 一種用于生成3D對象的替代方法
一種用于生成3D對象的替代方法
摘要
雖然最近關于根據文本提示生成 3D點云的工作已經顯示出可喜的結果,但最先進的方法通常需要多個 GPU 小時來生成單個樣本。這與最先進的生成圖像模型形成鮮明對比,后者在幾秒或幾分鐘內生成樣本。在本文中,我們探索了一種用于生成 3D 對象的替代方法,該方法僅需 1-2 分鐘即可在單個 GPU 上生成 3D 模型。
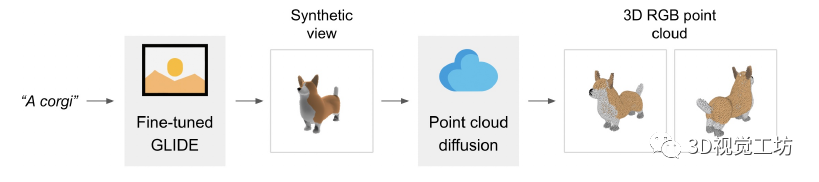
我們的方法首先使用文本到圖像的擴散模型生成單個合成視圖,然后使用以生成的圖像為條件的第二個擴散模型生成 3D 點云。雖然我們的方法在樣本質量方面仍未達到最先進的水平,但它的采樣速度要快一到兩個數量級,為某些用例提供了實際的權衡。
背景介紹

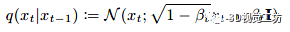

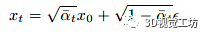

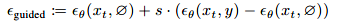
這種方法實施起來很簡單,只需要在訓練期間隨機丟棄條件信息。我們在整個模型中采用這種技術,使用丟棄概率 為0.1。
簡介
我們不是訓練單個生成模型直接生成以文本為條件的點云,而是將生成過程分為三個步驟。首先,我們生成一個以文本標題為條件的綜合視圖。接下來,我們生成一個基于合成視圖的粗略點云(1,024 個點)。最后,我們生成了一個以低分辨率點云和合成視圖為條件的精細點云(4,096 個點)。在實踐中,我們假設圖像包含來自文本的相關信息,并且不明確地以文本為條件點云。
1、數據集
我們在數百萬個 3D 模型上訓練我們的模型。我們發現數據集的數據格式和質量差異很大,促使我們開發各種后處理步驟以確保更高的數據質量。 為了將我們所有的數據轉換為一種通用格式,我們使用 Blender(Community,2018)從 20 個隨機攝像機角度將每個 3D 模型渲染為 RGBAD 圖像,Blender 支持多種 3D 格式并帶有優化的渲染引擎。對于每個模型,我們的 Blender 腳本將模型標準化為邊界立方體,配置標準照明設置,最后使用 Blender 的內置實時渲染引擎導出 RGBAD 圖像。
然后,我們使用渲染將每個對象轉換為彩色點云。特別地,我們首先通過計算每個 RGBAD 圖像中每個像素的點來為每個對象構建一個稠密點云。這些點云通常包含數十萬個不均勻分布的點,因此我們還使用最遠點采樣來創建均勻的 4K 點云。通過直接從渲染構建點云,我們能夠避免嘗試直接從 3D 網格采樣點時可能出現的各種問題,例如模型中包含的采樣點或處理以不尋常文件格式存儲的 3D 模型 。
最后,我們采用各種啟發式方法來減少數據集中低質量模型的出現頻率。首先,我們通過計算每個點云的 SVD 來消除平面對象,只保留那些最小奇異值高于某個閾值的對象。接下來,我們通過 CLIP 特征對數據集進行聚類(對于每個對象,我們對所有渲染的特征進行平均)。我們發現一些集群包含許多低質量的模型類別,而其他集群則顯得更加多樣化或可解釋。
我們將這些集群分到幾個不同質量的容器中,并使用所得容器的加權混合作為我們的最終數據集。
2、查看合成 GLIDE 模型
本文的點云模型以文中數據集的渲染視圖為條件,這些視圖都是使用相同的渲染器和照明設置生成的。因此,為了確保這些模型正確處理生成的合成視圖,我們的目標是顯式生成與數據集分布相匹配的 3D 渲染。 為此,我們微調了 GLIDE,混合了其原始的數據集和我們的 3D 渲染數據集。由于我們的 3D 數據集與原始 GLIDE 訓練集相比較小,因此我們僅在 5% 的時間內從 3D 數據集中采樣圖像,其余 95% 使用原始數據集。我們對 100K 次迭代進行了微調,這意味著該模型已經在 3D 數據集上進行了多次迭代(但從未兩次看到完全相同的渲染視點)。
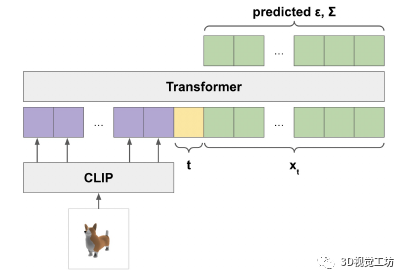
為了確保我們始終對分布渲染進行采樣(而不是僅在 5% 的時間內對其進行采樣),我們在每個 3D 渲染的文本提示中添加了一個特殊標記,表明它是 3D 渲染;然后我們在測試時使用此標記進行采樣。
3、點云擴散

