 文本處理技巧之正則表達式
文本處理技巧之正則表達式
在LabVIEW開發過程中,有很多地方都需要處理文本數據,比如數據通訊、報表生成、協議解析、文件I/O、界面交互等,那有沒有一個工具可以幫助我們快速處理文本數據呢?答案是有的,那就是:“正則表達式”!
正則表達式(Regular Expression)是強大、高效和便捷的文本處理工具。正則表達式搭配一種編程語言,可以賦予開發人員描述和分析文本的能力。它能夠添加、刪除、拆分、插入和修改各種類型的文本數據。掌握正則表達式,可能帶來超乎你想象的文本處理能力。
接下來請跟隨小編一起學習正則表達式的相關知識并且了解在LabVIEW中處理文本數據時如何使用正則表達式吧!
本文分享:
正則表達式—文本處理技巧
一、 正則表達式的組成
為了方便大家理解,小編先給大家舉個例子:huasui.exe是一個文件名,Windows文件對話框輸入[*.exe]可以選擇多個文件,這類文件名通常被稱作“文件群組”或“通配符”,其實這就是一種正則表達式,[*.exe]能夠匹配以字符「*」開頭,以普通文本「.exe」結尾的字符串,它的意思是:選擇以任意文本開頭,以 .exe結尾的所有文件。
就像上面的例子那樣,一個完整的正則表達式由兩種字符構成,其中特殊字符(如剛才例子中的*)稱為“元字符”,其它部分(如剛才例子中的.exe)叫作“普通字符”。正則表達式其實遠不止于此,它可以為很多高級應用提供十分豐富且描述力極強的元字符。
二、 在LabVIEW中使用正則表達式
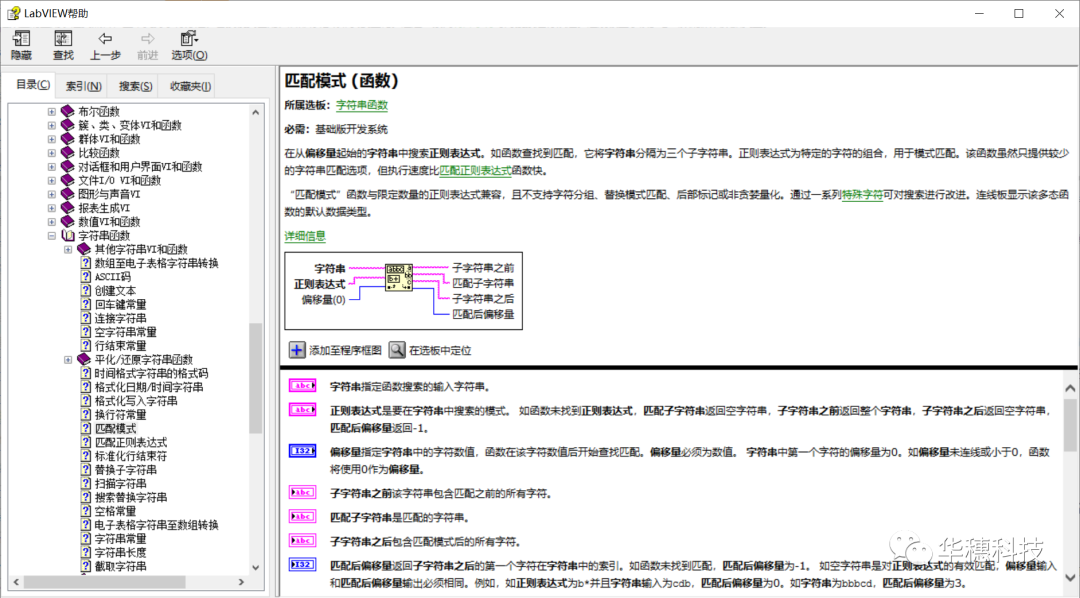
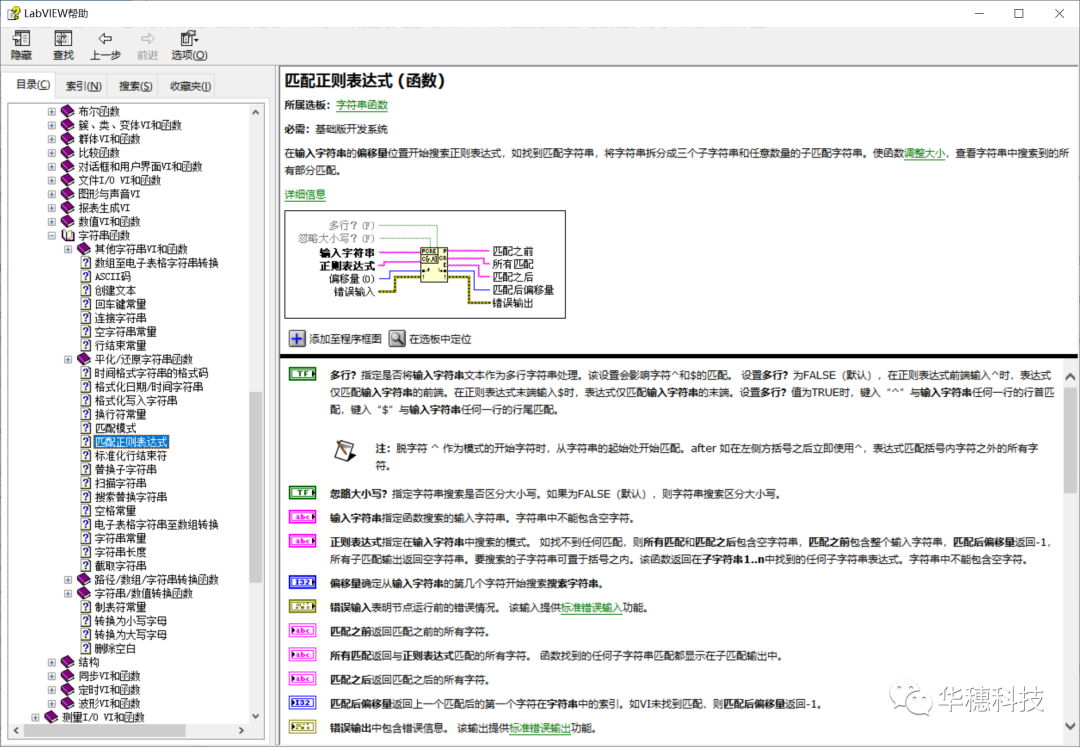
