 編寫一個LISP到JS編譯器的全過程
編寫一個LISP到JS編譯器的全過程
不知道你是不是和我一樣,看到“編譯器”三個字的時候,就感覺非常高大上,同時心底會升起一絲絲“害怕”!
我始終認為編譯器是很復雜...很復雜的東西,不是我這種小白能懂的。而且一想到要學習編譯器的知識,腦海里就浮現出那種 500 頁起的厚書。
一直到我發現 the-super-tiny-compiler 這個寶藏級的開源項目,它是一個僅 1000 行左右的迷你編譯器,其中注釋占了代碼量的 80%,實際代碼只有 200 行!麻雀雖小但五臟俱全,完整地實現了編譯器所需基本功能,通過 代碼+注釋+講解 讓你通過一個開源項目入門編譯器。
下面我將從介紹 什么是編譯器 開始,使用上述項目作為示例代碼,更加細致地講解編譯的過程,把編譯器入門的門檻再往下砍一砍。如果你之前沒有接觸過編譯器相關的知識,那這篇文章可以讓你對編譯器所做的事情,以及原理有一個初步的認識!
準備好變強了嗎?那我們開始吧!
一、什么是編譯器
從概念上簡單講:
編譯器就是將“一種語言(通常為高級語言)”翻譯為“另一種語言(通常為低級語言)”的程序。
對于現代程序員來說我們最熟悉的 JavaScript、Java 這些都屬于高級語言,也就是便于我們編程者編寫、閱讀、理解、維護的語言,而低級語言就是計算機能直接解讀、運行的語言。
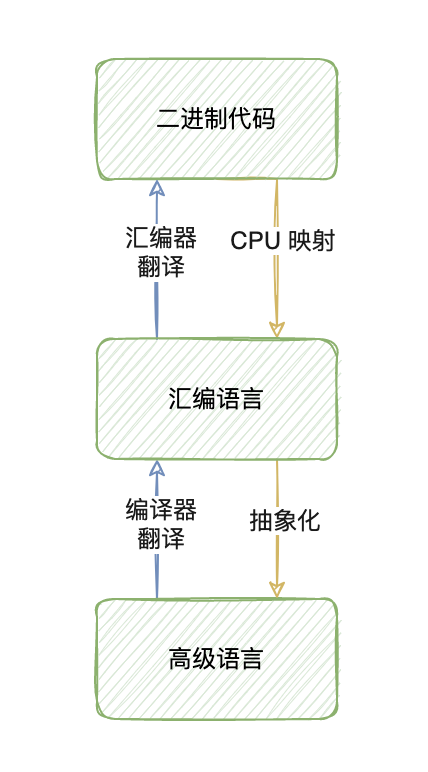
編譯器也可以理解成是這兩種語言之間的“橋梁”。編譯器存在的原因是因為計算機 CPU 執行數百萬個微小的操作,因為這些操作實在是太“微小”,你肯定不愿意手動去編寫它們,于是就有了二進制的出現,二進制代碼也被理解成為機器代碼。很顯然,二進制看上去并不好理解,而且編寫二進制代碼很麻煩,因此 CPU 架構支持把二進制操作映射作為一種更容易閱讀的語言——匯編語言。
雖然匯編語言非常低級,但是它可以轉換為二進制代碼,這種轉換主要靠的是“匯編器”。因為匯編語言仍然非常低級,對于追求高效的程序員來說是無法忍受的,所以又出現了更高級的語言,這也是大部分程序員使用且熟悉的編程語言,這些抽象的編程語言雖然不能直接轉化成機器操作,但是它比匯編語言更好理解且更能夠被高效的使用。所以我們需要的其實就是能理解這些復雜語言并正確地轉換成低級代碼的工具——編譯器。
我覺得對于初學者來說到這里有個大致的了解就可以了。因為接下去要分析的這個例子非常簡單但是能覆蓋大多數場景,你會從最真實最直接的角度來直面這個“大敵”——編譯器。
二、“迷你”編譯器
下面我們就用 the-super-tiny-compiler 為示例代碼,帶大家來簡單了解一下編譯器。
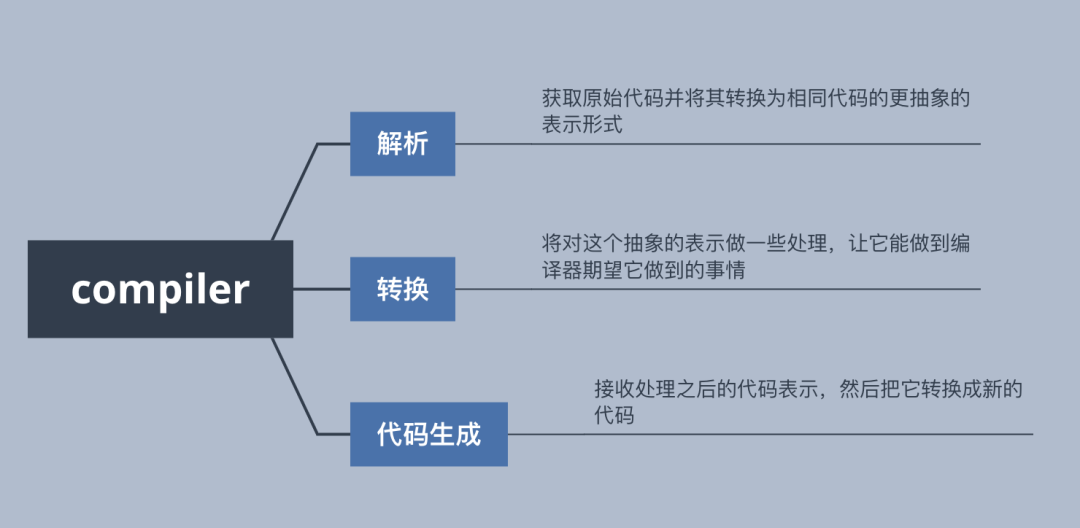
不同編譯器之間的不同階段可能存在差別,但基本都離不開這三個主要組成部分:解析、轉換和代碼生成。
其實這個“迷你”編譯器開源項目的目的就是這些:
證明現實世界的編譯器主要做的是什么
做一些足夠復雜的事情來證明構建編譯器的合理性
用最簡單的代碼來解釋編譯器的主要功能,使新手不會望而卻步
以上就解釋了這個開源項目存在的意義了,所以如果你對編譯器有很濃厚的興趣希望一學到底的,那肯定還是離不開大量的閱讀和鉆研啦,但是如果你希望對編譯器的功能有所了解,那這篇文章就別錯過啦!
