 港中大IDEA開源首個大規模全場景人體數據集Human-Art
港中大IDEA開源首個大規模全場景人體數據集Human-Art
編者按:
自古以來,人類形象已被廣泛記錄在繪畫、雕塑等形式多樣的藝術作品中,但目前大多數以人為中心的計算機視覺任務,都僅僅關注了現實世界中的真實照片,而忽略了人在虛擬場景下的表征。
針對于此,IDEA 研究院的 CVPR 2023 入選論文之一“Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes”,提出了首個同時包含現實和虛擬場景的大規模全場景人體數據集 Human-Art,現已正式開源。
本期《IDEA有研知》為你詳細介紹Human-Art 數據集及下游任務表現。另外,本文作者在博士階段首篇投稿論文即中CVPR,文末“科研有門道”環節將帶你一同聽聽她的科研心得~
話不多說
先來看看 Human-Art 輔助訓練的模型效果
天馬行空的兒童簡筆畫,大人未必數得清
用Human-Art訓練的模型能輕松辨認計算
創作中國傳統皮影畫,已有模型束手無策?
用Human-Art訓練一下,一鍵即可生成
左:原始Stable Diffusion模型生成圖
右:使用包含Human-Art數據微調后的模型生成圖
上圖給定文本:
“一張描述了三個人坐在中國亭子的皮影戲圖片”
上圖給定文本:
“一張描述了三個女人走路的色彩豐富的皮影戲圖片”
Human-Art 數據集現已正式開源
涵蓋5個真實場景和15個虛擬場景
代碼地址:
https://github.com/IDEA-Research/HumanArt
項目主頁:
https://idea-research.github.io/HumanArt/
5萬張圖像,超12.3萬個人物形象,
Human-Art為CV領域拓展虛擬場景
在照相機發明前,人類形象已在各類藝術創作載體上被記錄和呈現。從古代的壁畫到紙上的水墨畫、油畫,以及姿態豐富的人體雕塑,再到如今AIGC創作出各種各樣的虛擬人物,大量的藝術作品同樣提供了與人體相關的、豐富多樣的視覺數據。
然而,現有的計算機視覺任務、訓練的數據集等大多只關注到了真實世界的照片,這導致相關模型在更豐富的場景下,常常出現性能下降甚至完全失效的問題。即使是SOTA性能的人體檢測模型,面對虛擬場景的人體數據時也往往令人大失所望,檢測準確率不足20%。
已有工作關注到了虛擬場景數據集稀缺的問題,如ClassArch、Sketch2Pose、People-Art等數據集納入了人造場景下的數據,但都存在數據規模小(最多的ClassArch也僅收集了1513張照片),僅能支持單一場景的人體檢測任務等不足。
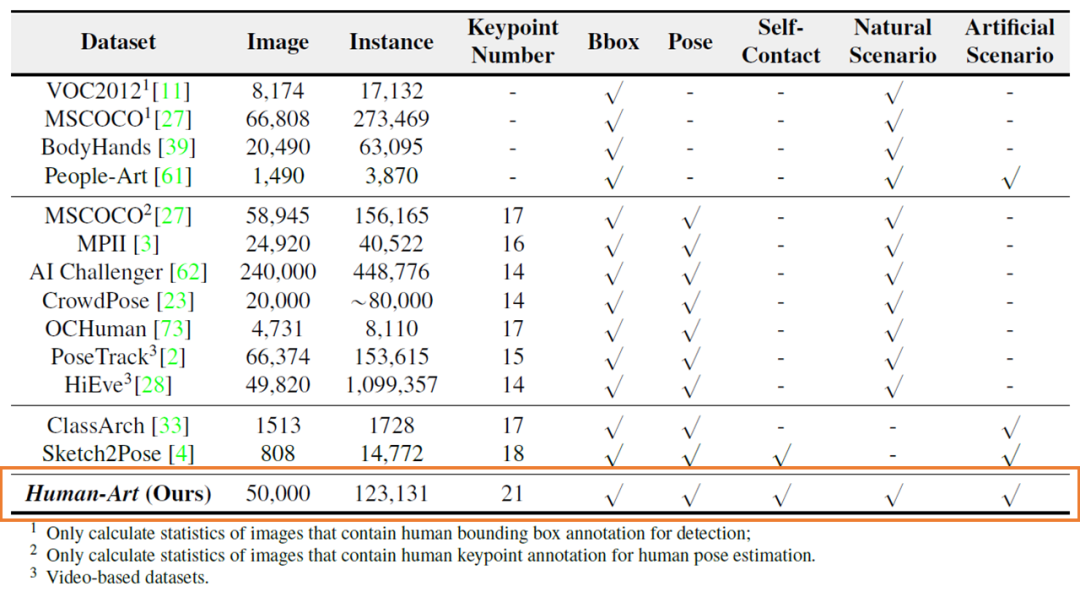
Human-Art數據集與常用數據集的對比