LabVIEW中提供了兩個可以使用正則表達式的函數,一個是“匹配模式”,一個是“匹配正則表達式”,它們在函數選板>>字符串中可以找到。
這兩個函數的使用方法大同小異。“匹配模式”函數類似于搜索及替換VI,該函數雖然只提供較少的字符串匹配選項(例如,該函數不支持括號和豎直線),但執行效率比“匹配正則表達式”函數高。具體使用差別可以參考LabVIEW自帶的幫助文檔。
三、 常用的正則表達式
在了解了以上LabVIEW和正則表達式的基礎知識之后,我們來一起看看正則表達式中常用的一些元字符及其含義,以下正則表達式都用一對左右角括號「 」括起來。
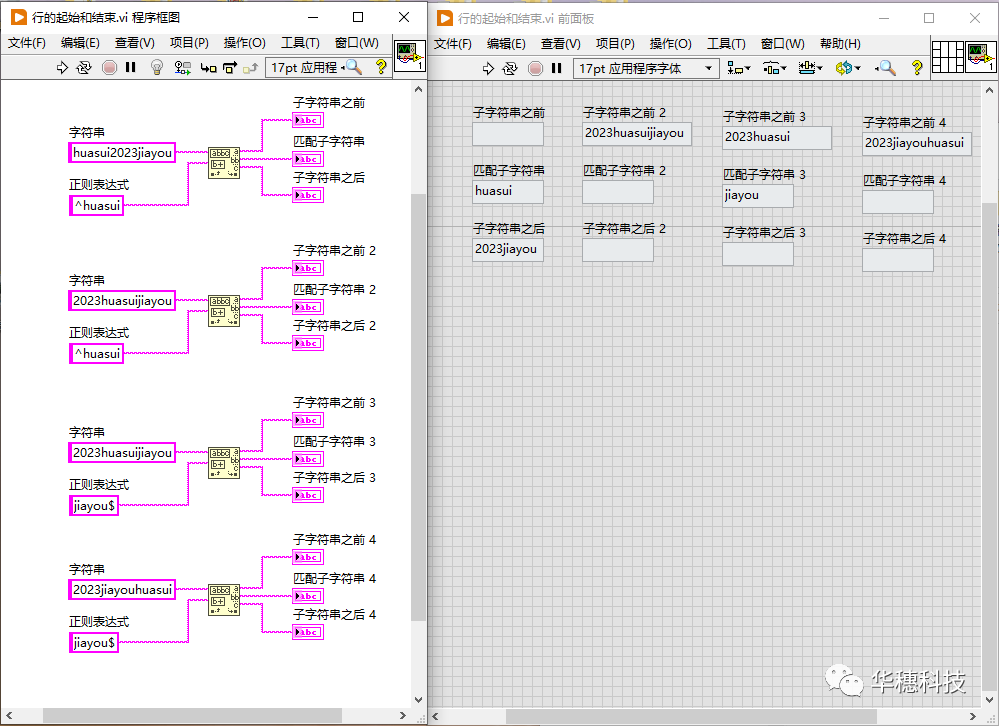
1. 行的起始和結束
在正則表達式中,符號「^」代表一行的開始,符號「$」則代表結束。比如正則表達式「huasui」尋找的是一行文本中任意位置的 huasui,而「^huasui」只尋找行首的 huasui,同樣「huasui$ 」只尋找位于行末的 huasui。在理解時應注意,元字符作用的是其緊挨著的一個字符。不要把「 ^huasui 」理解成匹配以 huasui開頭的行,而應該理解成匹配的是以h作為一行的第一個字符,緊接一個 u,然后接一個a,再接一個s,之后接一個u,最后接一個i的文本。雖然在這個例子中,這兩種理解的結果沒有差異,但是按照作用于字符來解讀更易于理解正則表達式的內部邏輯。
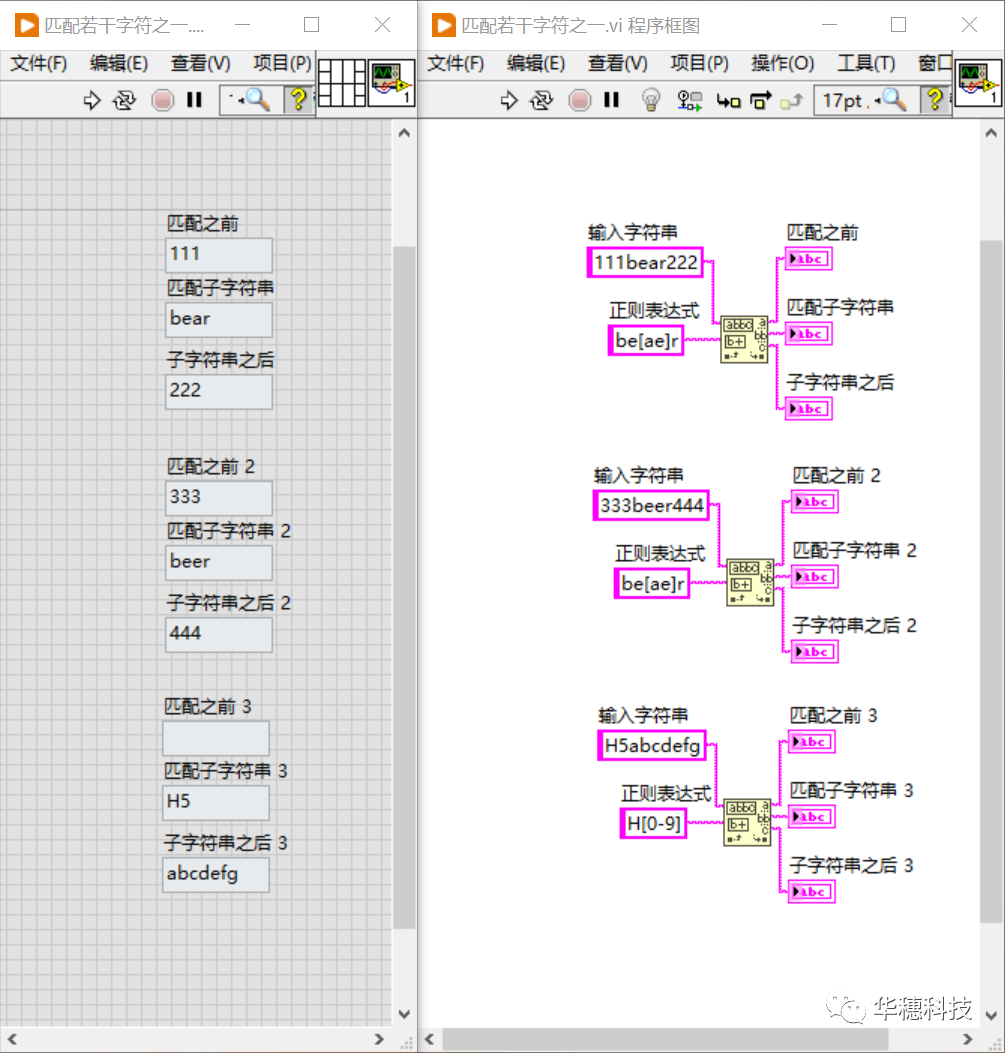
2.匹配若干字符之一
