

10、OPTICS
OPTICS 聚類( OPTICS 短于訂購點數以標識聚類結構)是上述 DBSCAN 的修改版本。
我們為聚類分析引入了一種新的算法,它不會顯式地生成一個數據集的聚類;而是創建表示其基于密度的聚類結構的數據庫的增強排序。此群集排序包含相當于密度聚類的信息,該信息對應于范圍廣泛的參數設置。
—源自:《OPTICS :排序點以標識聚類結構》,1999
它是通過 OPTICS 類實現的,主要配置是“ eps ”和“ min _ samples ”超參數。下面列出了完整的示例。
# optics聚類
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定義數據集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定義模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型擬合與聚類預測
yhat = model.fit_predict(X)
# 檢索唯一群集
clusters = unique(yhat)
# 為每個群集的樣本創建散點圖
for cluster in clusters:
# 獲取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 創建這些樣本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 繪制散點圖
pyplot.show()
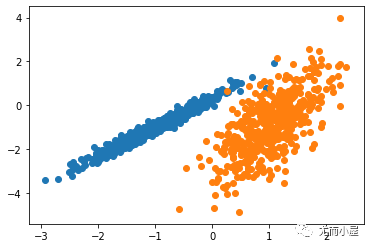
運行該示例符合訓練數據集上的模型,并預測數據集中每個示例的群集。然后創建一個散點圖,并由其指定的群集著色。在這種情況下,我無法在此數據集上獲得合理的結果。
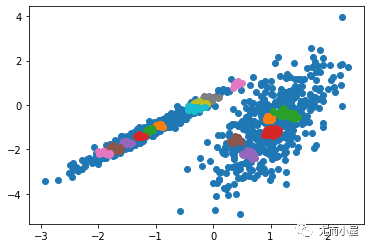
圖:使用OPTICS聚類確定具有聚類的數據集的散點圖
11、光譜聚類
光譜聚類是一類通用的聚類方法,取自線性線性代數。
最近在許多領域出現的一個有希望的替代方案是使用聚類的光譜方法。這里,使用從點之間的距離導出的矩陣的頂部特征向量。
—源自:《關于光譜聚類:分析和算法》,2002年
它是通過 Spectral 聚類類實現的,而主要的 Spectral 聚類是一個由聚類方法組成的通用類,取自線性線性代數。要優化的是“ n _ clusters ”超參數,用于指定數據中的估計群集數量。下面列出了完整的示例。
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定義數據集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定義模型
model = SpectralClustering(n_clusters=2)
# 模型擬合與聚類預測
yhat = model.fit_predict(X)
# 檢索唯一群集
clusters = unique(yhat)
# 為每個群集的樣本創建散點圖
for cluster in clusters:
# 獲取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 創建這些樣本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 繪制散點圖
pyplot.show()
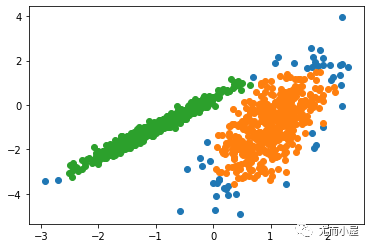
運行該示例符合訓練數據集上的模型,并預測數據集中每個示例的群集。然后創建一個散點圖,并由其指定的群集著色。
在這種情況下,找到了合理的集群。

圖:使用光譜聚類聚類識別出具有聚類的數據集的散點圖
12、高斯混合模型
高斯混合模型總結了一個多變量概率密度函數,顧名思義就是混合了高斯概率分布。它是通過 Gaussian Mixture 類實現的,要優化的主要配置是“ n _ clusters ”超參數,用于指定數據中估計的群集數量。下面列出了完整的示例。
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定義數據集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定義模型
model = GaussianMixture(n_components=2)
# 模型擬合
model.fit(X)
# 為每個示例分配一個集群
yhat = model.predict(X)
# 檢索唯一群集
clusters = unique(yhat)
# 為每個群集的樣本創建散點圖
for cluster in clusters:
# 獲取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 創建這些樣本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 繪制散點圖
pyplot.show()
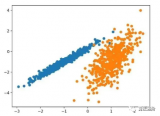
運行該示例符合訓練數據集上的模型,并預測數據集中每個示例的群集。然后創建一個散點圖,并由其指定的群集著色。在這種情況下,我們可以看到群集被完美地識別。這并不奇怪,因為數據集是作為 Gaussian 的混合生成的。

圖:使用高斯混合聚類識別出具有聚類的數據集的散點圖
三、總結
在本教程中,您發現了如何在 python 中安裝和使用頂級聚類算法。具體來說,你學到了:
- 聚類是在特征空間輸入數據中發現自然組的無監督問題。
- 有許多不同的聚類算法,對于所有數據集沒有單一的最佳方法。
- 在 scikit-learn 機器學習庫的 Python 中如何實現、適合和使用10種頂級聚類算法
-
代碼
+關注
關注
30文章
4880瀏覽量
69981 -
數據分析
+關注
關注
2文章
1469瀏覽量
34679 -
python
+關注
關注
56文章
4822瀏覽量
85833
發布評論請先 登錄
相關推薦
一種基于聚類和競爭克隆機制的多智能體免疫算法
Python無監督學習的幾種聚類算法包括K-Means聚類,分層聚類等詳細概述







 工商網監
工商網監

評論