

前言
繼醫學圖像處理系列之后,我們又回到了小樣本語義分割主題上,之前閱讀筆記的鏈接我也在文末整理了一下。
小樣本語義分割旨在學習只用幾個帶標簽的樣本來分割一個新的對象類,大多數現有方法都考慮了從與新類相同的域中采樣基類的設置(假設源域和目標域相似)。
然而,在許多應用中,為元學習收集足夠的訓練數據是不可行的。這篇論文也將小樣本語義分割擴展到了一項新任務,稱為跨域小樣本語義分割(CD-FSS),將具有足夠訓練標簽的域的元知識推廣到低資源域,建立了 CD-FSS 任務的新基準。
在開始介紹 CD-FSS 之前,我們先分別搞明白廣義上跨域和小樣本學習的概念(這個系列后面的文章就不仔細介紹了)。小樣本學習可以分為 Zero-shot Learning(即要識別訓練集中沒有出現過的類別樣本)和 One-Shot Learning/Few shot Learning(即在訓練集中,每一類都有一張或者幾張樣本)。幾個相關的重要概念:
域:一個域 D 由一個特征空間 X 和特征空間上的邊緣概率分布 P(X) 組成,其中 X=x1,x2,.....,xn,P(X) 代表 X 的分布。
任務:在給定一個域 D={X, P(X)} 之后,一個任務 T 由一個標簽空間 Y 以及一個條件概率分布 P(Y|X) 構成,其中,這個條件概率分布通常是從由特征—標簽對 ∈X,∈Y 組成的訓練數據(已知)中學習得到。父任務,如分類任務;子任務,如貓咪分類任務,狗狗分類任務。
Support set:支撐集,每次訓練的樣本集合。
Query set:查詢集,用于與訓練樣本比對的樣本,一般來說 Query set 就是一個樣本。
在 Support set 中,如果有 n 個種類,每個種類有 k 個樣本,那么這個訓練過程叫 n-way k-shot。如每個類別是有 5 個 examples 可供訓練,因為訓練中還要分 Support set 和 Query set,那么 5-shots 場景至少需要 5+1 個樣例,至少一個 Query example 去和 Support set 的樣例做距離(分類)判斷。
現階段絕大部分的小樣本學習都使用 meta-learning 的方法,即 learn to learn。將模型經過大量的訓練,每次訓練都遇到的是不同的任務,這個任務里存在以前的任務中沒有見到過的樣本。所以模型處理的問題是,每次都要學習一個新的任務,遇見新的 class。 經過大量的訓練,這個模型就理所當然的能夠很好的處理一個新的任務,這個新的任務就是小樣本啦。
