") 如何利用大規(guī)模語言模型將自然語言問題轉(zhuǎn)化為SQL語句?
如何利用大規(guī)模語言模型將自然語言問題轉(zhuǎn)化為SQL語句?
1 簡介?????????
有的工作嘗試引出中間推理步驟,通過將復(fù)雜問題顯示分解為多個子問題,從而以分而治之的方式來解決。考慮到組合泛化對于語言模型有一定的挑戰(zhàn),這種遞歸方法的對于復(fù)雜任務(wù)特定有用。根據(jù)解決子問題的方式可以分為串行跟并行兩種,串行的方式每個子問題相互依賴,前面子問題的答案會加入到后續(xù)子問題的prompt中,生成后續(xù)子問題的答案,而并行的方式則各個子問題的答案生成是獨(dú)立的,最后再將多個子問題的答案融合到一起。
2 并行式?????????
DECOMPRC
在閱讀理解場景下,多跳閱讀理解要求從眾多段落中進(jìn)行推理跟歸納。于是出現(xiàn)了新的方案DECOMPRC,將多跳閱讀理解問題分解成多個相對簡單的子問題(現(xiàn)有閱讀理解模型可以回復(fù)),從而提高閱讀理解準(zhǔn)確性。

圖1:DECOMPRC示例
整個方案分為三個部分
a)將原始的多跳閱讀理解問題分解為多個單跳子問題。可以根據(jù)多個不同的推理類型得到多種分解方式,這里需要根據(jù)不同推理類型分別訓(xùn)練多個用于問題分解的模型,對于每個分解模型,采用Point的方式,利用BERT對原問題進(jìn)行預(yù)測,得到幾個關(guān)鍵位置,利用關(guān)鍵位置原文本進(jìn)行劃分,再加上一些規(guī)則手段,就可以得到對應(yīng)的子問題了。