 如何通過poly實現C++編譯期多態
如何通過poly實現C++編譯期多態
引言
前面的文章中我們更多的聚焦在運行期反射,本篇我們將聚焦在一個與反射使用的機制有所類同,但更依賴編譯期特性的機制-》編譯期多態實現。
c++最近幾版的更新添加了大量的compiler time特性支持,社區輪子的熱情又進一步高漲。這幾年go與rust等語言也發展壯大,那么,我們能不能在c++中實現類似go interface和rust traits的機制呢?
答案是肯定的,開源社區早已經開始了自己的行動,dyno與folly::poly都已經有了自己的實現。兩者的實現思路基本一致,差別主要在于dyno使用了boost::hana和其他一些第三方庫來完成整體機制的實現。
而folly::poly出來的晚一些,主要使用c++的新特性來實現相關的功能,依賴比較少,所以本文將更多的以poly的實現來分析編譯期多態的整體實現。
一、從c++的運行時多態說起
(一)一個簡單的例子
struct Vehicle {
virtual void accelerate() = 0;
virtual ~Vechicle() {}
};
struct Car: public Vehicle {
void accelerate() override;
};
struct Truck: public Vehicle {
void accelerate() override;
};
(二)對應的運行時內存結構
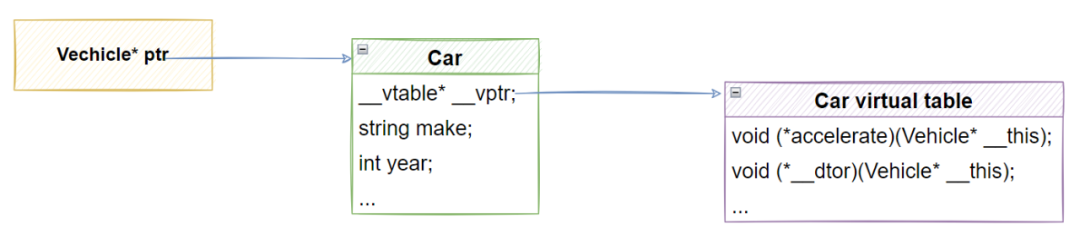
(三)運行時多態帶來的問題
性能問題
大量的文章都提到,因為virtual table的存在,對比純c的實現,c++運行時多態的使用會付出額外的性能開銷。
指針帶來的問題
運行時多態一般多配合指針一起使用,這也導致基本相關代碼都是配合堆內存來使用的,后續又引入了智能指針緩解堆內存分配導致的額外心智負擔,但智能指針的使用本身又帶來了其他問題。
侵入性問題
類繼承需要強制指定子類的基類,當我們引入第三方庫的時候,要么不可避免的需要對其進行修改,要么需要額外的包裝類,這些都會帶來復雜度的上升和性能的下降。還有一些其他的問題,這里就不再展開了,最近的cppconn多態本身相關的討論也是一個熱點,許多項目開始嘗試用自己的方法試圖解決運行時多態的問題,感興趣的可以自行去了解相關的內容。
本部分例子和內容主要來自Louis Dionne的Runtime Polymorphism: Back To The Basics。
二、dyno與poly的實現思路
(一)dyno與poly的目的-編譯期多態
dyno想達成的效果其實就是實現編譯期多態,如作者所展示的代碼片段:
interface Vechicle { void accelerate(); };
namespace lib{
struct Motorcycle { void accelerate(); };
}
struct Car { void accelerate(); };
struct Truck { void accelerate(); };
int main() {
std::vector vehicles;
vehicles.push_back(Car{...});
vehicles.push_back(Truck{...});
vehicles.push_back(lib::Motorcycle{...});
for(auto& vehicle: vehicles) {
