

過去十年,全球迎來一場 AI 革命,人工智能在各行各業引發了顛覆性的變革。在機器學習、深度學習、大規模語言模型等 AI 能力的加持下,自動駕駛、生物醫藥、行業大模型、智算中心等行業和領域正迎來百萬倍的效率飛躍。而這一切的背后,離不開加速計算。
在今日舉行的“2022 百度云智峰會·智算峰會”上,NVIDIA 亞太區開發與技術部總經理李曦鵬分享了以“加速計算助力智能云深入產業”為題的演講,介紹了 NVIDIA 在加速計算領域的思考及洞見,包括 NVIDIA 如何與客戶一起探索互聯網行業的加速計算解決方案,實現端到端的極致性能優化,以及加速計算可以如何助力云深入到行業。以下為內容概要。

10 年 100 倍,加速計算價值千億的巨大空間
我們首先看一下加速計算,以及各種計算任務(workload)如何上云。
對于一個現代的加速計算集群,這個集群可以是云上的一個高性能集群,也可以是客戶自建的一個加速計算集群。它們需要去承擔非常多種類的計算任務,從 AI 任務到 simulation(模擬或仿真),以及二者的組合 Sim+AI,或者 AI for Science,再到目前最火爆的數字孿生、量子計算等。大家可以看到,加速計算集群需要去支撐的計算任務非常豐富,實際上,這里還有大量,類似于數據處理、云端渲染、信息召回,數據庫等也同樣需要去加速的計算任務沒有羅列出來。
大家可能會說,上面的這些計算任務是一個數據中心的典型應用,為什么要說是加速計算集群的典型應用呢?過去幾十年間,得益于摩爾定律,算力在持續增長。但如今摩爾定律已經放緩,從最初每年 1.5-1.6 倍性能的提升,下降到如今每年 1.1 倍左右的提升。與此同時,加速計算卻依然保持著每年 1.6x 以上的性能增速。五年可以實現 10 倍的性能提升,十年就可以實現 100 倍的提升,這與摩爾定律十年可以實現的 4 倍性能提升形成了顯著的差異。
另一個方面,碳足跡、能源消耗,以及機房空間等各個因素,都制約了傳統計算的規模擴大。如果大家看一下使用了加速計算的 Green 500 前 30 的超級計算機,它們的平均效能比是其他超級計算機的 7 倍多。這不但帶來了能源的節省,也同時帶來了更低的成本,使得我們的計算任務,特別是以 AI 為代表的計算任務可以不斷地持續增加。
針對 AI 部分,和大家通常理解的只是模型訓練和預測不同,NVIDIA 一方面需要對整個工作流提供端到端的加速,另外,也需要通過對不同部分的模塊化,普惠到更多企業和終端用戶。NVIDIA 在這方面一直引領業界,我們也提供了從基礎設施、調度、加速庫、加速框架、部署工具,一直到最上層的應用框架的全套解決方案,也就是 PPT 中所展示的 NVIDIA AI 平臺軟件 NVIDIA AI Enterprise。這里我就不具體展開,只是舉一個例子。