例如預(yù)測出一個中間位置,就可以將原問題分割成兩部分,第一部分作為第一個子問題,第二部分作為第二個子問題,考慮到第二部分可能都是陳述句,就將前面的詞轉(zhuǎn)換成which。這里將分解模型簡化為一個span prediction問題,只需要400個訓(xùn)練數(shù)據(jù)就得到很不錯的效果了。
b)在第一步會產(chǎn)生多種問題分解方式,對于每一種分解方式,利用單跳閱讀理解模型回復(fù)每個子問題,然后根據(jù)不同分分解類型的特性得到最終的答案。
c)對于每一種分解方式,將原問題,分解類型,該分解方式下的問題跟對應(yīng)答案一同作為模型輸入,預(yù)測哪種分解方式對應(yīng)的結(jié)果最合理,將該分解方式下的答案作為多跳閱讀理解問題的答案。
整個流程可以簡單理解為,系統(tǒng)提供了幾種將多跳問題分解為子問題的方式,分別計算每個分解方式的合理性,再選擇其中最優(yōu)的分解方式對應(yīng)的答案作為原問題最終答案。
QA
在QA場景下,通過將復(fù)雜問題分解為相對簡單的子問題(QA模型可以回復(fù)),從而提高問答的效果。具體到多跳QA問題上,現(xiàn)將復(fù)雜問題分解為多個子問題,利用單跳QA模型生成全部子問題的答案并融合到一起作為復(fù)雜問題的答案。
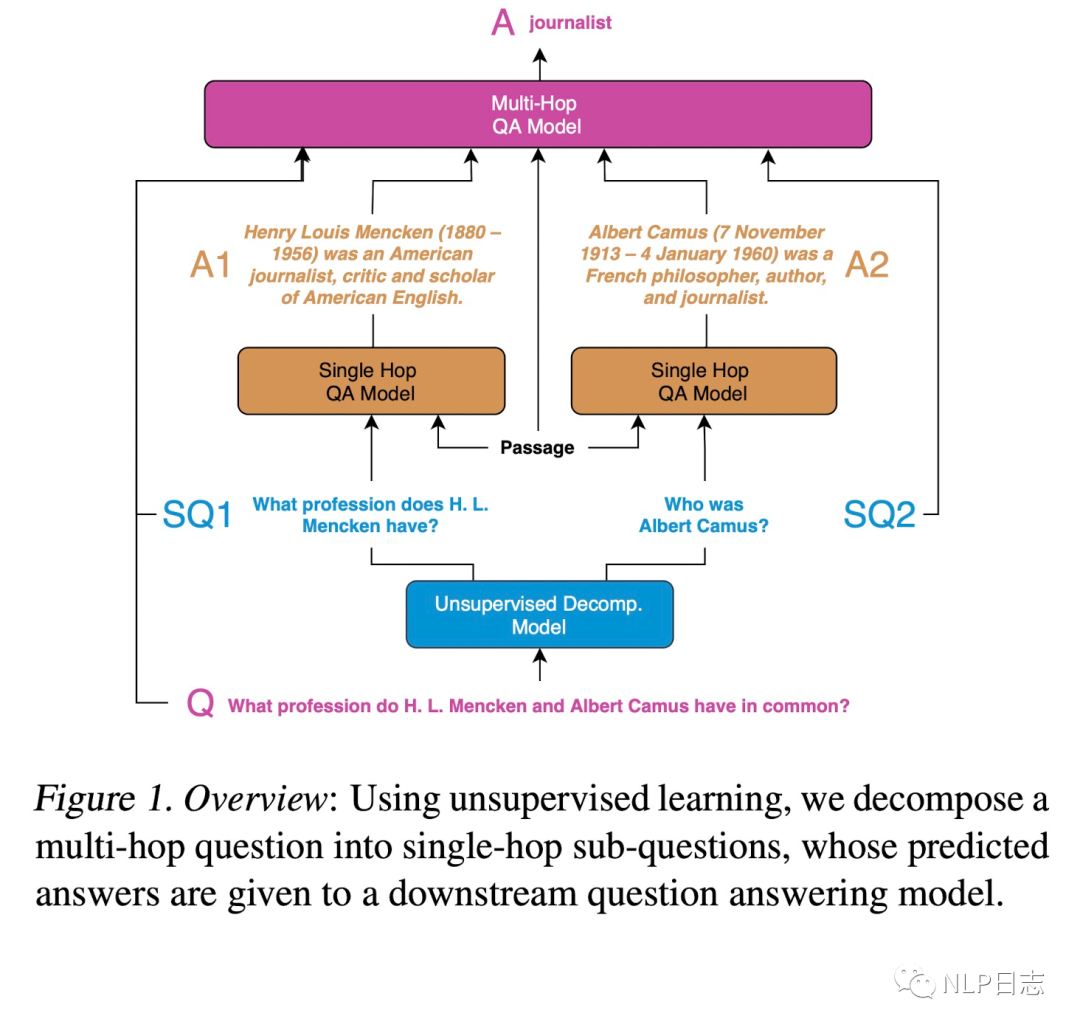
圖2: QA場景下的recursive prompting方案示例?
