 使用事件相機來進行隱私保護的視覺定位新方式
使用事件相機來進行隱私保護的視覺定位新方式
主要內容:
文章主要強調隱私保護下的視覺定位,這是近年來被很多研究者重視的一個研究方向,即在不傷害用戶隱私的情況下進行算法的研究。
文章以此提出了一種使用事件攝像機的魯棒、隱私保護的視覺定位算法,事件相機由于其高動態范圍和小的運動模糊比傳統相機有一定的優勢,但是缺點在于事件相機存在很大的域間隙,難以直接應用傳統的基于圖像的定位算法,針對存在的問題,文章提出了一種策略,即在定位之前,把事件相機捕獲的數據轉換為傳統圖像形式,從隱私角度來看與普通攝像機相比,事件攝像機只捕捉到一小部分視覺信息,因此可以自然隱藏敏感的視覺細節,為了進一步加強隱私保護,還在兩個級別上引入了隱私保護,即傳感器和網絡級別,傳感器級保護旨在通過輕量級過濾來隱藏面部細節,而網絡級保護則使用神經網絡來隱藏私人場景應用中的整個用戶視圖,這兩種級別的保護都涉及輕量計算,只會導致少量性能損失。
什么是事件相機?
我們大多數人對傳統相機以及其拍攝的RGB圖像很熟悉,但是對于事件相機應該是很少使用了解的。
早期的圖像處理(其實現在更多也是)都是基于傳統相機來做的,然而傳統相機在應用中有兩個很明顯的問題,如下圖,一個是運動模糊(當場景中的運動速度超過相機的采樣速率之后就會產生運動模糊),雖然可以通過算法彌補運動模糊,但是計算開銷很大,不滿足實時需求;另一個問題是由于光線的問題造成曝光不足或者過曝的動態范圍問題,強烈的陽光可能會使傳統相機無法看清視野物體。

Event camera則從傳感器層面解決傳統相機的缺點,同傳統相機不同,事件相機只觀測場景中的“運動”,確切地說是觀察場景中的“亮度的變化”,它只會在有亮度變化時輸出對應pixel的亮度變化(1或0),具有響應快、動態范圍寬、無運動模糊等優勢。
對于傳統的相機,從某種程度上是捕獲一個靜態/靜止的空間,而Event Camera的目的是捕捉運動的物體。對于單個像素點,Event Camera只有接收的光強產生變化時,該像素點才會輸出。比如亮度增加并超過的一個閾值,那么對應像素點將輸出一個亮度增加的事件。Event Camera沒有幀的概念,當場景變化時,就產生一系列的像素級(pixel-level)的輸出。事件相機的每個像素點是獨立異步工作的,所以動態范圍很大。總結就是,傳統相機以固定的幀率對場景進行全幀拍攝,所有像素同步工作。事件相機是每個像素獨立異步工作,采樣率高且僅對亮度變化(event)進行輸出,一個事件(event,亮度變化)包括發生的時刻、發生的像素坐標和事件發生的極性。所謂事件發生的極性表示的是亮度相比于前一次采樣是增加還是減少。
Contributions:
(1)使用事件攝像機在具有挑戰性的條件下進行魯棒定位
(2)傳感器級隱私保護以緩解觀察到的人的擔憂
(3)網絡級隱私保護以減輕用戶的擔憂
為什么要在隱私保護下進行算法研究?
如圖1所示,定位應用的使用者可能會擔心和提供商共享同樣的視圖,畢竟這在具有有限計算量的邊緣設備,比如手機、AR眼鏡等中是不可避免的,而且被觀察的人也會出現擔憂,被別人不知不覺就拍攝了照片。所以隱私保護下的視覺算法研究近年來被越來越多的研究者所關注研究。
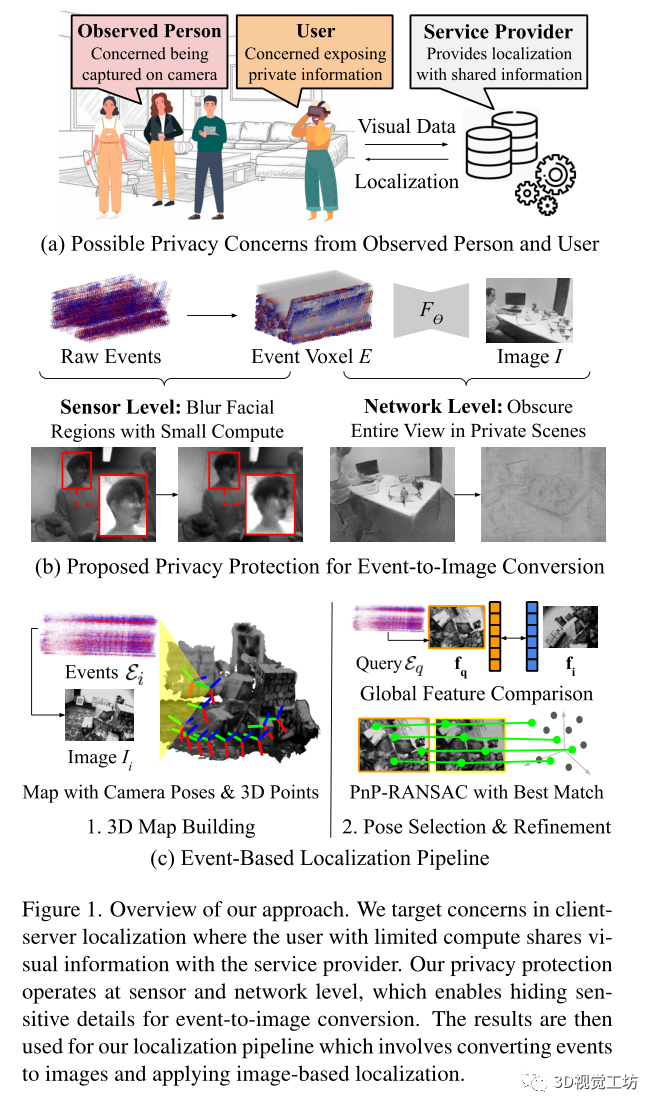
Pipeline:
給定事件相機記錄的事件流,算法輸出在3D地圖中找到的查詢事件相機的6自由度姿態,如圖1所示。


