") IPMT:用于小樣本語(yǔ)義分割的中間原型挖掘Transformer
IPMT:用于小樣本語(yǔ)義分割的中間原型挖掘Transformer
本文簡(jiǎn)要介紹發(fā)表在NeurIPS 2022上關(guān)于小樣本語(yǔ)義分割的論文《Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation》。該論文針對(duì)現(xiàn)有研究中忽視查詢(xún)和支持圖像之間因類(lèi)內(nèi)多樣性而帶來(lái)的類(lèi)別信息的差距,而強(qiáng)行將支持圖片的類(lèi)別信息遷移到查詢(xún)圖片中帶來(lái)的分割效率低下的問(wèn)題,引入了一個(gè)中間原型,用于從支持中挖掘確定性類(lèi)別信息和從查詢(xún)中挖掘自適應(yīng)類(lèi)別知識(shí),并因此設(shè)計(jì)了一個(gè)中間原型挖掘Transformer。文章在每一層中實(shí)現(xiàn)將支持和查詢(xún)特征中的類(lèi)型信息到中間原型的傳播,然后利用該中間原型來(lái)激活查詢(xún)特征圖。借助Transformer迭代的特性,使得中間原型和查詢(xún)特征都可以逐步改進(jìn)。相關(guān)代碼已開(kāi)源在:
https://github.com/LIUYUANWEI98/IPMT
一、研究背景
目前在計(jì)算機(jī)視覺(jué)取得的巨大進(jìn)展在很大程度上依賴(lài)于大量帶標(biāo)注的數(shù)據(jù),然而收集這些數(shù)據(jù)是一項(xiàng)耗時(shí)耗力的工作。為了解決這個(gè)問(wèn)題,通過(guò)小樣本學(xué)習(xí)來(lái)學(xué)習(xí)一個(gè)模型,并將該模型可以推廣到只有少數(shù)標(biāo)注圖像的新類(lèi)別。這種設(shè)置也更接近人類(lèi)的學(xué)習(xí)習(xí)慣,即可以從稀缺標(biāo)注的示例中學(xué)習(xí)知識(shí)并快速識(shí)別新類(lèi)別。