整個系統(tǒng)分為三個部分
a)無監(jiān)督問題分解,將原問題分解為多個相對簡單的子問題。這里需要訓(xùn)練一個分解模型,用于將復(fù)雜問題分解成多個子問題。由于這個任務(wù)下的監(jiān)督訓(xùn)練數(shù)據(jù)構(gòu)造成本高昂,于是提出了一種無監(jiān)督的訓(xùn)練數(shù)據(jù)構(gòu)造方式,對于每一個復(fù)雜問題q,從語料集Q中檢索召回得到N個對應(yīng)的簡單問題s作為q的子問題,N的取值可以依賴于具體任務(wù)或者具體問題。我們希望這些簡單問題在某些方面跟q足夠相似,同時這些簡單問題s之間有明顯差異。從而構(gòu)造出復(fù)雜問題跟子問題序列之間的偽pair對(q, [s1,…sN]),用于訓(xùn)練分解模型。
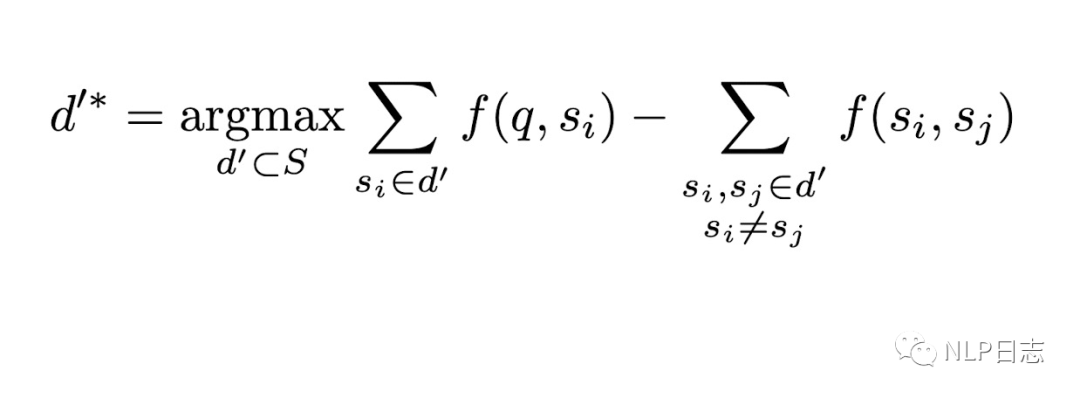
b)生成子問題回復(fù),利用現(xiàn)有的QA模型,去生成各個子問題的回復(fù)。這里不對QA模型有太多限制,只要它能正確回復(fù)語料庫S中的簡單問題即可,所以盡量采用在S中效果優(yōu)異的QA模型。
c)生成復(fù)雜問題回復(fù),將復(fù)雜問題,各個子問題跟對應(yīng)回復(fù)一同作為QA模型的輸入,生成復(fù)雜問題的回復(fù)。這里的QA模型可以采用跟第二步一樣的模型,只要將輸入做對應(yīng)調(diào)整即可。

圖3: QA場景下的recursive prompting方案示例
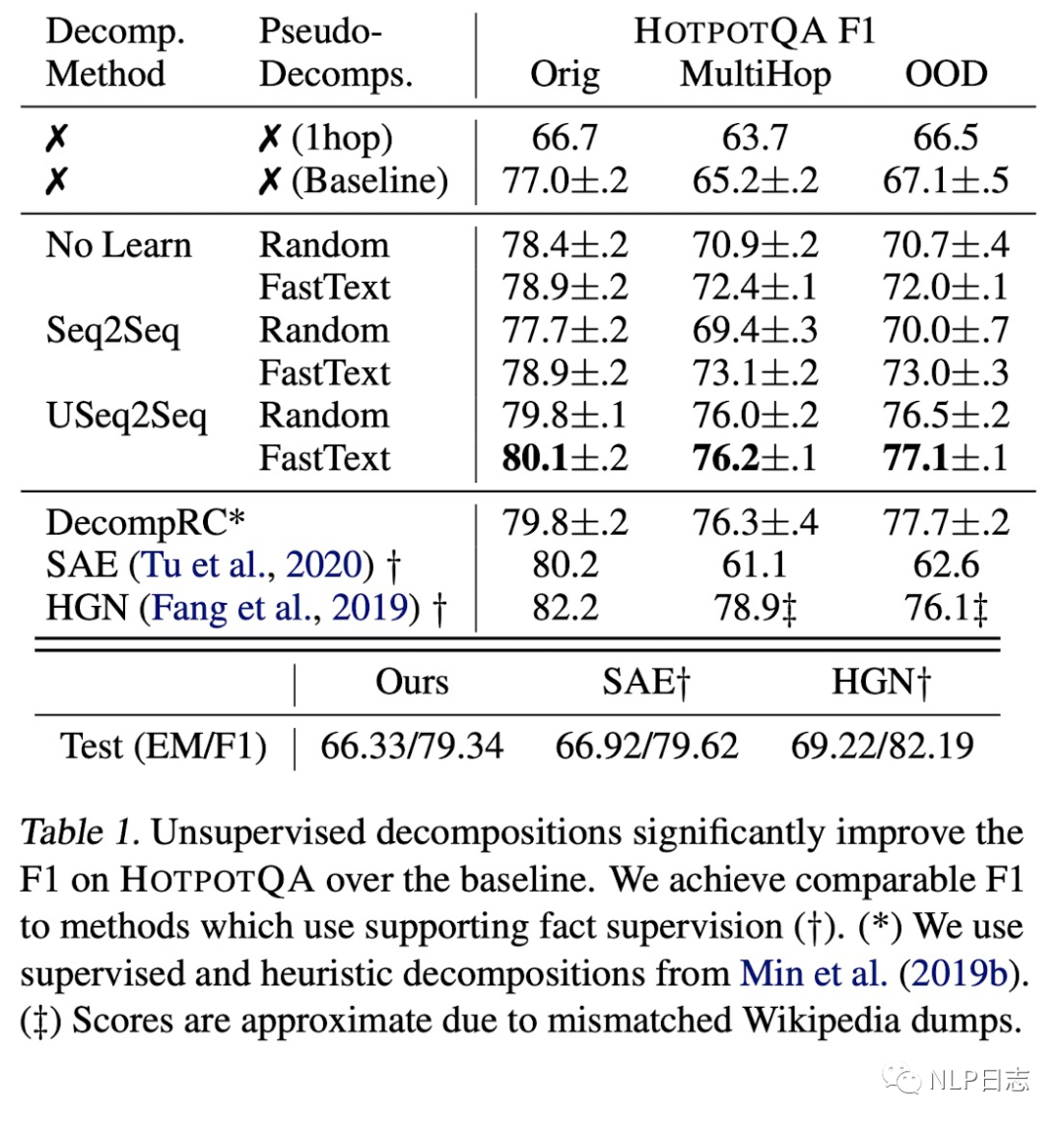
圖4: 實(shí)驗(yàn)結(jié)果對比
從實(shí)驗(yàn)效果上可以明顯看出這些問題分解的方式能夠顯著提升模型效果。