meta-learning 共分為 Training 和 Testing 兩個階段。
Training 階段的思路流程如下:
將訓練集采樣成支撐集和查詢集。
基于支撐集生成一個分類模型。
利用模型對查詢集進行預測生成 predict labels。
通過查詢集 labels(即ground truth)和 predict labels 進行 loss 計算,從而對分類模型 C 中的參數 θ 進行優化。
Testing 階段的思路:
利用 Training 階段學來的分類模型 C 在 Novel class 的支撐集上進一步學習。
學到的模型對 Novel class 的查詢集進行預測(輸出)。
總的來說,meta-learning 核心點之一是如何通過少量樣本學習分類模型C。
再來解釋下為什么要研究跨域的小樣本學習,當目標任務與源任務中數據分布差距過大,在源域上訓練得到的模型無法很好的泛化到目標域上(尤其是基于元學習的方法,元學習假設源域和目標域相似),從而無法提升目標任務的效果,即在某一個域訓練好的分類模型在其他域上進行分類測試時,效果不理想。
如果能用某種方法使得源域和目標域的數據在同一分布,則源任務會為目標任務提供更加有效的先驗知識。至此,如何解決跨域時目標任務效果不理想的問題成了跨域的小樣本學習。
如下圖,跨域小樣本學習對應當源域和目標域在不同子任務(父任務相同)且不同域下時,利用通過源域獲得的先驗知識幫助目標任務提高其 performance,其中已有的知識叫做源域(source domain),要學習的新知識叫目標域(target domain)。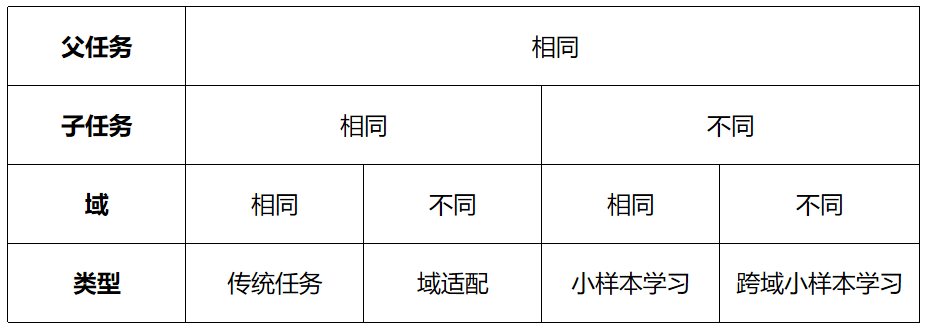
概述
在經過對跨域小樣本學習的詳細介紹后,我們再回到發表在 ECCV 2022 的 Cross-Domain Few-Shot Semantic Segmentation 這篇論文上。這篇文章為 CD-FSS 建立了一個新的基準,在提出的基準上評估了具有代表性的小樣本分割方法和基于遷移學習的方法,發現當前的小樣本分割方法無法解決 CD-FSS。
所以,提出了一個新的模型,被叫做 PATNet(Pyramid-Anchor-Transformation),通過將特定領域的特征轉化為下游分割模塊的領域無關的特征來解決 CD-FSS 問題,以快速適應新的任務。
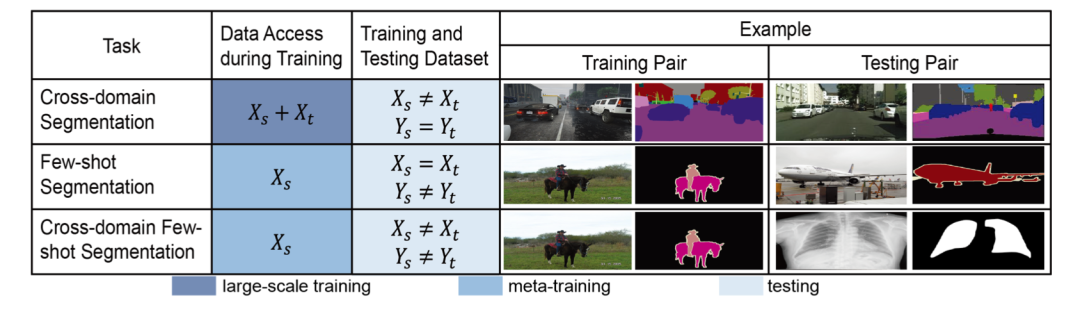