本文專(zhuān)注于小樣本學(xué)習(xí)在語(yǔ)義分割上的應(yīng)用,即小樣本語(yǔ)義分割。該任務(wù)旨在用一些帶標(biāo)注的支持樣本來(lái)分割查詢(xún)圖像中的目標(biāo)物體。然而,目前的研究方法都嚴(yán)重依賴(lài)從支持集中提取的類(lèi)別信息。盡管支持樣本能提供確定性的類(lèi)別信息指導(dǎo),但大家都忽略了查詢(xún)和支持樣本之間可能存在固有的類(lèi)內(nèi)多樣性。
在圖1中,展示了一些支持樣本原型和查詢(xún)圖像原型的分布。從圖中可以觀(guān)察到,對(duì)于與查詢(xún)圖像相似的支持圖像(在右側(cè)標(biāo)記為“相似支持圖像”),它們的原型在特征空間中與查詢(xún)?cè)徒咏谶@種情況下匹配網(wǎng)絡(luò)可以很好地工作。然而,對(duì)于與查詢(xún)相比在姿勢(shì)和外觀(guān)上具有較大差異的支持圖像(在左側(cè)標(biāo)記為“多樣化支持圖像”),支持和查詢(xún)?cè)椭g的距離會(huì)很遠(yuǎn)。在這種情況下,如果將支持原型中的類(lèi)別信息強(qiáng)行遷移到查詢(xún)中,則不可避免地會(huì)引入較大的類(lèi)別信息偏差。
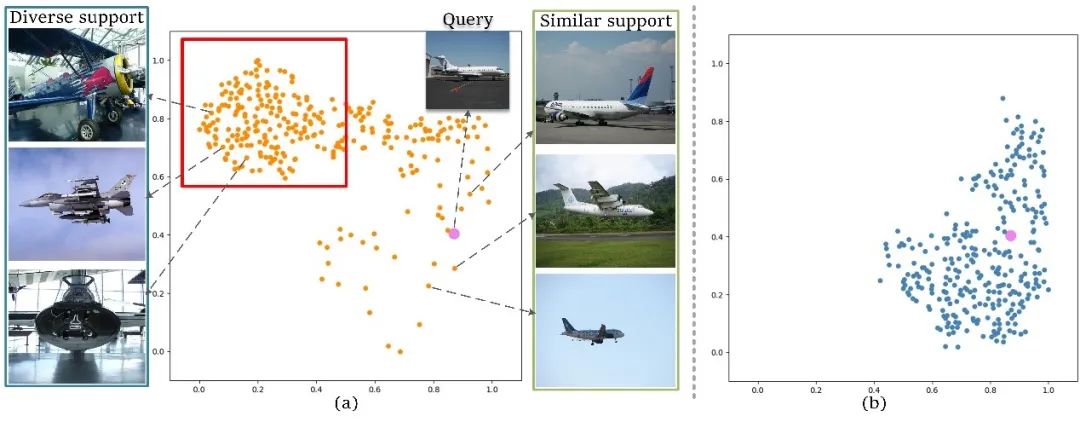
圖1 支持樣本原型與查詢(xún)圖像原型分布圖
因此,本文在通過(guò)引入一個(gè)中間原型來(lái)緩解這個(gè)問(wèn)題,該原型可以通過(guò)作者提出的中間原型挖掘Transformer彌補(bǔ)查詢(xún)和支持圖像之間的類(lèi)別信息差距。每層Transformer由兩個(gè)步驟組成,即中間原型挖掘和查詢(xún)激活。在中間原型挖掘中,通過(guò)結(jié)合來(lái)自支持圖像的確定性類(lèi)別信息和來(lái)自查詢(xún)圖像的自適應(yīng)類(lèi)別知識(shí)來(lái)學(xué)習(xí)中間原型。然后,使用學(xué)習(xí)到的原型在查詢(xún)特征激活模塊中激活查詢(xún)特征圖。此外,中間原型挖掘Transformer以迭代方式使用,以逐步提高學(xué)習(xí)原型和激活查詢(xún)功能的質(zhì)量。
