 JSON壓縮算法解讀
JSON壓縮算法解讀

1.關于作者
大家好!我是來自深圳技術大學FSR Lab(編者注:Falcon Swarm Robotics Lab獵鷹集群機器人控制實驗室的縮寫)的同學,標題FFH就是FSRlab For Harmony!并且我也正在參加OpenHarmony成長計劃從論文到開源提交研究,以后我們也會陸續在這個社區記錄學習心得和體會。
在OpenHarmony成長計劃啃論文俱樂部里,FFH小組同學們與華為、軟通動力、潤和軟件、拓維信息、深開鴻等公司一起,學習和研究序列化相關技術…
2. 為什么需要壓縮JSON?
盡管JSON數據格式比XML效率要高,但是它仍然是web服務器和瀏覽器傳輸過程中比較低效的數據格式。為什么呢?
-
首先,它將所有的內容都轉換為了文本。
-
第二是轉換之后的文本過度使用引號,這樣會給每個字符串添加多兩個字節。
-
第三,它本身沒有schema的標準格式,比如在一個消息中序列化多個對象的時候,即使每個對象的屬性的鍵名是重復且相同的,但是轉換后的文本數據還是會重復每一個鍵名。
JSON以前的時候有一個優勢,就是可以被Javascript引擎直接解析,但因為現在越來越重視安全性,JSON的這個優勢也逐漸消失了,但是因為它比XML效率以及性能都更高,所以許多傳統的C/S模式都是選擇JSON,比如web服務。當有龐大的數據量以及復雜數據結構需要從web瀏覽器中傳輸到服務器的時候,JSON壓縮就起到了非常大的作用,然而中間就會存在我們剛剛說的三點問題,我們也不能使用傳統的gzip壓縮算法,因為瀏覽器不知道服務器是否支持gzip解壓。
下面我們就來看看兩種常見的JSON壓縮算法,cJSON與HPack。
3. cJSON壓縮算法
cJSON壓縮算法(cJSON Compression Algorithm)的特點就是可以使用自動類型提取壓縮JSON數據格式的內容。它成功解決了一個非常重要的問題,就是我們上一小節提到的第三點,將不斷重復的鍵名舍去了,我們我們來看一個例子:
使用cJSON前的數據格式:
[
{ //表示一個坐標點
"x":100,
"y":100
},
{ //表示一個長方形
"x":100,
"y":100,
"width":200,
"height":150
},
{},//表示一個空對象
... //以下省略數以萬計的對象
]
上面未經壓縮的數據中,我們可以看到有非常多的空間被重復的鍵名所占據,比如“x”,“y”等等,當數據非常多的時候,這些看起來不起眼的重復鍵名會給傳輸效率帶來非常大的影響,其實解決思路也非常簡單,因為他們是重復的,那我們只存儲一次不就好了?下面我們來按照我們的思路看看cJSON處理過后的數據吧。
{
"templates":[
[], //type1
[] //type2
],
"value":[
{ //第一個對象:坐標點
"type":1,
"values":[
100,
100
]
},
{ //第二個對象:矩形
"type":2,
"values":[
100,
100,
200,
150
]
},
{
//第三個空對象
},
//以下省略數以萬計的對象......
]
}
從上面的數據中我們可以看到,我們格式化了數據,把鍵名存儲了起來,重復的就不存儲,然后值通過“type”索引來對應鍵名,這樣在數據量龐大的時候確實減少了不少空間,但是我們仔細看“templates”內的鍵名依舊有重復的字段存在。說明了我們還存在優化空間,優化完壓縮后效果如下:
{ "function": "cjson",
"templates": [
[0, "x", "y"],
[1, "width", "height"]
],
"values": [
[1, 100, 100 ], //第一個對象:坐標點
[2, 100, 100, 200, 150 ], //第二個對象:矩形