下圖是論文里給出的跨域的小樣本分割與現有任務的區別。 和 分別表示源域和目標域的數據分布。 代表源標簽空間, 代表目標標簽空間。
Proposed benchmark
提出的 CD-FSS 基準由四個數據集組成,其特征在于不同大小的域偏移。包括來自 FSS-1000 、Deepglobe、ISIC2018 和胸部 X-ray 數據集的圖像和標簽。
這些數據集分別涵蓋日常物體圖像、衛星圖像、皮膚損傷的皮膚鏡圖像和 X 射線圖像。所選數據集具有類別多樣性,并反映了小樣本語義分割任務的真實場景。如下圖:
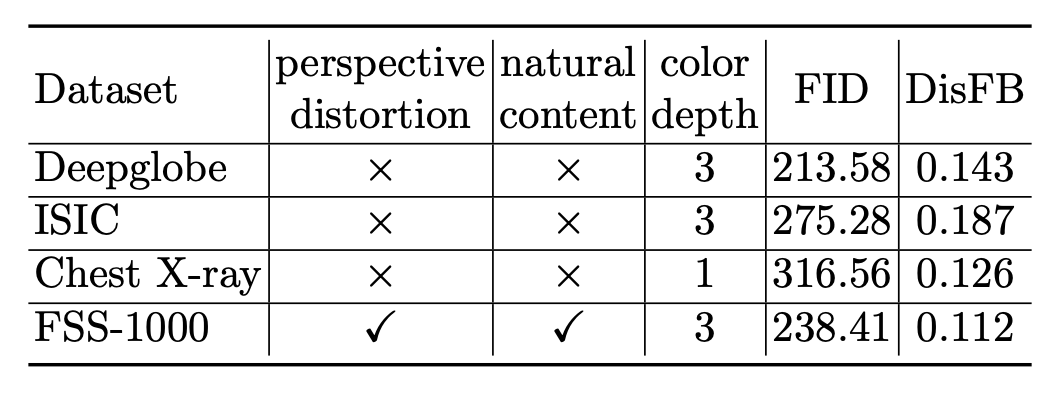
在下表中,每個域的任務難度從兩個方面進行衡量:1)域遷移(跨數據集)和 2)單個圖像中的類別區分(在數據集中)。 F?echet Inception Distance (FID) 用于測量這四個數據集相對于 PASCAL 的域偏移,于是單個圖像中的域偏移和類別區分分別由 FID 和 DisFB 測量。由于單個圖像中類別之間的區分對分割任務有重要影響,使用 KL 散度測量前景和背景類別之間的相似性。
整體機制 with CD-FSS
CD-FSS 的主要挑戰是如何減少領域轉移帶來的性能下降。以前的工作主要是學習 Support-Query 匹配模型,假設預訓練的編碼器足夠強大,可以將圖像嵌入到下游匹配模型的可區分特征中。
然而在大領域差距下,只在源域中預訓練的 backbone 在目標域中失敗了,如日常生活中的物體圖像到 X-ray 圖像。
為了解決這個問題,模型需要學會將特定領域的特征轉化為領域無關的特征。這樣一來,下游模型就可以通過匹配 Support-Query 的領域無關的特征來進行分割,從而很好地適應新領域。
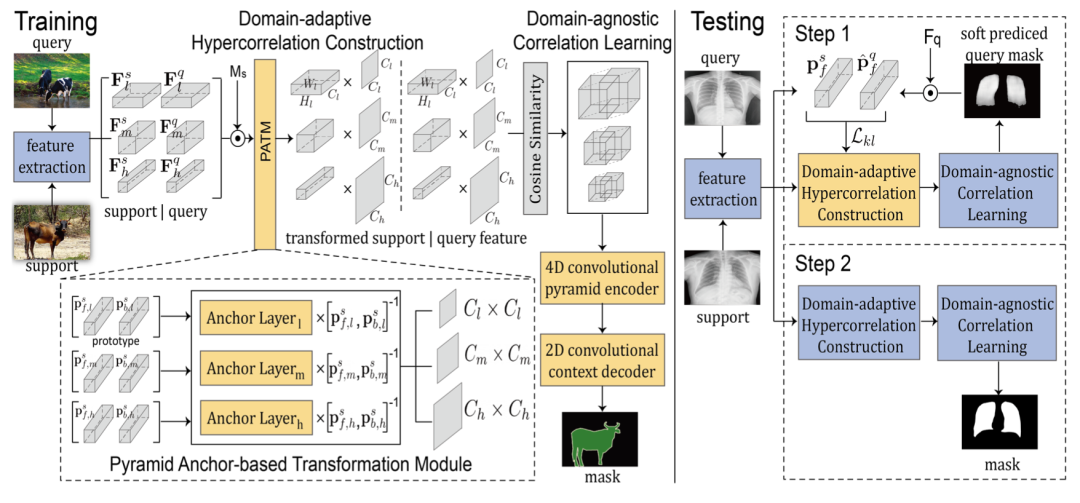
如下圖所示(左邊訓練,右邊測試),整體機制由三個主要部分組成,即特征提取 backbone、domain-adaptive hypercorrelation construction 和 domain-agnostic correlation learning。對于輸入的 Support-Query 圖像,首先用特征提取器提取所有的中間特征。然后,我們在 domain-adaptive hypercorrelation construction 部分引入一個特別新穎的模塊,稱為 Pyramid Anchor-based Transformation Module(PATM),將特定領域的特征轉換為領域無關的特征。
