

作為智能對話系統(tǒng),ChatGPT最近兩天爆火,都火出技術(shù)圈了,網(wǎng)上到處都在轉(zhuǎn)ChatGPT相關(guān)的內(nèi)容和測試?yán)樱Ч_實很震撼。我記得上一次能引起如此轟動的AI技術(shù),NLP領(lǐng)域是GPT 3發(fā)布,那都是兩年半前的事了,當(dāng)時人工智能如日中天如火如荼的紅火日子,今天看來恍如隔世;多模態(tài)領(lǐng)域則是以DaLL E2、Stable Diffusion為代表的Diffusion Model,這是最近大半年火起來的AIGC模型;而今天,AI的星火傳遞到了ChatGPT手上,它毫無疑問也屬于AIGC范疇。所以說,在AI泡沫破裂后處于低谷期的今天,AIGC確實是給AI續(xù)命的良藥,當(dāng)然我們更期待估計很快會發(fā)布的GPT 4,愿OpenAI能繼續(xù)撐起局面,給行業(yè)帶來一絲暖意。
說回ChatGPT,例子就不舉了,在網(wǎng)上漫山遍野都是,我們主要從技術(shù)角度來聊聊。那么,ChatGPT到底是采用了怎樣的技術(shù),才能做到如此超凡脫俗的效果?既然ChatGPT功能如此強大,那么它可以取代Google、百度等現(xiàn)有搜索引擎嗎?如果能,那是為什么,如果不能,又是為什么?
本文試圖從我個人理解的角度,來嘗試回答上述問題,很多個人觀點,偏頗難免,還請謹(jǐn)慎參考。我們首先來看看ChatGPT到底做了什么才獲得如此好的效果。
ChatGPT的技術(shù)原理
整體技術(shù)路線上,ChatGPT在效果強大的GPT 3.5大規(guī)模語言模型(LLM,Large Language Model)基礎(chǔ)上,引入“人工標(biāo)注數(shù)據(jù)+強化學(xué)習(xí)”(RLHF,Reinforcement Learning from Human Feedback ,這里的人工反饋其實就是人工標(biāo)注數(shù)據(jù))來不斷Fine-tune預(yù)訓(xùn)練語言模型,主要目的是讓LLM模型學(xué)會理解人類的命令指令的含義(比如給我寫一段小作文生成類問題、知識回答類問題、頭腦風(fēng)暴類問題等不同類型的命令),以及讓LLM學(xué)會判斷對于給定的prompt輸入指令(用戶的問題),什么樣的答案是優(yōu)質(zhì)的(富含信息、內(nèi)容豐富、對用戶有幫助、無害、不包含歧視信息等多種標(biāo)準(zhǔn))。
在“人工標(biāo)注數(shù)據(jù)+強化學(xué)習(xí)”框架下,具體而言,ChatGPT的訓(xùn)練過程分為以下三個階段:
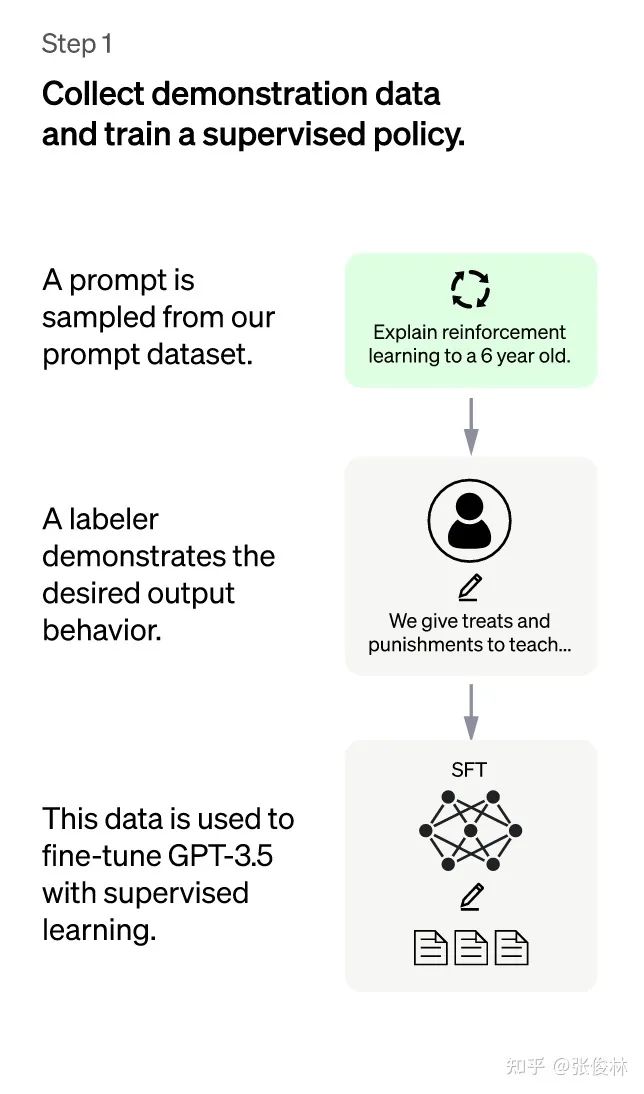