[] //第三個空對象
]
}
直接看壓縮后的代碼結構你可能不太能理解,那我們就來看看他的具體原理,為了解決“template”內鍵名重復的字段,這個算法采用了樹這個數據結構,每遇到一個要傳輸的對象,就按順序把鍵值存入樹的節點中(灰色的節點是被標記的結尾節點指針,表示該節點存儲的是某個對象最后一個屬性的鍵值),重復的就不存儲,這樣就解決了我們的問題,這個鍵值樹的變化過程如下:
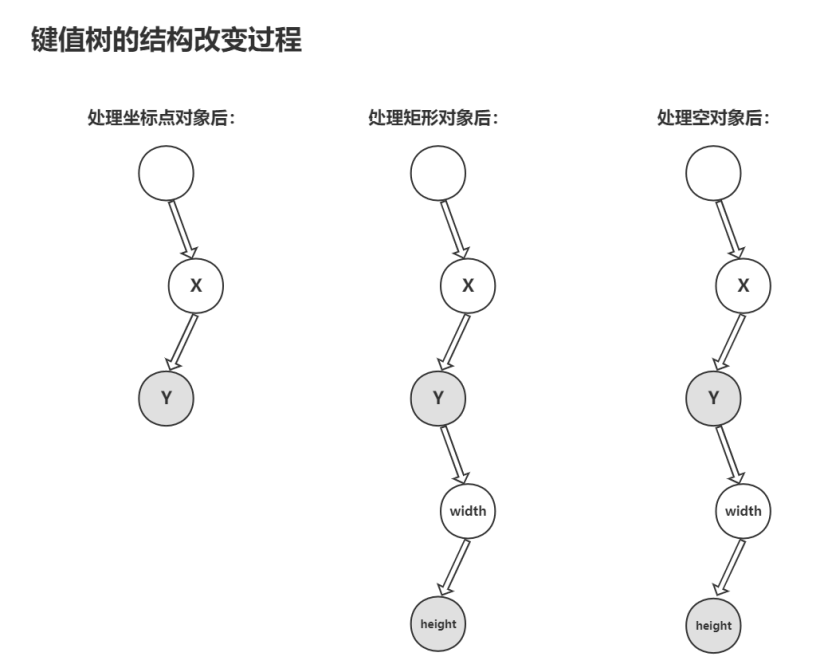
最后數據在匹配鍵值的時候就根據 “values” 中所標記的結尾節點指針找到對應鍵值數組,這樣就構成了cJSON的壓縮算法。
仔細的同學就會發現,如果一個對象中沒有"X"和"Y",只有“width”和“height”,或者鍵值節點順序是錯的,是不是會出問題?答案是對的,會出現無法匹配的鍵值的情況,所以這種方法只能在特定的場景下應用,存在一定局限性。
總體來說,cJSON在處理非常龐大的數據量的時候效果還是非常客觀的。
4.JSON.HPack壓縮算法
JSON.HPack壓縮算法(HPack Compression Algorithm)是一種無損、跨語言、注重性能的JSON數據壓縮算法,可以讓我們在使用post請求在客戶端發送數據到服務器的過程中相對普通JSON格式節省約70%的字符。
其原理本質上也是跟cJSON一樣將鍵值抽離開,舉個例子:
使用HPack算法前:
{
"id" : 1,
"sex" : "Female",
"age" : 38,
"classOfWorker" : "Private",
"maritalStatus" : "Married-civilian spouse present",
"education" : "1st 2nd 3rd or 4th grade",
"race" : "White"
}
使用HPack算法后:
[],
[]
可以看到相對于普通JSON以及cJSON少了很多字符,比如引號,各種括號等等,這種壓縮算法在數據量龐大的情況下效果也非常可觀。
HPack算法提供了幾個級別的壓縮(從0到4)。等級越高壓縮效率越高,每提升一個等級都有引入附加功能。0級壓縮通過從結構中分離鍵值來執行最基本的壓縮,并在索引0的元素上創建鍵名數組,下一個等級就可以通過假設存在重復條目來進一步減小JSON數據的大小。
5.性能分析
接下來我們直接用數據來看看這幾個壓縮算法的壓縮效率,我們分別用5組大小不同的JSON文件(50KB~1MB),每個JSON文件將使用servlet容器(tomcat)提供給瀏覽器,并分別用以下算法進行壓縮:
-
Original JSON size - 未作修改的JSON數據
-
Minimized - 刪除空白和新行(最基本的js優化)
-
Compresse cJSON - 使用CJSON壓縮算法進行JSON壓縮
-
Compresse HPack - 使用JSON.HPack壓縮算法進行JSON壓縮
-
Gzipped - 使用gzip和進行JSON壓縮
-
Gzipped + Minimized - 使用gzip和刪除空白和新行(最基本的js優化)進行JSON壓縮
-
Gzipped + Compresse cJSON - 使用gzip和CJSON壓縮算法進行JSON壓縮
-
Gzipped + Compresse HPack - 使用gzip和JSON.HPack壓縮算法進行JSON壓縮
下表(TABLE I.RESULTES)是用以上各種方式處理完后的JSON數據大小(bytes),不同列表示不同的JSON數據集,不同行表示使用不同的壓縮方式。
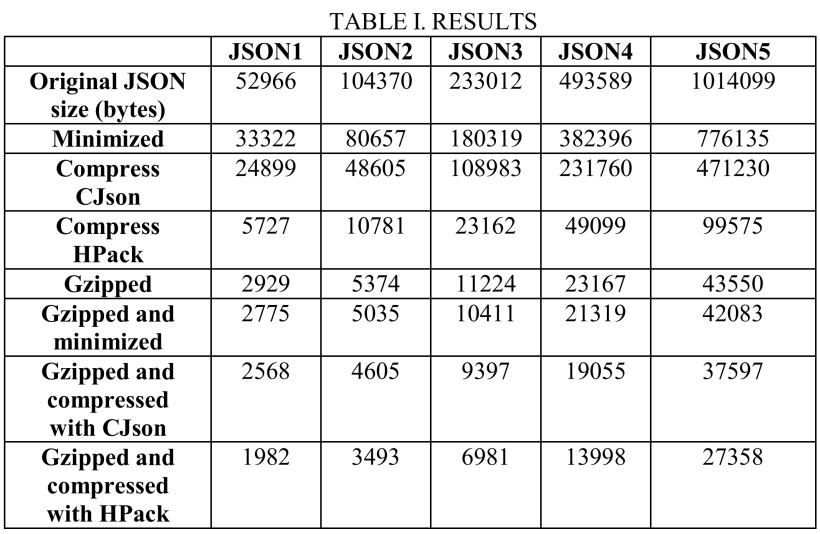
下面第一個圖表Y軸表示JSON數據大小(bytes):
