 ADS感知計算:系統計算復雜度挑戰
ADS感知計算:系統計算復雜度挑戰
為了能夠深入解讀Tesla上述的這些設計理念,本文從ADAS感知算法演進和工程化需求的角度,首先來重點介紹Tesla于2021年底發布的用來改進原有HydraNet方案的Occupancy Network。
HydraNet是一種對8個攝像頭的視頻幀(36fps)分別進行空間變換矯正補償和特征提取(ResNet),在BEV空間進行多攝像頭的時空特征融合,然后進行多任務學習(行人檢測,交通燈,可行駛區域分割,等等)。如圖1所示的幾例交通事故場景,可以看出純視覺的HydraNet方案在目標檢測上存在的一些致命的缺陷,例如小樣本目標的漏檢誤檢問題,非立體的平面目標畫像的誤檢問題等等。其根因可以簡單歸納幾點(Thinkautonomous, 2022):
1、接近地平線的遠景區域深度極度不一致問題:
小樣本目標問題:遠距離目標的深度信息消失,或者超低分辨率很難決定一個目標區域的深度(例如圖右橋墩漏檢后導致致命性車輛撞擊問題)
2、遮擋問題:
鬼影問題:不能穿透遮擋區域或者行駛車輛來識別被遮擋目標,遮擋目標長記憶軌跡預測困難
3、2D或者2.5D視頻約束問題:
非立體的平面目標畫像問題:難以對應到真實3D場景,難區分靜態和動態目標
2D目標固定框問題:難以識別懸掛或者懸空的障礙物(可能不在目標檢測框內,例如卸貨卡車的千斤頂支撐架,卡車貨架頂上的人梯等)

圖1可行駛空間3D目標漏檢場景
Occupancy Network在HydraNet基礎上通過添加高度這個維度對2DBEV空間進行擴展,其首先對圖像的特征圖進行MLP學習生成Value和Key,在BEV空間通過柵格坐標的位置編碼來生成Query,新柵格的區別是采用原有的2D柵格和高度一起構成3D柵格,對應生成的特征也從BEV特征變成了Occupancy特征。
其設計思路來自機器人設計用的occupancy grid mapping,即將真實3D場景分割成一個個3D的柵格grid。如圖2所示,每個柵格存在兩種狀態(占用或空閑),可以是多視覺3D呈現的Occupancy Volume,當然為了處理速度,目標的形狀不會是一種精確表征,只能是簡單逼近,但可以用來區分靜態和動態目標(更像是一個3D的blob),可以以3x以上的幀速運行(>100fps),內存占用也非常高效。
Occupancy Network將3D空間圖分割成一個個超小的cub或者voxel,通過DNN模型做占空兩個狀態的預測,顯然可以解決上述2D目標固定框問題(即所謂的懸空障礙物的問題),以及換了一種思維設計來解決業界難以實現的通用目標檢測器的問題(即所謂數據長尾效應下對未知障礙物的識別和避障能力問題)。
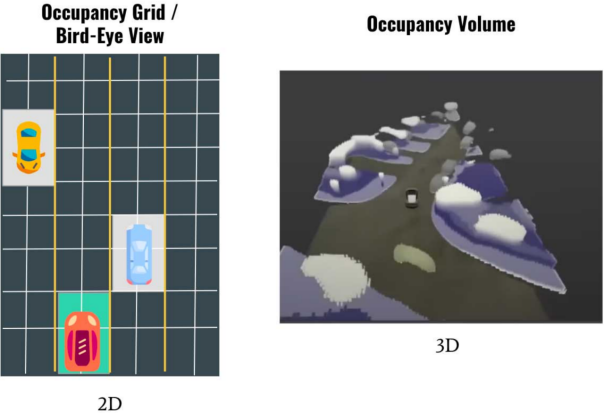
圖 2Occupancy Network與HydraNet目標表征對比
Occupancy Network網絡架構分析
如圖3所示,Occupancy Network在HydraNet基礎上,依舊采用Regnet + BiFPN進行特征提取,Attention模塊采用圖像位置編碼,利用Key, Value和固定的查詢(car vs not car, but vs not bus, traffic sign vs not traffic sign)來生產Occupancy Feature Volume。