串行式
SEQZERO
如何利用大規(guī)模語言模型將自然語言問題轉(zhuǎn)化為SQL語句?SEQZERO就是一種解法。由于SQL這種規(guī)范語言的復(fù)合結(jié)構(gòu),SQL語句很多情況下會顯得復(fù)雜且冗長,要讓語言模型學(xué)會生草本跟SQL語言需要大量訓(xùn)練數(shù)據(jù),于是出現(xiàn)了一種基于few-shot的方法SEQZERO。
一個SQL語句包括多個部分,例如From **,SELCT **, WHERE **,只要能從自然語言問題中提出這幾個部分對應(yīng)的元素,然后通過規(guī)則可以轉(zhuǎn)化為對應(yīng)的SQL語句。于是SEQZERO的做法就是先利用語言模型預(yù)測得到其中一個元素,將該元素加入到原問題中生成下個元素,重復(fù)此操作直到生成全部元素,然后通過規(guī)則將所有結(jié)果組合起來的就得到對應(yīng)的SQL語句。在預(yù)測每個元素的過程中,為了得到更加強(qiáng)大的泛化能力,采用了few-shot跟zero-shot的集成策略。
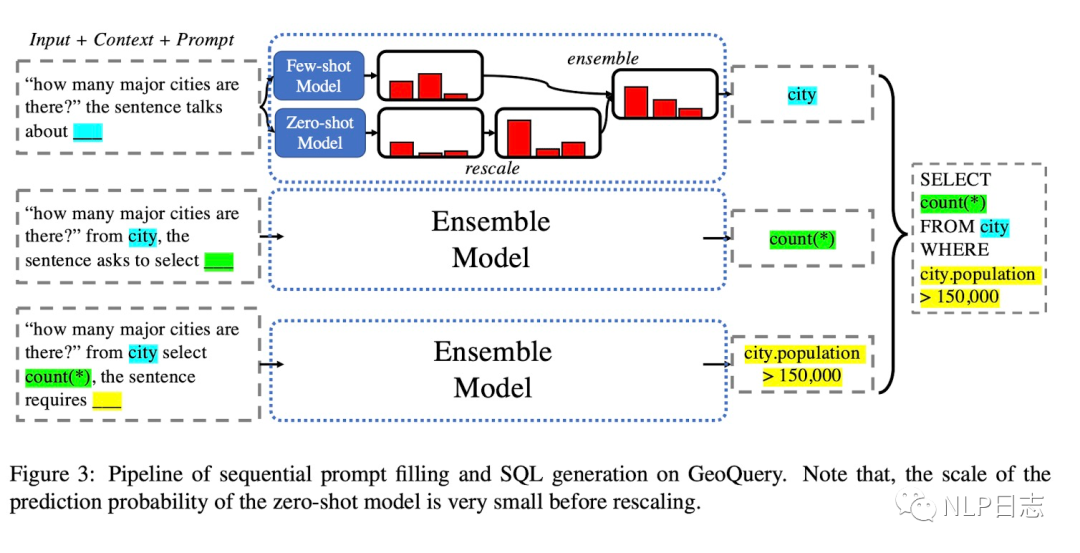
圖5: SEQZERO示例
Least-to-most
雖然chain-of-thought prompting在很多自然語言推理任務(wù)有顯著效果,但是當(dāng)問題比prompt里的示例更難時,它的表現(xiàn)會很糟糕。舉個例子,比如任務(wù)抽取文本每個單詞最后一個字母,prompt的示例輸入是3個單詞,輸入相對較短,但是問題的長度卻是10個單詞,這種情況下chain-of-thought prompting的策略就會失效。