") Pandas與PySpark強(qiáng)強(qiáng)聯(lián)手,功能與速度齊飛
Pandas與PySpark強(qiáng)強(qiáng)聯(lián)手,功能與速度齊飛
使用Python做數(shù)據(jù)處理的數(shù)據(jù)科學(xué)家或數(shù)據(jù)從業(yè)者,對(duì)數(shù)據(jù)科學(xué)包pandas并不陌生,也不乏像主頁君一樣的pandas重度使用者,項(xiàng)目開始寫的第一行代碼,大多是 import pandas as pd。pandas做數(shù)據(jù)處理可以說是yyds!而他的缺點(diǎn)也是非常明顯,pandas 只能單機(jī)處理,它不能隨數(shù)據(jù)量線性伸縮。例如,如果 pandas 試圖讀取的數(shù)據(jù)集大于一臺(tái)機(jī)器的可用內(nèi)存,則會(huì)因內(nèi)存不足而失敗。
另外 pandas 在處理大型數(shù)據(jù)方面非常慢,雖然有像Dask 或 Vaex 等其他庫來優(yōu)化提升數(shù)據(jù)處理速度,但在大數(shù)據(jù)處理神之框架Spark面前,也是小菜一碟。
幸運(yùn)的是,在新的 Spark 3.2 版本中,出現(xiàn)了一個(gè)新的Pandas API,將pandas大部分功能都集成到PySpark中,使用pandas的接口,就能使用Spark,因?yàn)?Spark 上的 Pandas API 在后臺(tái)使用 Spark,這樣就能達(dá)到強(qiáng)強(qiáng)聯(lián)手的效果,可以說是非常強(qiáng)大,非常方便。
這一切都始于 2019 年 Spark + AI 峰會(huì)。Koalas 是一個(gè)開源項(xiàng)目,可以在 Spark 之上使用 Pandas。一開始,它只覆蓋了 Pandas 的一小部分功能,但后來逐漸壯大起來。現(xiàn)在,在新的 Spark 3.2 版本中,Koalas 已合并到 PySpark。
Spark 現(xiàn)在集成了 Pandas API,因此可以在 Spark 上運(yùn)行 Pandas。只需要更改一行代碼:
importpyspark.pandasasps
由此我們可以獲得諸多的優(yōu)勢(shì):
- 如果我們熟悉使用Python 和 Pandas,但不熟悉 Spark,可以省略了需復(fù)雜的學(xué)習(xí)過程而立即使用PySpark。
- 可以為所有內(nèi)容使用一個(gè)代碼庫:無論是小數(shù)據(jù)和大數(shù)據(jù),還是單機(jī)和分布式機(jī)器。
- 可以在Spark分布式框架上,更快地運(yùn)行 Pandas 代碼。
最后一點(diǎn)尤其值得注意。
一方面,可以將分布式計(jì)算應(yīng)用于在 Pandas 中的代碼。且借助 Spark 引擎,代碼即使在單臺(tái)機(jī)器上也會(huì)更快!下圖展示了在一臺(tái)機(jī)器(具有 96 個(gè) vCPU 和 384 GiBs 內(nèi)存)上運(yùn)行 Spark 和單獨(dú)調(diào)用 pandas 分析 130GB 的 CSV 數(shù)據(jù)集的性能對(duì)比。