現在我們就要對這個項目本身進行進一步的學習了,有些背景需要提前了解一下。這個項目主要是把 LISP 語言編譯成我們熟悉的 JavaScript 語言。
那為什么要用 LISP 語言呢?
LISP 是具有悠久歷史的計算機編程語言家族,有獨特和完全用括號的前綴符號表示法。起源于 1958 年,是現今第二悠久仍廣泛使用的高端編程語言。
首先 LISP 語言和我們熟悉的 C 語言和 JavaScript 語言很不一樣,雖然其他的語言也有強大的編譯器,但是相對于 LISP 語言要復雜得多。LISP 語言是一種超級簡單的解析語法,并且很容易被翻譯成其他語法,像這樣:

所以到這里你應該知道我們要干什么了吧?那讓我們再深入地了解一下具體要怎么進行“翻譯”(編譯)吧!
三、編譯過程
前面我們已經提過,大部分的編譯器都主要是在做三件事:
解析
轉換
代碼生成
下面我們將分解 the-super-tiny-compiler 的代碼,然后進行逐行解讀。
讓我們一起跟著代碼,弄清楚上述三個階段具體做了哪些事情~
3.1 解析
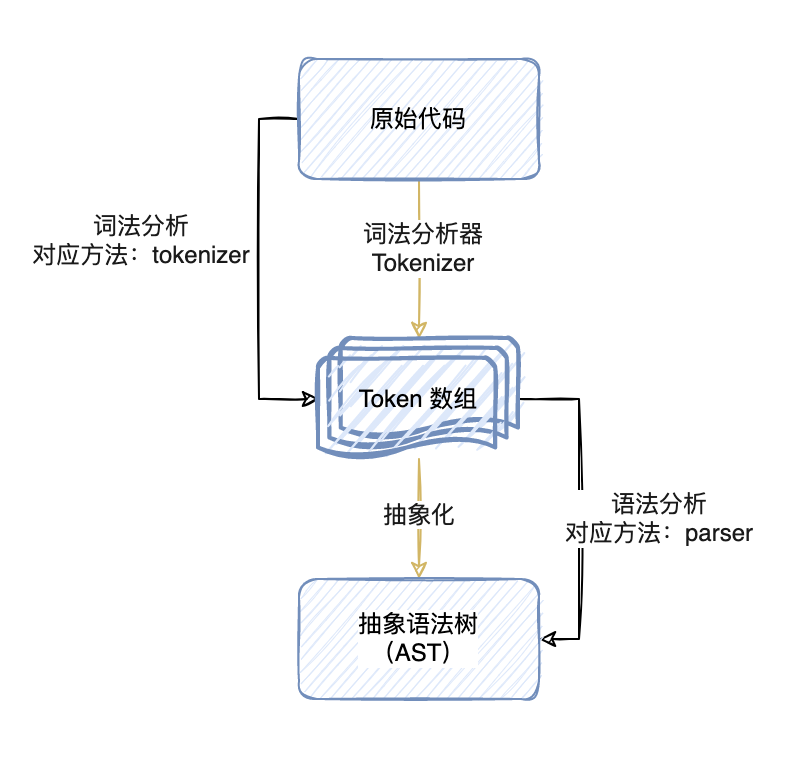
解析通常分為兩個階段:詞法分析和句法分析
詞法分析:獲取原始代碼并通過一種稱為標記器(或詞法分析器 Tokenizer)的東西將其拆分為一種稱為標記(Token)的東西。標記是一個數組,它描述了一個獨立的語法片段。這些片段可以是數字、標簽、標點符號、運算符等等。
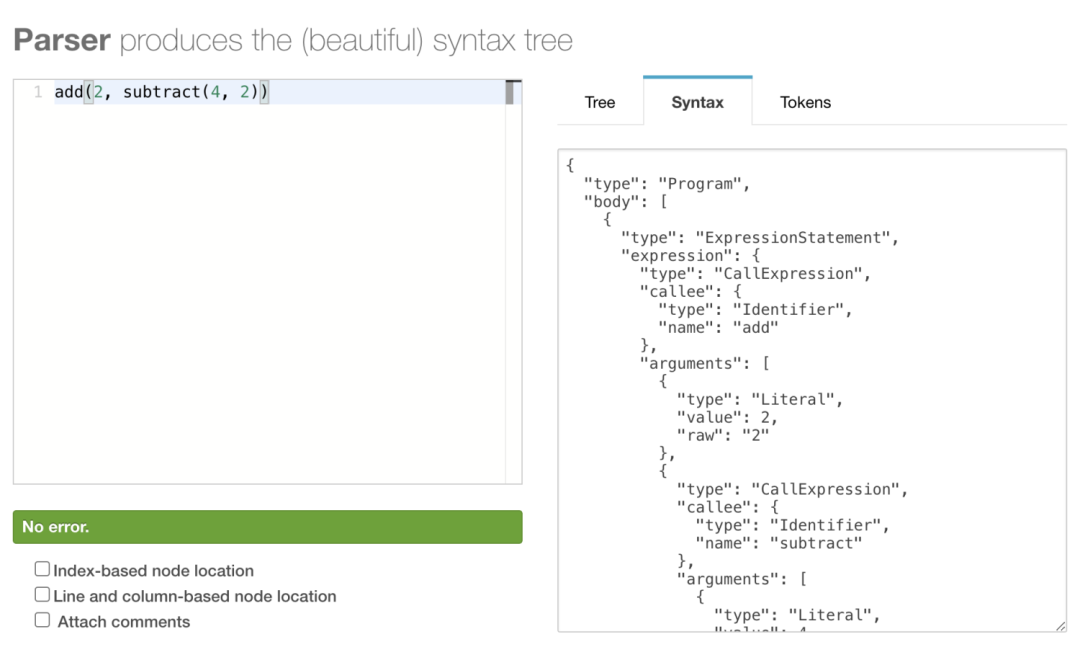
語法分析:獲取之前生成的標記(Token),并把它們轉換成一種抽象的表示,這種抽象的表示描述了代碼語句中的每一個片段以及它們之間的關系。這被稱為中間表示(intermediate representation)或抽象語法樹(Abstract Syntax Tree, 縮寫為AST)。AST 是一個深度嵌套的對象,用一種更容易處理的方式代表了代碼本身,也能給我們更多信息。
比如下面這個語法:
(add2(subtract42))
拆成 Token 數組就像這樣:
[
{type:'paren',value:'('},
{type:'name',value:'add'},
{type:'number',value:'2'},
{type:'paren',value:'('},
{type:'name',value:'subtract'},
{type:'number',value:'4'},
{type:'number',value:'2'},
{type:'paren',value:')'},
{type:'paren',value:')'},
]
代碼思路:
因為我們需要去解析字符串,就需要有一個像指針/光標來幫我們辨認目前解析的位置是哪里,所以會有一個 current 的變量,從 0 開始。而我們最終的目的是獲取一個 token 數組,所以也先初始化一個空數組 tokens。
//`current`變量就像一個指光標一樣讓我們可以在代碼中追蹤我們的位置 letcurrent=0; //`tokens`數組用來存我們的標記 lettokens=[];
既然要解析字符串,自然少不了遍歷啦!這里就用一個 while 循環來解析我們當前的字符串。
//在循環里面我們可以將`current`變量增加為我們想要的值 while(current
如何獲取字符串里面的單個字符呢?答案是用像數組那樣的中括號來獲取:
varchar=str[0]
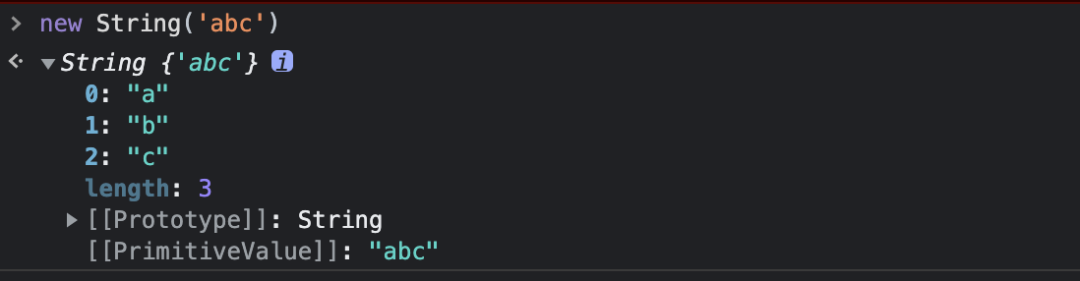
