

主要內(nèi)容: 提出了一種基于NeRF的六自由度姿態(tài)估計方法,即當(dāng)給定單個RGB查詢圖像時通過最小化NeRF模型渲染的圖像像素與查詢圖像中的像素之間的殘差來估計相機的平移和旋轉(zhuǎn)。
算法將基于動量的相機外參優(yōu)化算法集成到Instant Neural Graphics Primitives(一種最近非常快速的NeRF實現(xiàn),也是NVIDIA提出的),通過在姿態(tài)估計任務(wù)中引入并行蒙特卡羅采樣來克服問題總是收斂到局部極小值的問題,論文還研究了不同的基于像素的損失函數(shù)減少誤差的程度,最終的實驗也表明其方法可以在合成基準(zhǔn)和真實基準(zhǔn)上實現(xiàn)較好的泛化和魯棒性
Nerf(Neural Radiance Fields):神經(jīng)輻射場,它提供了一種僅從一個或幾個RGB圖像中捕獲復(fù)雜3D和光學(xué)結(jié)構(gòu)的機制,Nerf為在訓(xùn)練或測試期間在沒有網(wǎng)格模型的情況下將合成-分析應(yīng)用到更廣泛的現(xiàn)實場景提供了機會,NeRF將場景的密度和顏色參數(shù)化為3D場景坐標(biāo)的函數(shù),該函數(shù)既可以從給定相機姿態(tài)的多視圖圖像中學(xué)習(xí),也可以給定一個或幾個輸入圖像通過生成模型直接預(yù)測。
Instant NGP:其提出是用來降低Nerf的訓(xùn)練和推理代價,采用由可訓(xùn)練的特征向量的多分辨率哈希表增強的小神經(jīng)網(wǎng)絡(luò),允許網(wǎng)絡(luò)消除哈希沖突的歧義,使其易于在GPU上并行化,實現(xiàn)了幾個數(shù)量級的組合加速,允許在在線訓(xùn)練和推理等時間受限的環(huán)境中使用
出發(fā)點: 將Nerf用在姿態(tài)估計任務(wù)中的第一篇工作則是inerf,即反轉(zhuǎn)Nerf,此論文基于inerf,進(jìn)一步探索了Nerf在姿態(tài)估計任務(wù)中的應(yīng)用,普遍認(rèn)為NeRF的一個缺點是其計算開銷很大,為了克服這一限制,本文利用了他們之前提出的快速NeRF,即即時神經(jīng)圖形原件(Instant NGP),Instant NGP的結(jié)構(gòu)允許并行優(yōu)化,這可以用來克服局部最小值問題,從而實現(xiàn)比iNeRF更大的魯棒性。 Inerf:假設(shè)已經(jīng)得到了權(quán)重θ參數(shù)化的NeRF模型,并且相機內(nèi)參已知,iNeRF旨在恢復(fù)查詢圖像I的相機姿態(tài)T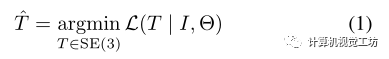