vehicle.accelerate();
}
}
想法很美好, 但現實是殘酷的, 并沒有interface存在, 在可預知的一段時間里, 也不會有, 那么如果要自己實現相關的機制, 該如何來達成呢? 我們在下文中先來看一下整體的實現思路。
(二)編譯期多態的設計思路
參考前面的運行時多態模型:
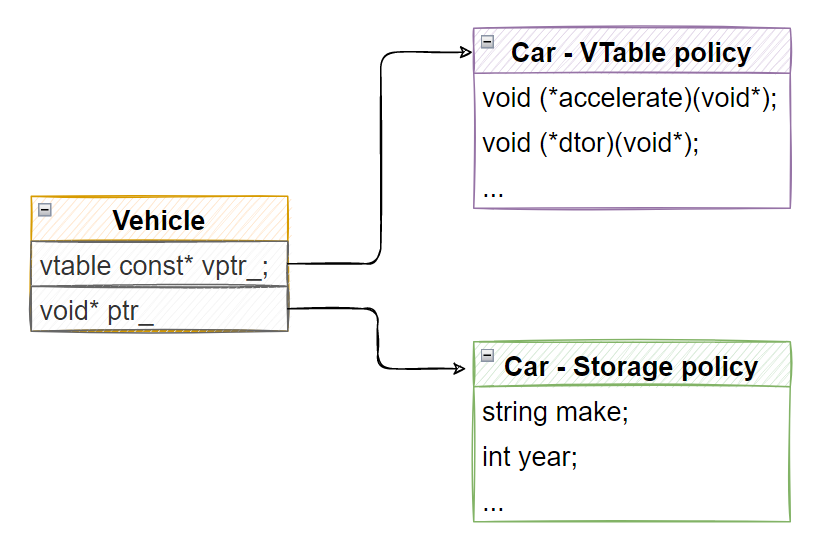
dyno的思路比較直接,嘗試使用兩個獨立的部分來解決編譯期多態的支持問題:
Storage policy-負責對象的存儲。
VTable policy-負責函數分發調用。
folly::Poly的實現思路大量參考了dyno,與dyno一致,也是同樣的結構。我們繼續以Vechicle舉例,假設真的存在Vechicle對象,那么它的組織肯定是如下圖所示的:
通過這種結構,我們就能正常的訪問到Car等具體對象的accelerate()方法了,原理上還是比較簡潔的,但是要做到完全的編譯期多態,并不是一個簡單的事情。接下來我們先來看一個poly的示例代碼,先從應用側了解一下它的使用。
三、poly的示例代碼
我們還是以Vechicle為例,給出一段poly的示例代碼:
struct IVehicle {
// Define the interface for vehicle
template <class Base> struct Interface : Base {
void accelerate() const {
folly::poly_call<0>(*this);
}
};
// Define how concrete types can fulfill that interface (in C++17):
template <class T> using Members = folly::PolyMembers<&T::accelerate>;
};
using vehicle = folly::Poly;
struct Car {
void accelerate() const {
std::cout << "Car accelerate!" << std::endl;
}
};
struct Trunk {
void accelerate() const {
std::cout << "Trunk accelerate!" << std::endl;
}
};
void accel_func(vehicle const& v) {
v.accelerate();
}
int main() {
accel_func(Car{}); // Car accelerate
accel_func(Trunk{}); // Trunk accelerate
return 0;
}
從上面的示例可以看到,poly的封裝使用還是比較簡潔的,主要是兩個輔助對象的定義:
IVehicle 類的定義
vehicle類的定義
(一)IVehicle類
struct IVehicle {
// Define the interface for vehicle
template <class Base> struct Interface : Base {
void accelerate() const {
folly::poly_call<0>(*this);
}
};
// Define how concrete types can fulfill that interface (in C++17):