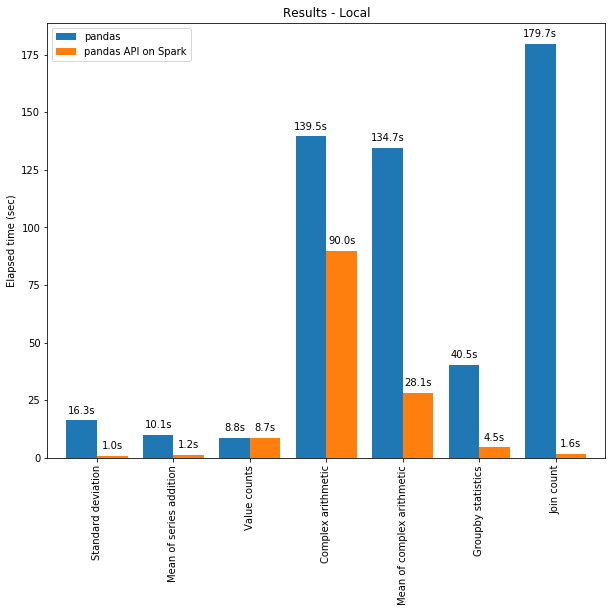
多線程和 Spark SQL Catalyst Optimizer 都有助于優(yōu)化性能。例如,Join count 操作在整個(gè)階段代碼生成時(shí)快 4 倍:沒有代碼生成時(shí)為 5.9 秒,代碼生成時(shí)為 1.6 秒。
Spark 在鏈?zhǔn)讲僮鳎╟haining operations)中具有特別顯著的優(yōu)勢(shì)。Catalyst 查詢優(yōu)化器可以識(shí)別過濾器以明智地過濾數(shù)據(jù)并可以應(yīng)用基于磁盤的連接(disk-based joins),而 Pandas 傾向于每一步將所有數(shù)據(jù)加載到內(nèi)存中。
現(xiàn)在是不是迫不及待的想嘗試如何在 Spark 上使用 Pandas API 編寫一些代碼?我們現(xiàn)在就開始吧!
在 Pandas / Pandas-on-Spark / Spark 之間切換
需要知道的第一件事是我們到底在使用什么。在使用 Pandas 時(shí),使用類pandas.core.frame.DataFrame。在 Spark 中使用 pandas API 時(shí),使用pyspark.pandas.frame.DataFrame。雖然兩者相似,但不相同。主要區(qū)別在于前者在單機(jī)中,而后者是分布式的。
可以使用 Pandas-on-Spark 創(chuàng)建一個(gè) Dataframe 并將其轉(zhuǎn)換為 Pandas,反之亦然:
#importPandas-on-Spark
importpyspark.pandasasps
#使用Pandas-on-Spark創(chuàng)建一個(gè)DataFrame
ps_df=ps.DataFrame(range(10))
#將Pandas-on-SparkDataframe轉(zhuǎn)換為PandasDataframe
pd_df=ps_df.to_pandas()
#將PandasDataframe轉(zhuǎn)換為Pandas-on-SparkDataframe
ps_df=ps.from_pandas(pd_df)
注意,如果使用多臺(tái)機(jī)器,則在將 Pandas-on-Spark Dataframe 轉(zhuǎn)換為 Pandas Dataframe 時(shí),數(shù)據(jù)會(huì)從多臺(tái)機(jī)器傳輸?shù)揭慌_(tái)機(jī)器,反之亦然(可參閱PySpark 指南[1])。
還可以將 Pandas-on-Spark Dataframe 轉(zhuǎn)換為 Spark DataFrame,反之亦然:
#使用Pandas-on-Spark創(chuàng)建一個(gè)DataFrame
ps_df=ps.DataFrame(range(10))
#將Pandas-on-SparkDataframe轉(zhuǎn)換為SparkDataframe
spark_df=ps_df.to_spark()
#將SparkDataframe轉(zhuǎn)換為Pandas-on-SparkDataframe
ps_df_new=spark_df.to_pandas_on_spark()
數(shù)據(jù)類型如何改變?
