 術開發一種硬件高效的RepGhost模塊
術開發一種硬件高效的RepGhost模塊
1 RepGhost:重參數化技術構建硬件高效的 Ghost 模塊
GhostNetV2 解讀:NeurIPS'22 Spotlight|華為諾亞GhostNetV2出爐:長距離注意力機制增強廉價操作
G-GhostNet 解讀:想要一個適配GPU端的輕量級網絡?安排!華為諾亞帶著 G-GhostNet 走來
1.1.1 特征復用技術和本文動機
特征復用技術是指:通過簡單地連接來自不同層的已有的一些特征圖,來額外獲得一些其他的特征。比如在 DenseNet[1] 中,在一個 Stage 內,前面層的特征圖被重復使用并被饋送到它們的后續層,從而產生越來越多的特征圖。或者在 GhostNet 中,作者通過一些廉價的操作來生成更多的特征圖,并將它們與原始特征圖 Concat 起來,從而產生越來越多的特征圖。它們都通過 Concat 操作,利用特征復用技術,來擴大 channel 數量和網絡容量,同時保持一個比較低的 FLOPs。似乎 Concat 操作已經成為特性復用的標準操作。
Concat 操作確實是一種 0 Params,0 FLOPs 的操作。但是,它在硬件設備上的計算成本是不可忽略的。 因為參數量和 FLOPs 不是機器學習模型實際運行時性能的直接成本指標。作者發現,在硬件設備上,由于復雜的內存復制,Concat 操作比加法操作效率低得多。因此,值得探索一種更好的、硬件效率更高的方法,以更好地適配特征復用技術。
因此,作者考慮引入結構重參數化方法,這個系列方法的有效性在 CNN 體系結構設計中得到了驗證。具體而言,模型訓練時是一個復雜的結構,享受高復雜度的結構帶來的性能優勢,訓練好之后再等價轉換為簡單的推理結構,且不需要任何時間成本。受此啟發,作者希望借助結構重參數化方法來實現特征的隱式重用,以實現硬件高效的架構設計。
所以本文作者希望通過結構重新參數化技術開發一種硬件高效的 RepGhost 模塊,以實現特征的隱式重用。如前文所述,要把 Concat 操作去掉,同時修改現有結構以滿足重參數化的規則。因此,在推斷之前,特征重用過程可以從特征空間轉移到權重空間,使 RepGhost 模塊高效。
1.1.2 Concat 操作的計算成本
作者將 GhostNet 1.0x 中的所有 Concat 操作替換成了 Add 操作,Add 操作也是一種處理不同特征的簡單操作,且成本較低。這兩個運算符作用于形狀完全相同的張量上。如下圖1所示為對應網絡中所有32個對應運算符的累計運行時間。Concat 操作的成本是 Add 操作的2倍。
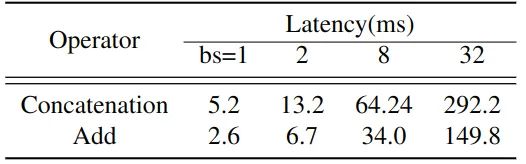