經過近半年的工作,本文研究團隊收集了來自5個現實場景和15個虛擬場景的5萬張高質量圖像,提出了首個同時包含現實和虛擬場景,具有人體框、人體關鍵點、自接觸點及文本描述的多場景大規模數據集Human-Art,彌補了先前數據集場景不足等問題。
Human-Art選取的場景,包括3個3D虛擬場景和12個2D虛擬場景。圖片風格除了常見的油畫、水墨畫等繪畫外,還有線條簡單的兒童簡筆畫、素描畫,形象大小各異的卡通畫,造型和服裝繁復的手辦模型,以及中國傳統的皮影等等。不同的場景都存在一定的數據處理難題,部分場景如雕塑、壁畫的人物形象殘缺或極難辨認等,需要研究團隊耗費大量時間和人力解決。(小編:聽說搭建數據集初期收集了近100萬張圖片,需要靠作者肉眼快速辨認才完成初篩……)經年累月斑駁褪色、細節難辨的壁畫
也是Human-Art數據集涵蓋的場景之一
Human-Art 每張圖片標注了人體框、21 個人體關鍵點、自接觸點及文本描述信息。為方便學術界和工業界的使用,Human-Art定義的21個人體關鍵點擴展了真實人體數據集MSCOCO中定義的17個關鍵點,新增4個腳趾尖、手指尖關鍵點。
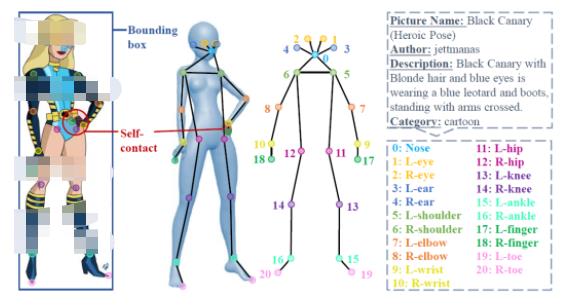
Human-Art的21個標注點信息
Human-Art 可支持多項人體相關的計算機視覺任務,如全場景人體檢測、全場景人體 2D/3D 姿態估計、全場景人體圖片生成,并為各項下游任務提供基準結果。相信未來將有助于提升各類模型在虛擬場景下訓練的性能,也可以為更多研究方向如 out-of-distribution(OOD)問題等提供幫助,為學術界帶來更多思考。
支持多項以人為主的下游視覺任務,
經Human-Art訓練的模型表現如何?
下游任務一:人體檢測
人體檢測(Human Detection)是從場景中識別并框出人物。過往的檢測方案存在兩個問題:一是大多選用通用的物體數據集訓練,沒有特別針對人做檢測,二是使用的數據集通常僅僅包含現實場景,人體檢測器在虛擬風格上的泛化性極差。
Human-Art中的圖片均以人為中心,支持對風格更具包容性的人體檢測器訓練。為了論證Human-Art數據集對于多風格訓練的作用,研究團隊在四個檢測器(Faster R-CNN、YOLOX、Deformable DETR、DINO)上進行了實驗。
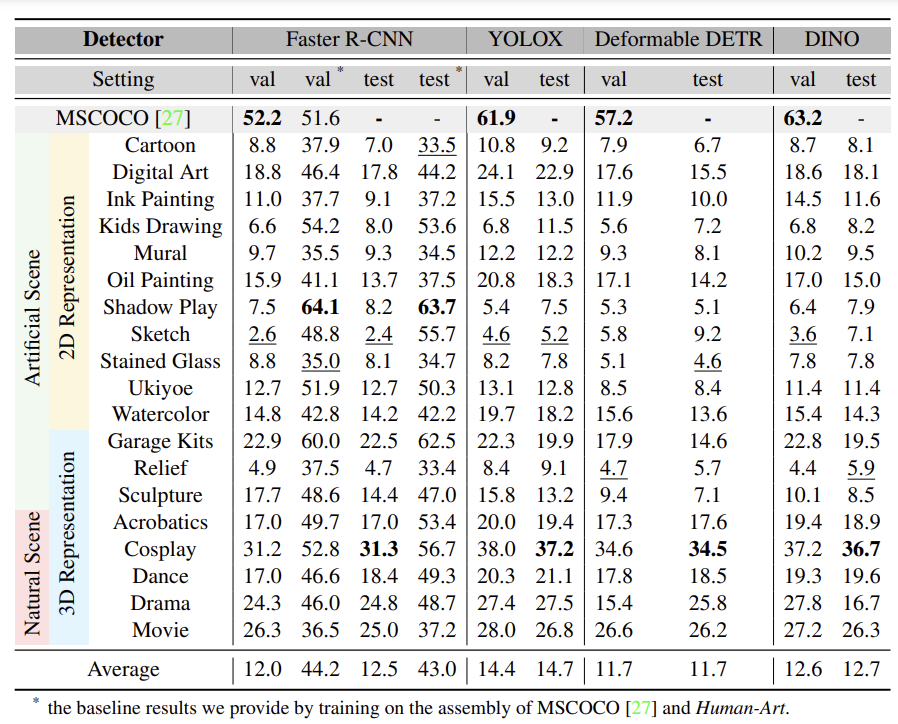
四種主要檢測器
使用Human-Art訓練測試結果
可以看到,未經過Human-Art訓練的檢測器在多風格人體數據上表現極差,而經過訓練后,Faster R-CNN檢測準確率在皮影風格上的提升可以高達56%,平均準確率提升達到31%。
下游任務二:2D人體姿態估計