Contributions:
提出了一種基于NeRF模型的估計6-DoF姿態(tài)方法。
將并行蒙特卡羅采樣引入到姿態(tài)估計任務(wù)中,展示了基于像素的損失函數(shù)選擇對魯棒性的重要性
通過合成和真實世界基準(zhǔn)進(jìn)行定量演示,證明所提出的方法改進(jìn)了泛化和魯棒性
Pipeline: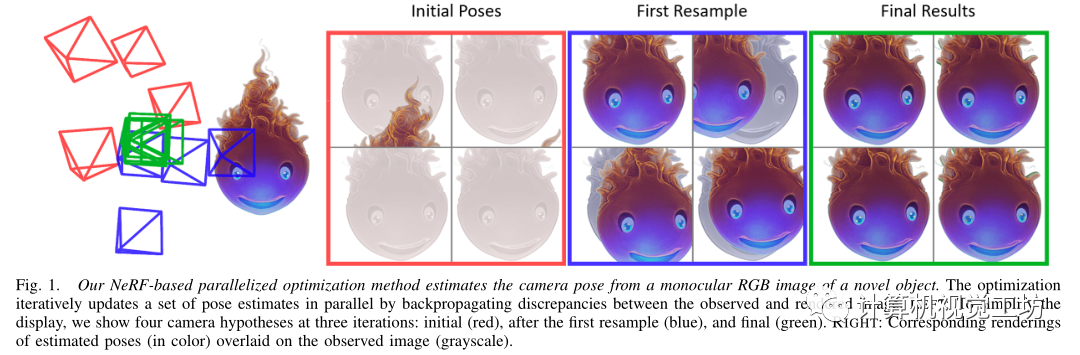
三個輸入:單個RGB圖像、初始粗略姿態(tài)估計(通過向真值添加干擾得到)以及從目標(biāo)的多個視圖中訓(xùn)練的即時NGP模型。
基于動量的相機外參優(yōu)化:
相對于標(biāo)準(zhǔn)Nerf,對相機姿態(tài)和梯度表示進(jìn)行了修改,允許梯度更新的動態(tài)性結(jié)合基于動量的方法來增強優(yōu)化。
首先,相機姿態(tài)由平移分量(位置)和旋轉(zhuǎn)分量(方向)組成,通常由特殊歐式群建模,即SE(3),NeRF中外參優(yōu)化的目標(biāo)是找到那些通過梯度下降將圖像空間損失最小化的相機姿態(tài),梯度更新在特殊的歐式群上的李代數(shù)se(3)中計算,然后生成結(jié)合旋轉(zhuǎn)和平移的相機姿態(tài)更新,作者認(rèn)為使用SE(3)/se3表示有一個缺點,即相機姿勢更新的旋轉(zhuǎn)中心不在相機原點,而是在旋轉(zhuǎn)軸上,這將相機位置和方向耦合起來,這種耦合導(dǎo)致某些情況下次優(yōu)梯度更新,如下圖所示,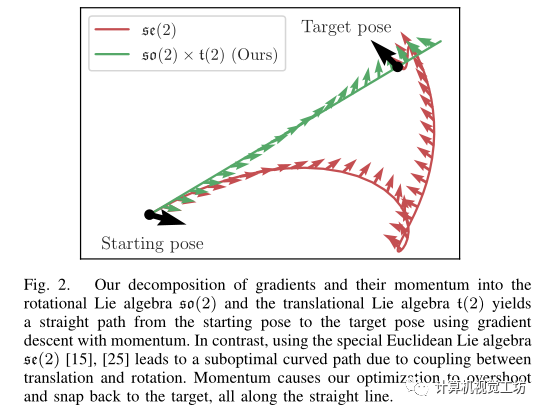
為了解耦平移和旋轉(zhuǎn)更新,作者將相機姿態(tài)建模為笛卡爾積SO(3)×T(3)(以及相應(yīng)的李代數(shù)空間上so(3)×t(3)),其在T(3)上采用加法結(jié)構(gòu),在SO(3)上采用乘積結(jié)構(gòu),梯度更新將沿直線移動,從而實現(xiàn)更高效的優(yōu)化。
其次,基于動量的優(yōu)化在經(jīng)驗上證明了比基于標(biāo)準(zhǔn)梯度的方法更有效,尤其是當(dāng)與自適應(yīng)更新相結(jié)合時,在NeRF中每個像素對應(yīng)于具有原點o和方向d的射線,沿著該射線,基于沿射線的移動距離ti得到pi=o+ti.d,損失的梯度與相機距離的叉積定義了每像素(光線)更新影響:
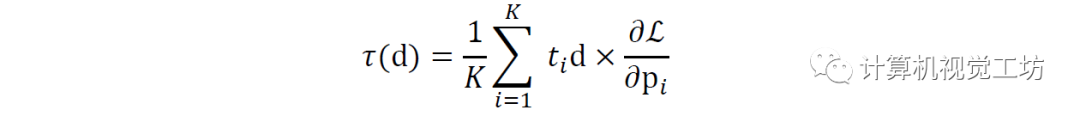
基于剛體力學(xué),對上式有一種物理解釋,即由外力對相機產(chǎn)生的一個扭矩,該外力由基于圖像的損失函數(shù)梯度產(chǎn)生,應(yīng)用于光線導(dǎo)出點,就像它剛性地連接到相機一樣。
因此將此分解應(yīng)用于Adam優(yōu)化器,將Adam的第一個moment轉(zhuǎn)化為相機的物理動量,因為相機被用作力矩的梯度“推動”,盡管Adam的第二moment和指數(shù)衰減沒有直接的物理類似物,由于物理系統(tǒng)遵循最小動作路徑,可以推斷相機在解耦參數(shù)化中遵循從其初始姿態(tài)到其優(yōu)化姿態(tài)的有效路徑。
并行蒙特卡洛采樣: 由于優(yōu)化的損失函數(shù)在6-DoF空間上是非凸的,單相機姿態(tài)假設(shè)很容易陷入局部極小值,由于Instant NGP的計算能力能夠同時從多個假設(shè)開始優(yōu)化,但是一個簡單的多起點思想是低效的,特別是在一個大的搜索空間中,其中許多假設(shè)在優(yōu)化過程中會偏離,因此它們無法對最終優(yōu)化做出貢獻(xiàn),且占用了大量計算資源,從粒子濾波框架中獲得靈感,提出了一種簡單有效的姿勢假設(shè)更新策略來處理這個問題。
將優(yōu)化過程分為兩個階段,自由探索和重采樣更新。 在第一階段,圍繞起始姿態(tài)生成相機姿態(tài)假設(shè),平移和旋轉(zhuǎn)偏移分別在歐式空間和SO(3)中均勻采樣,相機姿態(tài)假設(shè)將進(jìn)行獨立優(yōu)化,這樣其中一些可以相對接近實際情況。 之后第二階段,比較所有假設(shè)的損失,并將其作為采樣權(quán)重的參考。
不同損失函數(shù)的影響: 通過合成視圖進(jìn)行姿態(tài)估計的方法最大挑戰(zhàn)之一是與原視圖相比,視圖材質(zhì)具有不同的視覺表面,包括許多干擾、環(huán)境噪聲、照明條件變化和遮擋等都可能導(dǎo)致這個問題。
之前inerf使用L2損失,但作者研究了更多的損失選項以測量渲染像素和觀察像素之間的差異,不同的損失具有不同的收斂特性,進(jìn)而影響優(yōu)化過程