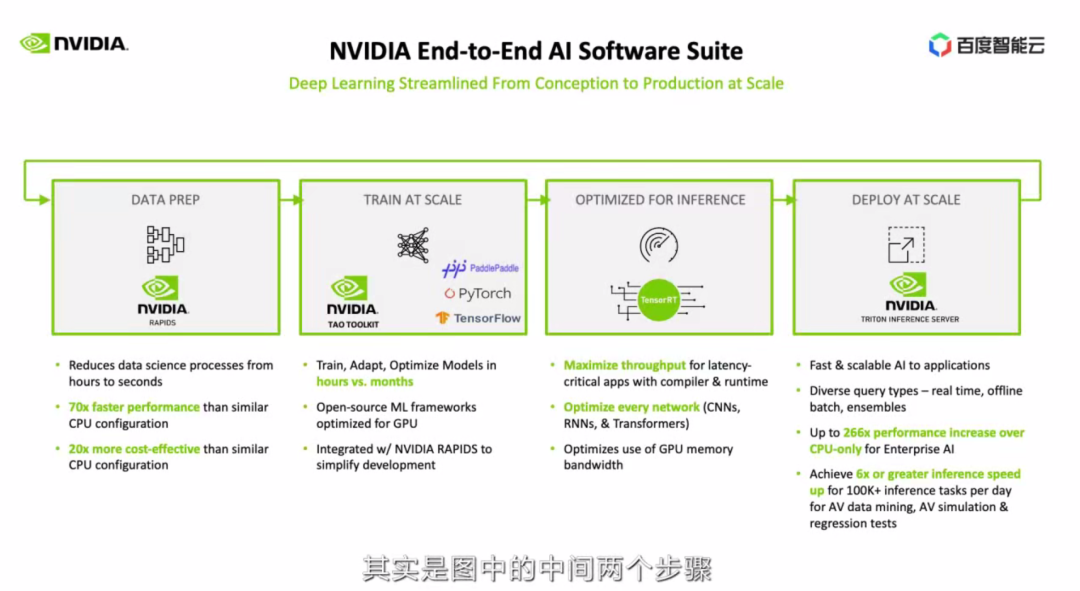
我們以典型的 AI 模型端到端流程,介紹 NVIDIA 能提供什么支持。通常我們看到的,其實是圖中中間的兩個步驟,訓練和預測,還有部分人在預測的時候也會簡單使用框架進行預測。但是實際上,問題比這個復雜很多。
首先我們需要去做數據預處理,這里 NVIDIA 提供了 RAPIDS (針對結構化的數據),CV-CUDA(針對圖片數據)等各種解決方案。
數據預處理的一個難點,需要做到訓練預測的一致性,減少調試過程。處理好的數據需要喂給模型訓練,模型訓練企業用戶可以選用不同的框架。NVIDIA 加速了 PyTorch、TensorFlow、JAX,還有國內越來越流行的 PaddlePaddle 等框架。同時,也有 TAO Toolkit 來做遷移學習。
這里的一個難點是,需要做好數據預處理和訓練的流水,避免頻繁的數據搬運。有了模型之后,我們需要做預測優化。TensorRT 是現在精度最高、速度最快的深度學習推理優化器,NVIDIA 也在不斷提高它的性能,并與各個深度學習框架集成,降低使用門檻。有了加速預測的模型后,我們可以使用 Triton 來進行大規模的部署。而實際使用中采集到的新數據,又可以用于訓練。如果我們只是加速其中一部份,是沒有辦法達到模型的快速迭代,和實現整體性能的成倍提升,因此我們強調端到端的優化。
剛才我們以 AI 為例,講到了 AI 類的計算任務如何可以被加速。但是實際上,目前世界上只有 5% 的計算任務被加速,這已經是幾百億美金的市場。
//
未來十年,所有的計算任務都將被加速,包括現有的以及十倍于現階段的新計算任務!這將為加速計算市場帶來 100 倍的增長空間!
NVIDIA 在加速計算的探索與經驗
大家可能會覺得,NVIDIA 真是高瞻遠矚,早早落子各個行業的加速計算方案。但是實際上,今天大家看到的解決方案,都是 NVIDIA 基于客戶的實際需求,與客戶深入合作出來的。下面,我們用大家最為熟悉的互聯網行業作為例子,介紹 NVIDIA 如何與客戶一起,打造行業的加速計算解決方案。
這一頁對我們理解加速計算的價值非常重要,因為,加速計算的特點,決定了我們的工作方式。首先,加速計算對于應用來說,可以帶來數量級的性能提升,加速與沒加速的應用,性能可能相差幾十倍甚至幾百倍。
第二,底層的庫,例如矩陣計算、快速傅立葉變換、排序、向量操作等,它有一定的普適性,但是上層的應用通常有特異性,并非所有的優化策略都可以自然而然地帶來上層應用的優化。這里沒有一個一勞永逸的方法。我們常常聽到一些加速計算初學者說自己使用了這樣或者那樣的優化方法,為什么性能并不明顯?因為,我們的優化應該是應用導向,Profiling 導向。