圖1:在基于 ARM 的手機上 Concat 操作和 Add 操作處理不同 Batch Size 的數據的運行時間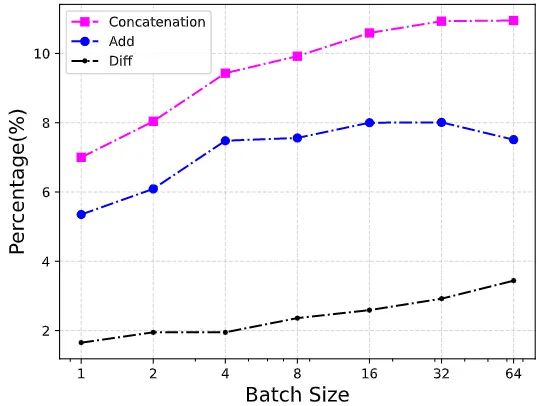
圖2:每個操作符在整個網絡中的運行時間的百分比。Diff:Concat 操作和 Add 操作的差值的百分比
1.1.3 Concat 操作和 Add 操作
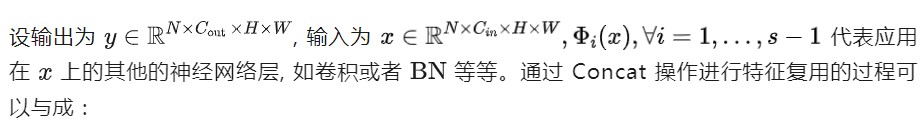
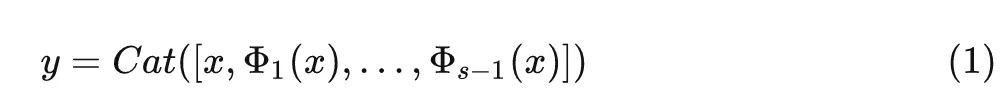
式中, 代表 Concat 操作。它只保留現有的特征映射,將信息處理留給下面的層。例如,在 Concat 操作之后通常會有一個 1×1 卷積來處理信道信息。但是,Concat 操作的成本問題促使作者尋找一種更有效的方法。
通過 Add 操作進行特征復用的過程可以寫成:
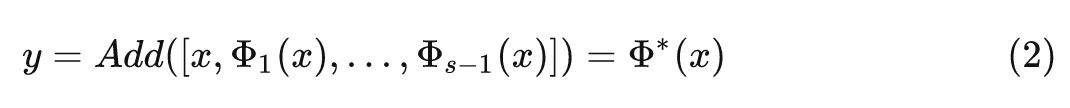
式中, 代表 Add 操作。與 Concat 操作不同,Add 操作還具有特征融合的作用,而且特征融合過程是在權值空間中完成的,不會引入額外的推理時間。
基于此,作者提出了以下 RepGhost 模塊。
1.1.4 RepGhost 模塊
這一小節介紹如何通過重參數化技術來進行特征復用,具體而言介紹如何從一個原始的 Ghost 模塊演變成 RepGhost 模塊。如下圖3所示,從 Ghost 模塊開始:
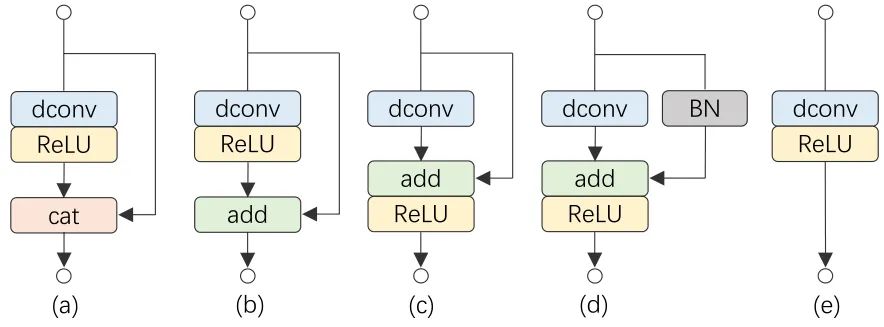
圖3:從一個原始的 Ghost 模塊演變成 RepGhost 模塊的過程
(a) 原始的 Ghost 模塊,這里省去了第一步的 1×1 卷積。
(b) 把原始的 Ghost 模塊的 Concat 操作換成 Add 操作,以求更高的效率。
(c) 把 ReLU 移到 Add 操作之后,這種移動使得模塊滿足結構重新參數化規則,從而可用于快速推理。
(d) 在恒等映射 Identity Mapping 分支中添加 BN 操作,使得在訓練過程中帶來非線性,并且可以被融合用于快速推斷。
(e) 模塊 (d) 可以被融合成模塊 (e),用于快速推斷。RepGhost 模塊有一個簡單的推理結構,它只包含規則的卷積層和ReLU,這使得它具有較高的硬件效率。特征融合的過程是在權重空間,而不是在特征空間中進行,然后把兩個分支的參數進行融合產生快速推理的結構。
與 Ghost 模塊的對比
作用:
Ghost 模塊提出從廉價的操作中生成更多的特征圖,因此可以以低成本的方式擴大模型的容量。
RepGhost 模塊提出了一種更有效的方法,通過重參數化來生成和融合不同的特征圖。與 Ghost 模塊不同,RepGhost 模塊去掉了低效的 Concat 操作,節省了大量推理時間。并且信息融合過程由 Add 操作以隱含的方式執行,而不是留給其他卷積層。

