

在機器學習算法中,輸入數據被組織為數據點。每個數據點都由描述所表示數據的特征組成。例如,尺寸和速度是可以將汽車與街道上的自行車區分開來的特征。汽車的大小和速度通常都高于自行車。機器學習方法的目標是將輸入數據轉換為有意義的輸出,例如將輸入數據分類為汽車和非汽車數據點或對象。輸入通常寫為向量,由多個數據點組成。輸出寫為。xy
二維或三維輸入數據可以在所謂的特征空間中進行說明和查看,其中每個數據點都相對于其特征繪制。圖 8 (a) 顯示了描述汽車和非汽車對象的二維特征空間的簡化示例。x
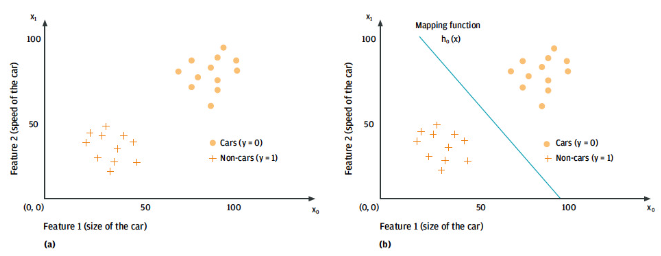
圖8.根據汽車和非汽車物體的大小和速度對汽車和非汽車對象進行分類:特征空間(a)以及兩個類(b)之間的相應間隔。
所謂的學習映射函數或,給出特征向量之間的差異(例如,分類為汽車和非汽車數據點)。該模型的結構范圍從簡單的線性函數(例如圖 8 (a) 中的汽車和非汽車對象的線劃分)到復雜的非線性神經網絡。學習方法的目標是確定系數的值,這些系數表示可用輸入數據中的模型參數。映射函數的輸出是算法對輸入數據描述內容的預測。model,h_θ (x)θ-
機器學習方法可以根據映射函數的學習方式進行分類(圖 9)。有三種可能性:
監督學習 –映射函數是根據訓練數據對計算的,其中預先知道的輸出在訓練階段單獨提供給學習算法。計算出模型參數后,可以將模型部署到目標應用程序中。當它收到未知數據點時,它的輸出將是預測值。yy
無監督學習 –在這種情況下,與監督學習相比,在訓練階段沒有可用的特征標簽對。學習算法的輸入僅包含未標記的數據點。這種機器學習方法的目標是直接從輸入特征在特征空間中的分布中推斷出輸入特征的標簽。x
強化(半監督)學習 –在這種情況下,訓練數據也沒有標簽,但構建模型是為了通過一組操作促進與其環境的交互。映射函數將環境的狀態映射到操作,該狀態由輸入數據提供給操作。獎勵信號指示操作在環境的特定狀態下的性能。當信號表明積極影響時,學習算法會加強動作。如果識別出負面影響,該算法將阻止環境的特定操作或狀態。
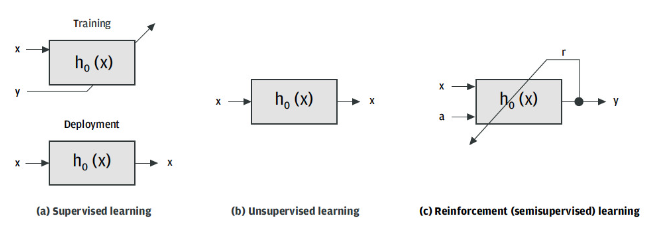
圖9.基于訓練方法的機器學習算法分類。
深度學習革命
近年來,所謂的深度學習范式徹底改變了機器學習領域。深度學習通過解決以前傳統模式識別方法無法解決的挑戰,對機器學習社區產生了巨大影響(LeCun et al. 2015)。深度學習的引入極大地提高了專為視覺識別、對象檢測、語音識別、異常檢測或基因組學而設計的系統精度。深度學習的關鍵方面是,用于解釋數據的特征是從訓練數據中自動學習的,而不是由工程師手動制作的。
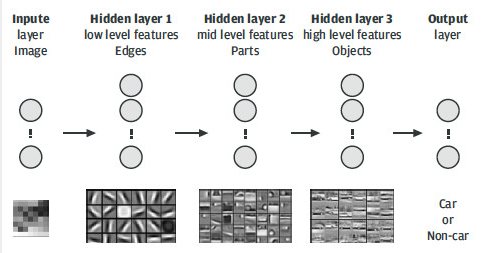
圖 10.經過訓練的深度卷積神經網絡可以識別圖像中的汽車。
到目前為止,構建良好的模式識別算法的主要挑戰是手動設計用于分類的手工制作的特征向量,例如早期版本的交通標志識別系統中使用的局部二進制模式,如第 1 部分所述。深度學習的出現已經用學習算法取代了特征向量的手動工程,該算法可以自動發現原始輸入數據中的重要特征。