二、方法原理簡(jiǎn)述
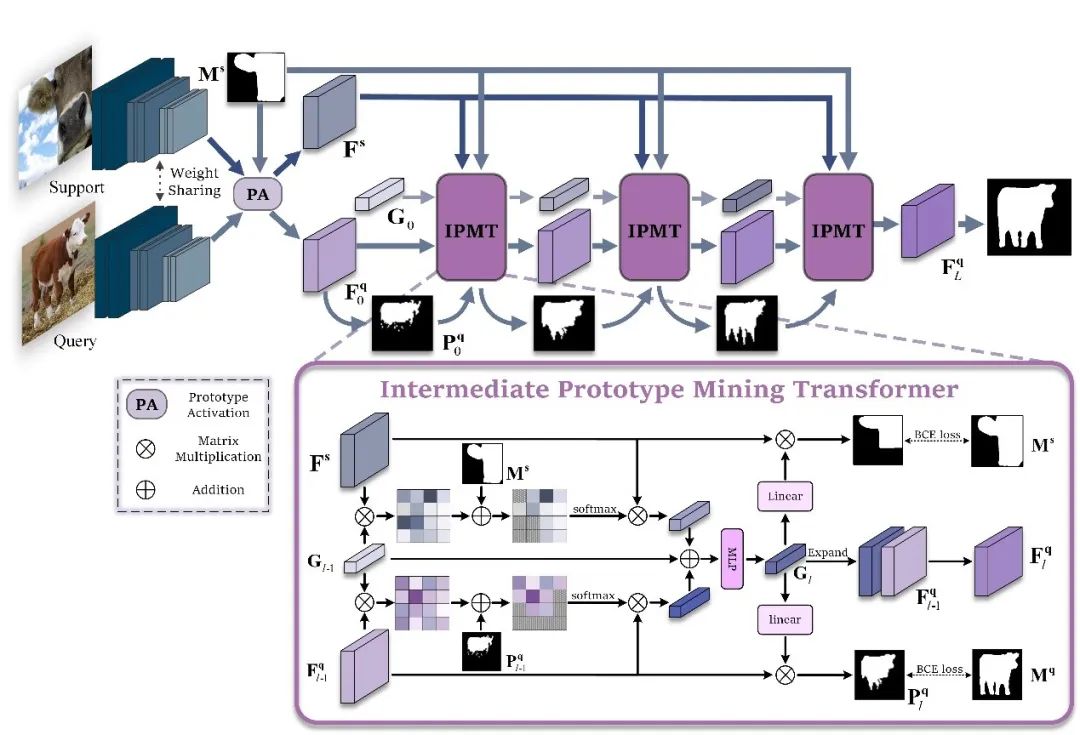
圖2 方法總框圖
支持圖像和查詢(xún)圖像輸入到主干網(wǎng)絡(luò)分別提取除支持特征和查詢(xún)特征。查詢(xún)特征在原型激活(PA)模塊中經(jīng)過(guò)簡(jiǎn)單的利用支持圖像原型進(jìn)行激活后,分割成一個(gè)初始預(yù)測(cè)掩碼,并將該掩碼和激活后的查詢(xún)特征作為中間原型挖掘Transformer層的一個(gè)輸入。同時(shí),將支持特征、支持圖片掩碼和隨機(jī)初始化的一個(gè)中間原型也做為第一層中間原型挖掘Transformer的輸入。在中間原型挖掘Transformer層中,首先進(jìn)行掩碼注意力操作。具體來(lái)說(shuō),計(jì)算中間原型與查詢(xún)或支持特征之間的相似度矩陣,并利用下式僅保留前景區(qū)域的特征相似度矩陣:
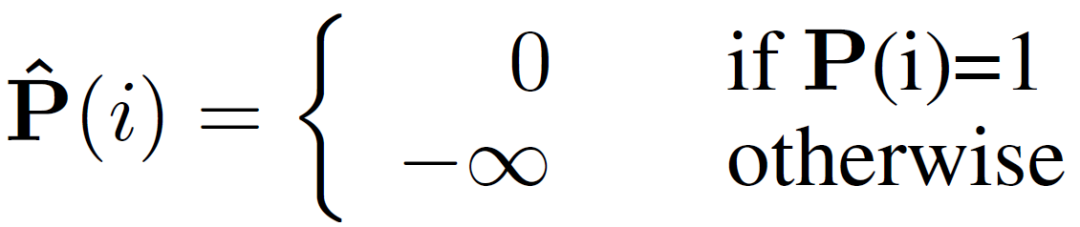
處理后的相似度矩陣作為權(quán)重,分別捕獲查詢(xún)或支持特征中的類(lèi)別信息并形成新的原型。
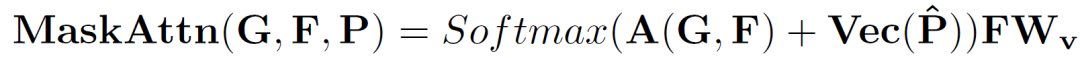
查詢(xún)特征新原型、支持特征新原型和原中間原型結(jié)合在一起形成新的中間原型,完成對(duì)中間原型的挖掘。
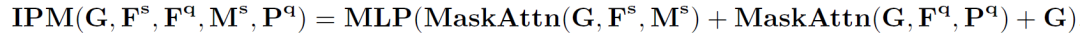
而后,新的中間原型在查詢(xún)特征激活模塊中對(duì)查詢(xún)特征中的類(lèi)別目標(biāo)予以激活。
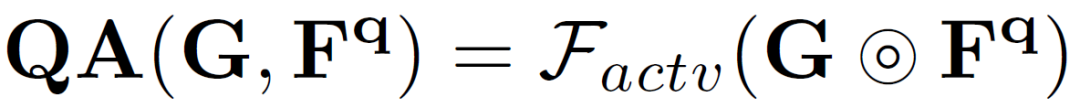