(ChatGPT:第一階段) 第一階段:冷啟動階段的監(jiān)督策略模型。靠GPT 3.5本身,盡管它很強,但是它很難理解人類不同類型指令中蘊含的不同意圖,也很難判斷生成內(nèi)容是否是高質(zhì)量的結(jié)果。為了讓GPT 3.5初步具備理解指令中蘊含的意圖,首先會從測試用戶提交的prompt(就是指令或問題)中隨機抽取一批,靠專業(yè)的標(biāo)注人員,給出指定prompt的高質(zhì)量答案,然后用這些人工標(biāo)注好的
(ChatGPT:第二階段)
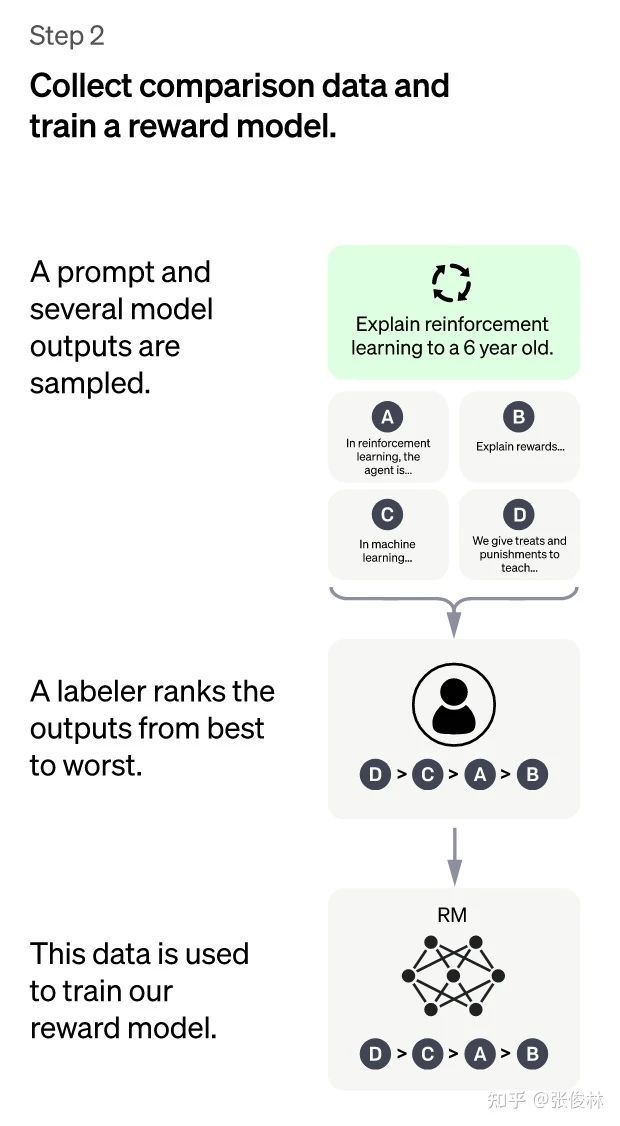
第二階段:訓(xùn)練回報模型(Reward Model,RM)。這個階段的主要目的是通過人工標(biāo)注訓(xùn)練數(shù)據(jù),來訓(xùn)練回報模型。具體而言,隨機抽樣一批用戶提交的prompt(大部分和第一階段的相同),使用第一階段Fine-tune好的冷啟動模型,對于每個prompt,由冷啟動模型生成K個不同的回答,于是模型產(chǎn)生出了
接下來,我們準(zhǔn)備利用這個排序結(jié)果數(shù)據(jù)來訓(xùn)練回報模型,采取的訓(xùn)練模式其實就是平常經(jīng)常用到的pair-wise learning to rank。對于K個排序結(jié)果,兩兩組合,形成(k2)個訓(xùn)練數(shù)據(jù)對,ChatGPT采取pair-wise loss來訓(xùn)練Reward Model。RM模型接受一個輸入
歸納下:在這個階段里,首先由冷啟動后的監(jiān)督策略模型為每個prompt產(chǎn)生K個結(jié)果,人工根據(jù)結(jié)果質(zhì)量由高到低排序,以此作為訓(xùn)練數(shù)據(jù),通過pair-wise learning to rank模式來訓(xùn)練回報模型。對于學(xué)好的RM模型來說,輸入
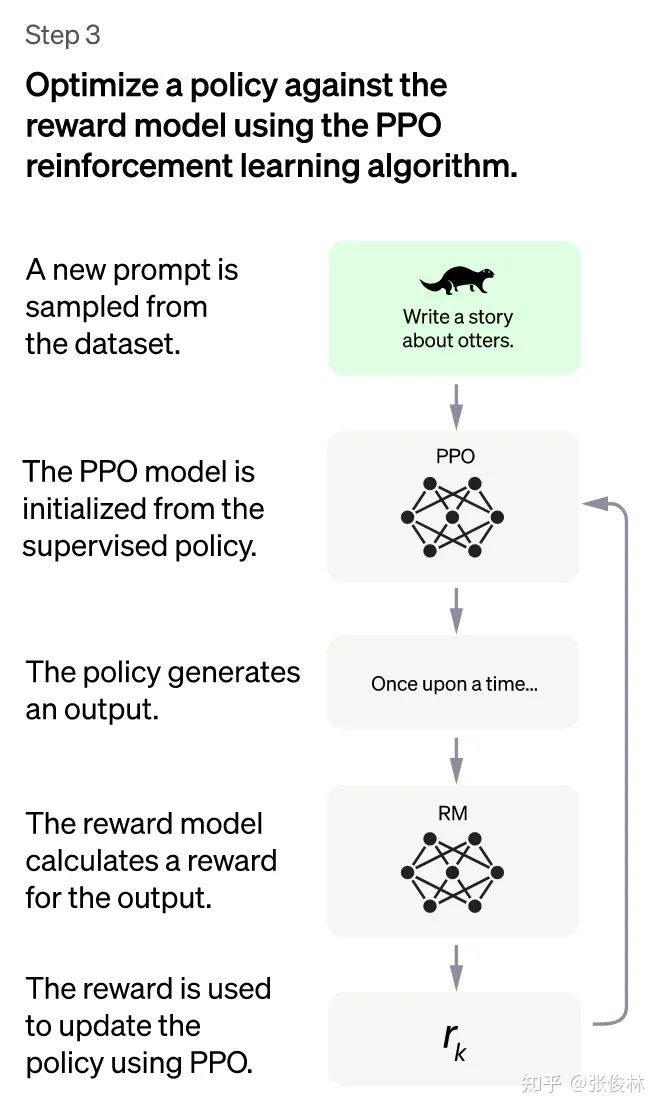
(ChatGPT:第三階段)
第三階段:采用強化學(xué)習(xí)來增強預(yù)訓(xùn)練模型的能力。本階段無需人工標(biāo)注數(shù)據(jù),而是利用上一階段學(xué)好的RM模型,靠RM打分結(jié)果來更新預(yù)訓(xùn)練模型參數(shù)。具體而言,首先,從用戶提交的prompt里隨機采樣一批新的命令(指的是和第一第二階段不同的新的prompt,這個其實是很重要的,對于提升LLM模型理解instruct指令的泛化能力很有幫助),且由冷啟動模型來初始化PPO模型的參數(shù)。然后,對于隨機抽取的prompt,使用PPO模型生成回答answer, 并用上一階段訓(xùn)練好的RM模型給出answer質(zhì)量評估的回報分?jǐn)?shù)score,這個回報分?jǐn)?shù)就是RM賦予給整個回答(由單詞序列構(gòu)成)的整體reward。有了單詞序列的最終回報,就可以把每個單詞看作一個時間步,把reward由后往前依次傳遞,由此產(chǎn)生的策略梯度可以更新PPO模型參數(shù)。這是標(biāo)準(zhǔn)的強化學(xué)習(xí)過程,目的是訓(xùn)練LLM產(chǎn)生高reward的答案,也即是產(chǎn)生符合RM標(biāo)準(zhǔn)的高質(zhì)量回答。