在架構上,深度學習系統由多層非線性單元組成,可以將原始輸入數據轉換為更高級別的抽象。每個層將前一層的輸出映射到適用于回歸或分類任務的更復雜的表示中。這種學習通常在深度神經網絡上進行,該網絡通過使用反向傳播算法進行訓練。該算法迭代地調整網絡的參數或權重,以模擬輸入訓練數據。因此,網絡在訓練結束時學習了輸入數據點的復雜非線性映射函數。
圖 10 顯示了深度神經網絡的符號表示,該網絡經過訓練以識別圖像中的汽車。輸入層表示原始輸入像素。隱藏層 1 通常模擬圖像某些位置和方向中邊緣的存在與否。第二個隱藏層使用在前一層中計算的邊對對象零件進行建模。第三個隱藏層構建了建模對象的抽象表示,在我們的例子中,這是汽車的成像方式。輸出層根據第三個隱藏層的高級特征計算給定圖像包含汽車的概率。
不同的網絡架構源于神經網絡的單元和層的分布方式。所謂的感知器是最簡單的,由單個輸出神經元組成。通過構建感知器可以獲得大量的神經網絡風格。這些網絡中的每一個都比其他網絡更適合特定的應用程序。圖 11 顯示了近年來創建的眾多神經網絡架構中最常見的三種。
深度前饋神經網絡(圖11a)是一種結構,其中兩個相鄰層之間的神經元完全互連,并且信息流僅在一個方向上,從系統的輸入到輸出。這些網絡可用作通用分類器,并用作所有其他類型的深度神經系統的基礎。
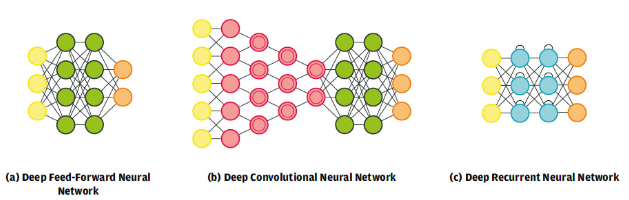
圖 11.深度神經網絡架構(來源:www.asimovinstitute.org)
深度卷積神經網絡(圖11b)改變了視覺感知方法的發展方式。此類網絡由交替的卷積層和池化層組成,這些層通過從輸入數據進行泛化來自動學習對象特征。這些學習到的特征被傳遞到一個完全互連的前饋網絡進行分類。這種類型的卷積網絡是圖 10 所示汽車檢測架構和第1 部分描述的用例的基礎。
雖然深度卷積網絡對視覺識別至關重要,但深度遞歸神經網絡(圖11c)對于自然語言處理至關重要。由于隱藏層中神經元之間的自遞歸連接,這種架構中的信息是時間依賴性的。網絡的輸出可能因數據饋入網絡的順序而異。例如,如果在單詞“mouse”之前輸入單詞“cat”,則會獲得一定的輸出。現在,如果輸入順序發生變化,輸出順序也可能更改。
機器學習算法的類型
盡管深度神經網絡是復雜機器學習挑戰中最常用的解決方案之一,但還有各種其他類型的機器學習算法可用。表1根據其性質(連續或離散)和訓練類型(有監督或無監督)對它們進行分類。
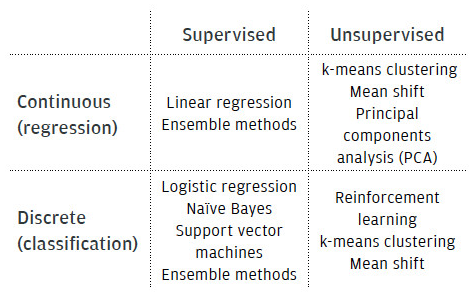
表 1.機器學習算法的類型
機器學習估計器可以根據其輸出值或訓練方法大致分類。如果后者估計連續值函數(即連續輸出),則該算法被歸類為回歸估計器。當機器學習算法的輸出是離散變量時,該算法稱為分類器。第 1 部分中描述的交通標志檢測和識別系統是此類算法的實現。y