1.1.5 RepGhostNet 網絡

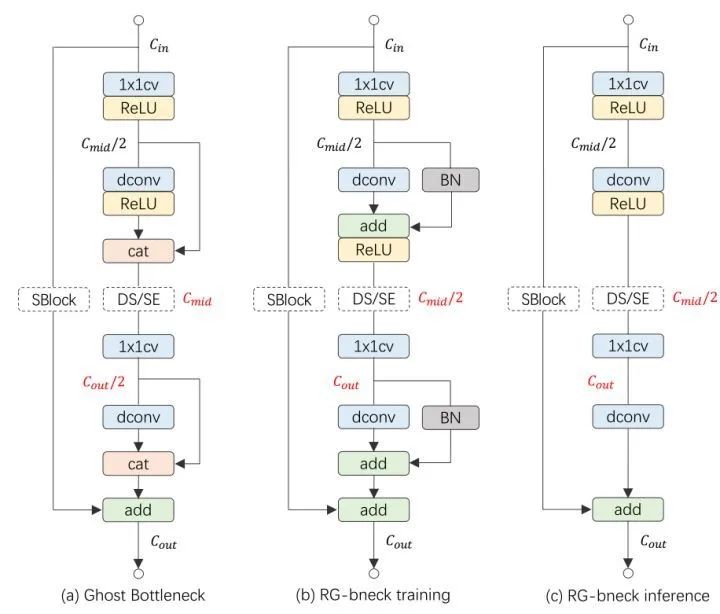
圖4:(a) GhostNet 網絡的一個 Block。(b) RepGhost 網絡訓練時的一個 Block。(c) RepGhost 網絡推理時的一個 Block
下圖5所示是 RepGhostNet 的網絡架構。首先是一個輸出通道為16的卷積層處理輸入數據。一堆正常的 1×1 卷積和 AvgPool 預測最終輸出。根據輸入大小將 RepGhost Bottleneck 分成5組,并且為每組中除最后一個 Bottleneck 之外的最后一個 Bottleneck 設置 stride=2。
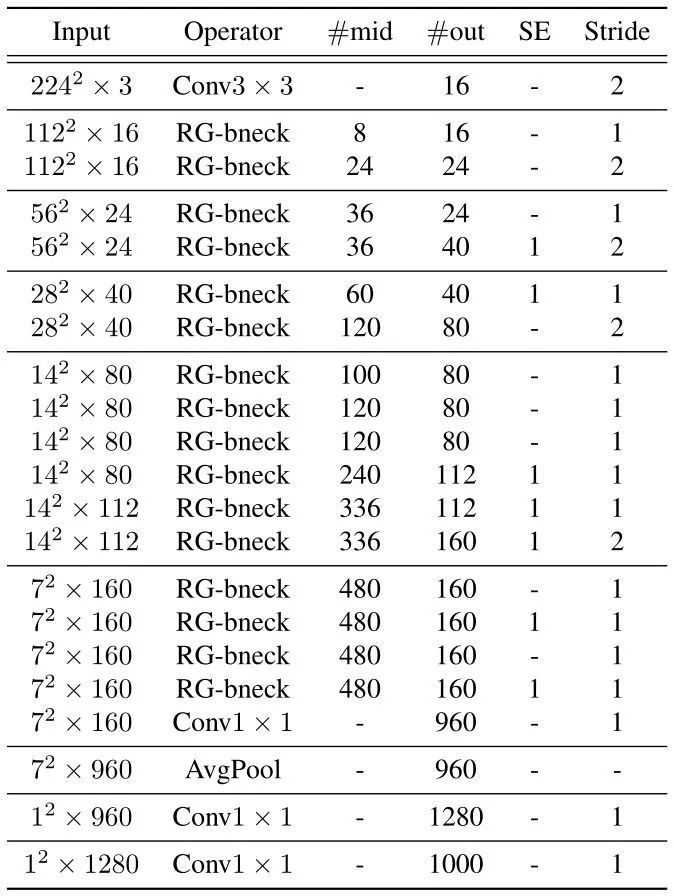
圖5:RepGhost 網絡架構
1.1.6 實驗結果
ImageNet-1K 實驗結果
如下圖所示是 ImageNet-1K 圖像分類任務的實驗結果。NVIDIA V100 GPUs ×8 作為訓練設備,Batch size 開到1024,優化器 SGD (0.9 momentum),基本學習率為 0.6,Epoch 數為 300,weight decay 為1e-5,并且使用衰減系數為0.9999的 EMA (Exponential Moving Average) 權重衰減。數據增強使用 timm 庫的圖像裁剪和翻轉,prob 0.2 的隨機擦除。對于更大的模型 RepGhostNet 1.3×,額外使用 auto augment。
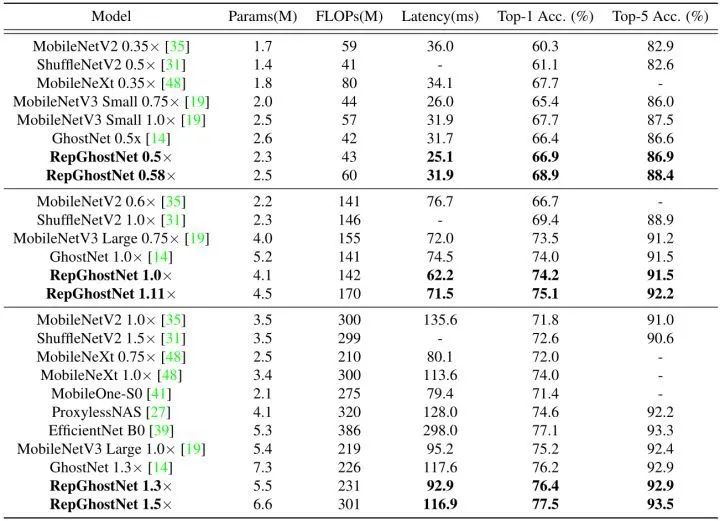
圖6:ImageNet-1K 實驗結果
實驗結果如上圖6所示。根據 FLOPs,所有模型被分為3個級別。在基于 ARM 的手機上評估每個模型的相應延遲。圖1描繪了所有模型的延遲和精度。可以看到,在準確性-延遲權衡方面,RepGhostNet 優于其他手動設計和基于 NAS 的模型。
RepGhostNet 實現了與其他先進的輕量級 CNN 相當甚至更好的準確性,而且延遲低得多。例如,RepGhostNet 0.5× 比 GhostNet 0.5× 快 20%,Top-1 準確性高 0.5%,RepGhostNet 1.0× 比 MobileNetV3 Large 0.75× 快 14%,Top-1 準確性高 0.7%。在延遲相當的情況下,RepGhostNet 在所有三個量級大小的模型上面都超過所有對手模型。比如,RepGhostNet 0.58× 比 GhostNet 0.5× 高 2.5%,RepGhostNet 1.11× 比MobileNetV3 Large 0.75× 高 1.6%。
目標檢測和實例分割實驗結果