人體姿態估計(Human Pose Estimation)是通過圖片還原其中人體關鍵點的位置,主要劃分為2D人體姿態估計和3D人體姿態估計。復雜姿態、遮擋和多樣化的背景,使其仍然相當具有挑戰性。
2D人體姿態估計可以被主要分為三類:自頂向下的方法(top-down)、自底向上的方法(bottom-up),以及單階段方法(one-stage)。與人體檢測類似,人體姿態識別也存在在虛擬風格上的泛化性問題。
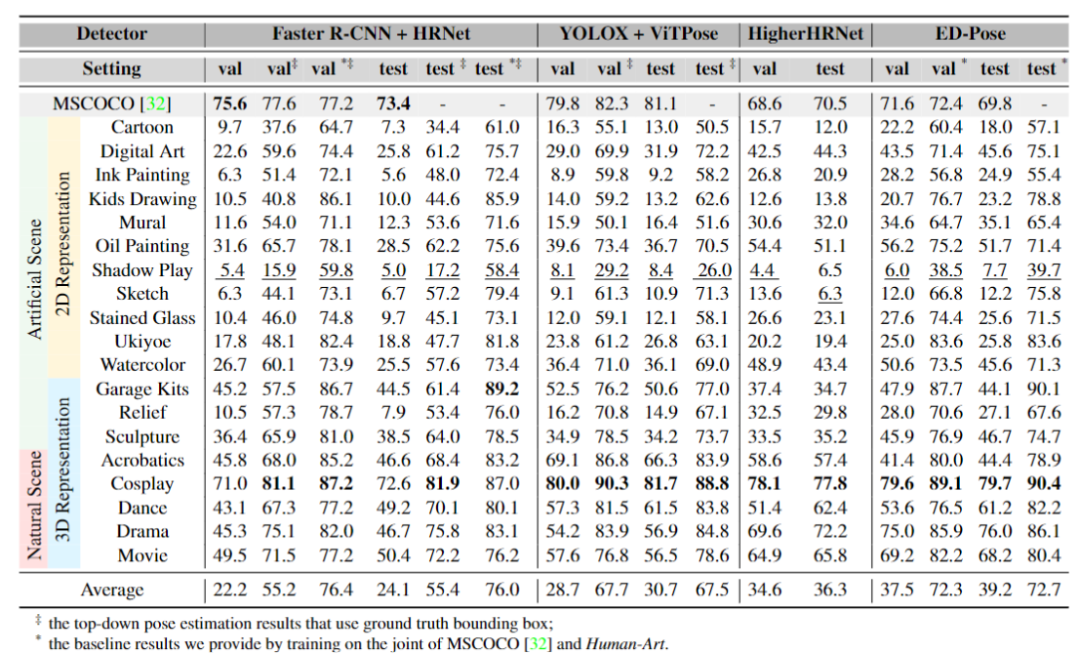
2D人體姿態估計中
使用Human-Art訓練前后對比
研究團隊在實驗中對比了三類方法在Human-Art上的結果。由于自頂向下的方法嚴重依賴于檢測器,使用未經訓練的人體姿態檢測器直接測試后的表現較難提升。相比之下,自底向上和單階段方法訓練的檢測器達到了更高精度,如自底向上方法HigherHRNet在多風格數據上的結果相比自頂向下的SOTA方法ViTPose有約6個點的提升,單階段方法ED-Pose框架訓練的模型準確率更是高出近10個點。(拓展了解:ICLR 2023入選論文ED-Pose)
下游任務三:3D人體姿態估計
單目3D人體姿態估計的深度信息檢測一直是任務難題,Human-Art標注的自接觸點信息能優先緩解這一問題。自接觸點通過合理的深度優化,將接觸區域映射到粗略SMPL模型(一種常用3D人體姿態的表征方法)的頂點上,最小化接觸頂點之間的距離。
Human-Art標注的自接觸關鍵點
能幫助優化3D人體姿態估計
下游任務四:圖片生成
Stable Diffusion等模型的提出,讓圖片生成任務成為領域內外的話題熱點。然而現有生成的人物類圖像,仍存在如多手多腳/少手少腳、肢體位置錯亂等問題,且無法更為精準地控制生成地人體姿態等。
Human-Art提供了豐富的以人為中心的圖片及對應標注,能為生成具有合理結構人體的圖片提供了良好先驗。同時,由于其豐富的標注,Human-Art可以有效輔助可控生成(如Text2Image、Pose & Text2Image),例如使用姿態信息(Pose)和文本(Text)信息訓練作為條件指導生成。
Pose & Text2Image模型效果對比
圖中Ours為基于Stable Diffusion改進的模型
在Human-Art及其他數據上共同訓練的結果
審核編輯 :李倩
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
46033 -
數據集
+關注
關注
4文章
1208瀏覽量
24739
原文標題:CVPR 2023 | 港中大&IDEA開源首個大規模全場景人體數據集Human-Art
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論