研究了L1(平等的對待error)、L2(懲罰較大的error,寬容較小的error)、Log L1(是L1損耗的對數(shù)版本,它試圖平滑收斂曲線,尤其是對于較大的誤差)、Relative L2(它對高強度目標(biāo)像素與低強度目標(biāo)像素錯位的情況更敏感)、MAPE(MAPE表示平均絕對百分比誤差,作為基于誤差相對百分比的精度度量,它也可以被視為相對L2損耗的L1等效值,它與規(guī)模無關(guān),對負(fù)錯誤的懲罰更重)、sMAPE(是MAPE的對稱版本,解決MAPE的不對稱問題,但當(dāng)預(yù)測和GT都具有低強度時,它可能是不穩(wěn)定的)、Smooth L1(平滑L1損失被設(shè)計為對異常值不太敏感,并且可以防止梯度爆炸)
最終通過實驗發(fā)現(xiàn)常用的L2損失未必是最好的,MAPE在其數(shù)據(jù)集測試上實現(xiàn)了最好的性能。
實驗: 在Nerf合成數(shù)據(jù)集和真實數(shù)據(jù)集LLFF與inerf進(jìn)行了比較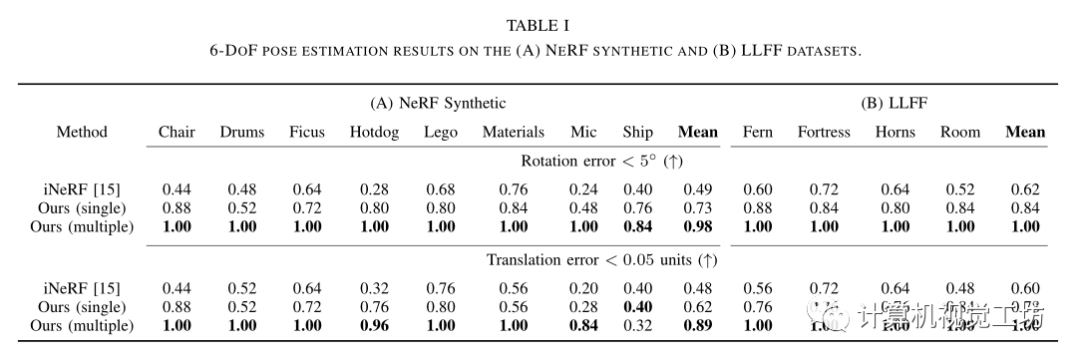
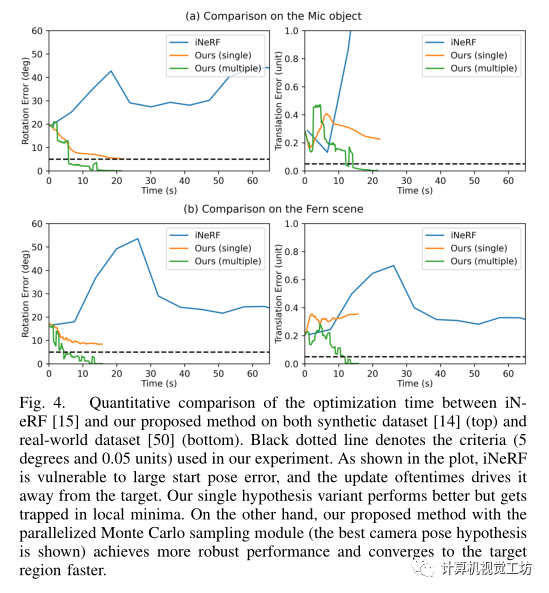
不同損失函數(shù)對結(jié)果性能的比較: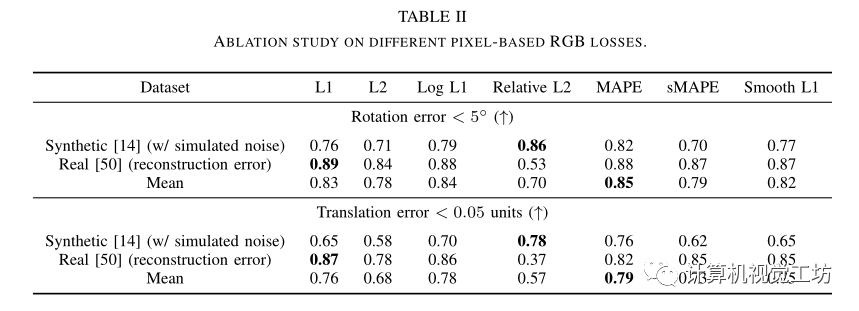
審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4797瀏覽量
102223 -
RGB
+關(guān)注
關(guān)注
4文章
803瀏覽量
59387 -
NGP
+關(guān)注
關(guān)注
0文章
12瀏覽量
6730
原文標(biāo)題:并行Nerf逆過程解決姿態(tài)估計問題!(Arxiv 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
DSP在六自由度電磁跟蹤系統(tǒng)中的應(yīng)用
基于FPGA EtherCAT的六自由度機器人視覺伺服控制設(shè)計
基于STM32、以太網(wǎng)、Labview的六自由度Stewart并聯(lián)運動平臺模型
一種改進(jìn)的單神經(jīng)元二自由度PID控制
基于單親遺傳算法二自由度PID控制器設(shè)計
二自由度內(nèi)模控制方法
三自由度轉(zhuǎn)臺的設(shè)計與實現(xiàn)
一種新型7自由度冗余繩驅(qū)動機械臂

一種基于六自由度IMU和動力學(xué)的車身姿態(tài)和側(cè)向速度估計方法

磁致伸縮位移傳感器在六自由度運動平臺上的應(yīng)用解析

六自由度視覺定位
六自由度激光跟蹤儀的特點

一文讀懂六自由度激光跟蹤儀






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論