假如我們要找的單詞是"bear",但又不確定它是不是寫成"beer",那么就可以使用正則表達式結構體 「 [...] 」,它允許使用者列出在某處可能匹配的字符,通常被稱作字符組,比如正則表達式「 be[ae]r」的意思是:先找到 b,然后跟著一個 e,再跟著一個 a 或 e,最后是一個r,所以該正則表達式可以匹配"bear"也可以匹配"beer"。 在字符組內可以使用字符組元字符[-](連字符)來表示一個范圍區間,比如正則表達式「 H[123456]」與「 H[1-6]」是等價的。「 [0-9] 」、「 [a-z] 」和 「 [A-Z] 」是常用的匹配數字、大小寫字母的簡潔表示。當然在一個字符組中也支持多重范圍,比如「 [0123456789abcdef] 」可以寫作「 [0-9a-f] 」。 需要注意的是:連字符[-]只有出現在字符組內部,且不處于開頭處時,它才是一個元字符,否則就是普通的連字符號。
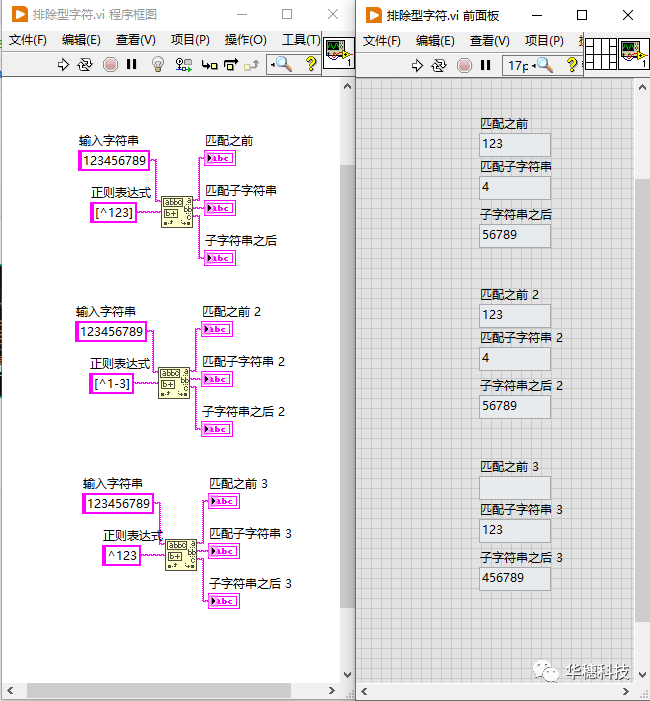
3. 排除型字符組
使用「 [^...] 」替代「 [...] 」,這個正則表達式可以匹配任何沒有出現的字符,例如「 [^0-4] 」可以匹配除了0-4以外的任何字符。表達式中開頭的 '^' 表示排除,所以它后面出現的字符都是不想匹配到的。
同樣的元字符出現在不同的地方有不同的含義,這就像同一個語句用在不同的語境中,它要表達的意思是不同的。比如 '^' 在表達式外最開頭的地方時表示一個行起始點,然而當它在表達式內部開頭處時就表示排除。
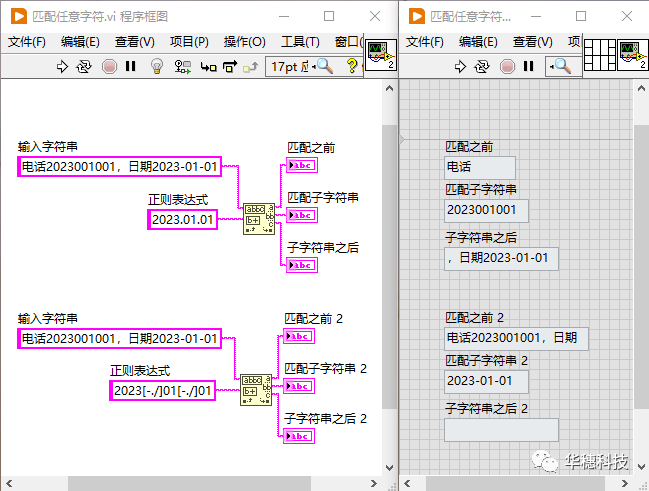
4.匹配任意字符
元字符「 . 」可以用來匹配任意字符。如果需要在正則表達式中使用一個匹配任意字符的占位符,用元字符「 . 」就十分方便。比如在一個字符串中查找 “2023/01/01” 或“2023-01-01” 或者“2023.01.01”,我們可以將正則表達式寫成「 2023[-./]01[-./]01 」,當然也可以簡單的寫成「2023.01.01」。