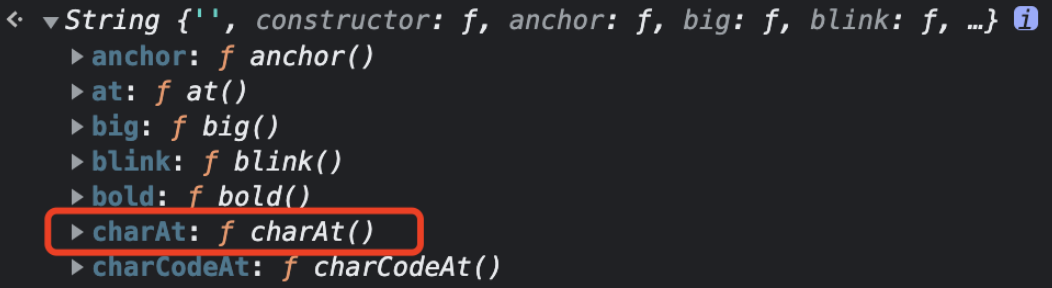
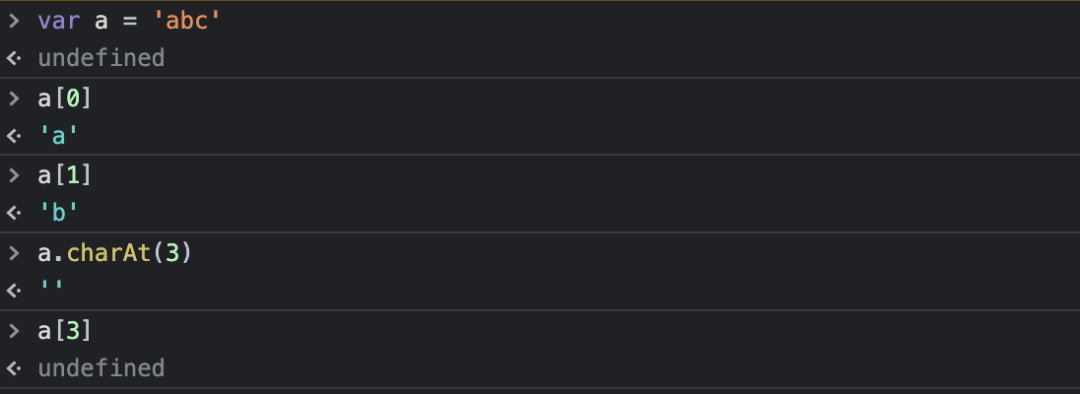
這里新增一個知識點來咯!在 JavaScript 中 String 類的實例,是一個類數組,從下面這個例子可以看出來:
可能之前你會用 charAt 來獲取字符串的單個字符,因為它是在 String 類型上的一個方法:
這兩個方法都可以實現你想要的效果,但是也存在差別。下標不存在時 str[index] 會返回 undefined,而 str.charAt(index) 則會返回 ""(空字符串):
隨著光標的移動和字符串中字符的獲取,我們就可以來逐步解析當前字符串了。
那解析也可以從這幾個方面來考慮,以 (add 2 (subtract 4 2)) 這個為例,我們會遇到這些:( 左括號、字符串、空格、數字、) 右括號。對于不同的類型,就要用不同的 if 條件判斷分別處理:
左右括號匹配代表一個整體,找到對應的括號只要做上標記就好
空格代表有字符分割,不需要放到我們的 token 數組里,只需要跳到下一個非空格的字符繼續循環就好
//檢查是否有一個左括號: if(char==='('){ //如果有,我們會存一個類型為`paren`的新標記到數組,并將值設置為一個左括號。 tokens.push({ type:'paren', value:'(', }); //`current`自增 current++; //然后繼續進入下一次循環。 continue; } //接下去檢查右括號,像上面一樣 if(char===')'){ tokens.push({ type:'paren', value:')', }); current++; continue; } //接下去我們檢查空格,這對于我們來說就是為了知道字符的分割,但是并不需要存儲為標記。 //所以我們來檢查是否有空格的存在,如果存在,就繼續下一次循環,做除了存儲到標記數組之外的其他操作即可 letWHITESPACE=/s/; if(WHITESPACE.test(char)){ current++; continue; }
字符串和數字因為具有各自不同的含義,所以處理上面相對復雜一些。先從數字來入手,因為數字的長度不固定,所以要確保獲取到全部的數字字符串呢,就要經過遍歷,從遇到第一個數字開始直到遇到一個不是數字的字符結束,并且要把這個數字存起來。
//(add123456) //^^^^^^ //只有兩個單獨的標記 // //因此,當我們遇到序列中的第一個數字時,我們就開始了 letNUMBERS=/[0-9]/; if(NUMBERS.test(char)){ //我們將創建一個`value`字符串,并把字符推送給他 letvalue=''; //然后我們將遍歷序列中的每個字符,直到遇到一個不是數字的字符 //將每個作為數字的字符推到我們的`value`并隨著我們去增加`current` //這樣我們就能拿到一個完整的數字字符串,例如上面的123和456,而不是單獨的123456 while(NUMBERS.test(char)){ value+=char; char=input[++current]; } //接著我們把數字放到標記數組中,用數字類型來描述區分它 tokens.push({type:'number',value}); //繼續外層的下一次循環 continue; }
為了更適用于現實場景,這里支持字符串的運算,例如 (concat "foo" "bar") 這種形式的運算,那就要對 " 內部的字符串再做一下解析,過程和數字類似,也需要遍歷,然后獲取全部的字符串內容之后再存起來:
//從檢查開頭的雙引號開始: if(char==='"'){ //保留一個`value`變量來構建我們的字符串標記。 letvalue=''; //我們將跳過編輯中開頭的雙引號 char=input[++current]; //然后我們將遍歷每個字符,直到我們到達另一個雙引號 while(char!=='"'){ value+=char; char=input[++current]; } //跳過相對應閉合的雙引號. char=input[++current]; //把我們的字符串標記添加到標記數組中 tokens.push({type:'string',value}); continue; }
最后一種標記的類型是名稱。這是一個字母序列而不是數字,這是我們 lisp 語法中的函數名稱:
//(add24) //^^^ //名稱標記 // letLETTERS=/[a-z]/i; if(LETTERS.test(char)){ letvalue=''; //同樣,我們遍歷所有,并將它們完整的存到`value`變量中 while(LETTERS.test(char)){ value+=char; char=input[++current]; } //并把這種名稱類型的標記存到標記數組中,繼續循環 tokens.push({type:'name',value}); continue; }
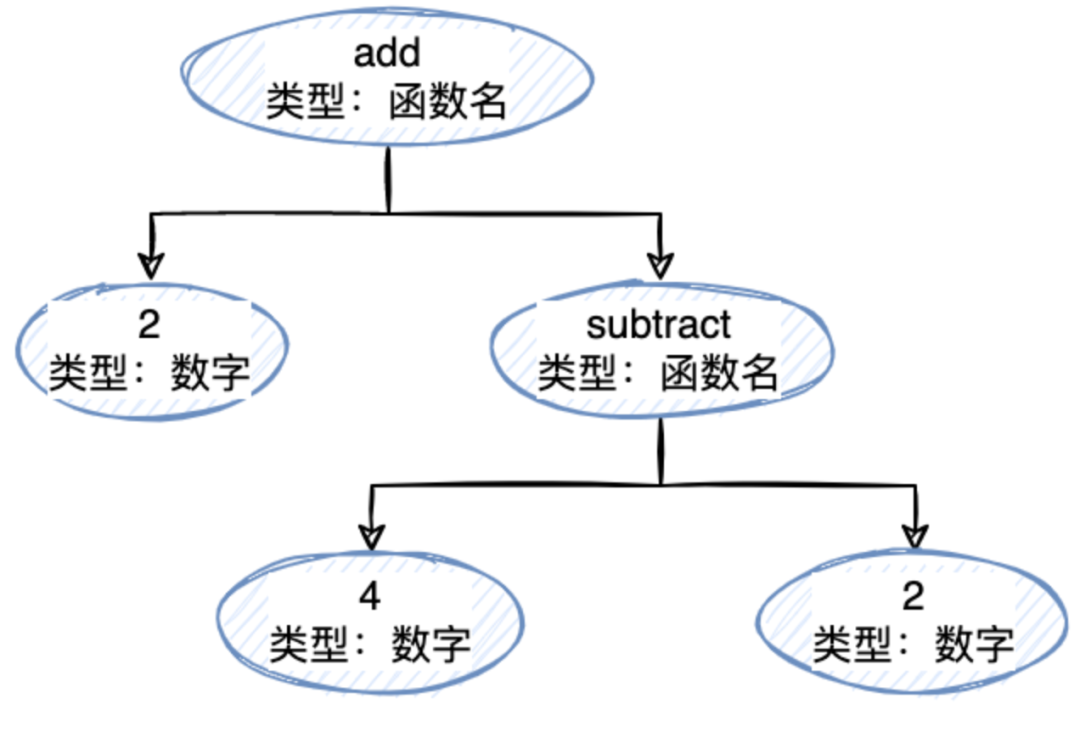
以上我們就能獲得一個 tokens 數組了,下一步就是構建一個抽象語法樹(AST)可能看起來像這樣:
{ type:'Program', body:[{ type:'CallExpression', name:'add', params:[{ type:'NumberLiteral', value:'2', },{ type:'CallExpression', name:'subtract', params:[{ type:'NumberLiteral', value:'4', },{ type:'NumberLiteral', value:'2', }] }] }] }
代碼思路:
同樣我們也需要有一個光標/指針來幫我們辨認當前操作的對象是誰,然后預先創建我們的 AST 樹,他有一個根節點叫做 Program:
letcurrent=0; letast={ type:'Program', body:[], };
再來看一眼我們之前獲得的 tokens 數組:
[ {type:'paren',value:'('}, {type:'name',value:'add'}, {type:'number',value:'2'}, {type:'paren',value:'('}, {type:'name',value:'subtract'}, {type:'number',value:'4'}, {type:'number',value:'2'}, {type:'paren',value:')'}, {type:'paren',value:')'}, ]
你會發現對于 (add 2 (subtract 4 2)) 這種具有嵌套關系的字符串,這個數組非常“扁平”也無法明顯的表達嵌套關系,而我們的 AST 結構就能夠很清晰的表達嵌套的關系。對于上面的數組來說,我們需要遍歷每一個標記,找出其中是 CallExpression 的 params,直到遇到右括號結束,所以遞歸是最好的方法,所以我們創建一個叫 walk 的遞歸方法,這個方法返回一個 node 節點,并存入我們的 ast.body 的數組中:
functionwalk(){ //在walk函數里面,我們首先獲取`current`標記 lettoken=tokens[current]; } while(current
下面就來實現我們的 walk 方法。我們希望這個方法可以正確解析 tokens 數組里的信息,首先就是要針對不同的類型 type 作區分:
首先先操作“值”,因為它是不會作為父節點的所以也是最簡單的。在上面我們已經了解了值可能是數字 (subtract 4 2) 也可能是字符串 (concat "foo" "bar"),只要把值和類型匹配上就好:
//首先先檢查一下是否有`number`標簽. if(token.type==='number'){ //如果找到一個,就增加`current`. current++; //然后我們就能返回一個新的叫做`NumberLiteral`的AST節點,并賦值 return{ type:'NumberLiteral', value:token.value, }; } //對于字符串來說,也是和上面數字一樣的操作。新增一個`StringLiteral`節點 if(token.type==='string'){ current++; return{ type:'StringLiteral', value:token.value, }; }
接下去我們要尋找調用的表達式(CallExpressions)。每匹配一個左括號,就能在下一個得到表達式的名字,在沒有遇到右括號之前都經過遞歸把樹狀結構豐富起來,直到遇到右括號停止遞歸,直到循環結束。從代碼上看更加直觀:
if( token.type==='paren'&& token.value==='(' ){ //我們將增加`current`來跳過這個插入語,因為在AST樹中我們并不關心這個括號 token=tokens[++current]; //我們創建一個類型為“CallExpression”的基本節點,并把當前標記的值設置到name字段上 //因為左括號的下一個標記就是這個函數的名字 letnode={ type:'CallExpression', name:token.value, params:[], }; //繼續增加`current`來跳過這個名稱標記 token=tokens[++current]; //現在我們要遍歷每一個標記,找出其中是`CallExpression`的`params`,直到遇到右括號 //我們將依賴嵌套的`walk`函數來增加我們的`current`變量來超過任何嵌套的`CallExpression` //所以我們創建一個`while`循環持續到遇到一個`type`是'paren'并且`value`是右括號的標記 while( (token.type!=='paren')|| (token.type==='paren'&&token.value!==')') ){ //我們把這個節點存到我們的`node.params`中去 node.params.push(walk()); token=tokens[current]; } //我們最后一次增加`current`變量來跳過右括號 current++; //返回node節點 returnnode; }
3.2 轉換
編譯器的下一個階段是轉換。要做的就是獲取 AST 之后再對其進行更改。它可以用相同的語言操作 AST,也可以將其翻譯成一種全新的語言。
那如何轉換 AST 呢?