時空融合后會生成4D Occupancy Grid。通過Deconvolution進行特征增強到原有尺寸,可以通過網絡層輸出上述討論過的Occupancy Volume,以及Occupancy Flow。Occupancy Flow其實就是針對每個voxel進行光流估計來觀察每一輛車在3D定位下運動流的向量預測(例如目標方向: red-向前;blue:backward;grey-stationary, 等等),可以用來有效解決目標遮擋問題,以及多目標運動預測與規劃等。
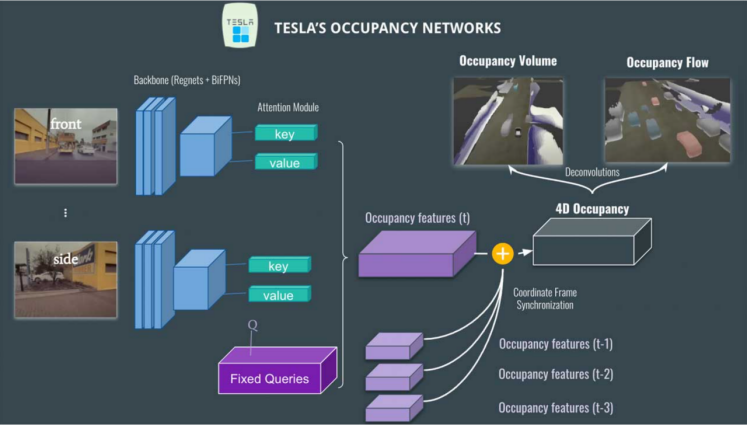
圖 3Occupancy Network架構
Tesla AI day上所介紹的Full Self Driving(FSD)解決方案框架中包括訓練數據(Auto Labelling, Simulation, Data Engine)、感知NN(Occupancy, Lanes & Objects)和規劃決策Planning三個模塊,以及AI模型的編譯訓練和推理部署的優化策略。
感知模塊(Lanes, Occupancy, Moving Objects)為規劃決策聯合建模提供視覺度量數據(Sparse Abstractions, Latent Features),通過幾何空間占有率來理解3D維度的遮擋問題,從而解決目標交互遮擋中產生的不確定性因素。其中Occupancy 展示在車道上發生了什么,而Sparse Abstractions用來對車道,道路使用者,運動目標等進行稀疏表征和特征編碼,稀疏表征特性除了減少復雜度以外,應用優勢包括可以將路口區域IOU提升4.2%等等。Occupancy網絡通過構建可駕駛的Surface,通過對道路上人車和障礙物的3D信息構建和呈現,預測這些目標物的屬性、運動狀態和趨勢。

Occupancy子模塊的特性包括:
Volumetric Occupancy
Multi-Camera & Video Context
Persistent Through Occlusions
Occupancy Semantics
Occupancy Flow
Resolution Where It Matters
Efficient Memory and Compute
Runs in around 10 milliseconds
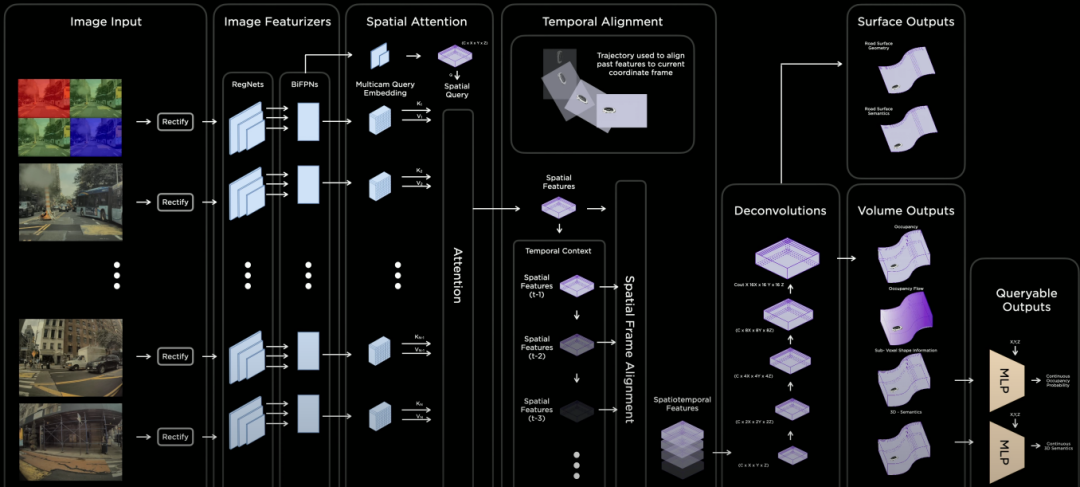
圖 4Tesla Occupancy Network模塊架構
在圖 4中,輸入采用未經過ISP處理的raw RGB圖像(10-bit Photon Count Stream,36Hz,在低照場景下感光度高,噪聲小),可以讓特征提取模塊同步也進行低照增強學習,可以將整體召回率提升3.9%,準確率提升1.7%左右。
從圖 4還可以看出,Occupancy Network在Rectify層進行圖像的View Transformation,然后采用Regnet + BiFPN進行特征提取,Attention模塊采用圖像位置編碼,采用Key, Value和Query來生產occupancy feature volume。利用里程計的定位信息進行柵格特征的時間軸對齊,以及特征信息時空融合后會生成4D Occupancy Grid。