寫正則表達式是一個尋求平衡的過程,它不是一味追求精簡,比如上面的例子「2023[-./]01[-./]01」這種寫法就要比「2023.01.01」表達的意思更加明確,但是寫起來也更麻煩,而后面這種寫法更加簡單,但是匹配的不夠精細。那么我們平時應該如何抉擇?其實這取決于你對需要檢索的文本的了解程度,以及你需要匹配的準確程度,在這二者之間尋求一個平衡。如果你確定在被檢索的文本中使用「2023.01.01」去匹配不會得到其他非預期的結果,那么使用它就是簡潔且合理的一種表示,但是當你不確定(比如被檢索的文本中可能有一串數字2023001001),那么匹配就會得到非預期結果,此時應該選擇更加精確的匹配方式「2023[-./]01[-./]01」。
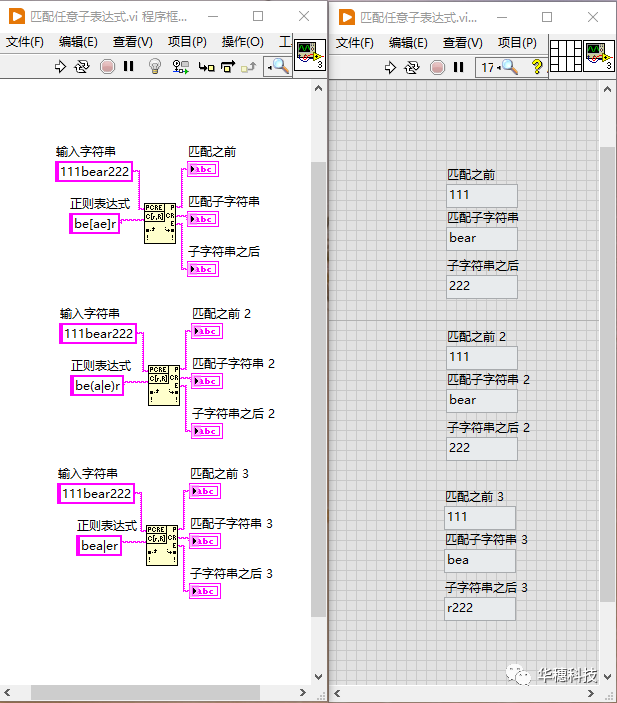
5.匹配任意子表達式
元字符「 | 」可以讓我們把不同的子表達式組合成一個總的表達式,并且這個總表達式又能匹配任意一個子表達式,所有的子表達式都被稱為“多選分支”。舉例說明:上面提到的正則表達式「be[ae]r」還能寫作「bear|beer」或者寫作「 be(a|e)r」。
使用「be(a|e)r」這種方式時圓括號是必要的,否則「 bea|er 」的含義就變成了匹配 “bea” 或 “er”,很顯然這不是我們預期的,圓括號的作用是可以限制元字符「 | 」的生效范圍。
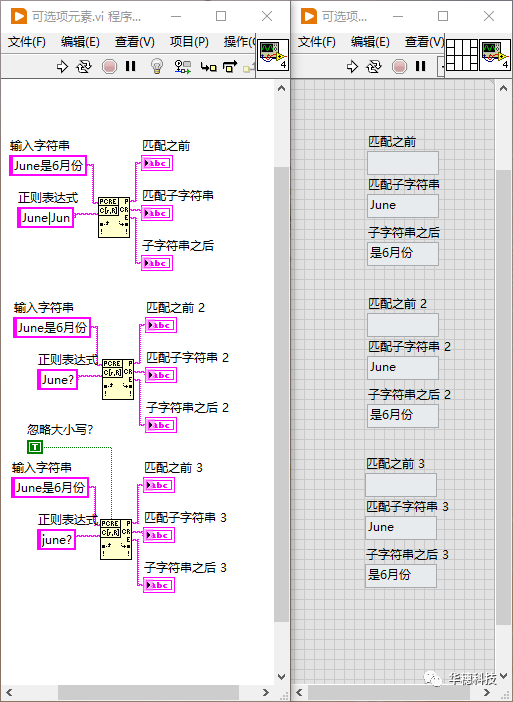
6. 可選項元素