使用 RetinaNet 和 Mask RCNN分別用于目標檢測任務和實例分割任務。僅替換 ImageNet 預訓練的主干,并在8個 NVIDIA V100 GPUs 中訓練12個時期的模型結果如下圖7所示。RepGhostNet 在兩個任務上都優于MobileNetV2,MobileNetV3 和 GhostNet,且推理速度更快。例如,在延遲相當的情況下,RepGhostNet 1.3× 在這兩項任務中比 GhostNet 1.1× 高出 1% 以上,RepGhostNet 1.5× 比 MobileNetV2 1.0× 高出 2% 以上。
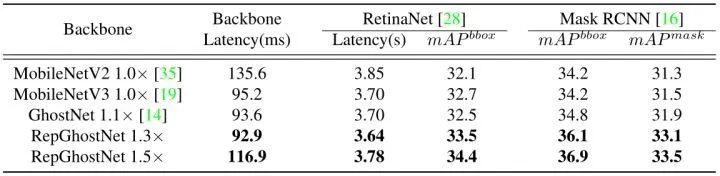
圖7:目標檢測和實例分割實驗結果
消融實驗1:與 Ghost-Res50 的對比
為了驗證大模型的 RepGhost 模塊的泛化性,作者將其與 GhostNet 模型 Ghost-Res50 進行了比較。用 RepGhost 模塊替換 Ghost-Res50 中的 Ghost 模塊,得到 RepGhost-Res50。所有模型都使用相同的訓練設置進行訓練。對于 MNN 延時,與圖6結果使用相同的手機測得。對于 TRT 延遲,作者首先將模型轉換為 TensorRT,然后在 Batch size 為32的 T4 GPU 上運行框架上的每個模型100次,并報告平均延遲。
結果如下圖8所示。可以看到,RepGhost-Res50 在 CPU 和 GPU 上都明顯快于 Ghost-Res50,但精度相當。特別地,在 MNN 推理和 TensorRT 推理中,RepGhost-Res50 (s=2) 比 Ghost-Res50 (s=4) 分別獲得了 22% 和44% 的加速比。

圖8:與 Ghost-Res50 的對比
消融實驗2:重參數化結構
為了驗證重新參數化結構,作者在 RepGhostNet 0.5× 上進行消融實驗,方法是在圖 3(c) 所示的模塊的恒等映射分支中交替使用 BN,1×1 Depth-wise Convolution 和恒等映射本身。結果如下圖9所示。可以看到,帶有 BN 重參數化的 RepGhostNet 0.5× 達到了最好的性能。作者將其作為所有其他 RepGhostNet 的默認重新參數化結構。
作者將這種改善歸因于 BN 的非線性,它提供了比恒等映射更多的信息。1×1 Depth-wise Convolution 之后也是 BN,因此,由于后面的歸一化,其參數對特征不起作用,并且可能使 BN 統計不穩定,作者推測這導致了較差的性能。
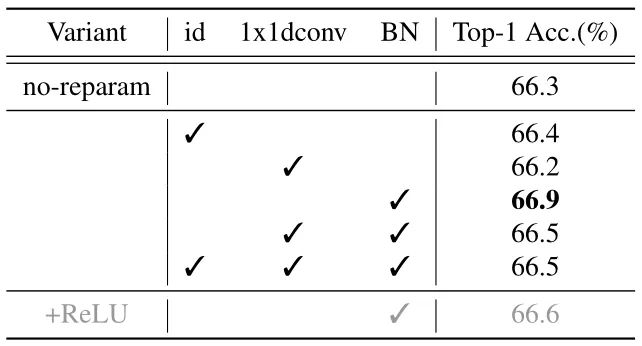
圖9:重新參數化結構消融實驗
消融實驗3:Shortcut 的必要性