template <class T> using Members = folly::PolyMembers<&T::accelerate>;
};
IVehicle類主要提供兩個功能:
通過內嵌類型Members來完成接口包含的所有成員的定義,如上例中的&T::accelerate。
通過內嵌類型Interface提供類型擦除后的poly《》對象的訪問接口。
兩者的部分信息其實有所重復,另外因為poly是基于c++17特性的,所以也沒有使用concept對Interface的類型提供約束,這個地方約束性和簡潔性上會有一點折扣。
(二) vehicle類
using vehicle = folly::Poly《IVehicle》;
這個類使用我們前面定義的IVehicle類來定義一個folly::Poly《IVechicle》容器對象,所有滿足IVehicle定義的類型都可以被它所容納,與std::any類似,只是std::any用于裝填任意類型,folly::Poly《》只能用來裝填符合相關Interface定義的對象,比如上面定義的vehicle,就能用來容納前面示例中定義的Car和Trunk等實現了void accelerate() const方法的類型。同樣,區別于std::any只是用作一個萬能容器,這里的vehicle本身也是支持函數調用的,比如例子中的:accelerate()。
(三)示例小結
通過上面的示例代碼,我們對poly的使用有了初步的了解,從上面的代碼中可以看出,編譯期多態的使用還是比較簡潔的,整體過程跟c++標準的繼承比較類似,有幾點差別比較大:
我們不需要侵入性的去指定子類的基類,我們通過非侵入性的方式來使用poly庫。
我們是通過構建的folly::Poly《》來完成對各種子類型的容納的,而不是直接使用基類來進行類型退化再統一存儲所有子類,這樣也就避免了繼承一般搭配堆內存分配使用的問題。
那么,整套機制是如何實現的呢? 我們在下文中將具體展開。
四、關于實現的猜想
前面的文章中我們介紹了運行時反射的相關機制,所以類似poly這種使用側的包裝,如果我們拋開性能,考慮用反射實現類似機制,還是比較容易的。
(一)VTable與meta::class
VTable的概念其實與前面的篇章里提到的meta::class功能基本一致:
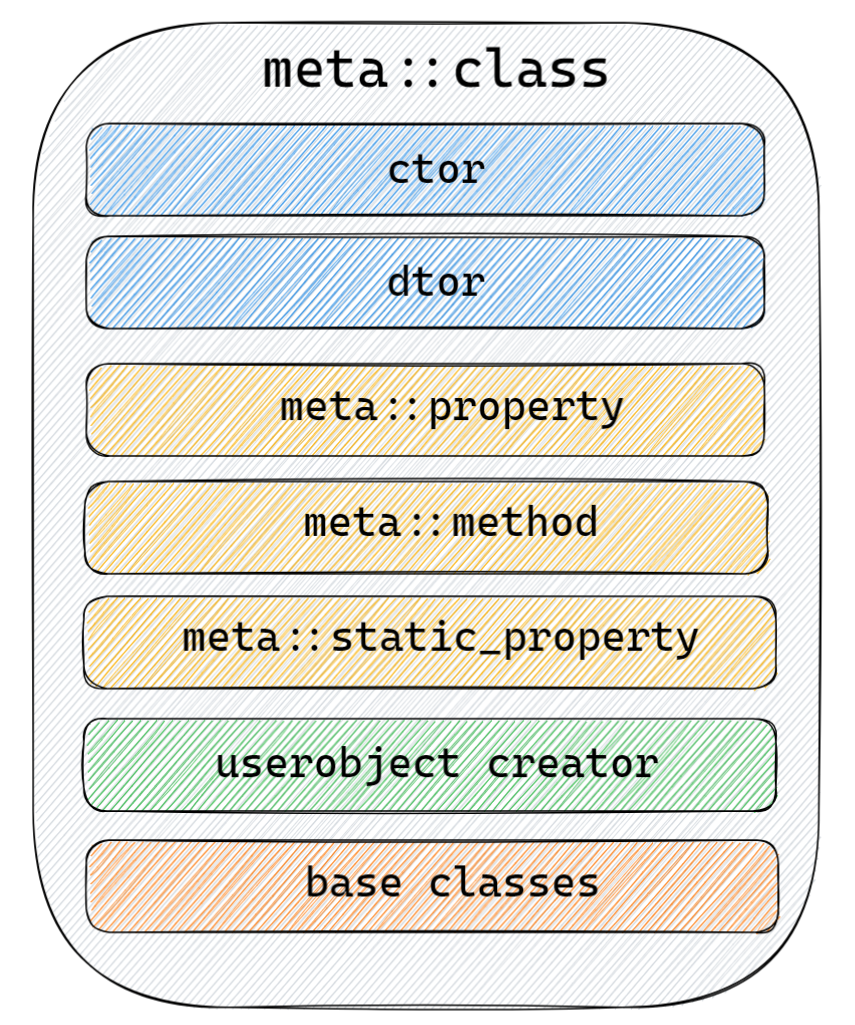
meta::class上存的meta::method都是已經完成類型擦除的版本,所以我們可以通過名稱很容易的從中查詢出自己需要的函數,比如上例中的accelerate,相關代碼類似于:
const reflection::Function* accel_func = nullptr;
car_meta_class.TryGetFunction("accelerate", accel_func);
runtime::Call(*accel_func, car_obj);
當然,此處我們省略了meta::class的注冊過程,也省略了car_obj這個UserObject的創建過程。
(二)folly::Poly《》與UserObject
我們很容易想到,使用UserObject作為Car和Trunk的容器,能夠起到跟folly:Poly《》類似的效果。利用UserObject,我們可以很好的完成各種不同類型對象的類型擦除,很好的完全不同類型對象的統一存儲和函數參數傳遞的目的。
(三)運行時反射實現的例子
