") CLIP-Chinese:中文多模態(tài)對比學(xué)習(xí)預(yù)訓(xùn)練模型
CLIP-Chinese:中文多模態(tài)對比學(xué)習(xí)預(yù)訓(xùn)練模型
筆者最近嘗試在業(yè)務(wù)中引入多模態(tài),基于CLIP論文的思想,實現(xiàn)了基于Vit-Bert的CLIP模型,下面將其稱為BertCLIP模型。筆者用140萬的中文圖文數(shù)據(jù),基于LiT-tuning的方式,訓(xùn)了一版BertCLIP模型。BertCLIP模型在中文圖文相似度、文本相似度、圖片相似度等任務(wù)上都有著不錯的表現(xiàn)。
本文將對該工作進行詳細的介紹并且分享筆者使用的中文訓(xùn)練語料、BertCLIP預(yù)訓(xùn)練權(quán)重、模型代碼和訓(xùn)練pipeline等。
首先展示一下BertCLIP預(yù)訓(xùn)練模型在圖文相似度上的效果。

項目地址:
https://github.com/yangjianxin1/CLIP-Chinese
預(yù)訓(xùn)練權(quán)重(使用方法,詳見下文):
| 預(yù)訓(xùn)練模型 | 預(yù)訓(xùn)練權(quán)重名稱 | 權(quán)重地址 |
| BertCLIP整體權(quán)重 |
YeungNLP/clip-vit-bert-chinese-1M |
https://huggingface.co/YeungNLP/clip-vit-bert-chinese-1M |
| 單獨提取出來的Bert權(quán)重 |
YeungNLP/bert-from-clip-chinese-1M |
https://huggingface.co/YeungNLP/bert-from-clip-chinese-1M |
論文標題:
Learning Transferable Visual Models From Natural Language Supervision
01
模型簡介
CLIP是由OpenAI提出的一種多模態(tài)對比學(xué)習(xí)模型,OpenAI使用了4億對圖文數(shù)據(jù),基于對比學(xué)習(xí)的方法對CLIP模型進行訓(xùn)練。