通過Deconvolution進行特征增強到原有尺寸,可以通過網絡層輸出Volume(Occupancy Volume, Occupancy Flow, Sub-Voxel形狀信息,和3D的語義信息)和Surface(道路表面幾何信息和語義信息)。對接Volume還可以輸出輕量級可查詢的輸出,包括連續的Occupancy概率和3D語義理解,這種設計思路除了可以提供Occupancy的速度加速度外,查詢功能還可以提供類似NeRF的分辨率可變化的聚焦能力。輸出3D Volume和Surface信息,可以提供NeRF狀態信息,通過Volumetric Rendering來生成不同角度的3D場景重建。
總體而言,Tesla AI day上介紹的純視覺的Occupancy Network的推理計算時間在10毫秒左右,對應視頻的36Hz采樣速度,與10Hz采樣速度的LiDAR而言,對高速目標的感知能力,可以有很強的優勢。同時從2D BEV特征演進到3D Occupancy特征,可以有效應對曲面地面感知和有高低變化的車道線感知,提升3D目標輪廓的定位誤差。
Tesla采用低精度LD地圖并對車道線幾何/拓撲關系的信息,車道線數量,寬度,以及一些特殊車道屬性等信息來進行編碼,與視覺感知的特征信息一起用來生成車道線Dense World Tensor提供給Vector Lane模塊,由于篇幅原因其具體細節將會另文進行對比分析。
ADS感知計算的演進趨勢分析
對于自動駕駛ADS行業,我們可以將其核心演進趨勢定義為群體智能的社會計算,簡單表述為,用NPU大算力和去中心化計算來虛擬化駕駛環境,通過數字化智能體(自動駕駛車輛AV)的多模感知交互(社交)決策,以及車車協同,車路協同,車云協同,通過跨模數據融合、高清地圖重建、云端遠程智駕等可信計算來構建ADS的社會計算能力。
在真實的交通場景里,一個理性的人類司機在復雜的和擁擠的行駛場景里,通過與周圍環境的有效協商,包括揮手給其它行駛車輛讓路,設置轉向燈或閃燈來表達自己的意圖,來做出一個個有社交共識的合理決策。而這種基于交通規則+常識的動態交互,可以在多樣化的社交/交互駕駛行為分析中,通過對第三方駕駛者行為和反應的合理期望,來有效預測場景中動態目標的未來狀態。這也是設計智能車輛AV安全行駛算法的理論基礎,即通過構建多維感知+行為預測+運動規劃的算法能力來實現決策安全的目的。
在ADS動態和不確定性的場景中,環境需要建模成部分可觀察的馬爾可夫決策過程MDP即POMDP,為了降低計算復雜度,一般都選擇離散化空間或者部分連續空間來解決POMDP問題。對不確定性信息評估的一種常用的做法是對當前狀態進行概率分布進行構建,得到一個置信(belief)狀態,這種形態可以通過離線或者在線構建。
駕駛者的決策過程,可以轉化為對部分可觀察環境虛擬化或參數化,同時對個體間社交選擇的偏愛進行參數化,嵌入到價值函數中去,通過基于優化的狀態反饋策略,尋求駕駛群體利益最大化問題的最優解。
ADS算法的典型系統分層架構,一般包括傳感層,感知層,定位層,決策層(預測+規劃)和控制層。ADS算法的典型系統分層架構如圖5所示,對ADS感知計算而言,目前已經從多模數據結構化+決策層后融合演進到了一個全新的Birds-Eye-View (BEV)統一空間感知融合架構,即4D時空的多模態多任務學習+傳感信息協同共享。對比Tesla純視覺模態的技術方案,ADS感知算法面臨的類似挑戰具體體現在:
能夠在統一BEV空間支持多模傳感器感知融合,通過Multiview Camera +LiDAR/Radar組合模式,但需要解決3D目標定位誤差問題、漏檢誤檢、目標發現不及時問題,以及路面下曲面目標感知、車道線信息缺失/不規則/不清晰、3D場景下復雜車道線感知能力不足等問題。
能夠在統一BEV空間支持多模組合多任務共享,需要提升有限算力下的計算效率,更需要降低設計方案的計算復雜度。
能夠提供全場景的適配能力,需要解決算法模型在信息提取中對極端惡劣場景(雨雪霧、低照度、高度遮擋、傳感器部分失效、主動或被動場景攻擊等)的泛化感知能力,降低對標注數據和高清地圖的過度依賴。
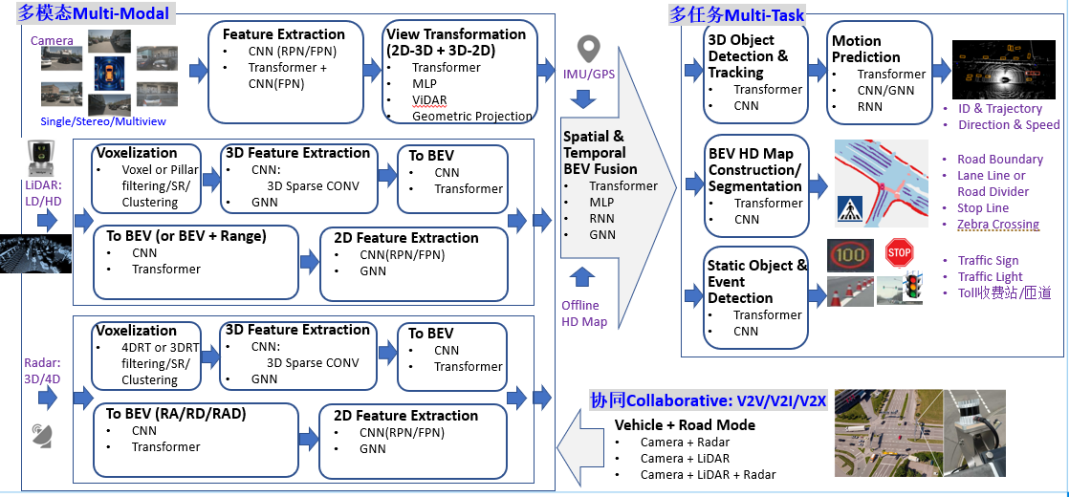
圖5BEV統一空間感知融合架構案例
ADS感知計算:系統計算復雜度挑戰
ADS感知計算,其實主要是對物理世界的一個3D幾何空間重建任務。對比Tesla和行業主流設計方案的異同,可以看出選擇BEV空間的獨特優勢,它消除了2D任務中常見的Perspective-View(PV,2D空間)下重疊遮擋或者比例問題,便利于隨后進行預測規劃和控制。如圖5所示,BEV感知計算可以分成三個部分:
BEV Camera:純視覺或者以視覺為主,Single/Stereo/Multi-view多方位配置, 感知計算包括3D目標識別和分割
BEV LiDAR:基于點云/Grid/Voxel進行目標檢測或者場景分割任務
BEV Radar:基于Range/Angle/Doppler進行大目標檢測或者場景分割任務
BEVFusion:多模融合,包括Camera, LiDAR, GNSS, Odometry, HD Map, CAN-bus等等。
在圖5中,BEV感知計算通常包括2D或者3D特征提取,View Transformation視覺變換(可選,也可以直接采用Front-View,或者直接對2D特征進行3D目標識別)和3DDecoder。采用2D特征提取或者2D View Transformation在2D空間進行顯然可以降低計算復雜度,但會帶來性能損失。
3DDecoder可以在2D/3D空間直接對特征進行3D感知多任務計算,包括3D目標bounding box檢測,BEVmap Segmentation分割, 3D Lane Keypoints檢測等等。
類似于Tesla所采用的BEV Camera純視覺方案中,View Transformer模塊可以分成兩個部分:
1、2D-3D Mapping:
Geometric Projection:工業界較常用,數學計算復雜度高,多在CPU上進行運算,負載重,而且空間對齊也是一個問題,類似Tesla同時采用一個額外NN網絡進行補償矯正。
DNN-alike:計算復雜,可以用GPU/NPU進行運算,減少CPU負荷,如果能夠添加深度信息提取通道,可以增強系統性能。
2、3D-2DMapping
Grid Sampler:工業界常用,但依賴于Camera參數,長期使用有偏移問題。
MLP或者Transformer:通過Cross-Attention來進行幾何空間變換,計算量會比較大。
在圖5中,BEVLiDAR通道,通常可以采用幾種數據表征Points, BEVGrid,Voxel, Pillar。相對而言,Pillar是一種特殊類型的Voxel,通過柱形映射到2D空間,擁有無限高度屬性。采用Pillar特征可以大大減少內存空間和計算復雜度,可以說是工程化中一個非常好的折衷。