你可能會注意到我們的 AST 中的元素看起來非常相似。這些元素都有 type 屬性,它們被稱為 AST 結點。這些節點含有若干屬性,可以用于描述 AST 的部分信息。
//我們可以有一個“NumberLiteral”的節點: { type:'NumberLiteral', value:'2', } //或者可能是“CallExpression”的一個節點: { type:'CallExpression', name:'subtract', params:[...嵌套節點放在這里...], }
對于轉換 AST 無非就是通過新增、刪除、替換屬性來操作節點,或者也可以新增節點、刪除節點,甚至我們可以在原有的 AST 結構保持不變的狀態下創建一個基于它的全新的 AST。
由于我們的目標是一種新的語言,所以我們將要專注于創造一個完全新的 AST 來配合這個特定的語言。
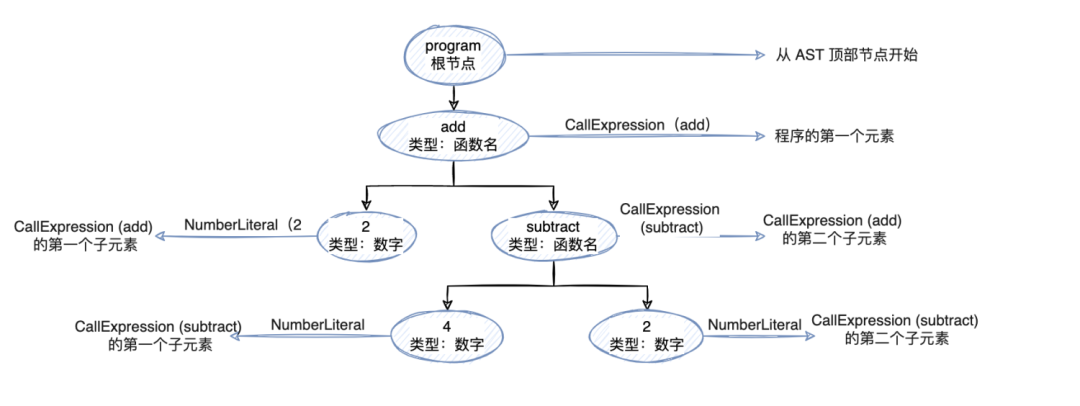
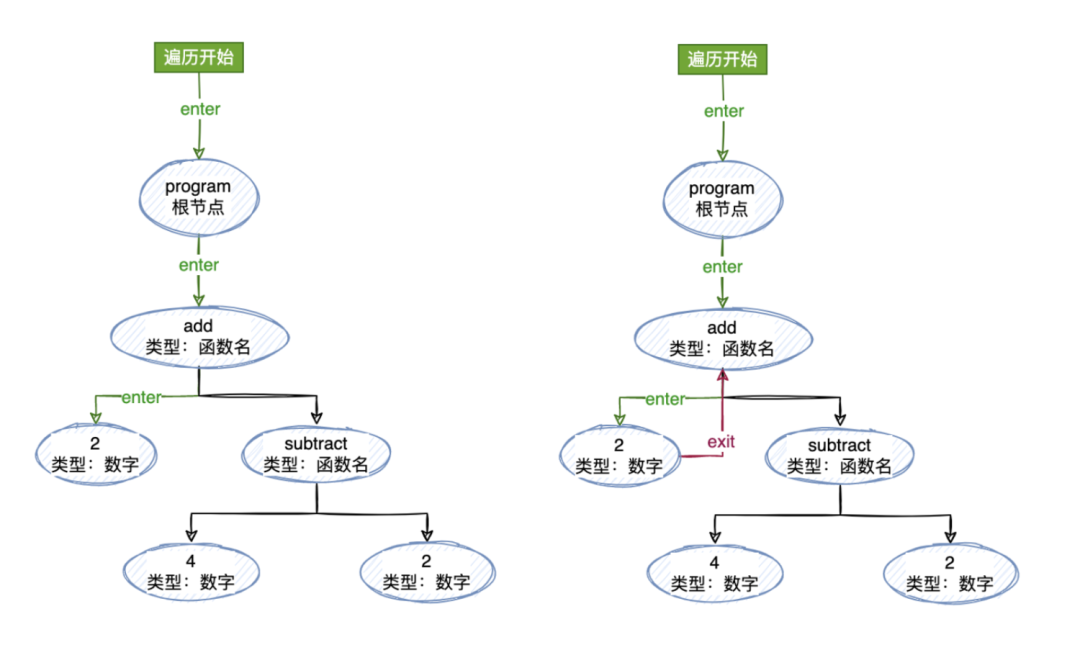
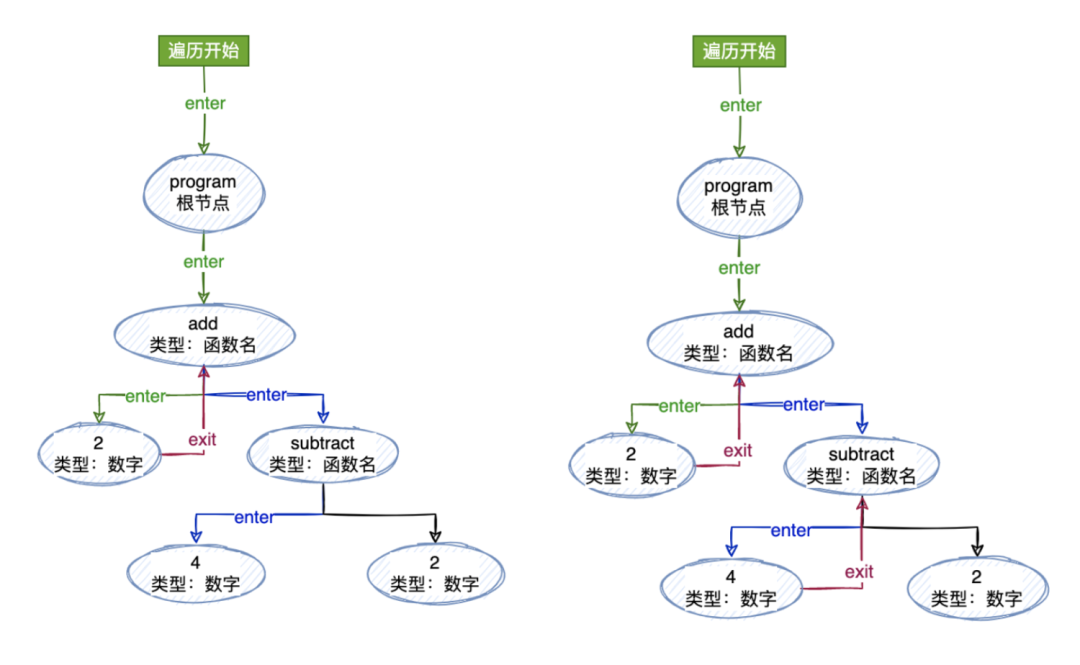
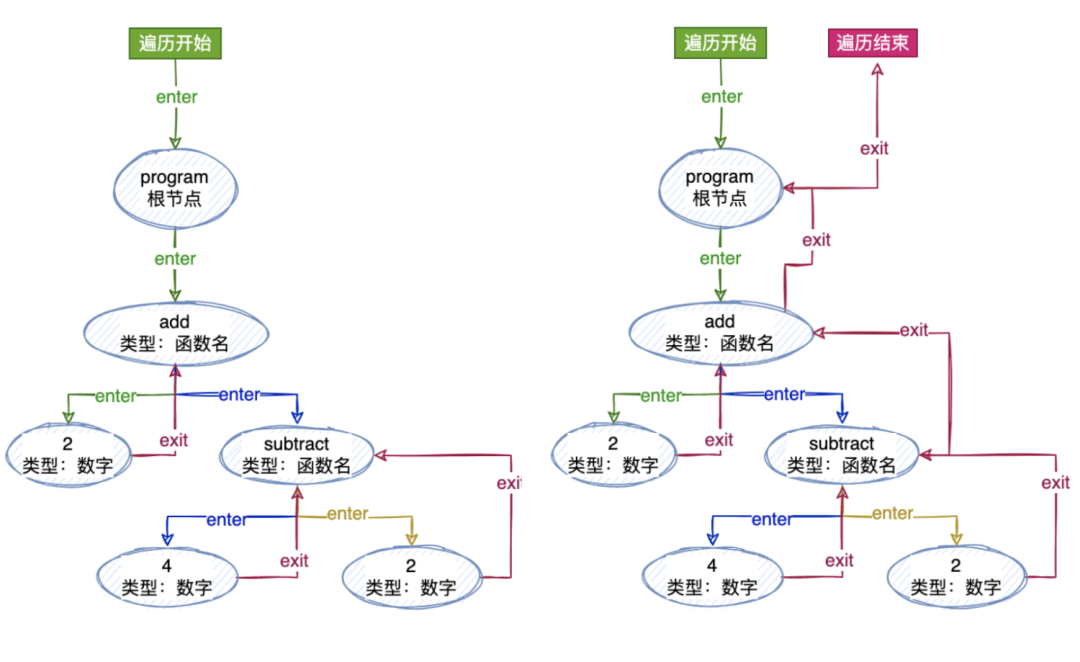
為了能夠訪問所有這些節點,我們需要遍歷它們,使用的是深度遍歷的方法。對于我們在上面獲取的那個 AST 遍歷流程應該是這樣的:
如果我們直接操作這個 AST 而不是創造一個單獨的 AST,我們很有可能會在這里引入各種抽象。但是僅僅訪問樹中的每個節點對于我們來說想做和能做的事情已經很多了。
(使用訪問(visiting)這個詞是因為這是一種模式,代表在對象結構內對元素進行操作。)
所以我們現在創建一個訪問者對象(visitor),這個對象具有接受不同節點類型的方法:
varvisitor={ NumberLiteral(){}, CallExpression(){}, };
當我們遍歷 AST 的時候,如果遇到了匹配 type 的結點,我們可以調用 visitor 中的方法。
一般情況下為了讓這些方法可用性更好,我們會把父結點也作為參數傳入。
varvisitor={ NumberLiteral(node,parent){}, CallExpression(node,parent){}, };
當然啦,對于深度遍歷的話我們都知道,往下遍歷到最深的自節點的時候還需要“往回走”,也就是我們所說的“退出”當前節點。你也可以這樣理解:向下走“進入”節點,向上走“退出”節點。
為了支持這點,我們的“訪問者”的最終形式應該像是這樣:
varvisitor={ Program:{ enter(node,parent){}, exit(node,parent){}, }, NumberLiteral:{ enter(node,parent){}, exit(node,parent){}, }, CallExpression:{ enter(node,parent){}, exit(node,parent){}, }, ... };
遍歷
首先我們定義了一個接收一個 AST 和一個訪問者的遍歷器函數(traverser)。需要根據每個節點的類型來調用不同的訪問者的方法,所以我們定義一個 traverseNode 的方法,傳入當前的節點和它的父節點,從根節點開始,根節點沒有父節點,所以傳入 null 即可。
functiontraverser(ast,visitor){ // traverseNode 函數將接受兩個參數:node 節點和他的 parent 節點 //這樣他就可以將兩者都傳遞給我們的訪問者方法(visitor) functiontraverseNode(node,parent){ //我們首先從匹配`type`開始,來檢測訪問者方法是否存在。訪問者方法就是(enter 和 exit) letmethods=visitor[node.type]; //如果這個節點類型有`enter`方法,我們將調用這個函數,并且傳入當前節點和他的父節點 if(methods&&methods.enter){ methods.enter(node,parent); } //接下去我們將按當前節點類型來進行拆分,以便于對子節點數組進行遍歷,處理到每一個子節點 switch(node.type){ //首先從最高的`Program`層開始。