CLIP模型主要由文本編碼器和圖片編碼器兩部分組成,訓(xùn)練過程如下圖所示。對于batch size為N的圖文對數(shù)據(jù),將N個圖片與N個文本分別使用圖片編碼器和文本編碼器進行編碼,并且映射到同一個向量空間。然后分別計算兩兩圖文對編碼的點乘相似度,這樣就能得到一個N*N的相似度矩陣。
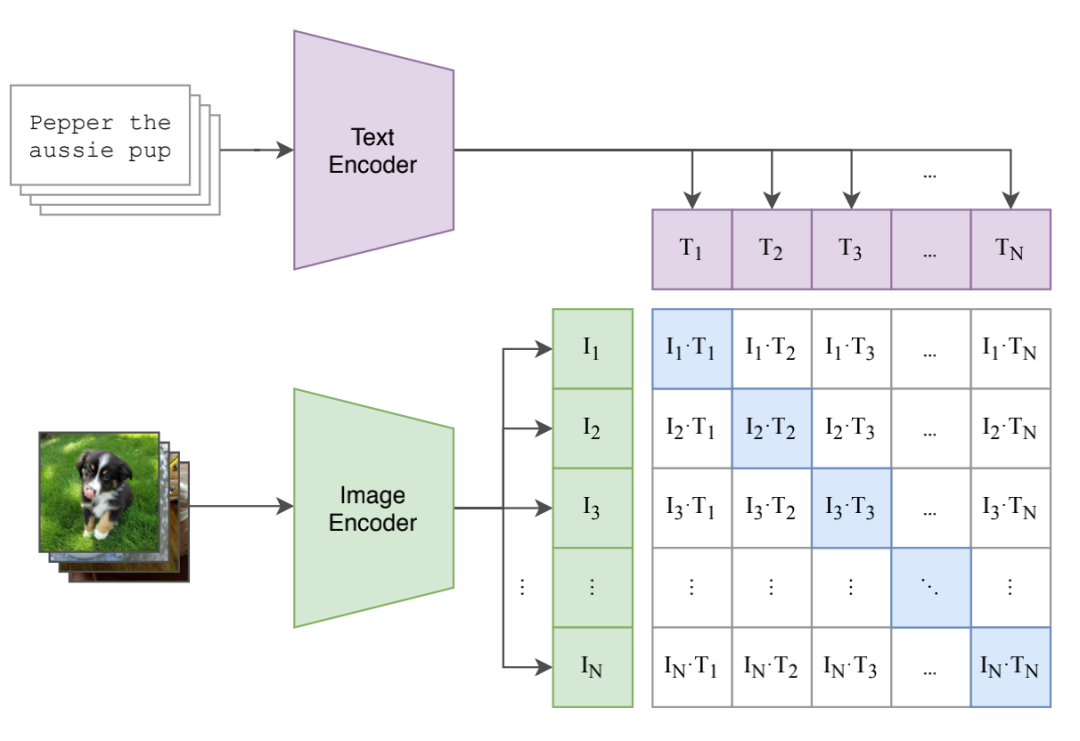
然后使用我們熟悉的對比損失InfoNCE Loss來計算該batch的訓(xùn)練損失,更新模型權(quán)重。對InfoNCE Loss不熟悉的小伙伴,可以回顧筆者往期的文章:SimCSE:簡單有效的句向量對比學(xué)習(xí)方法。
舉個例子,對于圖片I1,分別計算I1與文本T1~TN的相似度,T1是I1的正樣本,而T2~TN均視為I1的負樣本,我們希望I1與T1的相似度盡可能大,而I1與其他文本的相似度盡可能小。
在計算T1的InfoNCE Loss時,首先將T1與所有文本的相似度進行softmax歸一化,得到相似度的分布,然后計算相似度分布與label的交叉熵損失,而T1的label為1。由此可以將這個loss的計算方式推廣到整個batch。
有小伙伴可能會覺得,對于圖片l1,文本T2~TN中可能存在它的正樣本,若將T2~TN均視為I1的負樣本,會對模型的訓(xùn)練帶來很大的影響。對于該問題,我們可以認為,當數(shù)據(jù)量足夠大,并且batch size足夠大的時候,上述誤差對模型的優(yōu)化方向的影響是有限的。在預(yù)訓(xùn)練時代,我們要相信大力是能夠出奇跡的,只要堆足夠多優(yōu)質(zhì)的數(shù)據(jù),很多問題都可以迎刃而解。
02
項目介紹
訓(xùn)練細節(jié)
BertCLIP主要由Vit和Bert組成,在預(yù)訓(xùn)練時,筆者分別使用不同的預(yù)訓(xùn)練權(quán)重來初始化Vit和Bert的權(quán)重。使用OpenAI開源的CLIP模型來初始化Vit權(quán)重,使用孟子中文預(yù)訓(xùn)練權(quán)重來初始化Bert權(quán)重。