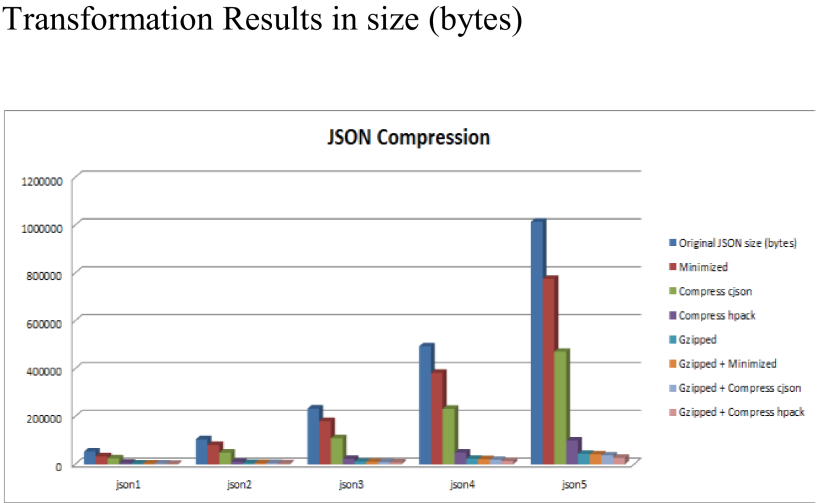
第二張圖Y軸是JSON數據大小的百分比(%),原始數據為100%:
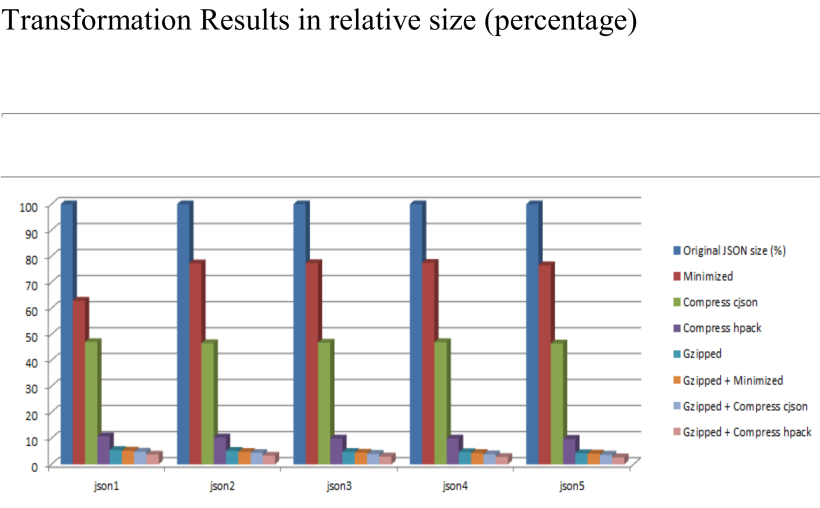
從上面的幾個圖表中我們可以直觀地看到,單獨使用cJSON可以把原始數據大小壓縮到45%左右,單獨使用HPack可以把原始數據大小壓縮到8%左右,可見整體上HPack是優于cJSON的。
然而我們可以看到當使用gzip和上面提到的兩個壓縮算法相結合進行JSON壓縮,效果才是最優的,基本可以達到1%~2%的壓縮率。
總的來說,HPack比cJSON效率更高,速度也更快,但是在使用壓縮算法進行傳輸的過程中,接收的一端需要進行相應的解壓縮操作,否則無法使用被壓縮過后的JSON數據,這一步也會存在一定的性能開銷,在我們選擇使用JSON壓縮的時候,也需要考慮到這一點。當可以使用gzip進行壓縮的時候,這種方法比其他壓縮算法的效率都高,當兩者同時結合起來,效果顯而易見。
好了,我們這一次完整地了解了JSON序列化的發展,規范,應用以及相關的壓縮算法,相信大家不僅對JSON壓縮算法有了更深的了解,也對JSON序列化這個技術領域有了深刻的認識。
6.參考文獻
JSON Compression Algorithmshttp://repository.utm.md/bitstream/handle/5014/6418/ICMCS_2011_1_pg_244_247.pdf?sequence=1<本文完>
寫在最后
OpenHarmony 成長計劃—“啃論文俱樂部”(以下簡稱“啃論文俱樂部”)是在 2022年 1 月 11 日的一次日常活動中誕生的。截至 3 月 31 日,啃論文俱樂部已有 87 名師生和企業導師參與,目前共有十二個技術方向并行探索,每個方向都有專業的技術老師帶領同學們通過啃綜述論文制定技術地圖,按“降龍十八掌”的學習方法編排技術開發內容,并通過專業推廣培養高校開發者成為軟件技術學術級人才。
啃論文俱樂部的宗旨是希望同學們在開源活動中得到軟件技術能力提升、得到技術寫作能力提升、得到講解技術能力提升。大學一年級新生〇門檻參與,已有俱樂部來自多所高校的大一同學寫出高居榜首的技術文章。
如今,搜索“啃論文”,人們不禁想到、而且看到的都是我們——OpenHarmony 成長計劃—“啃論文俱樂部”的產出。
OpenHarmony開源與開發者成長計劃—“啃論文俱樂部”學習資料合集
1)入門資料:啃論文可以有怎樣的體驗
https://docs.qq.com/slide/DY0RXWElBTVlHaXhi?u=4e311e072cbf4f93968e09c44294987d
2)操作辦法:怎么從啃論文到開源提交以及深度技術文章輸出https://docs.qq.com/slide/DY05kbGtsYVFmcUhU
3)企業/學校/老師/學生為什么要參與 & 啃論文俱樂部的運營辦法https://docs.qq.com/slide/DY2JkS2ZEb2FWckhq
4)往期啃論文俱樂部同學分享會精彩回顧:
同學分享會No1.成長計劃啃論文分享會紀要(2022/02/18)https://docs.qq.com/doc/DY2RZZmVNU2hTQlFY
同學分享會No.2 成長計劃啃論文分享會紀要(2022/03/11)https://docs.qq.com/doc/DUkJ5c2NRd2FRZkhF
同學們分享會No.3 成長計劃啃論文分享會紀要(2022/03/25)
https://docs.qq.com/doc/DUm5pUEF3ck1VcG92?u=4e311e072cbf4f93968e09c44294987d
現在,你是不是也熱血沸騰,摩拳擦掌地準備加入這個俱樂部呢?當然歡迎啦!啃論文俱樂部向任何對開源技術感興趣的大學生開發者敞開大門。