這樣,對于原來的例子,省略meta class的注冊過程,大致的代碼如下:
struct Car {
void accelerate() const {
std::cout << "Car accelerate!" << std::endl;
}
};
struct Trunk {
void accelerate() const {
std::cout << "Trunk accelerate!" << std::endl;
}
};
void accel_func(UserObject& v) {
auto& meta_class = v.GetClass();
const reflection::Function* accel_func = nullptr;
meta_class.TryGetFunction("accelerate", accel_func);
runtime::Call(*accel_func, v);
}
int main() {
//Car meta class register ignore here
// ...
//Trunk meta class register ignore here
accel_func(UserObject::MakeOwned(Car{})); // Car accelerate
accel_func(UserObject::MakeOwned(Trunk{})); // Trunk accelerate
return 0;
}
功能上似乎是那么回事,甚至因為運行時反射本身各部分類型擦除很徹底,好像實現上更靈活了,但是,這其實只是形勢上實現了一個運行時interface like的功能,我們容易看出,這個實現達成了以下目的:
非侵入性,Car與Trunk不需要額外的修改就能支持interface like的功能。
我們可以利用類型擦除的UserObject對Car和Trunk這些不同類型的對象進行存儲。
不同對象上的accelerate()實現可以被正確的調用。
同時,這個實現存在諸多的問題:
運行時實現,性能肯定有比較大的折扣。
比較徹底的類型擦除帶來的問題,整個實現一點都不compiler time,編譯期的基礎類型檢查也完全沒有了。
那么我們肯定會想到,poly是如何利用compiler time特性,實現更快的interface like的版本的呢? 這也是我們下一章節開始想展開的內容。
五、poly的實現分析
在開始分析前,我們先來回顧一下前面的示例代碼:
using vehicle = folly::Poly;
void accel_func(vehicle const& v) {
v.accelerate();
}
int main() {
accel_func(Car{}); // Car accelerate
accel_func(Trunk{});
return 0;
}
一切的起點發生在accel_func()將臨時構造的Car{}和Trunk{}向vehicle轉換的過程中,而我們知道vehicle實際類型是folly::Poly
上例中,Car和Trunk類型向Duck Type類型轉換的代碼如下:
template <class I>
template ::value, int>>
inline PolyVal::PolyVal(T&& t) {
using U = std::decay_t;
//some compiler time && runtime check ignore here
//...