元字符「 ? 」表示可選項,把它加在某個字符后面,就表示這里允許出現這個字符,但該字符并不是匹配成功的必要條件。該元字符只作用于它之前緊鄰的一個元素。
比如6月份的英文是“June”,也能簡寫為“Jun”,所以我們既可以用「June|Jun」來匹配,也可以用「June?」來匹配。使用正則表達式來解決實際問題時,可能有很多不同的思路和方法,我們需要在其中尋找平衡。正則表達式不是死記硬背的公式,它其實靈活的像是一門藝術。
7. 重復出現
「 + 」和「 * 」的功能和「 ? 」類似,元字符「 + 」代表前面緊鄰的字符出現一次或多次,而「 * 」代表前面緊鄰的字符沒有出現或出現多次。這三個元字符稱作量詞,因為它們限定了所作用字符的出現次數。 默認情況下,量詞匹配將盡可能多地匹配,這種匹配方式被稱作“貪婪匹配”。如果你希望盡可能少的匹配,那么就在字符串的后面加上[?]進行“非貪婪匹配“(也被稱作“懶惰匹配“)。

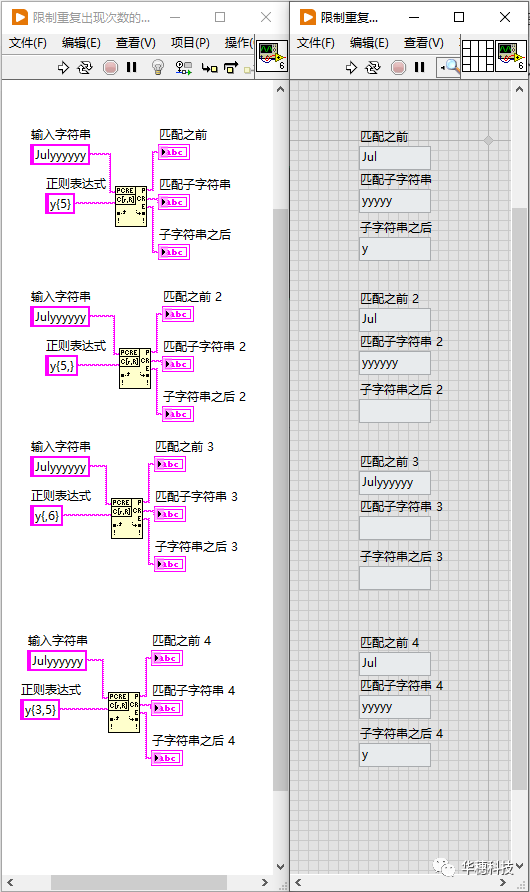
8. 限制重復出現次數的范圍
元字符序列「 {min, max} 」可以表示重現次數的區間范圍,所以它叫做區間量詞,例如「 {2, 4} 」能夠容許的重現次數在2到4之間,當然它還有其它幾種用法,總結如下:
{n} 準確匹配n次
{n,} 至少匹配n次
{,n} 最多匹配n次
{n,m} 最少匹配n次,最多不超過m次
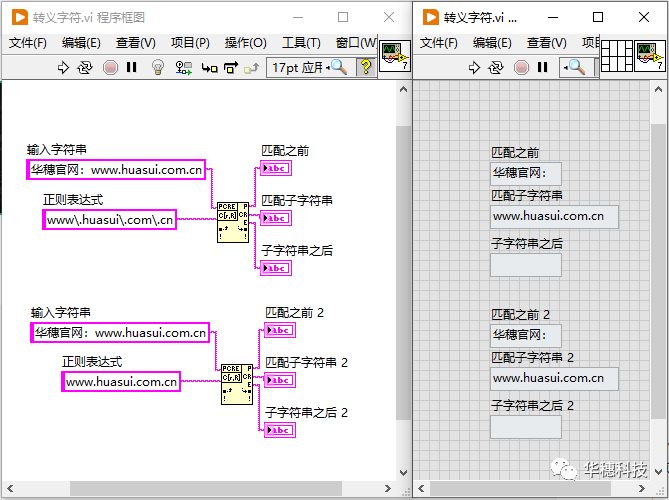
9.轉義字符
如果想匹配的某個字符本身就是一個元字符,那么就需要用到轉義字符(反斜杠 '')。比如要匹配一個網址 "www.huasui.com.cn",如果不對[.]進行轉義,正則表達式會認為這里的[.]是一個元字符,而不是普通的點號,所以正確的寫法是「 www.huasui.com.cn 」。