我們基于LiT-tuning的方法來訓(xùn)練BertCLIP模型,也就是將Vit部分的模型參數(shù)進行凍結(jié),只訓(xùn)練BertCLIP的其他部分的參數(shù)。LiT-tuning是多模態(tài)模型訓(xùn)練的一種范式,它旨在讓文本編碼空間向圖像編碼空間靠近,并且可以加快模型的收斂速度。
筆者使用了140萬條中文圖文數(shù)據(jù)對,batchsize為768,warmup step為1000步,學(xué)習(xí)率為5e-5,使用cosine衰減策略,混合精度訓(xùn)練了50個epoch,總共73100步,訓(xùn)練loss最終降為0.23左右。模型的訓(xùn)練loss變化如下圖所示。
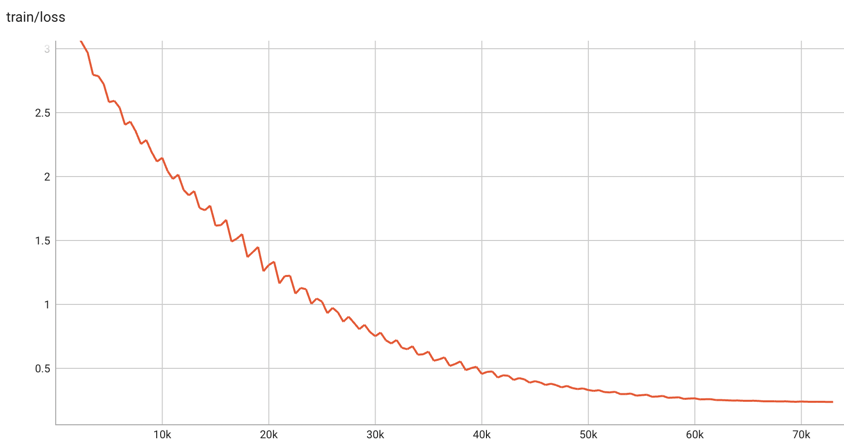
由于訓(xùn)練資源的限制,以及訓(xùn)練數(shù)據(jù)的獲取需要耗費較多時間,目前筆者僅使用了140萬的訓(xùn)練數(shù)據(jù)。對于預(yù)訓(xùn)練而言,140萬的訓(xùn)練數(shù)據(jù)量略微少了些,筆者訓(xùn)練50輪,模型也許會過分擬合訓(xùn)練數(shù)據(jù)。如若條件允許,讀者可以在共享的模型權(quán)重的基礎(chǔ)上,使用更多域內(nèi)數(shù)據(jù)進行二次預(yù)訓(xùn)練。
筆者曾使用實際業(yè)務(wù)中1700萬的圖文數(shù)據(jù)訓(xùn)練BertCLIP模型,訓(xùn)練10輪,大概22萬步,訓(xùn)練損失大約降為0.7。在域內(nèi)的圖文匹配、同義詞挖掘等任務(wù)中有不錯的效果。
使用方法
BertCLIP模型的使用方法非常簡單,首先將項目clone到本地機器上,并且安裝相關(guān)依賴包。
git clone https://github.com/yangjianxin1/CLIP-Chinese.git
pipinstall-rrequirements.txt
使用如下代碼,即可加載預(yù)訓(xùn)練權(quán)重和processor,對圖片和文本進行預(yù)處理,并且得到模型的輸出。
from transformers import CLIPProcessor