為了便于學(xué)習(xí)中間原型中的自適應(yīng)類(lèi)別信息,作者使用它在支持和查詢(xún)圖像上生成兩個(gè)分割掩碼,并計(jì)算兩個(gè)分割損失。
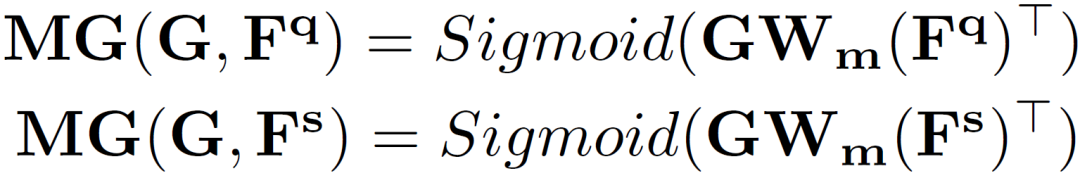
并設(shè)計(jì)雙工分割損失(DSL):
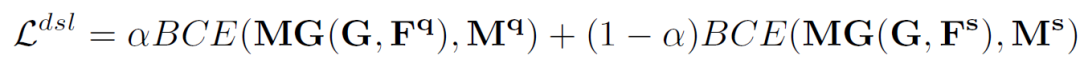
由于一個(gè)中間原型挖掘Transformer層可以更新中間原型、查詢(xún)特征圖和查詢(xún)分割掩碼,因此,作者通過(guò)迭代執(zhí)行這個(gè)過(guò)程,得到越來(lái)越好的中間原型和查詢(xún)特征,最終使分割結(jié)果得到有效提升。假設(shè)有L 層,那么對(duì)于每一層有:
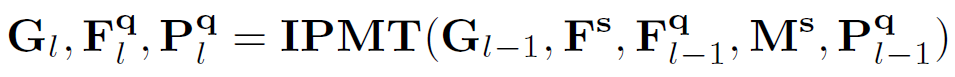
上式中具體過(guò)程又可以分解為以下環(huán)節(jié):
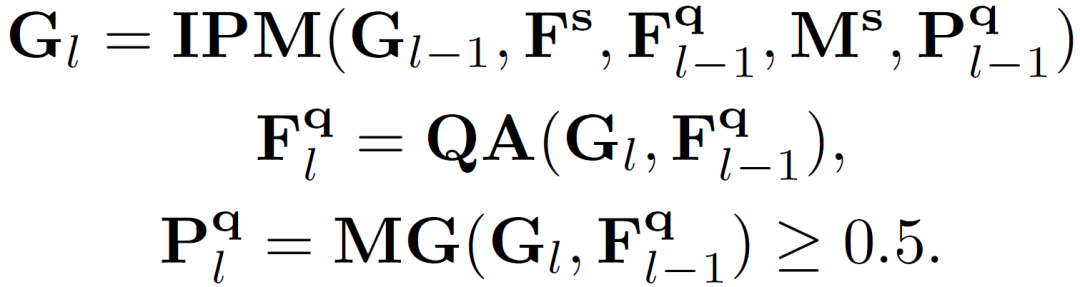
三、實(shí)驗(yàn)結(jié)果及可視化

圖3 作者提出方法的結(jié)果的可視化與比較
在圖3中,作者可視化了文章中方法和僅使用支持圖像的小樣本語(yǔ)義分割方法[1]的一些預(yù)測(cè)結(jié)果。可以看出,與第 2 行中僅使用支持信息的結(jié)果相比,第3行中的結(jié)果展現(xiàn)出作者的方法可以有效地緩解由固有的類(lèi)內(nèi)多樣性引起的分割錯(cuò)誤。
表4 與先前工作在PASCAL-5i[2]數(shù)據(jù)集上的效果比較
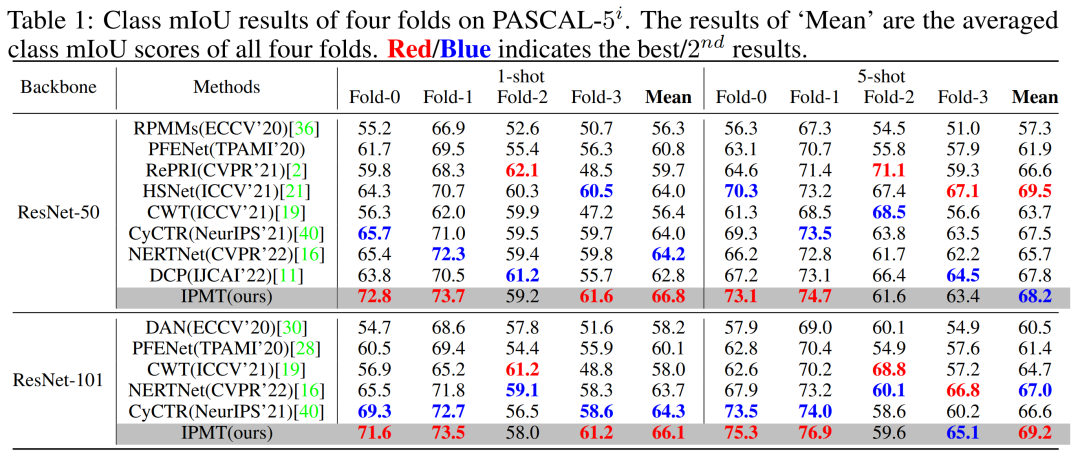
從表4中可以發(fā)現(xiàn),作者的方法大大超過(guò)了所有其他方法,并取得了新的最先進(jìn)的結(jié)果。在使用 ResNet-50 作為主干網(wǎng)絡(luò)時(shí), 在 1-shot 設(shè)置下與之前的最佳結(jié)果相比,作者將 mIoU 得分提高了 2.6。此外,在使用 ResNet-101作為主干網(wǎng)絡(luò)時(shí),作者方法實(shí)現(xiàn)了 1.8 mIoU(1-shot)和 2.2 mIoU(5-shot )的提升。