if (inSitu()) {
auto const buff = static_cast<void*>(&_data_()->buff_);
::new (buff) U(static_cast(t));
} else {
_data_()->pobj_ = new U(static_cast(t));
}
vptr_ = vtableFor();
}
非常直接的代碼,可以看出與dyno的思路完全一致,主要完成我們前面提到過的兩件事:
Storage policy-分配合適的空間以存儲對象。
VTable policy-為對象關聯正確的VTable。
當然,實際的實現過程其實還有比較多的細節,我們先來具體看一下storage與VTable這兩部分的實現細節。
(一)storage處理
整個poly的storage處理完全參考了dyno的實現,當然并沒有像dyno那樣提供多種storage policy,而是固定的分配策略:
if (inSitu()) {
auto const buff = static_cast<void*>(&_data_()->buff_);
::new (buff) U(static_cast(t));
} else {
_data_()->pobj_ = new U(static_cast(t));
}
適合原地構造的,則直接使用replacement new來原地構造對象(性能最優的方式),否則則還是使用堆分配。這里會用到一個Data類型,也是完全copy的dyno的實現,定義如下:
struct Data {
Data() = default;
// Suppress compiler-generated copy ops to not copy anything:
Data(Data const&) {}
Data& operator=(Data const&) { return *this; }
union {
void* pobj_ = nullptr;
std::aligned_storage_t<sizeof(double[2])> buff_;
};
};
其實我們已經不難猜到inSitu()的實現了,其中肯定有對對象大小的判斷:
template <class T>
inline constexpr bool inSitu() noexcept {
return !std::is_reference::value &&
sizeof(std::decay_t) <= sizeof(Data) &&
std::is_nothrow_move_constructible<std::decay_t>::value;
}
除了原地構造的大小限制外-寫死的兩個double大小,poly增加了對無異常移動構造的約束,也就是對象的移動構造如果不是nothrow的,就算大小滿足要求,也依然會使用堆分配進行構造。
storage這部分主要還是使用SBO的優化策略,這部分dyno相關的視頻中有詳細的介紹,poly的實現完全照搬了那部分思路,感興趣的同學可以自行去看一下參考部分的相關視頻,了解更多的細節,也包括dyno作者自己做的性能分析。
(二)VTable處理
vptr_ = vtableFor《I, U》();
處理的難點
對于Car和Trunk,它們同名的void accelerate()函數,其實類型并不相同,這是因為類的成員函數都隱含了一個this指針,將自己的類型帶入進去了。簡單的保存成員函數的指針的方式肯定不適用了,另外因為我們需要最終得到統一的Duck Type-vehicle,我們也需要統一Car和Trunk的VTable類型,所以這里肯定是要對接口函數的類型做一次擦除操作的。
另外,因為我們需要盡可能的避免運行時開銷,所以在我們使用Duck Type對對象的相關接口,如上面的accelerate()進行訪問的時候,我們希望中間過程是足夠高效的。
poly是如何做到這兩點的呢? 我們帶著這兩個疑問,逐步深入相關的代碼了解具體的實現。
-
vtableFor<>實現
template <class I, class T>
constexpr VTable const* vtableFor() noexcept {
return &StaticConst>> ::value;
}
這個地方的StaticConst是一個類似singleton的封裝:
// StaticConst
//
// A template for defining ODR-usable constexpr instances. Safe from ODR
// violations and initialization-order problems.