于是提出了Least-to-most,通過兩階段的prompting來解決這種問題,第一階段通過prompting將原問題分解為一系列子問題,第二階段則是通過prompting依次解決子問題,前面子問題的問題跟答案會加入到候選子問題的模型輸入中去,方便語言模型更好地回復(fù)候選子問題。由于這兩個階段任務(wù)有所區(qū)別,對應(yīng)的prompt內(nèi)容也不同。
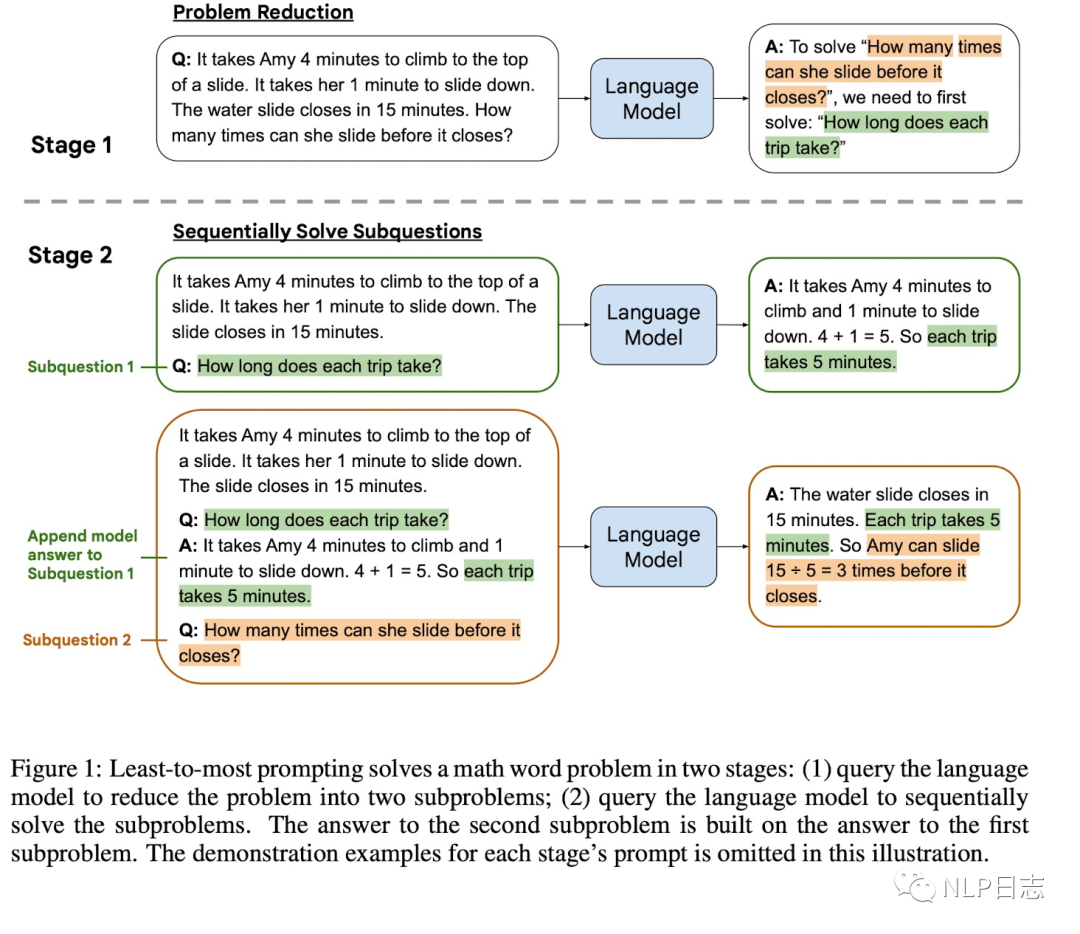
圖6: Least-to-most示例
4 其他
Successive prompting
前面幾種方法都是一開始就將問題分解為多個子問題,然后在通過串行或者并行的方式回復(fù)所有子問題,而successive prompting則是每次分解出一個子問題,讓語言模型去回復(fù)該子問題,再將該子問題以及對應(yīng)答案加入到模型輸入種,進(jìn)而分解出下一個子問題,重復(fù)這個過程直到?jīng)]有新的子問題生成,那么最后一個子問題的答案就是原問題的答案。

圖7: successive prompting示例
5 總結(jié)???????????????
Recursive prompting這種思路其實(shí)蠻好理解的,目前大規(guī)模語言模型處理這些簡單任務(wù)效果是很不錯的,但是復(fù)雜問題就比較糟糕了,一方面構(gòu)造這些復(fù)雜問題相關(guān)數(shù)據(jù)的工作很艱巨,另一方面直接讓語言模型在這些復(fù)雜問題數(shù)據(jù)上訓(xùn)練效果也很一般(想想為什么有些數(shù)據(jù)集上sota指標(biāo)也很低)。