表5 各模塊消融實(shí)驗(yàn)
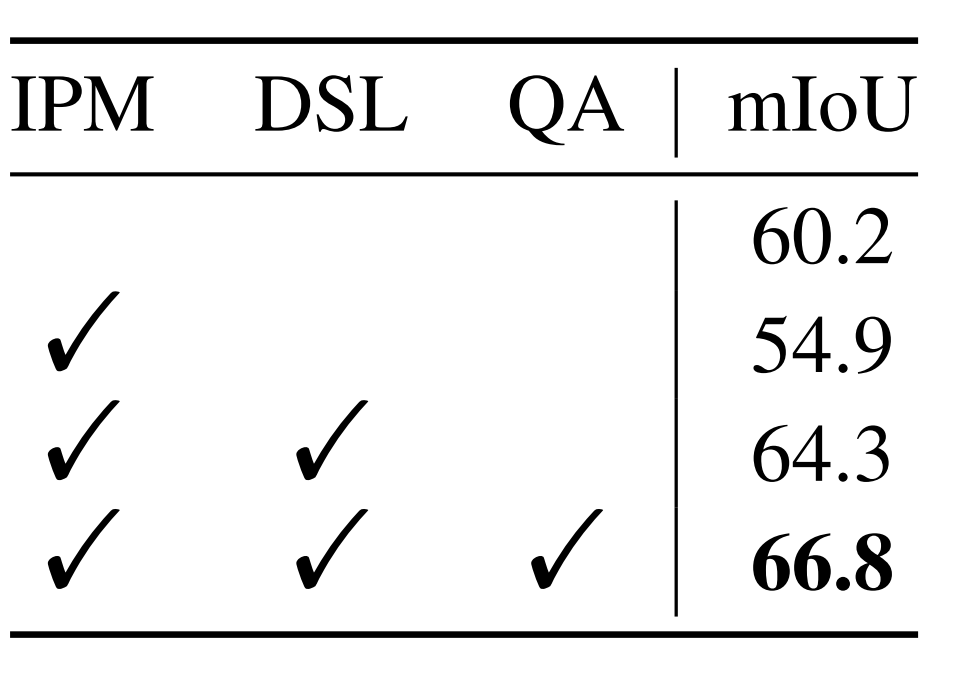
表5中指出,當(dāng)僅使用 IPM 會(huì)導(dǎo)致 5.3 mIoU 的性能下降。然而,當(dāng)添加 DSL 時(shí),模型的性能在baseline上實(shí)現(xiàn)了 4.1 mIoU 的提升。作者認(rèn)為這種現(xiàn)象是合理的,因?yàn)闊o(wú)法保證 IPM 中的可學(xué)習(xí)原型將在沒(méi)有 DSL 的情況下學(xué)習(xí)中間類(lèi)別知識(shí)。同時(shí),使用 QA 激活查詢(xún)特征圖可以進(jìn)一步將模型性能提高 2.5 mIoU。這些結(jié)果清楚地驗(yàn)證了作者提出的 QA 和 DSL 的有效性。
表6 中間原型Transformer有效性的消融研究
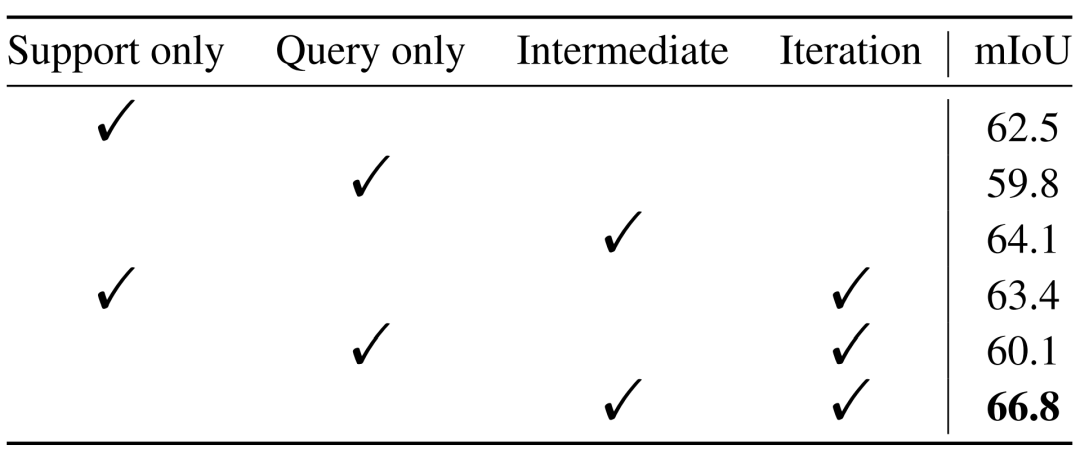
在表6中,作者對(duì)比了僅使用support或者query提供類(lèi)別信息時(shí),和是否使用迭代方式提取信息時(shí)的模型的性能情況。可以看出,借助中間原型以迭代的方式從support和query中都獲取類(lèi)型信息所取得的效果更為出色,也驗(yàn)證了作者提出方法的有效性。
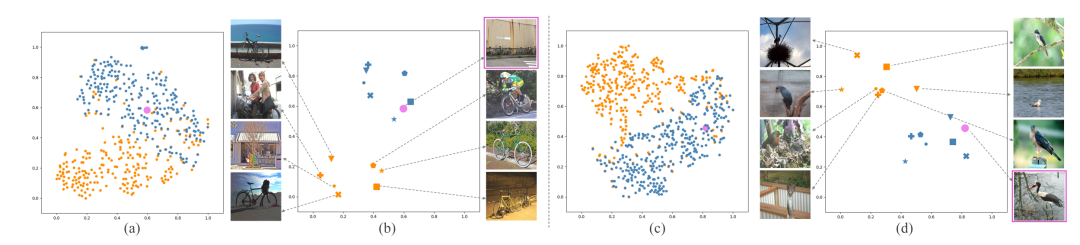
圖7 支持原型和中間原型分別的可視化比較
如圖7所示,作者將原本的支持原型可視化為橘色,學(xué)習(xí)到的中間原型可視化為藍(lán)色,查詢(xún)圖像原型可視化為粉色。可以看到,在特征空間中,中間原型比支持原型更接近查詢(xún)?cè)停虼蓑?yàn)證了作者的方法有效地緩解了類(lèi)內(nèi)多樣性問(wèn)題并彌補(bǔ)了查詢(xún)和支持圖像之間的類(lèi)別信息差距。