如果我們不斷重復(fù)第二和第三階段,很明顯,每一輪迭代都使得LLM模型能力越來越強。因為第二階段通過人工標(biāo)注數(shù)據(jù)來增強RM模型的能力,而第三階段,經(jīng)過增強的RM模型對新prompt產(chǎn)生的回答打分會更準(zhǔn),并利用強化學(xué)習(xí)來鼓勵LLM模型學(xué)習(xí)新的高質(zhì)量內(nèi)容,這起到了類似利用偽標(biāo)簽擴充高質(zhì)量訓(xùn)練數(shù)據(jù)的作用,于是LLM模型進一步得到增強。顯然,第二階段和第三階段有相互促進的作用,這是為何不斷迭代會有持續(xù)增強效果的原因。
盡管如此,我覺得第三階段采用強化學(xué)習(xí)策略,未必是ChatGPT模型效果特別好的主要原因。假設(shè)第三階段不采用強化學(xué)習(xí),換成如下方法:類似第二階段的做法,對于一個新的prompt,冷啟動模型可以產(chǎn)生k個回答,由RM模型分別打分,我們選擇得分最高的回答,構(gòu)成新的訓(xùn)練數(shù)據(jù)
以上是ChatGPT的訓(xùn)練流程,主要參考自instructGPT的論文,ChatGPT是改進的instructGPT,改進點主要在收集標(biāo)注數(shù)據(jù)方法上有些區(qū)別,在其它方面,包括在模型結(jié)構(gòu)和訓(xùn)練流程等方面基本遵循instructGPT。可以預(yù)見的是,這種Reinforcement Learning from Human Feedback技術(shù)會快速蔓延到其它內(nèi)容生成方向,比如一個很容易想到的,類似“A machine translation model based on Reinforcement Learning from Human Feedback”這種,其它還有很多。但是,我個人認(rèn)為,在NLP的某個具體的內(nèi)容生成領(lǐng)域再采用這個技術(shù)意義應(yīng)該已經(jīng)不大了,因為ChatGPT本身能處理的任務(wù)類型非常多樣化,基本涵蓋了NLP生成的很多子領(lǐng)域,所以某個NLP子領(lǐng)域如果再單獨采用這個技術(shù)其實已經(jīng)不具備太大價值,因為它的可行性可以認(rèn)為已經(jīng)被ChatGPT驗證了。如果把這個技術(shù)應(yīng)用在比如圖片、音頻、視頻等其它模態(tài)的生成領(lǐng)域,可能是更值得探索的方向,也許不久后我們就會看到類似“A XXX diffusion model based on Reinforcement Learning from Human Feedback”,諸如此類,這類工作應(yīng)該還是很有意義的。