定位過程中的隱私保護:
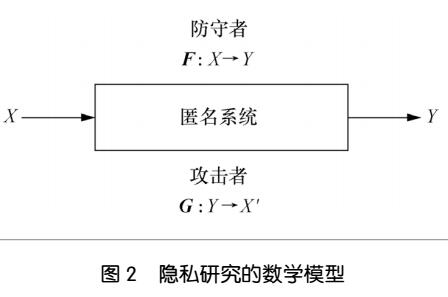
提出了兩個級別的隱私保護以防止信息共享過程中可能發生的違規行為。
(1)傳感器級隱私保護,其專注于隱藏面部細節。
(2)網絡級隱私保護,目標是在私人場景中進行定位,其用戶可能希望完全隱藏他們正在查看的內容
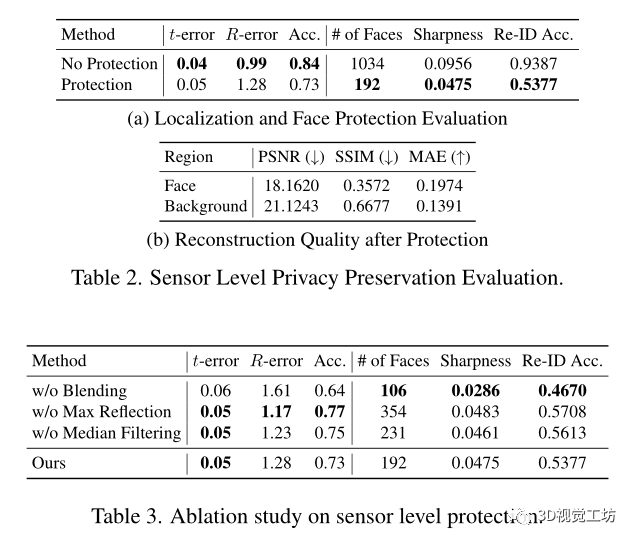
傳感器級隱私保護:
傳感器級隱私保護在一致或彎曲的區域暫時移除,并將結果與原始體素混合,這種低級操作保留了靜態結構,同時模糊了動態或面部信息,通過沿時間軸的中值濾波來過濾時間上不一致的區域,如圖2a所示。
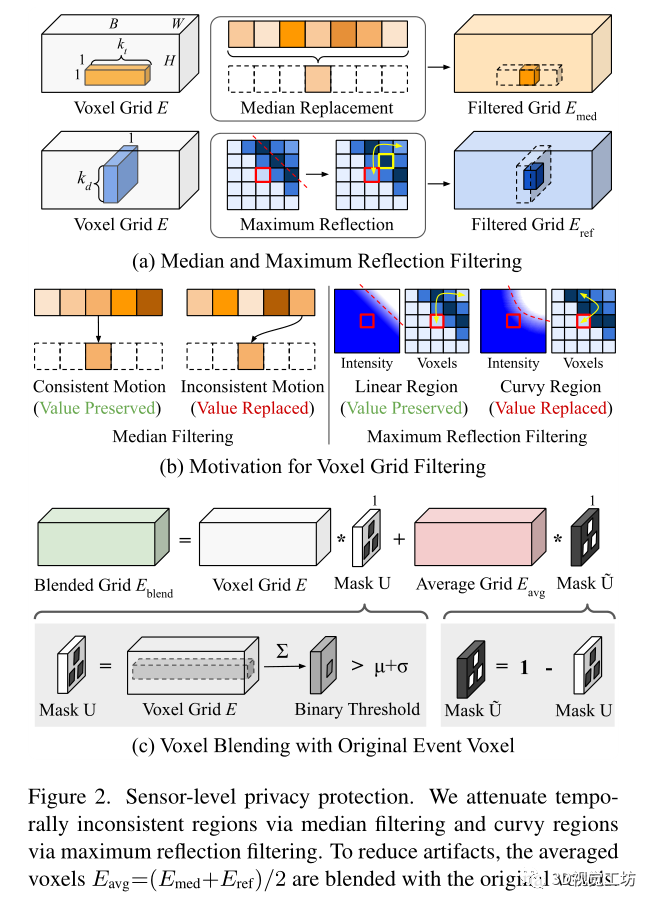