但是讓語言模型學(xué)會根據(jù)具體問題進(jìn)行拆解,通過將復(fù)雜問題分解為相對簡單的子問題,采用分而治之的方式,再將子問題答案匯總,不就得到原問題的答案了嘛。這也跟我們?nèi)祟惖男袨槟J礁咏咏瑢τ趶?fù)雜任務(wù),我們會通過合理規(guī)劃將其劃分為具體多個子任務(wù),然后再去一一解決這些子任務(wù)。想想中華民族偉大復(fù)興的道路,不也是通過一個又一個的五年計劃逐步向前推進(jìn)的嘛。
審核編輯:劉清
-
SQL
+關(guān)注
關(guān)注
1文章
768瀏覽量
44177 -
語言模型
+關(guān)注
關(guān)注
0文章
530瀏覽量
10298 -
SQL語句
+關(guān)注
關(guān)注
0文章
19瀏覽量
7068
原文標(biāo)題:增強(qiáng)語言模型之Recursive prompting
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
名單公布!【書籍評測活動NO.30】大規(guī)模語言模型:從理論到實(shí)踐
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
python自然語言
自然語言處理怎么最快入門?

自然語言處理怎么最快入門_自然語言處理知識了解
基于自然語言生成多表SQL語句模板填充的方法

自然語言和ChatGPT的大模型調(diào)教攻略
自然語言處理的概念和應(yīng)用 自然語言處理屬于人工智能嗎
大規(guī)模語言模型的基本概念、發(fā)展歷程和構(gòu)建流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論