盡管 會增加內存訪問成本 (從而影響運行時性能),但對于計算受限的移動設備來說,這種影響可以忽略不計,如表所示。7.考慮到所有這些,我們確認快捷方式對于輕量級CNN是必要的,并在我們的RepGhostNet中保留快捷方式。mageNet 數據集上的準確性,結果如下圖顯示了使用和不使用快捷方式時 RepGhostNet 的準確性和延遲。
很明顯,Shortcut 不會嚴重影響實際運行的延時,但有助于優化過程。另一方面,大模型去掉 Shortcut 對 Latency 的影響要小于小模型,這可能意味著 Shortcut 對于輕量級 CNN 比大型模型更重要,例如 RepVGG 和 MobileOne。
盡管 Shortcut 會增加內存訪問成本 (從而影響運行時性能),但對于計算受限的移動設備來說,這種影響可以忽略不計。考慮到所有這些,我們認為 Shortcut 對于輕量級 CNN 是必要的,并在 RepGhostNet 中保留了 Shortcut 操作。
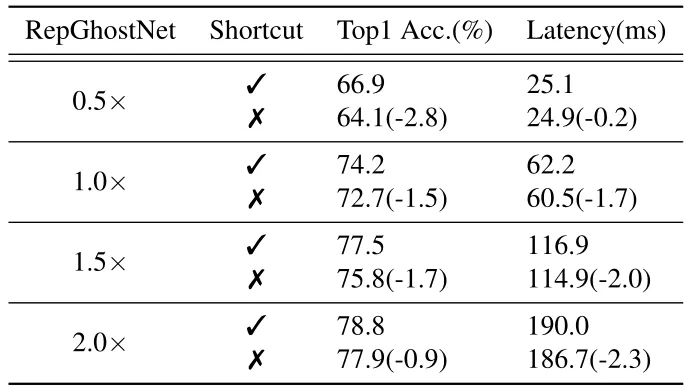
圖10:Shortcut 的必要性消融實驗結果
總結
GhostNet 通過一些廉價的操作來生成更多的特征圖,并將它們與原始特征圖 Concat 起來,從而產生越來越多的特征圖,它利用特征復用技術,來擴大 channel 數量和網絡容量,同時保持一個比較低的 FLOPs。似乎 Concat 操作已經成為特性復用的標準操作。Concat 操作確實是一種 0 Params,0 FLOPs 的操作。
但是,它在硬件設備上的計算成本是不可忽略的。所以本文作者希望通過結構重新參數化技術開發一種硬件高效的 RepGhost 模塊,以實現特征的隱式重用。RepGhostNet 把 Concat 操作去掉,同時修改現有結構以滿足重參數化的規則。最終得到的 RepGhostNet 是一個高效的輕量級 CNN,在幾個視覺任務中都展示出了移動設備的精度-延遲權衡方面良好的技術水平。
審核編輯:劉清
-
gpu
+關注
關注
28文章
4768瀏覽量
129320 -
機器學習
+關注
關注
66文章
8438瀏覽量
133020 -
cnn
+關注
關注
3文章
353瀏覽量
22317 -
ema
+關注
關注
0文章
3瀏覽量
2400
原文標題:輕量級CNN模塊!RepGhost:重參數化實現硬件高效的Ghost模塊
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【WaRP7試用申請】一種高效的協議融合解決方案
一種高效LLC電源參考設計
一種無線射頻收發模塊的應用
開發DSP硬件驅動程序的一種方法
一種模塊化高效電子商務推薦系統的設計

一種基于GaN的超高效功率模塊
一種明場成像細胞術(BFIC)技術
一種簡單高效配置FPGA的方法





 工商網監
工商網監
評論