? Ry ? {0,1,…,q}
異常檢測是無監督學習的一種特殊應用。此處的目標是識別數據集中的異常值或異常。異常值定義為特征向量,與應用程序中常見的特征向量相比,這些特征向量具有不同的屬性。換句話說,它們在特征空間中占據不同的位置。
表 1 還列出了一些流行的機器學習算法。下面簡要解釋這些內容。
線性回歸是一種回歸方法,用于將線、平面或超平面擬合到數據集。擬合模型是一個線性函數,可用于對實值函數進行預測。y
邏輯回歸是線性回歸方法的離散對應物,其中映射函數給出的預測實際值被轉換為概率輸出,該輸出表示輸入數據點對某個類的成員資格。
樸素貝葉斯分類器是一組基于貝葉斯定理構建的機器學習方法,該定理假設每個特征都獨立于其他特征。
支持向量機 (SVM) 旨在使用所謂的邊距計算類之間的分離。邊距的計算盡可能寬,以便盡可能清楚地分隔類。
集成方法,如決策樹、運行dom 森林或AdaBoost組合了一組基礎分類器,有時稱為“弱”學習器,目的是獲得“強”分類器。
神經網絡是機器學習算法,其中回歸或分類問題由一組稱為神經元的互連單元解決。從本質上講,神經網絡試圖模仿人腦的功能。
K-均值聚類是一種用于將具有共同屬性的特征分組在一起的方法,即它們在特征空間中彼此接近。k 均值根據要分組的給定聚類數,以迭代方式將常見要素分組到球形聚類中。
均值偏移也是一種數據聚類技術,對于異常值而言,該技術更為通用和穩健。與 k 均值相反,均值偏移只需要一個優化參數(搜索窗口大小),并且不假定數據聚類的球形先驗形狀。
主成分分析 (PCA) 是一種數據降維技術,它將一組可能相關的特征轉換為一組名為主成分的線性不相關變量。主成分按方差順序排列。第一個分量的變化最大;第二個在此之下有下一個變體,依此類推。
第三部分在功能安全要求的背景下評估這些機器學習算法。
審核編輯:郭婷
-
機器學習
+關注
關注
66文章
8473瀏覽量
133732 -
深度學習
+關注
關注
73文章
5536瀏覽量
122191
發布評論請先 登錄
相關推薦
射頻電路設計——理論與應用
**【技術干貨】Nordic nRF54系列芯片:傳感器數據采集與AI機器學習的完美結合**
背景抑制光電開關的設計及應用
【「具身智能機器人系統」閱讀體驗】1.全書概覽與第一章學習
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
什么是機器學習?通過機器學習方法能解決哪些問題?


【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】+ 鳥瞰這本書
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
機器學習算法原理詳解
深度學習與傳統機器學習的對比
名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?
深入探討機器學習的可視化技術






 工商網監
工商網監

評論