 簡述SystemVerilog的各種隨機化方法
簡述SystemVerilog的各種隨機化方法
我習慣將驗證空間理解為:驗證中原則上需要覆蓋的芯片所有有可能出現的工作狀態的集合。為了探索這片廣袤的驗證空間,驗證的時候搞出了帶有約束的隨機測試(constrainted-random testing),并搞了覆蓋率(coverage)作為評估機制。這也是一套成熟可信的工程學方法。
因為約束和隨機化可以講的干貨太多,于是我做了拆分。本文要介紹的內容就僅涉及SV的隨機化處理,包括偽隨機數的產生、隨機穩定性和編程示例。
偽隨機數的產生
SystemVerilog提供了很多生成偽隨機數的方法,比如產生隨機數的內建函數**random, **urandom, $urandom_range,對象隨機方法object.randomize(),標準庫隨機函數std::randomize()等等。這些函數的用法在很多教程中都會提到,而本文要做的,是要挖一挖這些函數的“玄機”。

1. Probabilistic Distribution System Functions
第一類隨機函數是概率分布系統函數(probabilistic distribution system funtions),這類函數在LRM中明確包括**random, **dist_uniform, **dist_normal, **dist_exponential, $dist_poisson等可以產生滿足不同概率分布的隨機數的函數,并且在附錄N中用C代碼給出了這些函數的實現算法。這就意味著,使用相同的種子,這些函數在不同的仿真軟件中產生出來的隨機數序列應該是一致的。這也是這類函數跟其他類函數的主要區別。
2. Object and Scope Randomization Method
再來看對象隨機方法object.randomize(),這個函數在LRM中被稱為“the object and scope randomization method”。顧名思義,它專門被用來隨機化對象。它是所有SV類中都會默認存在的內置虛函數(原型是virtual function int randomize()),但是它不能被覆蓋(overridden)。當你使用object.randomize() 來對對象進行隨機化的時候,注意它只會隨機化類中有rand關鍵詞修飾的成員變量,并且在成功隨機化之后會返回1,失敗則返回0。除此之外,每個類中還有randomize的兩個回調函數pre_randomize()和post_randomize(),這兩個函數分別會在執行randomize()的前后自動被調用。注意,這兩個函數并不是虛函數(其函數原型沒有virtual關鍵字),但他們是由虛函數randomize()來自動調用的,因此也表現為虛函數的多態行為。
這套使用類來描述和控制隨機數據及其約束的機制相當強大。之所以這么說,一方面是因為有了類的繼承特性的加持,隨機變量可以方便地繼承和擴展;另一方面是因為SV還提供了約束的覆蓋、擴展、使能和禁用等功能。但這里有一個問題,就是object.randomize()還是只能隨機化類的成員變量,不能隨機化局部變量。為了解決這個問題,SV又搞來了一個可用于當前范圍內,且不限于對象成員的隨機化函數std::randomize(),它在LRM中的定性是scope randomize function。
Std lib下的std::randomize()的適用性比object.randomize()要好,不過它不能自動隨機對象中的rand成員變量,也沒有pre和post函數可以調用,畢竟魚和熊掌不可兼得呀。std::randomize()在某些場景下前面的“std::”是可以省略的,但還是建議使用的時候加上比較好,能與上面講的object.randomize()做出區分。除了可以隨機化當前范圍內變量,std::randomize()使用的時候可以將需要隨機化的多個變量同時放到參數列表中一起做隨機,且能適配這些變量的位寬。該函數返回結果跟object.randomize()一樣,成功返回1,失敗返回0。
3. Random Number System Function