值得注意的是,我們沒有為這個模型使用位置編碼。因此,模型本身對于輸入點云是排列不變的(盡管輸出順序與輸入順序相關)。
4、點云上采樣
對于圖像擴散模型,最好的質量通常是通過使用某種形式的層級結構來實現的,其中低分辨率基礎模型產生輸出,然后由另一個模型進行上采樣。我們采用這種方法來生成點云,首先使用大型基礎模型生成 1K 點,然后使用較小的上采樣模型上采樣到 4K 點。
值得注意的是,我們模型的計算需求隨點數的增加而增加,因此對于固定模型大小,生成 4K 點的成本是生成 1K 點的四倍。 我們的上采樣器使用與我們的基本模型相同的架構,為低分辨率點云提供額外的條件標記。為了達到 4K 點,上采樣器以 1K 點為條件并生成額外的 3K 點,這些點被添加到低分辨率點云中。我們通過一個單獨的線性嵌入層傳遞條件點,而不是用于 的線性嵌入層,從而允許模型將條件信息與新點區分開來,而無需使用位置嵌入。
5、點云網格
對于基于渲染的評估,我們不直接渲染生成的點云。相反,我們將點云轉換為帶紋理的網格并使用 Blender 渲染這些網格。從點云生成網格是一個經過充分研究的問題,有時甚至是一個難題。我們的模型生成的點云通常有裂縫、異常值或其他類型的噪聲,使問題特別具有挑戰性。
為此,我們簡要嘗試使用預訓練的 SAP 模型(Peng 等人,2021 年),但發現生成的網格有時會丟失點云中存在的大部分形狀或重要的形狀細節。我們沒有訓練新的 SAP 模型,而是選擇了一種更簡單的方法。 為了將點云轉換為網格,我們使用基于回歸的模型來預測給定點云的對象的符號距離場,然后將行進立方體 (Lorensen & Cline, 1987) 應用于生成的 SDF 以提取網格。然后,我們使用距離原始點云最近的點的顏色為網格的每個頂點分配顏色。
實驗結果
由于通過文本條件合成3D是一個相當新的研究領域,因此還沒有針對此任務的標準基準集。然而,其他幾項工作使用 CLIP R-Precision 評估 3D 生成,我們在表 1 中與這些方法進行了比較。除了 CLIP R-Precision 之外,我們還注意到報告的每種方法的采樣計算要求。
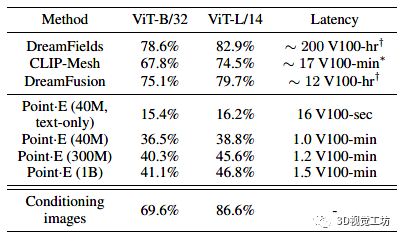
雖然我們的方法比當前最先進的方法表現要差些,但我們注意到此評估的兩個微妙之處,它們可以解釋部分(但可能不是全部)這種差異:
與 DreamFusion 等基于多視圖優化的方法不同,Point E 不會明確優化每個視圖以匹配文本提示。這可能會導致 CLIP R-Precision 降低,因為某些物體不容易從所有角度識別。
我們的方法生成的點云必須在渲染前進行預處理。將點云轉換為網格是一個難題,我們使用的方法有時會丟失點云本身中存在的信息。
總結與展望
本文介紹了 Point E,一個用于從文本生成點云的方法,它首先生成合成視圖,然后生成以這些視圖為條件的彩色點云。我們發現 Point E 能夠根據文本提示有效地生成多樣化和復雜的 3D 形狀。希望我們的方法可以作為文本到 3D這一塊研究領域進一步工作的起點。
審核編輯:劉清
-
gpu
+關注
關注
28文章
4768瀏覽量
129324 -
RGB
+關注
關注
4文章
801瀏覽量
58692 -
SVD
+關注
關注
0文章
21瀏覽量
12191 -
Clip
+關注
關注
0文章
31瀏覽量
6698
原文標題:使用擴散模型從文本提示中生成3D點云
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊混元3D AI創作引擎正式發布
騰訊混元3D AI創作引擎正式上線
一種3D交聯導電粘結劑用于硅負極Angew

Sonair推出用于機器人避障的3D超聲波傳感器
3d打印機器人外殼模型ABS材料3D打印噴漆服務-CASAIM
歡創播報 騰訊元寶首發3D生成應用

奧比中光3D相機打造高質量、低成本的3D動作捕捉與3D動畫內容生成方案
3D建模的重要內容和應用
3D建模的特點和優勢都有哪些?
包含具有多種類型信息的3D模型
NVIDIA生成式AI研究實現在1秒內生成3D形狀






 工商網監
工商網監
評論