因為 Program 節點有一個名叫 body 的屬性,里面包含了節點數組 //我們調用`traverseArray`來向下遍歷它們 // //請記住,`traverseArray`會依次調用`traverseNode`,所以這棵樹將會被遞歸遍歷 case'Program': traverseArray(node.body,node); break; //接下去我們對`CallExpression`做相同的事情,然后遍歷`params`屬性 case'CallExpression': traverseArray(node.params,node); break; //對于`NumberLiteral`和`StringLiteral`的情況,由于沒有子節點,所以直接break即可 case'NumberLiteral': case'StringLiteral': break; //接著,如果我們沒有匹配到上面的節點類型,就拋出一個異常錯誤 default: thrownewTypeError(node.type); } //如果這個節點類型里面有一個`exit`方法,我們就調用它,并且傳入當前節點和他的父節點 if(methods&&methods.exit){ methods.exit(node,parent); } } //調用`traverseNode`來啟動遍歷,傳入之前的AST樹,由于AST樹最開始 //的點沒有父節點,所以我們直接傳入null就好 traverseNode(ast,null); }
因為 Program 和 CallExpression 兩種類型可能會含有子節點,所以對這些可能存在的子節點數組需要做進一步的處理,所以創建了一個叫 traverseArray 的方法來進行迭代。
//traverseArray函數來迭代數組,并且調用traverseNode函數 functiontraverseArray(array,parent){ array.forEach(child=>{ traverseNode(child,parent); }); }
轉換
下一步就是把之前的 AST 樹進一步進行轉換變成我們所期望的那樣變成 JavaScript 的 AST 樹:
如果你對 JS 的 AST 的語法解析不是很熟悉的話,可以借助在線工具網站來幫助你知道大致要轉換成什么樣子的 AST 樹,就可以在其他更復雜的場景進行應用啦~
我們創建一個像之前的 AST 樹一樣的新的 AST 樹,也有一個Program 節點:
functiontransformer(ast){ letnewAst={ type:'Program', body:[], }; //這里有個 hack 技巧:這個上下文(context)屬性只是用來對比新舊 ast 的 //通常你會有比這個更好的抽象方法,但是為了我們的目標能實現,這個方法相對簡單些 ast._context=newAst.body; //在這里調用遍歷器函數并傳入我們的舊的AST樹和訪問者方法(visitor) traverser(ast,{...}}; //在轉換器方法的最后,我們就能返回我們剛創建的新的AST樹了 returnnewAst; }
那我們再來完善我們的 visitor對象,對于不同類型的節點,可以定義它的 enter 和 exit 方法(這里因為只要訪問到節點并進行處理就可以了,所以用不到退出節點的方法:exit):
{ //第一個訪問者方法是NumberLiteral NumberLiteral:{ enter(node,parent){ //我們將創建一個也叫做`NumberLiteral`的新節點,并放到父節點的上下文中去 parent._context.push({ type:'NumberLiteral', value:node.value, }); }, }, //接下去是`StringLiteral` StringLiteral:{ enter(node,parent){ parent._context.push({ type:'StringLiteral', value:node.value, }); }, }, CallExpression:{...} }