template <typename T>
struct StaticConst {
static constexpr T value{};
};
template <typename T>
constexpr T StaticConst::value;
這樣我們就有了一個根據類型來查詢全局唯一VTable指針的機制了,足夠高效。
核心問題的解決都是發生在VTableFor
-
VTableFor與VTable的實現
template <class I, class T>
struct VTableFor : VTable {
constexpr VTableFor() noexcept : VTable{Type{}} {}
};
template <
class I,
class = MembersOf<I, Archetype>>,
class = SubsumptionsOf<I>>
struct VTable;
template <class I, FOLLY_AUTO... Arch, class... S>
struct VTable, TypeList>
: BasePtr..., std::tuple...> {
private:
template <class T, FOLLY_AUTO... User>
constexpr VTable(Type, PolyMembers) noexcept
: BasePtr{vtableFor()}...,
std::tuple...>{thunk_()...},
state_{inSitu() ? State::eInSitu : State::eOnHeap},
ops_{getOps()} {}
public:
constexpr VTable() noexcept
: BasePtr{vtable()}...,
std::tuple...>{
static_cast>(throw_())...},
state_{State::eEmpty},
ops_{&noopExec} {}
template <class T>
explicit constexpr VTable(Type) noexcept
: VTable{Type{}, MembersOf{}} {}
State state_;
void* (*ops_)(Op, Data*, void*);
};
這個地方的代碼實現其實有點繞,一開始我以為是使用的CTAD,c++17的模板參數自動推導的功能,按照類似的方式在自己的代碼上嘗試始終失敗,最后才發現跟CTAD一點關系沒有。
首先是第一點,VTable通過I(也就是例子中的IVehicle),就能夠完全構建出自己的類型了,這也是為什么Car與Trunk的VTable類型完全一致的原因,因為類型定義上,完全不依賴具體的Car和Trunk。
然后是第二點,VTable的第一個構造函數為VTable提供實際的數據來源,這里才會用到具體的類型Car和Trunk。
那么VTable的設計是如何實現具體的類型分離的呢? 這里直接給出答案,我們可以認為,poly對接口函數做了一個部分的類型擦除,相比于之前介紹的反射對所有函數進行類型統一,poly的函數擦除方法可以說是剛剛好,以上文中的accelerate()舉例,在Car中的時候原始類型為:
void(const Car::*)();
最終類型擦除后產生的函數類型為:
void(*)(const folly::Data &);
這樣,不管是Car和Trunk,它們對應接口的類型就被統一了,同時,Data本身也跟我們前面提到的Duck Type-PolyVal關聯起來了。
這種轉換老司機們肯定容易想到lambda,lambda肯定也是用于處理這種參數統一的利器,不過poly這里選用了一種編譯開銷更有優勢的方式:
template <
class T,
FOLLY_AUTO User,
class I,
class = ArgTypes,
class = Bool>
struct ThunkFn {
template <class R, class D, class... As>
constexpr /* implicit */ operator FnPtr() const noexcept {
return nullptr;
}
};
template <class T, FOLLY_AUTO User, class I, class... Args>
struct ThunkFn<
T,
User,
I,
TypeList,
Bool<
!std::is_const>::value ||
IsConstMember>::value>> {
template <class R, class D, class... As>
constexpr /* implicit */ operator FnPtr() const noexcept {
struct _ {
static R call(D& d, As... as) {
return folly::invoke(
memberValue(),
get(d),
convert(static_cast(as))...);
}
};
return &_::call;
}
};
通過一個結構體的靜態函數來繞開lambda來對函數的參數類型進行轉換,當然,通過這里我們也能了解到具體的接口函數的執行過程了,有幾點需要注意一下:
-
folly::invoke()的功能與標準庫的std::invoke()功能一致。
-
get
(d)完成Data類型到具體類型的還原。
-
與反射中類似,也存在對參數表中的參數的convert的處理,這塊就不再展開了,基本都是原始類型參數的派發,因為一些進階功能存在Poly類型轉換派發的情況,此處不再詳細描述了。
再回到多個接口函數的存儲上,這個是通過繼承的std::tuple<>來完成的,所以我們在Interface的定義中也會發現
struct VTable, TypeList>
: BasePtr..., std::tuple...>
template <class T, FOLLY_AUTO... User>
constexpr VTable(Type, PolyMembers) noexcept
: BasePtr{vtableFor()}...,
std::tuple...>{thunk_()...},
state_{inSitu() ? State::eInSitu : State::eOnHeap},
ops_{getOps()} {}
trunk_()函數完成對上面函數類型轉換函數ThunkFn()的調用,這樣整個虛表中最重要的信息就構造完成了。
(三)關于性能
我們直接以windows上的release版為例,通過生成的asm大致推測poly實際的運行時性能:
//...