最后要將講的是SV中比較古老的隨機函數和方法urandom()和urandom_range()。后者只是在前者的基礎上增加了范圍限制。**urandom的函數原型是function int unsigned **urandom [(int seed)]。可以看出來,這兩個函數的返回值都是32bit的無符號數。如果初始隨機種子一樣,則相同工具的每一次仿真跑出來的隨機數是一致的,這是涉及到下小節要講的一個重要的特性:隨機穩定性。
隨機穩定性(Random stability)
在SV中,不同線程(thread)或對象(object)在隨機化時使用的隨機數產生器(RNG)是相互獨立的。另一方面,相同線程或相同對象在相同隨機種子的情況下,每一次仿真中產生的隨機數序列是一樣的。這個屬性就叫random stability。
隨機穩定性之所以重要,是因為在芯片驗證中,隨機驗證方法是很重要的一部分,在用例回歸之后,那些Failed的測試用例通常需要使用觸發錯誤的隨機種子來重現,比如把波形Dump出來。因此,有必要了解線程和對象的隨機化機制。下面從三個層面看這套機制是怎么運作的。
**Initialization RNG:**初始化RNG是產生隨機數的開始,用來給RNG初始化隨機種子。每一個模塊實例(module instance)、接口實例(interface instance)、程序塊(program)和包(package)實例都有屬于自己的初始化RNG,在不指定隨機種子的情況下,默認的隨機種子根據不同編譯器的實現決定的。上小節講的每一種偽隨機數的產生方法都有自己指定隨機種子的函數
**Hierarchy seeding:**分層分配隨機種子是隨機穩定性的重要機制。在創建新的線程或者實例化對象的時候,父線程使用的RNG的下一個隨機值會作為這個新線程或者新對象的RNG的隨機狀態,即作為新的種子傳遞下去。
**Thread and Object Stability:**SV中將程序(program)、模塊(module)、接口(interface)、函數(function)、任務(task)等這些獨立的塊叫Process。每個Process都有自己的RNG。每個RNG都有自己的隨機狀態(random state)。我們可以通過process::self()這個靜態方法獲取當前Process的RNG句柄,在通過句柄調用get_randstate()方法來獲得隨機狀態。不同的仿真工具返回來的隨機狀態的值的表現方式可能會不一樣,但基本都是一段看起來沒有規律的字符串,這個字符串表示下一個要產生的隨機數的值。
SV的這套隨機穩定性機制,盡管通常不需要我們去做什么,但是要知道:在我們要復現一個執行失敗的測試用例的時候,不要改動之前布下的種子,也不要改變程序中線程和對象創建的順序,避免更改了分層隨機種子的順序。
編程示例
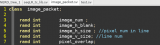
下面的例程和仿真結果展示了以上介紹到的隨機函數和特性,代碼中也附有必要的注釋。如果需要源碼,可以在公眾號中直接回復"SV隨機"獲得下載鏈接。
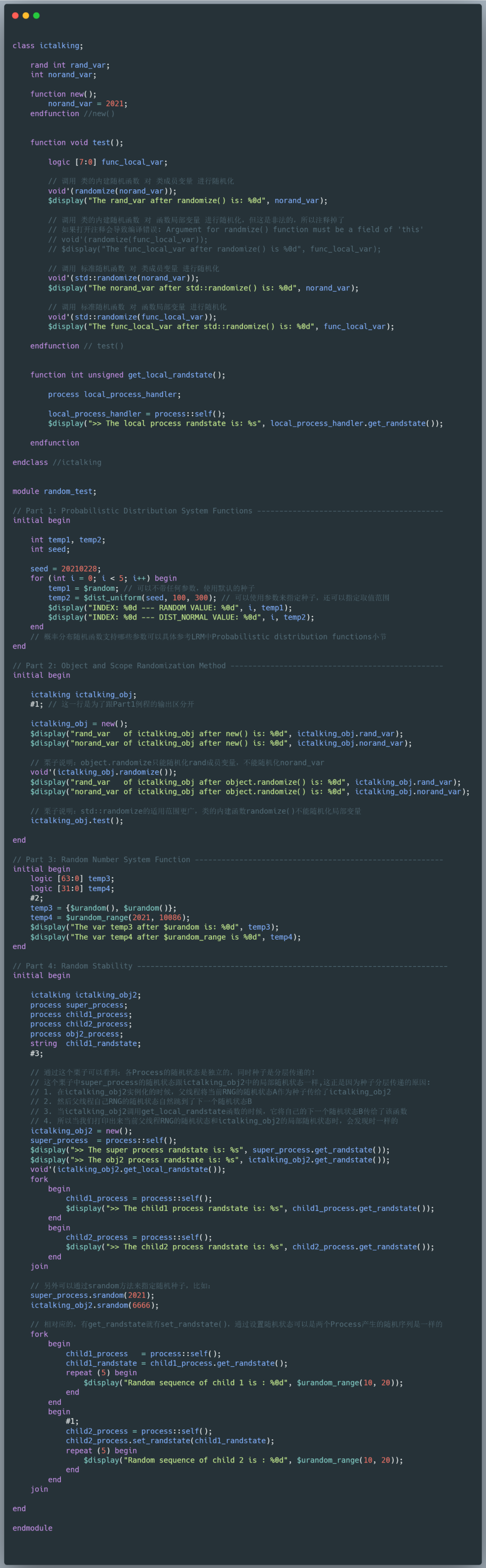
仿真結果如下圖所示:

參考文獻
[1] IEEE Standard Association. "IEEE Standard for SystemVerilog-Unified Hardware Design, Specification, and Verification Language." (2013).
-
芯片
+關注
關注
455文章
50851瀏覽量
423907 -
Verilog
+關注
關注
28文章
1351瀏覽量
110122 -
System
+關注
關注
0文章
165瀏覽量
36965
發布評論請先 登錄
相關推薦
求教!!LabVIEW怎樣數據的隨機化
高速ADC的數字輸出隨機化器
緩沖區溢出的危害及避免緩沖區溢出的三種方法
新的隨機化廣播加密方案
SystemVerilog中的隨機化激勵
System Verilog中的隨機化激勵
一種隨機化的軟件模型生成方法
華為手機已經開啟了MAC地址隨機化功能可以有效的防范WiFi探針
華為手機EMUI 8.0及以上版本已經默認開啟了MAC地址隨機化功能
固態硬盤的順序讀寫和隨機讀寫有何區別
簡述SystemVerilog的隨機約束方法
SV約束隨機化總結





 工商網監
工商網監
評論