接下來,用所有轉換后的特征圖計算多層次的相關圖,并將其送入 domain-agnostic correlation learning 部分。使用兩個現成的模塊,分別為 4D 卷積金字塔編碼器和 2D 卷積上下文解碼器,被用來以粗到細的方式產生預測掩碼,并具有高效的 4D 卷積。
在測試階段,論文里還提出了一個任務自適應微調推理(TFI)策略,以鼓勵模型通過 Lkl 損失微調 PATM 來快速適應目標領域,Lkl 損失衡量 Support-Query 預測之間的前景原型相似度。
PATNet
上一部分提到 PATM 將特定領域的特征轉換為領域無關的特征,這一部分我們仔細看一下。Pyramid Anchor-based Transformation Module(PATM)的核心思想是學習 pyramid anchor layers,將特定領域的特征轉換為領域無關的特征。直觀地說,如果我們能找到一個轉化器,將特定領域的特征轉化為領域無關的度量空間,它將減少領域遷移帶來的不利影響。由于領域無關的度量空間是不變的,所以下游的分割模塊在這樣一個穩定的空間中進行預測會更容易。
理想情況下,屬于同一類別的特征在以同樣的方式進行轉換時將產生類似的結果。因此,如果將 Support 特征轉換為領域空間中的相應錨點,那么通過使用相同的轉換,也可以使屬于同一類別的 Query 特征轉換為接近領域空間中的錨點。采用線性變換矩陣作為變換映射器,因為它引入的可學習參數較少。
如上一部分中的圖,使用 anchor layers 和 Support 圖像的原型集來計算變換矩陣。如果 A 代表 anchor layers 的權重矩陣,P 表示 Support 圖像的原型矩陣。既通過尋找一個矩陣來構建轉換矩陣 W,使 WP=A。
任務自適應微調推理(TFI)策略
為了進一步提高 Query 圖像預測的準確率,提出了一個任務自適應微調推理(TFI,Task- adaptive Fine-tuning Inference)策略,以便在測試階段快速適應新的對象。
如果模型能夠為 Query 圖像預測一個好的分割結果,那么分割后的 Query 圖像的前景類原型應該與 Support 的原型相似。