對于 CallExpression 會相對比較復雜一點,因為它可能含有嵌套的內容。
CallExpression:{ enter(node,parent){ //首先我們創建一個叫`CallExpression`的節點,它帶有表示嵌套的標識符“Identifier” letexpression={ type:'CallExpression', callee:{ type:'Identifier', name:node.name, }, arguments:[], }; //下面我們在原來的`CallExpression`節點上定義一個新的 context, //它是 expression 中 arguments 這個數組的引用,我們可以向其中放入參數。 node._context=expression.arguments; //之后我們將檢查父節點是否是`CallExpression`類型 //如果不是的話 if(parent.type!=='CallExpression'){ //我們將用`ExpressionStatement`來包裹`CallExpression`節點 //這么做是因為單獨存在的`CallExpressions`在 JavaScript 中也可以被當做是聲明語句。 // //比如`vara=foo()`與`foo()`,后者既可以當作表達式給某個變量賦值, //也可以作為一個獨立的語句存在 expression={ type:'ExpressionStatement', expression:expression, }; } //最后我們把我們的`CallExpression`(可能有包裹)放到父節點的上下文中去 parent._context.push(expression); }, }
3.3 代碼生成
編譯器的最后一個階段是代碼生成,這個階段做的事情有時候會和轉換(transformation)重疊,但是代碼生成最主要的部分還是根據 AST 來輸出代碼。
代碼生成有幾種不同的工作方式,有些編譯器將會重用之前生成的 token,有些會創建獨立的代碼表示,以便于線性地輸出代碼。但是接下來我們還是著重于使用之前生成好的 AST。根據前面的這幾步驟,我們已經得到了我們新的 AST 樹:
接下來將調用代碼生成器將遞歸的調用自己來打印樹的每一個節點,最后輸出一個字符串。
functioncodeGenerator(node){ //還是按照節點的類型來進行分解操作 switch(node.type){ //如果我們有`Program`節點,我們將映射`body`中的每個節點 //并且通過代碼生成器來運行他們,用換行符將他們連接起來 case'Program': returnnode.body.map(codeGenerator) .join(' '); //對于`ExpressionStatement`,我們將在嵌套表達式上調用代碼生成器,并添加一個分號 case'ExpressionStatement': return( codeGenerator(node.expression)+ ';'//<
經過代碼生成之后我們就得到了這樣的 JS 字符串:add(2, subtract(4, 2)); 也就代表我們的編譯過程是成功的!
四、結語
以上就是編寫一個 LISP 到 JS 編譯器的全過程
那么,今天學到的東西哪里會用到呢?眾所周知的 Vue 和 React 雖然寫法上有所區別,但是“殊途同歸”都是通過 AST 轉化的前端框架。這中間最重要的就是轉換 AST,它是非常“強大”且應用廣泛,比較常見的使用場景:
IDE 的錯誤提示、代碼高亮,還可以幫助實現代碼自動補全等功能
常見的 Webpack 和 rollup 打包(壓縮)
AST 被廣泛應用在編譯器、IDE 和代碼優化壓縮上,以及前端框架 Vue、React 等等。雖然我們并不會常常與 AST 直接打交道,但它總是無時無刻不陪伴著我們。
審核編輯:劉清


-
編譯器
+關注
關注
1文章
1636瀏覽量
49173 -
LISP
+關注
關注
0文章
12瀏覽量
7729 -
AST
+關注
關注
0文章
7瀏覽量
2338
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論