在使用 Pandas-on-Spark 和 Pandas 時(shí),數(shù)據(jù)類型基本相同。將 Pandas-on-Spark DataFrame 轉(zhuǎn)換為 Spark DataFrame 時(shí),數(shù)據(jù)類型會(huì)自動(dòng)轉(zhuǎn)換為適當(dāng)?shù)念愋停ㄕ?qǐng)參閱PySpark 指南[2])
下面的示例顯示了在轉(zhuǎn)換時(shí)是如何將數(shù)據(jù)類型從 PySpark DataFrame 轉(zhuǎn)換為 pandas-on-Spark DataFrame。
>>>sdf=spark.createDataFrame([
...(1,Decimal(1.0),1.,1.,1,1,1,datetime(2020,10,27),"1",True,datetime(2020,10,27)),
...],'tinyinttinyint,decimaldecimal,floatfloat,doubledouble,integerinteger,longlong,shortshort,timestamptimestamp,stringstring,booleanboolean,datedate')
>>>sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0),
float: float, double: double, integer: int,
long: bigint, short: smallint, timestamp: timestamp,
string: string, boolean: boolean, date: date]
psdf=sdf.pandas_api()
psdf.dtypes
tinyint int8
decimal object
float float32
double float64
integer int32
long int64
short int16
timestamp datetime64[ns]
string object
boolean bool
date object
dtype: object
Pandas-on-Spark vs Spark 函數(shù)
在 Spark 中的 DataFrame 及其在 Pandas-on-Spark 中的最常用函數(shù)。注意,Pandas-on-Spark 和 Pandas 在語法上的唯一區(qū)別就是 import pyspark.pandas as ps 一行。
當(dāng)你看完如下內(nèi)容后,你會(huì)發(fā)現(xiàn),即使您不熟悉 Spark,也可以通過 Pandas API 輕松使用。
導(dǎo)入庫
#運(yùn)行Spark
frompyspark.sqlimportSparkSession
spark=SparkSession.builder
.appName("Spark")
.getOrCreate()
#在Spark上運(yùn)行Pandas
importpyspark.pandasasps
讀取數(shù)據(jù)
以 old dog iris 數(shù)據(jù)集為例。
#SPARK
sdf=spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
#PANDAS-ON-SPARK
pdf=ps.read_csv('iris.csv')
選擇
#SPARK
sdf.select("sepal_length","sepal_width").show()
#PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()
刪除列
#SPARK
sdf.drop('sepal_length').show()#PANDAS-ON-SPARK
pdf.drop('sepal_length').head()
刪除重復(fù)項(xiàng)
#SPARK
sdf.dropDuplicates(["sepal_length","sepal_width"]).show()
#PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].drop_duplicates()
篩選
#SPARK
sdf.filter((sdf.flower_type=="Iris-setosa")&(sdf.petal_length>1.5)).show()
#PANDAS-ON-SPARK
pdf.loc[(pdf.flower_type=="Iris-setosa")&(pdf.petal_length>1.5)].head()
計(jì)數(shù)
#SPARK
sdf.filter(sdf.flower_type=="Iris-virginica").count()
#PANDAS-ON-SPARK
pdf.loc[pdf.flower_type=="Iris-virginica"].count()
唯一值
#SPARK
sdf.select("flower_type").distinct().show()
#PANDAS-ON-SPARK
pdf["flower_type"].unique()
排序
#SPARK
sdf.sort("sepal_length","sepal_width").show()
#PANDAS-ON-SPARK
pdf.sort_values(["sepal_length","sepal_width"]).head()
分組
#SPARK
sdf.groupBy("flower_type").count().show()
#PANDAS-ON-SPARK
pdf.groupby("flower_type").count()
替換
#SPARK
sdf.replace("Iris-setosa","setosa").show()
#PANDAS-ON-SPARK
pdf.replace("Iris-setosa","setosa").head()
連接
#SPARK
sdf.union(sdf)
#PANDAS-ON-SPARK
pdf.append(pdf)
transform 和 apply 函數(shù)應(yīng)用
有許多 API 允許用戶針對(duì) pandas-on-Spark DataFrame 應(yīng)用函數(shù),例如:
DataFrame.transform()
DataFrame.apply()
DataFrame.pandas_on_spark.transform_batch()
DataFrame.pandas_on_spark.apply_batch()
Series.pandas_on_spark.transform_batch()
每個(gè) API 都有不同的用途,并且在內(nèi)部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之間的主要區(qū)別在于,前者需要返回相同長(zhǎng)度的輸入,而后者不需要。
#transform
psdf=ps.DataFrame({'a':[1,2,3],'b':[4,5,6]})
defpandas_plus(pser):
returnpser+1#應(yīng)該總是返回與輸入相同的長(zhǎng)度。
psdf.transform(pandas_plus)
#apply
psdf=ps.DataFrame({'a':[1,2,3],'b':[5,6,7]})
defpandas_plus(pser):
returnpser[pser%2==1]#允許任意長(zhǎng)度
psdf.apply(pandas_plus)
在這種情況下,每個(gè)函數(shù)采用一個(gè) pandas Series,Spark 上的 pandas API 以分布式方式計(jì)算函數(shù),如下所示。
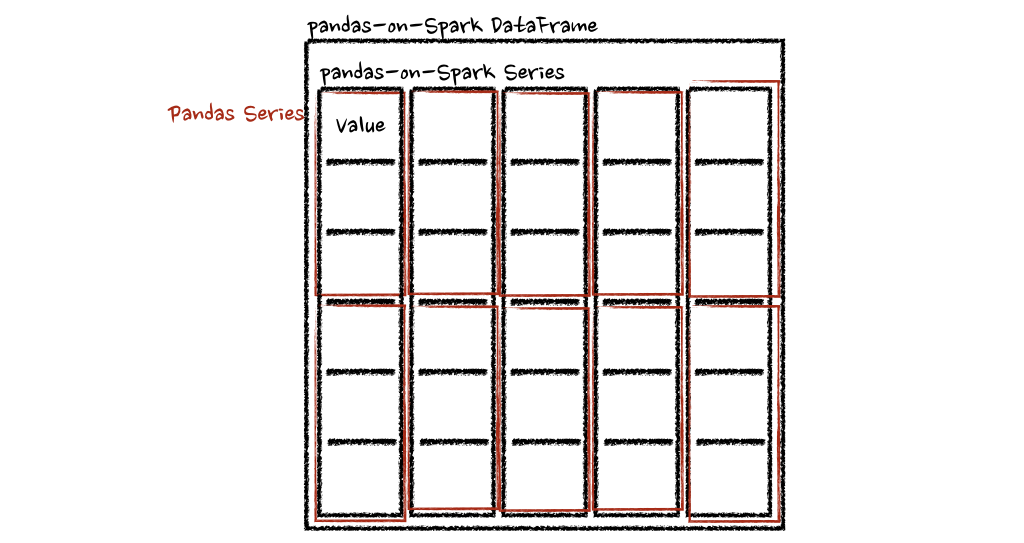
在“列”軸的情況下,該函數(shù)將每一行作為一個(gè)熊貓系列。
psdf=ps.DataFrame({'a':[1,2,3],'b':[4,5,6]})