四、 常用字符及其含義
| 字符 | 含義 |
| 匹配一個詞語邊界,也就是詞語和空格間的位置。例如,'st' 可以匹配"test" 中的 'st',但不能匹配 "string" 中的 'st' | |
| B | 匹配非詞語邊界。'stB' 能匹配"string" 中的 'st',但不能匹配"test" 中的 'st' |
| d | 匹配一個數字字符。等價于 [0-9] |
| D | 匹配一個非數字字符。等價于 [^0-9] |
| s | 匹配任意空白字符,包括空格、換頁符、制表符等。等價于 [ f v]。 |
| S | 匹配任意非空白字符。等價于 [^ f v] |
| w | 匹配包含下劃線的任意單詞字符。等價于'[A-Za-z0-9_]' |
| W | 匹配任意非單詞字符。等價于 '[^A-Za-z0-9_]' |
| 匹配制表符。等價于 x09 和 cI | |
| 匹配換行符。等價于 x0a 和 cJ | |
| 匹配回車符。等價于 x0d 和 cM |
五、 常用匹配組
| 匹配組 | 含義 |
| (demo) | 匹配demo并獲取一個自動命名的組 |
|
(? |
匹配demo并獲取組’name’ |
| (?=demo) |
demo出現在聲明右側,但demo不作為匹配結果返回。 例如: 輸入:public keywod string "xyz"; 正則:w+(?=wod),返回“key”, 含義:匹配以wod結束的單詞,但不返回wod |
| (?<=demo) |