在這里值得一提的是,對于Transformer進行3D目標檢測的計算復雜度問題,尤其是針對BEVLiDAR或者BEVRadar數據,在覆蓋的駕駛區域非常大的場景(100m x 100m)下,如何有效降低內存需求和感知計算復雜度。這需要從Transformer網絡架構層面針對超大點云數據處理方式進行有效調整。
以3D目標檢測與跟蹤為例,Transformer Encoder中輸入Token數量顯著變多后,Token間自關注Self-Attention模塊計算對內存需求成二次元非線性方式加速度增加。簡單地采用Point-based或者BEV-Grid-based亞采樣導致Token跨越區域或者Grid會導致目標檢測性能嚴重受損。
一種設計思路案例如圖 6所示,用計算復雜度低的主干網絡backbone,例如PointPillars來完全替代Transformer Encoder。Transformer Encoder的優勢是在于可以更好地提取上下文的全局特征信息,而CNN網絡可以很好地對上下文局部信息進行編碼和特征提取。
主干網絡的特征輸出進行降維變換成一系列Token(特征向量),而且網絡類型的可選取范圍也相對比較廣,只要能夠在BEV Grid或者3D空間內提供特定位置的特性向量就可以。Transformer Encoder這個計算瓶頸模塊被移除后, Token長度N的選取可以更大一些,如果decoder輸入查詢Q的數量是M, 對應Transformer Decoder的最大Cross Attention矩陣的尺寸是N x M,其中N 遠遠大于M。
在Decoder分層傳遞中通過采用一種查詢刷新的策略,可以有效彌補Transformer Encoder被替換后估計精度下降的問題。值得一提的是Transformer Decoder輸出的矢量是可以語義解釋的Object-bound的特征向量,可以直接做為ReID特征項用于目標跟蹤,同時這種設計思路可以拓展到Multi-modal多模輸入。
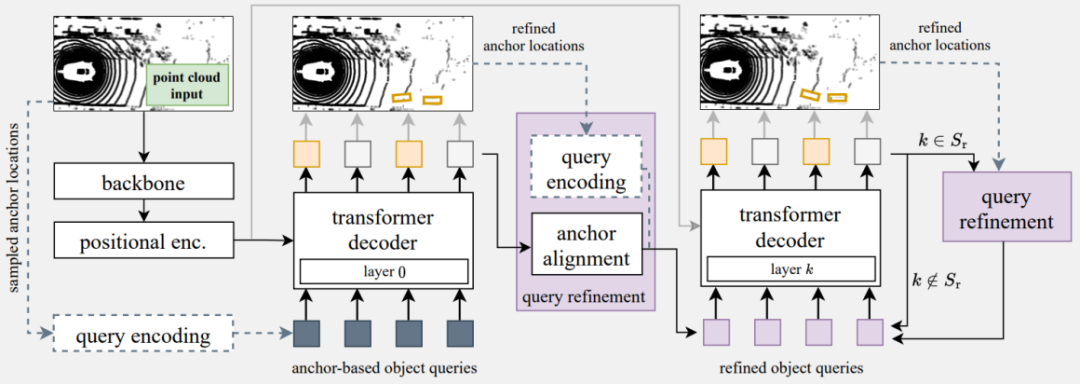
圖63D目標檢測的改進架構案例
審核編輯:劉清
-
檢測器
+關注
關注
1文章
867瀏覽量
47724 -
ADAS技術
+關注
關注
0文章
21瀏覽量
3285 -
FSD
+關注
關注
0文章
95瀏覽量
6137 -
MLP
+關注
關注
0文章
57瀏覽量
4257
原文標題:特斯拉ADS算法的自我革命
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCB與PCBA工藝復雜度的量化評估與應用初探!
基于紋理復雜度的快速幀內預測算法
嵌入式視頻教程之軟硬件關系的復雜度
嵌入式視頻教程之軟硬件關系的復雜度
嵌入式視頻教程之軟硬件關系的復雜度
如何降低LMS算法的計算復雜度,加快程序在DSP上運行的速度,實現DSP?
時間復雜度是指什么
圖像復雜度對信息隱藏性能影響分析
基于移動音頻帶寬擴展算法計算復雜度優化
基于QR分解的低復雜度的可靠性約束算法

一種低復雜度稀疏信道估計算法的詳細資料說明
常見機器學習算法的計算復雜度
如何計算時間復雜度






 工商網監
工商網監
評論