第三,根據 Amdahl’s law,一個計算任務里面只有盡可能多的環節被加速才能帶來性能的大幅提升。舉個極端例子,如果一個計算任務,只有一半的部分被加速了,即使加速速度達到 1000x,整個計算任務的加速上限也只有 2x。因為上層應用的特異性,需要對整個工作流進行優化。而優化帶來的巨大收益,我們需要更多地進行軟硬協同的設計。所以,AI/HPC 的核心是加速計算,而加速計算的核心是優化,優化,端到端的優化!這需要,業務、算法、工程人員和優化工程師的密切配合。這也是我今天最重要的一頁 PPT。

下面,我們以推薦系統,這個互聯網最重要的應用為例,介紹 NVIDIA 如何與客戶一起,打造行業的加速計算解決方案。
目前 NVIDIA 在推薦系統方面已經擁有了全鏈路的解決方案和產品。但是幾年前,我們最早和百度合作的時候還不是這個樣子。
大家可以看到,最著名的 wide & deep 模型是 Google 團隊在 2016 年推出的,NVIDIA 和行業客戶的深入合作則從 2018 年開始。在一開始,我們就針對 NVIDIA 的 DGX 高性能服務器來重新設計了推薦系統的訓練方法和數據分布方式,并且后續的軟件、硬件演化都是在此基礎上不斷去解決新遇到的技術瓶頸。
我們在一開始就是希望去解決 TB 級別以上的推薦系統的模型。在這個過程中的一些重要節點包括:NVIDIA Merlin 的推出、DLRM 進入 MLPerf、Merlin-HugeCTR 將 DLRM 的訓練時間推進到 1 分鐘以內、Big-ANN-Benchmark 將技術點從排序部分拓展到召回部分等等。另外,今年 3 月份推出的 NVIDIA Grace Hopper SuperChip,更近一步推進了推薦系統的進化。這是一個軟硬協同設計、軟件適配硬件,應用和軟件反過來推進硬件架構革新的典型例子。
我們再來看一下推薦系統技術架構路線及其架構的演化。大家注意,軟件架構與硬件架構的演進是和應用本身的發展息息相關,兩者是相輔相成的。軟硬件架構的演進為應用和算法的演進提供了可能性,而應用和算法的演進也對軟硬件架構提出了新的要求。因此,我們稱之為 co-design。
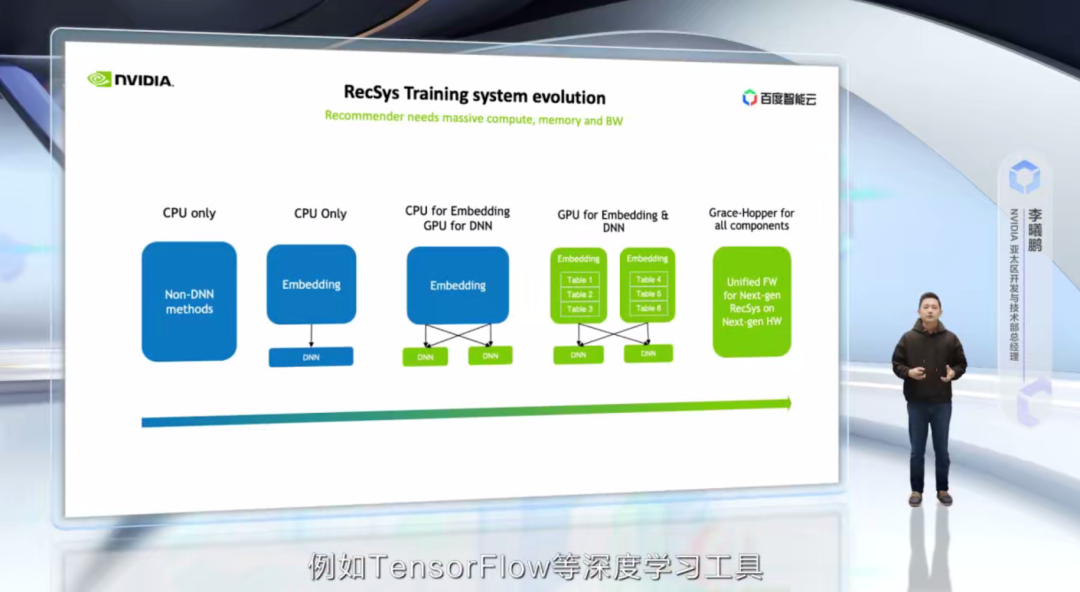
我們回到這頁 PPT,從最左邊看,是在沒有深度學習時期的推薦系統,例如傳統的矩陣分解,協同過濾等。這個階段對于算力的要求其實并不高,因此通常直接采用 CPU 的方案。
而到了一些淺層 DNN 的引入,計算量有了適當增加,embedding 大小也持續增加,大家出于慣性,還是喜歡直接使用 CPU。但是很自然,這樣的性能會受到節點間通信帶寬的限制,也就是再增加服務器的數目,對于提高計算速度沒有幫助。這個時候大家就想,我是不是應該做加速計算?