from component.model import BertCLIPModel
from PIL import Image
import requests
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
# 加載預(yù)訓(xùn)練模型權(quán)重
model = BertCLIPModel.from_pretrained(model_name_or_path)
# 初始化processor
CLIPProcessor.tokenizer_class='BertTokenizerFast'
processor = CLIPProcessor.from_pretrained(model_name_or_path)
# 預(yù)處理輸入
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["一只小狗在搖尾巴", "一只小豬在吃飯"], images=image, return_tensors="pt", padding=True)
inputs.pop('token_type_ids') # 輸入中不包含token_type_ids
outputs = model(**inputs)
# 對于每張圖片,計算其與所有文本的相似度
logits_per_image = outputs.logits_per_image # image-text的相似度得分
probs = logits_per_image.softmax(dim=1) # 對分數(shù)進行歸一化
# 對于每個文本,計算其與所有圖片的相似度
logits_per_text = outputs.logits_per_text # text-image的相似度得分
probs = logits_per_text.softmax(dim=1) # 對分數(shù)進行歸一化
# 獲得文本編碼
text_embeds = outputs.text_embeds
# 獲得圖像編碼
image_embeds = outputs.image_embeds
單獨加載圖像編碼器,進行下游任務(wù)。
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPVisionModel
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
model = CLIPVisionModel.from_pretrained(model_name_or_path)
CLIPProcessor.tokenizer_class = 'BertTokenizerFast'
processor = CLIPProcessor.from_pretrained(model_name_or_path)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
單獨加載文本編碼器,進行下游任務(wù)。
from component.model import BertCLIPTextModel
from transformers import BertTokenizerFast
model_name_or_path = 'YeungNLP/clip-vit-bert-chinese-1M'
model = BertCLIPTextModel.from_pretrained(model_name_or_path)
tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path)
inputs = tokenizer(["一只小狗在搖尾巴", "一只小豬在吃飯"], padding=True, return_tensors="pt")
inputs.pop('token_type_ids') # 輸入中不包含token_type_ids
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
筆者也將BertCLIP中Bert的預(yù)訓(xùn)練權(quán)重單獨拎出來,可以使用BertModel直接加載,進行下游任務(wù)。
from transformers import BertTokenizer, BertModel
model_name_or_path = 'YeungNLP/bert-from-clip-chinese-1M'
tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
model = BertModel.from_pretrained(model_name_or_path)
在項目中,筆者上傳了多線程下載訓(xùn)練圖片、訓(xùn)練pipeline,以及相似度計算的腳本,更多細節(jié)可參考項目代碼。
03
模型效果
圖文相似度
在計算圖文相似的時候,首先計算兩兩圖文向量之間的點乘相似度。對于每張圖,將其與所有文本的相似度進行softmax歸一化,得到最終的分數(shù)。


文本相似度
在計算文本相似度的時候,首先計算兩兩文本之間的點乘相似度。對于每個文本,將其與自身的相似度置為-10000(否則對于每個文本,其與自身的相似度永遠為最大),然后將其與所有文本的相似度進行softmax歸一化,得到最終的分數(shù)。
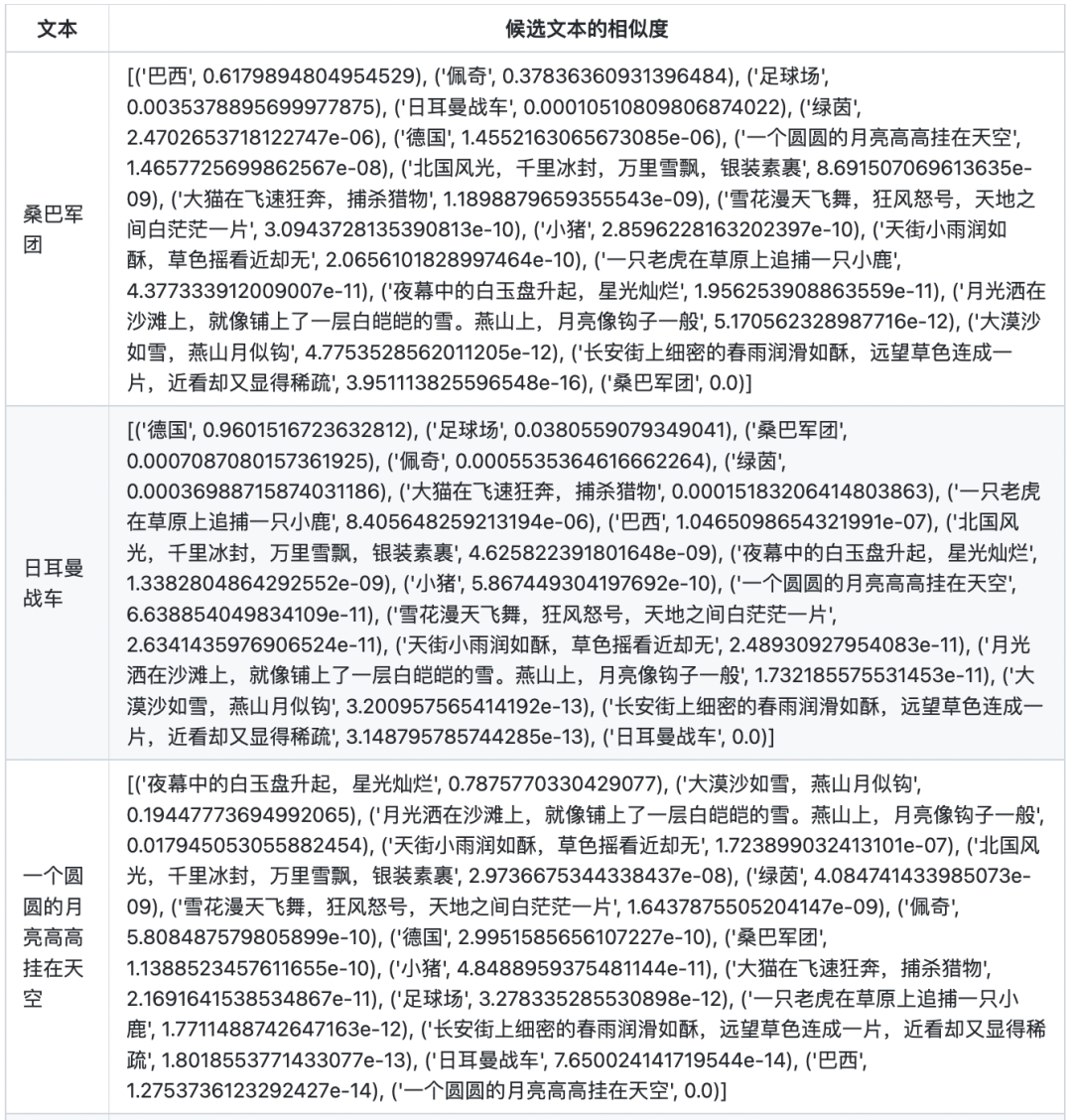
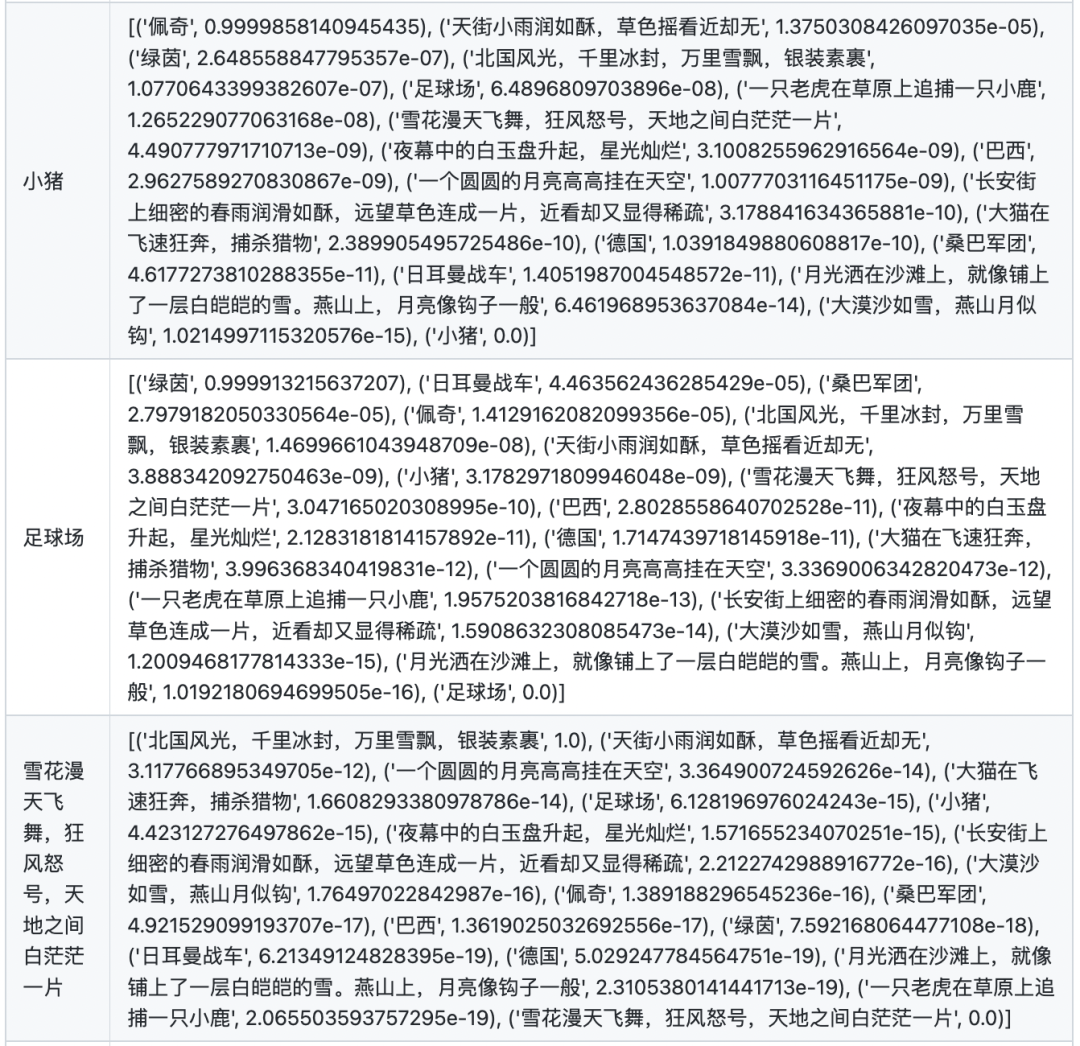
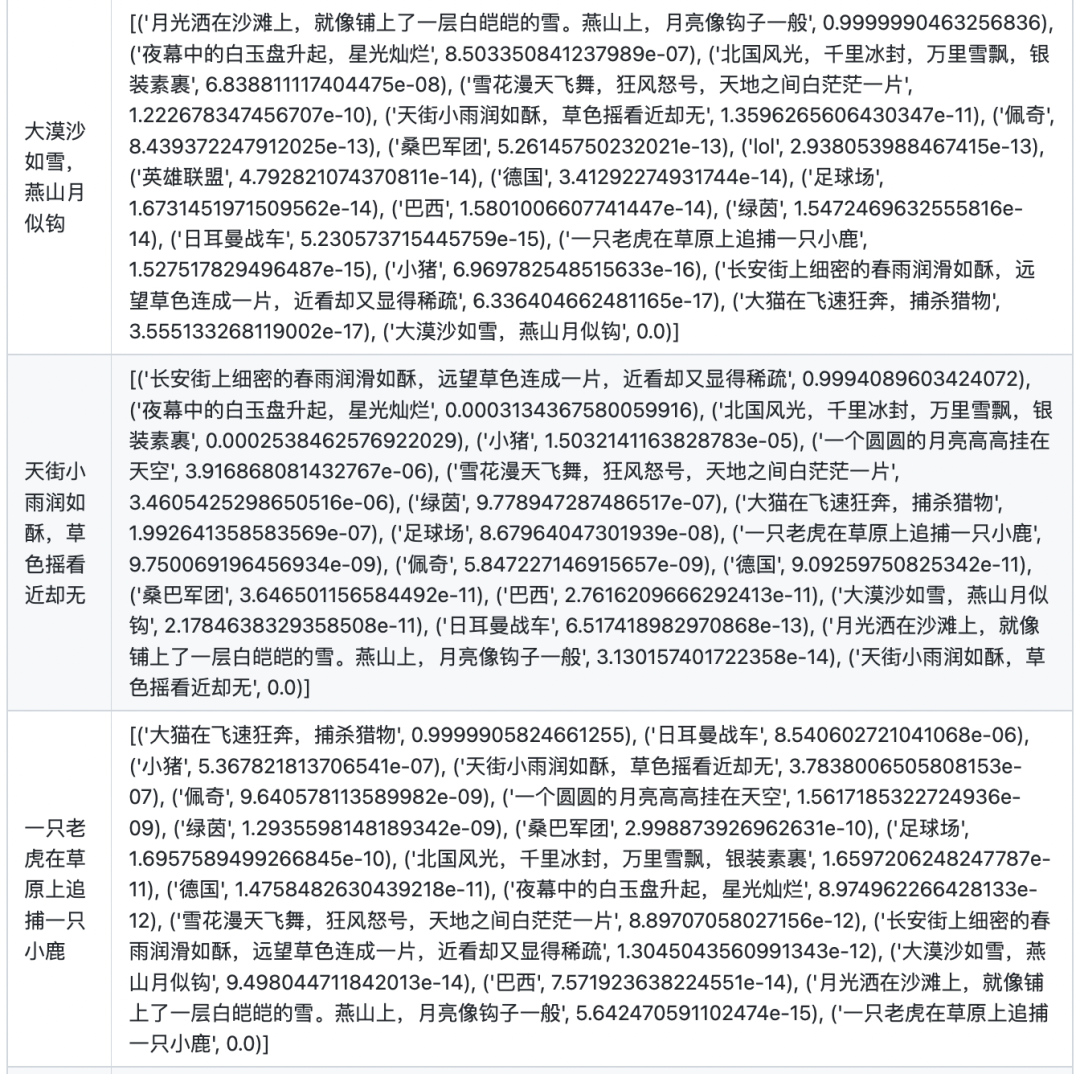

圖片相似度
圖片相似度的計算方式與文本相似度的方式一致。為方便展示,僅選出top1的圖片及其相似度分數(shù)。
注:由于在訓(xùn)練BertCLIP時,將圖像編碼器的權(quán)重凍結(jié),所以該部分的能力,主要歸功于OpenAI的clip預(yù)訓(xùn)練權(quán)重。如想要優(yōu)化模型在域內(nèi)數(shù)據(jù)的圖片相似度計算能力,圖像編碼器需要一起參與訓(xùn)練。


04
結(jié)語
在本文中,筆者基于CLIP的思想,設(shè)計了Vit-Bert結(jié)構(gòu)的BertCLIP模型,并且使用140萬中文圖文數(shù)據(jù)對,對模型進行預(yù)訓(xùn)練。在圖文相似度、文本相似度、圖片相似度任務(wù)上做了嘗試,取得了不錯的效果。