另外一個值得關(guān)注的采取類似技術(shù)的工作是DeepMind的sparrow,這個工作發(fā)表時間稍晚于instructGPT,如果你仔細(xì)分析的話,大的技術(shù)思路和框架與instructGPT的三階段基本類似,不過明顯sparrow在人工標(biāo)注方面的質(zhì)量和工作量是不如instructGPT的。反過來,我覺得sparrow里把回報模型分為兩個不同RM的思路,是優(yōu)于instructGPT的,至于原因在下面小節(jié)里會講。
ChatGPT能否取代Google、百度等傳統(tǒng)搜索引擎
既然看上去ChatGPT幾乎無所不能地回答各種類型的prompt,那么一個很自然的問題就是:ChatGPT或者未來即將面世的GPT4,能否取代Google、百度這些傳統(tǒng)搜索引擎呢?我個人覺得目前應(yīng)該還不行,但是如果從技術(shù)角度稍微改造一下,理論上是可以取代傳統(tǒng)搜索引擎的。

為什么說目前形態(tài)的ChatGPT還不能取代搜索引擎呢?主要有三點原因:首先,對于不少知識類型的問題,ChatGPT會給出看上去很有道理,但是事實上是錯誤答案的內(nèi)容(參考上圖的例子(from @Gordon Lee),ChatGPT的回答看著胸有成竹,像我這么沒文化的基本看了就信了它,回頭查了下這首詞里竟然沒這兩句),考慮到對于很多問題它又能回答得很好,這將會給用戶造成困擾:如果我對我提的問題確實不知道正確答案,那我是該相信ChatGPT的結(jié)果還是不該相信呢?此時你是無法作出判斷的。這個問題可能是比較要命的。其次,ChatGPT目前這種基于GPT大模型基礎(chǔ)上進一步增加標(biāo)注數(shù)據(jù)訓(xùn)練的模式,對于LLM模型吸納新知識是非常不友好的。新知識總是在不斷出現(xiàn),而出現(xiàn)一些新知識就去重新預(yù)訓(xùn)練GPT模型是不現(xiàn)實的,無論是訓(xùn)練時間成本還是金錢成本,都不可接受。如果對于新知識采取Fine-tune的模式,看上去可行且成本相對較低,但是很容易產(chǎn)生新數(shù)據(jù)的引入導(dǎo)致對原有知識的災(zāi)難遺忘問題,尤其是短周期的頻繁fine-tune,會使這個問題更為嚴(yán)重。所以如何近乎實時地將新知識融入LLM是個非常有挑戰(zhàn)性的問題。其三,ChatGPT或GPT4的訓(xùn)練成本以及在線推理成本太高,導(dǎo)致如果面向真實搜索引擎的以億記的用戶請求,假設(shè)繼續(xù)采取免費策略,OpenAI無法承受,但是如果采取收費策略,又會極大減少用戶基數(shù),是否收費是個兩難決策,當(dāng)然如果訓(xùn)練成本能夠大幅下降,則兩難自解。以上這三個原因,導(dǎo)致目前ChatGPT應(yīng)該還無法取代傳統(tǒng)搜索引擎。