而企業用戶很自然第一步,把 DNN 部分移到 GPU 上,這是因為,一,這部分算力最大;另外,二,例如 TensorFlow 等深度學習工具,針對這一部分已經提供了很好的支持。更進一步,隨著 DNN 部分的加速,大家會發現瓶頸開始往 embedding 和 CPU-GPU 之間的通信轉移,也就是 CPU 的內存帶寬和 PCIe 的帶寬成為了新的瓶頸。
這個時候,下一代的技術演變就出現了,也就是把 embedding table 也進行 GPU 加速,這里解決了兩個問題,一個是內存帶寬,GPU 的內存帶寬高達 2T~3TB/s,遠遠高于系統的內存帶寬。另外,把 embedding table 移到 GPU 上,將 CPU-GPU 之間通過 PCIe 的通信變為 GPU-GPU 之間 NVLink 的通信,這部分通信速度也得到了成倍的提高。這就有了 NVIDIA 的全 GPU 解決方案。
更進一步,因為 embedding 數據天然存在冷熱分布,因此可以利用系統內存進一步提升模型大小,同時保持訓練速度,這個時候,NVIDIA 的 Grace Hopper、CPU 和 GPU 之間的高速 C2C 互聯就起到了幫助。
我們觀察到,幾乎所有的重點客戶都已經遷移到 CPU+GPU 的混合部署,而頭部客戶都有重點業務遷移到純 GPU 方案上,而業界領先的幾家公司都有在調研和開發 Grace Hopper 的統一架構。這是一個清晰的發展趨勢,各個公司有快有慢,但是加速計算的潮流是無法阻擋的。
對 NVIDIA 而言,推薦系統是一個完全誕生于中國、推廣到全世界的全新計算任務。在這個過程中,NVIDIA 的經驗是,立足于客戶真正有價值的難題,和客戶一起攻堅,實現端到端的性能優化!
以推薦系統為例,NVIDIA 的技術增長飛輪是從解決模型推理線上時延的問題,通過優化,實現了幾十倍的性能提升,從而給廣告業務帶來顯著的收入提升,進一步推動了更多的模型研發,更復雜的模型開始向 GPU 遷移,最后,引導整個工作流向 GPU 的遷移。
通過一個個關鍵難題的解決,客戶的更多計算任務在 GPU 上實現了性能加速,同時 NVIDIA 也沉淀出了 Merlin 這樣的產品來降低推薦系統的進入門檻,擴大了用戶群體,帶動新一輪的需求產生。這便是我們業務增長的邏輯!
NVIDIA 非常關注客戶計算任務中最關鍵的問題,和客戶一起工作,一起為了端到端的極致優化。可以說,加速計算的本質就是實現性能極致優化。而能實現這一點,除了 NVIDIA 帶來全棧計算能力之外,更重要的是我們有一批優秀的優化工程師,這是我們的核心生產力。
加速計算助力智能云深入產業
我們剛才看了一個互聯網的典型應用,推薦系統。下面,我們來討論下,加速計算如何可以助力云深入到行業、產業。
以自動駕駛行業為例,看看 NVIDIA 可以做些什么,讓技術飛輪轉動起來。自動駕駛是一個巨大的行業,麥肯錫的報告稱其產業規模可達 8,660 億美金。而行業的玩家也非常需要技術賦能,特別是基于 AI 的技術賦能。大家想到自動駕駛行業,首先想到的還是車上的設備,比如多少個雷達,多少個攝像頭,用的什么芯片。其實這個行業遠遠不止這樣。
我們換個角度,從業務的端到端來看,從自動駕駛汽車的設計、工程、仿真、制造、到銷售、服務,都存在著大量的計算任務需要去發掘和構建。這里面的計算任務包括AI的計算任務、HPC 的計算任務、數據科學的計算任務,還有數字孿生所帶來的各種機會。
這一切,誰最懂?我們的客戶應該最懂自己的需求。當然,也有很多客戶,還沒有能將自己的需求和加速計算連接起來。而這個行業的解決方案,還有很多空白和等待我們去發掘的地方。這就需要 NVIDIA、百度智能云,一起深入到客戶一線,和客戶一起分析他們的計算任務,一起共創,找到真正關鍵的、有價值的計算任務,利用云設施、云服務,構建基于加速計算的解決方案,并通過優化好這些計算任務,實現業務價值,從而推動更多的需求。
再舉一個例子,比如未來自動駕駛汽車的設計,也是一個充滿想象力的領域。這里面需要大量的計算機輔助工程(CAE)。比如,基于流體力學的外型設計、基于材料力學和結構力學的整車強度分析、基于熱物理的電池熱管理模擬、雷達天線方位和覆蓋范圍模擬等。這些都是典型的 HPC 應用,更快的模擬速度、更低的模擬成本,可以加大設計的選擇空間和加快效果的驗證。
目前,GPU 已經支持了主流的 120 多個 CAE 應用,單就計算流體力學(CFD)部分,已經可以帶來 7x 的成本節省和 4x 的電力消耗下降。并且,CFD 也是 AI for Science 快速發展的領域,NVIDIA 的 Modulus,百度的 Paddle AI+Science 科學開發套件,都可以進一步加速 CFD 這一領域。
未來,汽車外型的氣動設計可以變成一個自動化的過程,會不會有更多優秀的氣動外形的車問世?這將是一個讓人充滿遐想的領域。注意,這還只是整個產業鏈中,設計環節中 CAE 的一個例子而已。因此,在我看來,未來利用云設施、云服務,構建基于加速計算的解決方案,大有可為!