四、總結(jié)及結(jié)論
在文章中,作者關(guān)注到查詢(xún)和支持之間的類(lèi)內(nèi)多樣性,并引入中間原型來(lái)彌補(bǔ)它們之間的類(lèi)別信息差距。核心思想是通過(guò)設(shè)計(jì)的中間原型挖掘Transformer并采取迭代的方式使用中間原型來(lái)聚合來(lái)自于支持圖像的確定性類(lèi)型信息和查詢(xún)圖像的自適應(yīng)的類(lèi)別信息。令人驚訝的是,盡管它很簡(jiǎn)單,但作者的方法在兩個(gè)小樣本語(yǔ)義分割基準(zhǔn)數(shù)據(jù)集上大大優(yōu)于以前的最新結(jié)果。為此,作者希望這項(xiàng)工作能夠激發(fā)未來(lái)的研究能夠更多地關(guān)注小樣本語(yǔ)義分割的類(lèi)內(nèi)多樣性問(wèn)題。
審核編輯 :李倩
-
模塊
+關(guān)注
關(guān)注
7文章
2749瀏覽量
48091 -
圖像
+關(guān)注
關(guān)注
2文章
1091瀏覽量
40669 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1702瀏覽量
46225
原文標(biāo)題:?NeurIPS 2022 | IPMT:用于小樣本語(yǔ)義分割的中間原型挖掘Transformer
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
SparseViT:以非語(yǔ)義為中心、參數(shù)高效的稀疏化視覺(jué)Transformer

transformer專(zhuān)用ASIC芯片Sohu說(shuō)明

Transformer模型的具體應(yīng)用

手冊(cè)上新 |迅為RK3568開(kāi)發(fā)板NPU例程測(cè)試
語(yǔ)義分割25種損失函數(shù)綜述和展望






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論