defpandas_plus(pser):
returnsum(pser)#允許任意長(zhǎng)度
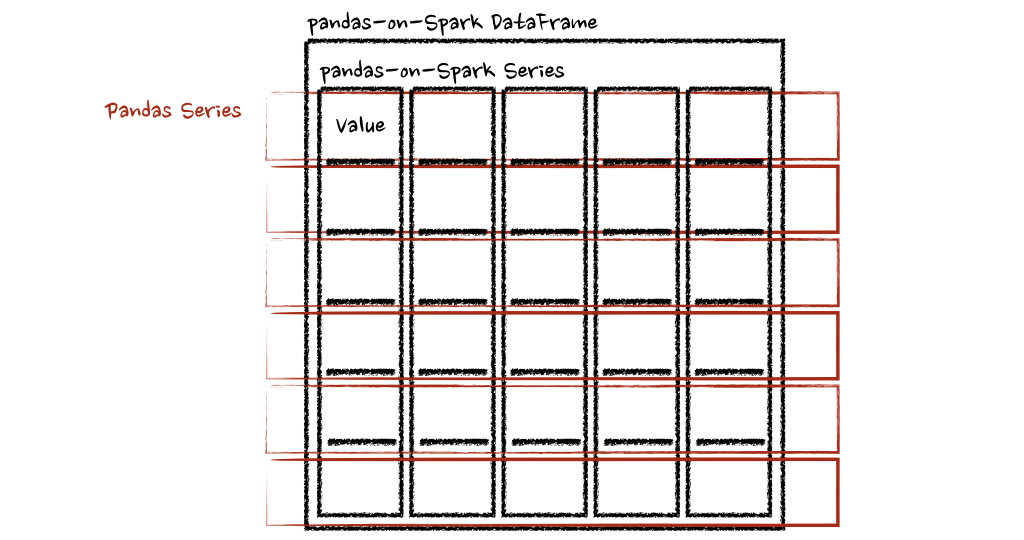
psdf.apply(pandas_plus,axis='columns')
上面的示例將每一行的總和計(jì)算為pands Series
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后綴表示 pandas-on-Spark DataFrame 或 Series 中的每個(gè)塊。API 對(duì) pandas-on-Spark DataFrame 或 Series 進(jìn)行切片,然后以 pandas DataFrame 或 Series 作為輸入和輸出應(yīng)用給定函數(shù)。請(qǐng)參閱以下示例:
psdf=ps.DataFrame({'a':[1,2,3],'b':[4,5,6]})
defpandas_plus(pdf):
returnpdf+1#應(yīng)該總是返回與輸入相同的長(zhǎng)度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf=ps.DataFrame({'a':[1,2,3],'b':[4,5,6]})
defpandas_plus(pdf):
returnpdf[pdf.a>1]#允許任意長(zhǎng)度
psdf.pandas_on_spark.apply_batch(pandas_plus)
兩個(gè)示例中的函數(shù)都將 pandas DataFrame 作為 pandas-on-Spark DataFrame 的一個(gè)塊,并輸出一個(gè) pandas DataFrame。Spark 上的 Pandas API 將 pandas 數(shù)據(jù)幀組合為 pandas-on-Spark 數(shù)據(jù)幀。
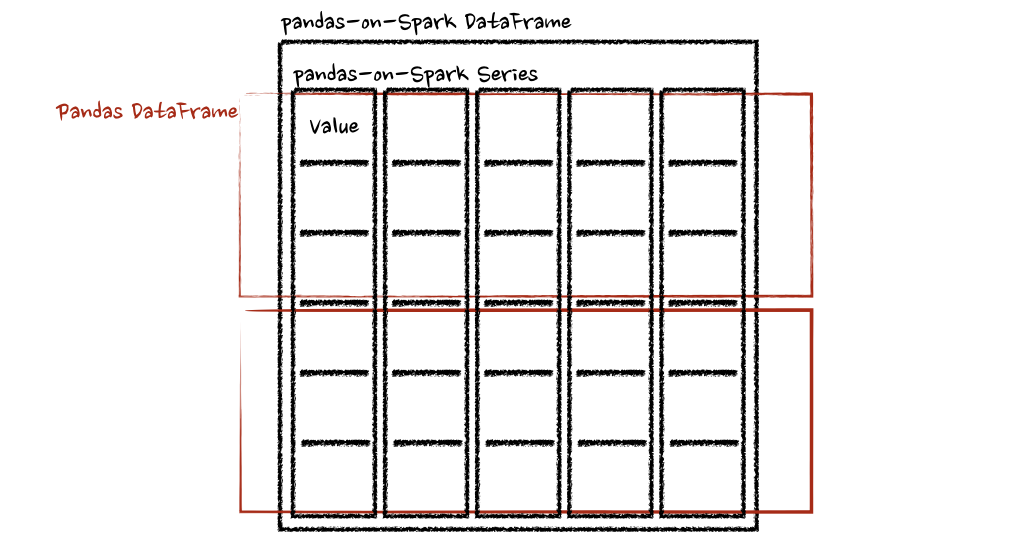 在 Spark 上使用 pandas API的注意事項(xiàng)
在 Spark 上使用 pandas API的注意事項(xiàng)避免shuffle
某些操作,例如sort_values在并行或分布式環(huán)境中比在單臺(tái)機(jī)器上的內(nèi)存中更難完成,因?yàn)樗枰獙?shù)據(jù)發(fā)送到其他節(jié)點(diǎn),并通過網(wǎng)絡(luò)在多個(gè)節(jié)點(diǎn)之間交換數(shù)據(jù)。
避免在單個(gè)分區(qū)上計(jì)算
另一種常見情況是在單個(gè)分區(qū)上進(jìn)行計(jì)算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分區(qū)規(guī)范。這會(huì)將所有數(shù)據(jù)移動(dòng)到單個(gè)機(jī)器中的單個(gè)分區(qū)中,并可能導(dǎo)致嚴(yán)重的性能下降。對(duì)于非常大的數(shù)據(jù)集,應(yīng)避免使用此類 API。
不要使用重復(fù)的列名
不允許使用重復(fù)的列名,因?yàn)?Spark SQL 通常不允許這樣做。Spark 上的 Pandas API 繼承了這種行為。例如,見下文:
importpyspark.pandasasps
psdf=ps.DataFrame({'a':[1,2],'b':[3,4]})
psdf.columns=["a","a"]
Reference 'a' is ambiguous, could be: a, a.;
此外,強(qiáng)烈建議不要使用區(qū)分大小寫的列名。Spark 上的 Pandas API 默認(rèn)不允許它。
importpyspark.pandasasps
psdf=ps.DataFrame({'a':[1,2],'A':[3,4]})
Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打開以啟用它,但需要自己承擔(dān)風(fēng)險(xiǎn)。
frompyspark.sqlimportSparkSession
builder=SparkSession.builder.appName("pandas-on-spark")
builder=builder.config("spark.sql.caseSensitive","true")
builder.getOrCreate()
importpyspark.pandasasps
psdf=ps.DataFrame({'a':[1,2],'A':[3,4]})
psdf
a A
0 1 3
1 2 4
使用默認(rèn)索引
pandas-on-Spark 用戶面臨的一個(gè)常見問題是默認(rèn)索引導(dǎo)致性能下降。當(dāng)索引未知時(shí),Spark 上的 Pandas API 會(huì)附加一個(gè)默認(rèn)索引,例如 Spark DataFrame 直接轉(zhuǎn)換為 pandas-on-Spark DataFrame。
如果計(jì)劃在生產(chǎn)中處理大數(shù)據(jù),請(qǐng)通過將默認(rèn)索引配置為distributed或distributed-sequence來使其確保為分布式。
有關(guān)配置默認(rèn)索引的更多詳細(xì)信息,請(qǐng)參閱默認(rèn)索引類型[3]。
在 Spark 上使用 pandas API
盡管 Spark 上的 pandas API 具有大部分與 pandas 等效的 API,但仍有一些 API 尚未實(shí)現(xiàn)或明確不受支持。因此盡可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 沒有實(shí)現(xiàn)__iter__(),阻止用戶將所有數(shù)據(jù)從整個(gè)集群收集到客戶端(驅(qū)動(dòng)程序)端。不幸的是,許多外部 API,例如 min、max、sum 等 Python 的內(nèi)置函數(shù),都要求給定參數(shù)是可迭代的。對(duì)于 pandas,它開箱即用,如下所示:
>>>importpandasaspd
>>>max(pd.Series([1,2,3]))
3
>>>min(pd.Series([1,2,3]))
1
>>>sum(pd.Series([1,2,3]))
6
Pandas 數(shù)據(jù)集存在于單臺(tái)機(jī)器中,自然可以在同一臺(tái)機(jī)器內(nèi)進(jìn)行本地迭代。但是,pandas-on-Spark 數(shù)據(jù)集存在于多臺(tái)機(jī)器上,并且它們是以分布式方式計(jì)算的。很難在本地迭代,很可能用戶在不知情的情況下將整個(gè)數(shù)據(jù)收集到客戶端。因此,最好堅(jiān)持使用 pandas-on-Spark API。上面的例子可以轉(zhuǎn)換如下:
>>>importpyspark.pandasasps
>>>ps.Series([1,2,3]).max()
3
>>>ps.Series([1,2,3]).min()
1
>>>ps.Series([1,2,3]).sum()
6
pandas 用戶的另一個(gè)常見模式可能是依賴列表推導(dǎo)式或生成器表達(dá)式。但是,它還假設(shè)數(shù)據(jù)集在引擎蓋下是本地可迭代的。因此,它可以在 pandas 中無縫運(yùn)行,如下所示:
importpandasaspd
data=[]
countries=['London','NewYork','Helsinki']
pser=pd.Series([20.,21.,12.],index=countries)
fortemperatureinpser:
asserttemperature>0
iftemperature>1000:
temperature=None
data.append(temperature**2)