demo出現在聲明左側,但demo不作為匹配結果返回 例如: 輸入:public remember string "abc"; 正則:(?<=str)w+,返回“ing”, 含義:匹配以str開頭的單詞,但不返回str |
| (?!demo) |
demo不出現在聲明右側,且demo不作為匹配結果返回 例如: 輸入:remember bwa cwe "abc"; 正則:w*w(?!a)w*,返回“cwe”, 含義:匹配帶w后面不是跟隨a的單詞 |
| (?demo) | demo不出現在聲明左側,但demo不作為匹配結果返回 |
審核編輯:湯梓紅
-
LabVIEW
+關注
關注
1974文章
3656瀏覽量
324289 -
數據
+關注
關注
8文章
7080瀏覽量
89177 -
函數
+關注
關注
3文章
4338瀏覽量
62739 -
文本
+關注
關注
0文章
118瀏覽量
17092 -
正則表達式
+關注
關注
0文章
27瀏覽量
3528
原文標題:知識分享 | 文本處理技巧之正則表達式
文章出處:【微信號:華穗科技,微信公眾號:華穗科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是正則表達式?正則表達式如何工作?哪些語法規則適用正則表達式?
shell正則表達式學習
使用 Linux/Unix 進行文本處理
正則表達式匹配器
深入淺出boost正則表達式
Linux中的Grep正則表達式詳細資料說明
Python正則表達式的學習指南

Python正則表達式指南
python正則表達式中的常用函數
Linux入門之正則表達式
shell腳本基礎:正則表達式grep






 工商網監
工商網監
評論