對于累積量不足的體素網格區域,由于信噪比較低,濾波過程可能會產生偽影。因此使用圖2b所示的二進制閾值將過濾后的體素與原始事件體素混合。
網絡級別隱私保護:
網絡級隱私保護將用戶的視圖完全隱藏在私有空間中,不讓服務提供商看到,同時節省了用戶端的計算。在服務提供商和用戶之間分割事件到圖像的轉換過程,其中推斷是使用私人重新訓練的重建網絡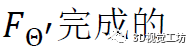 完成的
完成的
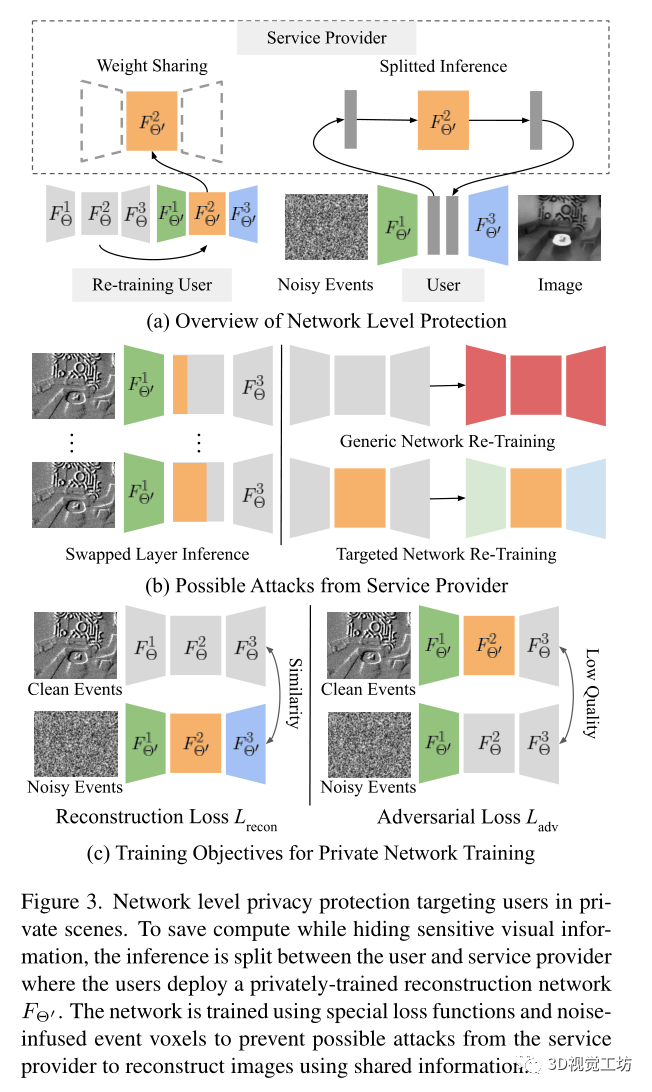