pd.Series(data,index=countries)
London 400.0
New York 441.0
Helsinki 144.0
dtype: float64
但是,對(duì)于 Spark 上的 pandas API,它的工作原理與上述相同。上面的示例也可以更改為直接使用 pandas-on-Spark API,如下所示:
importpyspark.pandasasps
importnumpyasnp
countries=['London','NewYork','Helsinki']
psser=ps.Series([20.,21.,12.],index=countries)
defsquare(temperature)->np.float64:
asserttemperature>0
iftemperature>1000:
temperature=None
returntemperature**2
psser.apply(square)
London 400.0
New York 441.0
Helsinki 144.0
減少對(duì)不同 DataFrame 的操作
Spark 上的 Pandas API 默認(rèn)不允許對(duì)不同 DataFrame(或 Series)進(jìn)行操作,以防止昂貴的操作。只要有可能,就應(yīng)該避免這種操作。
寫在最后
到目前為止,我們將能夠在 Spark 上使用 Pandas。這將會(huì)導(dǎo)致Pandas 速度的大大提高,遷移到 Spark 時(shí)學(xué)習(xí)曲線的減少,以及單機(jī)計(jì)算和分布式計(jì)算在同一代碼庫中的合并。
審核編輯 :李倩
-
API
+關(guān)注
關(guān)注
2文章
1502瀏覽量
62051 -
代碼
+關(guān)注
關(guān)注
30文章
4790瀏覽量
68649 -
過濾器
+關(guān)注
關(guān)注
1文章
429瀏覽量
19614
原文標(biāo)題:Pandas 與 PySpark 強(qiáng)強(qiáng)聯(lián)手,功能與速度齊飛
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
東芝白電牽手創(chuàng)維 強(qiáng)強(qiáng)聯(lián)手布局中國(guó)市場(chǎng)

百度Apollo和恩智浦強(qiáng)強(qiáng)聯(lián)手 推出高安全性的ECU安全集成方案
強(qiáng)強(qiáng)聯(lián)手,瑞芯微與商湯科技聯(lián)合發(fā)布AI人臉識(shí)別一站式解決方案

單絲強(qiáng)伸儀簡(jiǎn)介
FPC軟板補(bǔ)強(qiáng)設(shè)計(jì)
強(qiáng)強(qiáng)攜手:世強(qiáng)與傳感器領(lǐng)導(dǎo)者TE正式合作
中國(guó)移動(dòng)和華為強(qiáng)強(qiáng)聯(lián)手將我國(guó)的5G建設(shè)走在世界的前端
百度華為聯(lián)手為AI時(shí)代打造最強(qiáng)算力
華為與美的的強(qiáng)強(qiáng)聯(lián)手或?qū)⒁I(lǐng)進(jìn)智能家電時(shí)代
鴻蒙系統(tǒng)不再“孤軍奮戰(zhàn)” 華為、美的強(qiáng)強(qiáng)聯(lián)手
芯華章宣布傅勇出任首席技術(shù)官,強(qiáng)強(qiáng)聯(lián)手加速打造系統(tǒng)級(jí)數(shù)字驗(yàn)證解決方案
Codasip和IAR強(qiáng)強(qiáng)聯(lián)手,共同演示用于RISC-V的雙核鎖步技術(shù)
新思科技與Arm強(qiáng)強(qiáng)聯(lián)手,加快下一代移動(dòng)SoC開發(fā)
LoRa和Sigfox的強(qiáng)強(qiáng)聯(lián)手





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論