最后,我想重新展示這張技術飛輪,和 NVIDIA 創始人兼首席執行官黃仁勛今年 10 月份對于加速計算的判斷,作為今天分享的結束頁。
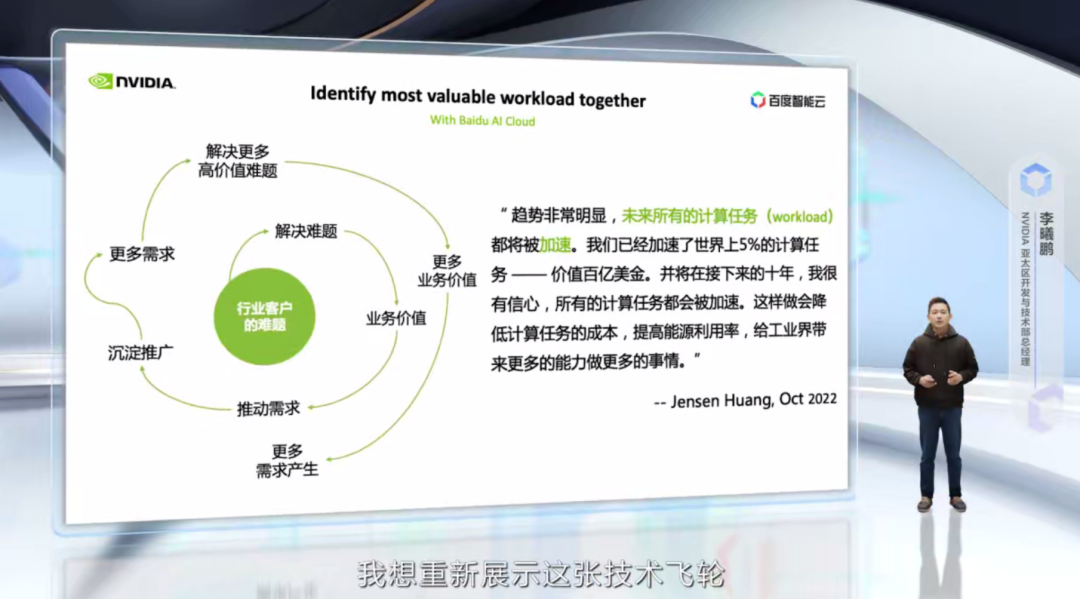
這個世界需要加速計算,需要云,需要 NVIDIA 和百度智能云,一起深入客戶一線,一起發現、優化,加速最重要的計算任務,需要業務、工程、優化工程師的緊密合作!
原文標題:百度智算峰會精彩回顧:加速計算助力智能云深入產業
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3862瀏覽量
92255
原文標題:百度智算峰會精彩回顧:加速計算助力智能云深入產業
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
百度智能云發布昆侖芯三代萬卡集群及DeepSeek-R1/V3上線
百度智能云四款大模型應用接入DeepSeek
英特爾攜手百度智能云加速AI落地
esp32在Arduino IDE中可以實現調用百度智能云接口嗎?
百度沈抖沈抖正式發布新一代智能計算操作系統—萬源
百度沈抖:傳統云計算不再是主角,智能計算呼喚新一代“操作系統”


百度智能云正式發布了《百度智能云水業大模型白皮書》






 工商網監
工商網監

評論