與優化模型中的參數不同,我們只對 anchor layers 進行微調,以避免過擬合。上圖右側顯示了該策略的流程,在測試階段,在第 1 步(step 1)中,只有錨層使用提議的 Lkl 進行相應的更新,Lkl 衡量 Support 和 Query set 的前景類原型之間的相似性。在第 2 步(step 1)中,模型中的所有層都被凍結,并對 Query 圖像進行最終預測。通過這種方式,模型可以快速適應目標域,并利用經過微調的 anchor layers 產生的輔助校準特征對分割結果進行完善。
如下圖是幾個 1-shot 任務的可視化比較結果。對于每個任務,前三列顯示 Support 和 Query set 的金標準。接下來的兩列分別表示沒有PATM 和沒有 TFI 的分割結果,最后一列顯示了用 Lkl 微調后的最終分割結果。
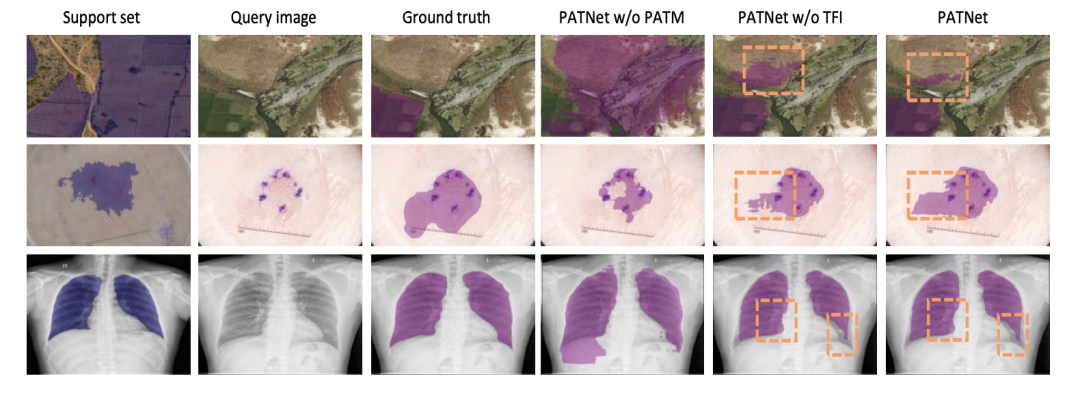
實驗和可視化
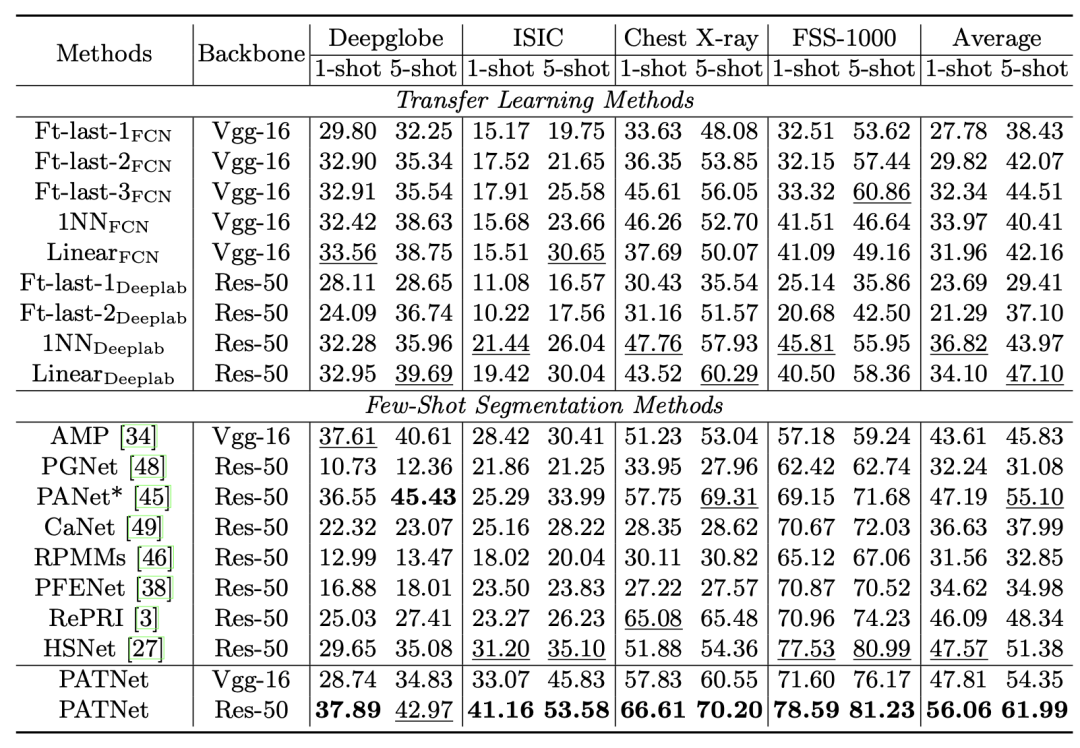
如下表所示,是元學習和遷移學習方法在 CD-FSS 基準上的 1-way 1-shot 和 5-shot 結果的平均 IoU。所有的方法都是在 PASCAL VOC 上訓練,在 CD-FSS 上測試。
下圖是模型在 CD-FSS 上進行 1-way 1-shot 分割的定性結果。其中,Support 圖像標簽是藍色。Query 圖像標簽和預測結果是另一種顏色。
總結
這篇論文也將小樣本語義分割擴展到了一項新任務,稱為跨域小樣本語義分割(CD-FSS)。建立了一個新的 CD-FSS benchmark 來評估不同域轉移下小樣本分割模型的跨域泛化能力。實驗表明,由于跨域特征分布的巨大差異,目前 SOTA 的小樣本分割模型不能很好地泛化到來自不同域的類別。所以,提出了一種新模型,被叫做 PATNet,通過將特定領域的特征轉換為與領域無關的特征,用于下游分割模塊以快速適應新的領域,從而也解決了 CD-FSS 問題。
審核編輯:劉清
-
圖像處理
+關注
關注
27文章
1320瀏覽量
57490 -
FSS
+關注
關注
0文章
13瀏覽量
9778
原文標題:ECCV 2022: 跨域小樣本語義分割新基準
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SparseViT:以非語義為中心、參數高效的稀疏化視覺Transformer

TSP研究:車內網聯服務向跨域融合、全場景融合、艙駕融合方向拓展
一文解析跨時鐘域傳輸
手冊上新 |迅為RK3568開發板NPU例程測試
語義分割25種損失函數綜述和展望







 工商網監
工商網監

評論