的應用于圖神經網絡的隨機dropping方法。首先,我們統一了隨機dropping方法并分析了它們的性能。其次,我們從理論上說明了DropMessage在穩定訓練過程和保持信息多樣性方面的優勢。由于其對消息矩陣做細粒度的drop操作,DropMessage在大多數情況下顯示出更大的可應用性。最后,通過在五個公共數據集和兩個工業數據集上進行的多任務實驗,我們證明了所提方法的有效性和泛化性。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4796瀏覽量
102190 -
算法
+關注
關注
23文章
4678瀏覽量
94310 -
矩陣
+關注
關注
0文章
428瀏覽量
34917
原文標題:AAAI2023 best paper | DropMessage:統一的圖神經網絡隨機Dropping方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡教程(李亞非)
【PYNQ-Z2試用體驗】神經網絡基礎知識
卷積神經網絡如何使用
【案例分享】ART神經網絡與SOM神經網絡
人工神經網絡實現方法有哪些?
如何構建神經網絡?
神經網絡移植到STM32的方法
一種基于高效采樣算法的時序圖神經網絡系統介紹
基于過擬合神經網絡的混沌偽隨機序列
Adaline神經網絡隨機逼近LMS算法的仿真研究
神經網絡的偽隨機數生成方法
人工神經網絡的原理和多種神經網絡架構方法






 工商網監
工商網監

評論