那么這幾個問題,是否可以解決呢?其實,如果我們以ChatGPT的技術(shù)路線為主體框架,再吸納其它對話系統(tǒng)采用的一些現(xiàn)成的技術(shù)手段,來對ChatGPT進行改造,從技術(shù)角度來看,除了成本問題外的前兩個技術(shù)問題,目前看是可以得到很好地解決。我們只需要在ChatGPT的基礎(chǔ)上,引入sparrow系統(tǒng)以下能力:基于retrieval結(jié)果的生成結(jié)果證據(jù)展示,以及引入LaMDA系統(tǒng)的對于新知識采取retrieval模式,那么前面提到的新知識的及時引入,以及生成內(nèi)容可信性驗證,基本就不是什么大問題。
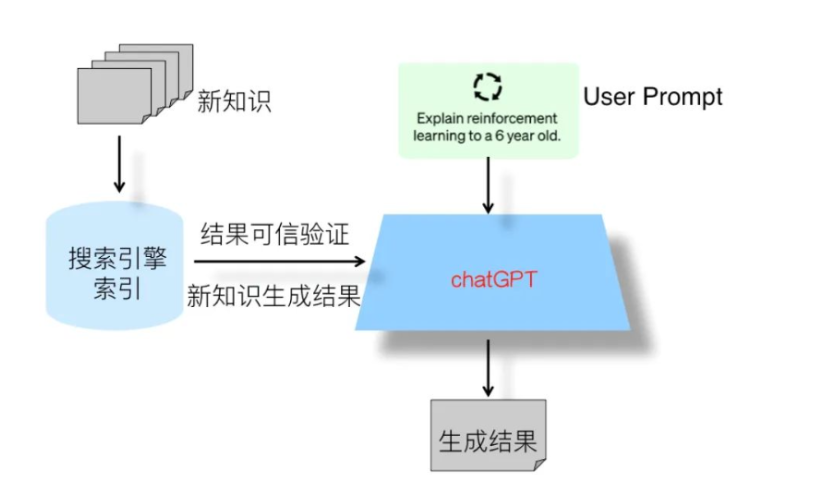
基于以上考慮,在上圖中展示出了我心目中下一代搜索引擎的整體結(jié)構(gòu):它其實是目前的傳統(tǒng)搜索引擎+ChatGPT的雙引擎結(jié)構(gòu),ChatGPT模型是主引擎,傳統(tǒng)搜索引擎是輔引擎。傳統(tǒng)搜索引擎的主要輔助功能有兩個:一個是對于ChatGPT產(chǎn)生的知識類問題的回答,進行結(jié)果可信性驗證與展示,就是說在ChatGPT給出答案的同時,從搜索引擎里找到相關(guān)內(nèi)容片段及url鏈接,同時把這些內(nèi)容展示給用戶,使得用戶可以從額外提供的內(nèi)容里驗證答案是否真實可信,這樣就可以解決ChatGPT產(chǎn)生的回答可信與否的問題,避免用戶對于產(chǎn)生結(jié)果無所適從的局面。當(dāng)然,只有知識類問題才有必要尋找可信信息進行驗證,很多其他自由生成類型的問題,比如讓ChatGPT寫一個滿足某個主題的小作文這種完全自由發(fā)揮的內(nèi)容,則無此必要。所以這里還有一個什么情況下會調(diào)用傳統(tǒng)搜索引擎的問題,具體技術(shù)細(xì)節(jié)完全可仿照sparrow的做法,里面有詳細(xì)的技術(shù)方案。傳統(tǒng)搜索引擎的第二個輔助功能是及時補充新知識。既然我們不可能隨時把新知識快速引入LLM,那么可以把它存到搜索引擎的索引里,ChatGPT如果發(fā)現(xiàn)具備時效性的問題,它自己又回答不了,則可以轉(zhuǎn)向搜索引擎抽取對應(yīng)的答案,或者根據(jù)返回相關(guān)片段再加上用戶輸入問題通過ChatGPT產(chǎn)生答案。關(guān)于這方面的具體技術(shù)手段,可以參考LaMDA,其中有關(guān)于新知識處理的具體方法。
除了上面的幾種技術(shù)手段,我覺得相對ChatGPT只有一個綜合的Reward Model,sparrow里把答案helpful相關(guān)的標(biāo)準(zhǔn)(比如是否富含信息量、是否合乎邏輯等)采用一個RM,其它類型toxic/harmful相關(guān)標(biāo)準(zhǔn)(比如是否有bias、是否有害信息等)另外單獨采用一個RM,各司其職,這種模式要更清晰合理一些。因為單一類型的標(biāo)準(zhǔn),更便于標(biāo)注人員進行判斷,而如果一個Reward Model融合多種判斷標(biāo)準(zhǔn),相互打架在所難免,判斷起來就很復(fù)雜效率也低,所以感覺可以引入到ChatGPT里來,得到進一步的模型改進。