accel_func(Car{}); // Car accelerate
00007FF696421166 mov qword ptr [rsp+20h],0
00007FF69642116F lea rdi,[__ImageBase (07FF696420000h)]
00007FF696421176 lea rax,[rdi+33B0h]
00007FF69642117D mov qword ptr [rsp+30h],rax
00007FF696421182 lea rcx,[rsp+20h]
00007FF696421187 call ?? ::`folly::ThunkFn,std::integral_constant1 > >::operatorconst > void (__cdecl*)(folly::Data const &)'::`2'::call (07FF696421490h)
00007FF69642118C nop
00007FF69642118D mov rax,qword ptr [rsp+30h]
00007FF696421192 mov r9,qword ptr [rax+10h]
00007FF696421196 xor ecx,ecx
00007FF696421198 xor r8d,r8d
00007FF69642119B lea rdx,[rsp+20h]
00007FF6964211A0 call r9
00007FF6964211A3 nop
accel_func(Trunk{}); // Trunk accelerate
//...
到真正調用到實際的accelerate()函數,編譯期的各種中間過程,基本都能被優化掉,整體性能估計跟virtual dispatch接近或者更高,有時間再結合實際的工程示例測試一下相關的數據,本篇性能相關的分析就先到這里了。
(四)poly小結
poly核心機制的實現并不復雜,主要也就是本章介紹的這部分,但poly還實現了一些進階功能,比如interface之間的繼承,非成員函數的支持等,導致整個實現的復雜度飆升,感興趣的可以自行翻閱相關的代碼,推薦的熟悉順序是:
TypeList.h-里面封裝了大量類型和類型運算相關的功能,整體思路類似boost::mpl的meta function,但基本沒有其他依賴,實現也足夠簡單,值得一看。
PolyNode等其它用于支撐Interface繼承的結構。
正常來說,熟悉了TypeList中的meta function以及常用的TypeFold等實現,讀懂相關代碼不會存在太多的障礙。
另外,Windows上不推薦直接使用源碼編譯folly,依賴庫比較多,并且應該很久沒人維護了,獲取dependency的python腳本都直接報錯,建議windows上直接使用vcpkg 安裝folly進行使用,因為folly與boost 類似,基本只有頭文件實現,通過這種方式并不影響源碼的閱讀和調試。
六、總結
本篇我們重點介紹了編譯期多態,也講到了它與反射的一些關聯和差異,最后結合poly的相關實現介紹了一些核心的技術點。當然,就編譯期反射來說,我們還有更多可以做的內容:
比如參考視頻中提到的結合未來的語言新特性如reflect,meta class來進一步簡化使用接口。
或者通過離線的方式做一部分代碼生成來進一步簡化使用側的Interface定義,甚至提供更強的編譯期約束等。
這些我們會嘗試在實際的落地中逐步完善,有相關的進展再來分享了。
審核編輯:郭婷
-
C++
+關注
關注
22文章
2112瀏覽量
73707 -
代碼
+關注
關注
30文章
4803瀏覽量
68750
原文標題:如何優雅地實現C++編譯期多態?
文章出處:【微信號:C語言與CPP編程,微信公眾號:C語言與CPP編程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HighTec C/C++編譯器套件全面支持芯來RISC-V IP
HighTec C/C++編譯器支持Andes晶心科技RISC-V IP
TMS320C28x優化C/C++編譯器v22.6.0.LTS

OpenHarmony標準系統C++公共基礎類庫案例:HelloWorld

c++編譯后鏈接失敗的原因?如何解決?
C++中實現類似instanceof的方法

SEGGER編譯器優化和安全技術介紹 支持最新C和C++語言

keil用c++編譯含有rtos模塊時的錯誤問題怎么解決?
C++簡史:C++是如何開始的






 工商網監
工商網監
評論