掃碼添加 OpenHarmony 高校小助手,加入“啃論文俱樂部”微信群
后續,我們會在服務中心公眾號陸續分享一些 OpenHarmony 開源與開發者成長計劃—“啃論文俱樂部”學習心得體會和總結資料。記得呼朋引伴來看哦。























原文標題:JSON壓縮算法解讀
文章出處:【微信公眾號:開源技術服務中心】歡迎添加關注!文章轉載請注明出處。
-
開源技術
+關注
關注
0文章
389瀏覽量
7963 -
OpenHarmony
+關注
關注
25文章
3728瀏覽量
16405
原文標題:JSON壓縮算法解讀
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
EE-257:面向Blackfin處理器的引導壓縮/解壓縮算法

think-cell——使用JSON數據實現自動化(一)

【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
【BearPi-Pico H3863星閃開發板體驗連載】LZO壓縮算法移植
Huffman壓縮算法概述和詳細流程
名單公布!【書籍評測活動NO.46】從算法到電路 | 數字芯片算法的電路實現
JSON協議是什么,物聯網中的RTU中如何使用JSON協議和服務器交互
【RTC程序設計:實時音視頻權威指南】音視頻的編解碼壓縮技術
FPGA壓縮算法有哪些

Python壓縮和解壓縮實現代碼分享
基于門控線性網絡(GLN)的高壓縮比無損醫學圖像壓縮算法





 工商網監
工商網監
評論