該預(yù)訓(xùn)練模型,能夠在中文圖文檢索、文本相似度計算、同義詞挖掘、相似圖召回等任務(wù)上發(fā)揮作用。并且在下游的一些多模態(tài)任務(wù)中,可以憑借該模型同時引入圖片和文本信息,擴充模型的信息域。由于Bert需要將文本空間向圖片空間對齊,所以Bert必然能夠?qū)W到了豐富的語義信息,這能夠?qū)ο掠蔚腘LP任務(wù)帶來增益。讀者也可以基于筆者分享的Bert預(yù)訓(xùn)練權(quán)重,進行下游NLP任務(wù)的finetune,相信會有所幫助。
不足之處在于,對于預(yù)訓(xùn)練而言,140萬的數(shù)據(jù)稍顯不足,讀者可以使用自身域內(nèi)數(shù)據(jù)進行二次預(yù)訓(xùn)練。
審核編輯 :李倩
-
編碼器
+關(guān)注
關(guān)注
45文章
3655瀏覽量
134872 -
模型
+關(guān)注
關(guān)注
1文章
3278瀏覽量
48970 -
OpenAI
+關(guān)注
關(guān)注
9文章
1103瀏覽量
6597
原文標題:CLIP-Chinese:中文多模態(tài)對比學(xué)習(xí)預(yù)訓(xùn)練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
商湯日日新多模態(tài)大模型權(quán)威評測第一
KerasHub統(tǒng)一、全面的預(yù)訓(xùn)練模型庫
一文理解多模態(tài)大語言模型——下

一文理解多模態(tài)大語言模型——上

利用OpenVINO部署Qwen2多模態(tài)模型
直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)

預(yù)訓(xùn)練和遷移學(xué)習(xí)的區(qū)別和聯(lián)系
大語言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練模型的基本原理和應(yīng)用
深度學(xué)習(xí)模型訓(xùn)練過程詳解
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的預(yù)訓(xùn)練
螞蟻推出20億參數(shù)多模態(tài)遙感模型SkySense
機器人基于開源的多模態(tài)語言視覺大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論