通過吸取各種現(xiàn)有技術(shù)所長,我相信大致可以解決ChatGPT目前所面臨的問題,技術(shù)都是現(xiàn)成的,從產(chǎn)生內(nèi)容效果質(zhì)量上取代現(xiàn)有搜索引擎問題不大。當(dāng)然,至于模型訓(xùn)練成本和推理成本問題,可能短時期內(nèi)無法獲得快速大幅降低,這可能是決定LLM是否能夠取代現(xiàn)有搜索引擎的關(guān)鍵技術(shù)瓶頸。從形式上來看,未來的搜索引擎大概率是以用戶智能助手APP的形式存在的,但是,從短期可行性上來說,在走到最終形態(tài)之前,過渡階段大概率兩個引擎的作用是反過來的,就是傳統(tǒng)搜索引擎是主引擎,ChatGPT是輔引擎,形式上還是目前搜索引擎的形態(tài),只是部分搜索內(nèi)容Top 1的搜索結(jié)果是由ChatGPT產(chǎn)生的,大多數(shù)用戶請求,可能在用戶看到Top 1結(jié)果就能滿足需求,對于少數(shù)滿足不了的需求,用戶可以采用目前搜索引擎翻頁搜尋的模式。我猜搜索引擎未來大概率會以這種過渡階段以傳統(tǒng)搜索引擎為主,ChatGPT這種instruct-based生成模型為輔,慢慢切換到以ChatGPT生成內(nèi)容為主,而這個切換節(jié)點,很可能取決于大模型訓(xùn)練成本的大幅下降的時間,以此作為轉(zhuǎn)換節(jié)點。
審核編輯 :李倩
-
引擎
+關(guān)注
關(guān)注
1文章
363瀏覽量
22755 -
模型
+關(guān)注
關(guān)注
1文章
3440瀏覽量
49612 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11426 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1580瀏覽量
8428
原文標(biāo)題:ChatGPT會取代搜索引擎嗎
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦

OpenAI免費開放ChatGPT搜索功能
OpenAI推出ChatGPT搜索功能
Meta開發(fā)新搜索引擎,減少對谷歌和必應(yīng)的依賴
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
OpenAI推出SearchGPT原型,正式向Google搜索引擎發(fā)起挑戰(zhàn)
微軟計劃在搜索引擎Bing中引入AI摘要功能
AI搜索挑戰(zhàn)百度谷歌,重塑信息檢索的市場?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論