但是考慮到服務提供商可能會攻擊,如圖3b所示,有三種可能的攻擊:交換層推斷、通用網絡重新訓練和目標網絡重新訓練。首先,在交換層推斷中,采用 的中間推斷結果,并使用原始網絡參數Θ運行其余的重建。另外兩種攻擊涉及使用服務提供商可能可用的大量事件數據重新訓練一組新的網絡。通用網絡再訓練使用與私人訓練相同的訓練目標訓練隨機初始化的神經網絡。目標網絡重新訓練類似地使用相同的目標訓練神經網絡,但使用
的中間推斷結果,并使用原始網絡參數Θ運行其余的重建。另外兩種攻擊涉及使用服務提供商可能可用的大量事件數據重新訓練一組新的網絡。通用網絡再訓練使用與私人訓練相同的訓練目標訓練隨機初始化的神經網絡。目標網絡重新訓練類似地使用相同的目標訓練神經網絡,但使用 的共享參數值初始化網絡的中間部分。使用重新訓練的網絡,服務提供商可以嘗試交換層推斷,如圖3b所示。
的共享參數值初始化網絡的中間部分。使用重新訓練的網絡,服務提供商可以嘗試交換層推斷,如圖3b所示。

實驗:
數據集,使用三個數據集進行評估,DA VIS240C、EvRooms和EvHumans。
DA VIS240C包括使用DA VIS攝像機拍攝的場景,該攝像機同時輸出事件和幀。
EvRooms是文章提出的一個新數據集,用于評估基于事件的定位算法在具有挑戰性的外部條件下的魯棒性。數據集在20個場景中被捕獲,并分成包含快速相機運動(EvRoomsF)和低光照(EvRoomsL)的記錄。
EvHumans是另一個提出的新數據集,用于評估移動人群中的隱私保護定位。數據集由22名志愿者在12個場景中移動而成。這兩個數據集都是使用DA VIS346相機拍攝的。
比較的算法:
和直接的定位方法PoseNet,SP-LSTM以及以各種事件表示為輸入的基于結構的方法
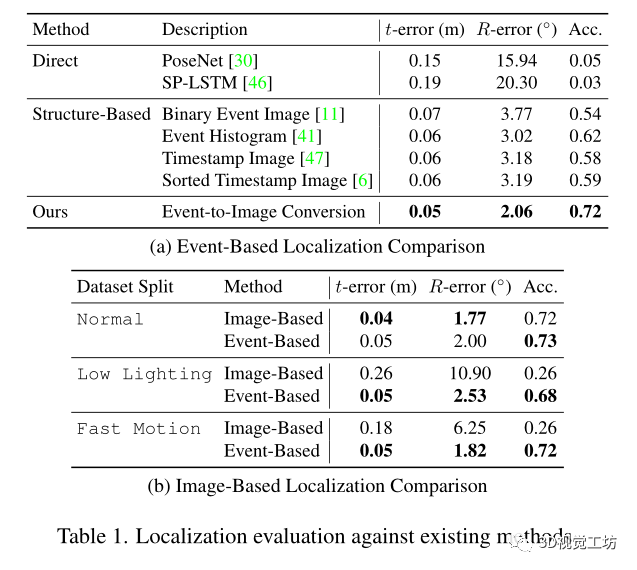
在隱私保護方面的效果:

總結:
提出了一種魯棒的基于事件的定位算法,可以同時保護用戶隱私。利用事件到圖像的轉換來適應事件攝像機上基于結構的定位。為了在轉換過程中保護隱私,提出了傳感器和網絡級別的保護。傳感器級保護的目標是隱藏面部標志,而網絡級保護的目的是在私人場景中為用戶隱藏整個視圖。
審核編輯 :李倩
-
傳感器
+關注
關注
2552文章
51237瀏覽量
754764 -
算法
+關注
關注
23文章
4622瀏覽量
93060 -
像素
+關注
關注
1文章
205瀏覽量
18607 -
相機
+關注
關注
4文章
1358瀏覽量
53721
原文標題:Arxiv 2022|使用事件相機來進行隱私保護的視覺定位新方式
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
四元數視覺:CCD機器視覺系統運行原理及工作方式
CCD機器視覺系統運行原理及工作方式
深圳CCD視覺檢測定位系統有什么特點?
四元數數控:深圳機器視覺引導定位是什么?
CCD視覺定位系統在紫外激光打標機上的應用
機器視覺入門課程(光源選型、鏡頭選型、相機選型、打光方式分析)
基于RFID隱私保護分析
如何使用差分隱私保護進行譜聚類算法
自動駕駛的視覺定位與導航應用詳細解析
解析工業相機如何進行視覺檢測
基于優化局部抑制的軌跡隱私保護算法







 工商網監
工商網監
評論