

OpenCore和Silicore的Wishbone規(guī)范,旨在提供標(biāo)準(zhǔn)的IP核互連方案,以滿足現(xiàn)代片上系統(tǒng)(SoC)設(shè)計(jì)的要求,包括CPU,DMA引擎,內(nèi)存接口,外設(shè)接口等。
andEuros公司自成立以來一直使用Wishbone規(guī)范,并開發(fā)了Wishbone總線的改進(jìn)版本,稱為Wishbone II,以提出一種先進(jìn)的流水線架構(gòu),其中讀寫事務(wù)是分開的,總線充當(dāng)事務(wù)總線。通過這種方式,可以同時進(jìn)行多個事務(wù),通過采用新的每單元鎖定概念,消除路徑上的所有延遲并停止 RMW 周期。當(dāng)然,最終的好處是最終總線吞吐量已增加到最大。
大規(guī)模FPGA/ASIC SoC設(shè)計(jì)的設(shè)計(jì)和開發(fā)迫使設(shè)計(jì)人員實(shí)現(xiàn)具有標(biāo)準(zhǔn)化模塊接口的模塊化架構(gòu),該接口以任何可能的配置連接各種IP模塊。OpenCores發(fā)布了最流行的互連架構(gòu)之一,稱為Wishbone B.3總線。以類似的方式,Altera引入了自己的互連方案,稱為Avalon Bus,SOPC Builder和Nios(II)系統(tǒng)就是圍繞該方案制造的。Xilinx 還推出了自己的總線,稱為片上外設(shè)總線與處理器本地總線 相結(jié)合。
這些互連架構(gòu)是面向單事務(wù)主/從的,這意味著只要沒有收到該字,從給定地址請求單詞的 CPU 就會停止自身和到目標(biāo)的路徑(總線)。以這種方式丟失了大量總線周期,盡管系統(tǒng)總線頻率相對較高,但實(shí)際數(shù)據(jù)吞吐量仍低于預(yù)期。即使特殊信號引入了快速突發(fā)讀取和寫入,總線周期仍然會丟失,直到接收到第一個字,代價是源和目標(biāo)兩端的突發(fā)邏輯加倍。當(dāng)訪問具有較大延遲的較慢模塊時,總線停滯更為明顯。在這些情況下,系統(tǒng)性能會顯著下降;例如,100 MHz 系統(tǒng)的吞吐量可能會下降到每秒幾 MB。
這就是為什么迫切需要開發(fā)采用新概念的總線架構(gòu)的原因。引入了一些新信號來支持基于 Wishbone B.3 架構(gòu)的新事務(wù)總線概念,克服了延遲問題,同時保持了向后兼容性。
叉骨II交易總線概念
在我們提議的總線中,交易由一個交易向量表示,其中包含:
源(模塊)地址
目標(biāo)(模塊)地址
算子
數(shù)據(jù)
源地址和目標(biāo)地址定義路徑;操作員描述要沿路徑和/或目標(biāo)地址執(zhí)行的一個或多個操作;某些操作需要提供補(bǔ)充數(shù)據(jù)才能完成交易。實(shí)際實(shí)現(xiàn)需要額外的握手信號。
事務(wù)向量被放置在事務(wù)總線上,將向量從源傳輸?shù)侥繕?biāo),并根據(jù)向量的請求執(zhí)行面向總線的操作。一旦事務(wù)向量被放置(發(fā)送),源就沒有進(jìn)一步的責(zé)任,事務(wù)總線將完全控制它。然后,源已準(zhǔn)備好發(fā)出下一個事務(wù)向量。可以事先發(fā)出多個任務(wù)或請求,每個總線周期一個,這減少了目標(biāo)模塊上任何預(yù)測邏輯的需求,以支持突發(fā)讀取或?qū)懭胱鳛楦鞣N突發(fā)讀取的預(yù)測邏輯。
有兩種類型的事務(wù):
獨(dú)立
依賴(當(dāng)它們的順序很重要時)
為了支持依賴事務(wù),事務(wù)總線絕不能更改已放置事務(wù)的順序。事務(wù)總線具有完全確認(rèn)的機(jī)制,用于接受新的事務(wù)向量、執(zhí)行內(nèi)部轉(zhuǎn)發(fā)并傳遞到目標(biāo)模塊。透明架構(gòu)將自身反映為一個簡單的輸入輸出黑匣子;但是,該實(shí)現(xiàn)基于多管道結(jié)構(gòu),其中每個 (FIFO) 行包含一個事務(wù)向量。
Wishbone II 事務(wù)總線僅提供四種基本操作:
單次讀取
單次寫入
細(xì)胞鎖
總線鎖
單次讀取和寫入由模塊發(fā)出,其中單元和總線鎖定操作位于事務(wù)總線域中。突發(fā)讀取和突發(fā)寫入是通過發(fā)出讀取或?qū)懭胧聞?wù)流來完成的。RMW周期通過總線得到支持,甚至更好的是,可以使用新的單元鎖定概念來促進(jìn)它們,該概念不會使整個SoC總線停滯,而是將單個或多個存儲單元鎖定到給定的所有者。只要未解鎖,其他人就無法訪問這些單元格。
叉骨II信號
Wishbone II 事務(wù)向量由 Wishbone B.3 規(guī)范組成,引入了以下新信號:
WB_ACW寫入確認(rèn)
WB_ACR閱讀致謝
WB_TGA雙向地址標(biāo)簽
WB_ALK地址鎖
在進(jìn)一步的文本中,前綴WB可以更改為WBM表示主接口,WBS表示從接口,也可以留空以描述任何主接口或從接口。輸入信號附加在末尾_I,輸出信號帶有_O。建議的總線丟棄了Wishbone B.3 ACK信號,因?yàn)樗墓δ墁F(xiàn)在在ACR和ACW信號之間分配。表1列出了主機(jī)和從站的完整基本信號說明。新信號以粗體標(biāo)記。
叉骨二期巴士交易
寫入事務(wù)
寫入事務(wù)幾乎與 Wishbone B.3 規(guī)范中給出的寫入事務(wù)相同,除了 Wishbone II 使用 ACW 信號來確認(rèn)寫入周期。讀寫事務(wù)由與寫入事務(wù)相同的讀取請求組成,只是設(shè)置了目標(biāo)操作信號 WE。
讀取事務(wù)
讀取事務(wù)由兩個事務(wù)組成:
源發(fā)出的讀取請求事務(wù)
目標(biāo)發(fā)出的讀取響應(yīng)事務(wù)
讀取請求由表示源的主模塊發(fā)送,方法是首先發(fā)出一個寫入事務(wù),并將目標(biāo)操作 WE 設(shè)置為讀取。主機(jī)應(yīng)設(shè)置地址標(biāo)記寫入向量以識別讀取響應(yīng)。(如果只有一個主控形狀,則不需要這樣做。讀取請求事務(wù)的確認(rèn)方式與寫入事務(wù)相同。
目標(biāo)通過返回由確認(rèn)信號 ACR 標(biāo)記的單獨(dú)讀取響應(yīng)事務(wù)并提供有效數(shù)據(jù)和地址標(biāo)記讀取信息來完成事務(wù)。地址標(biāo)記讀取是地址標(biāo)記寫入的副本。
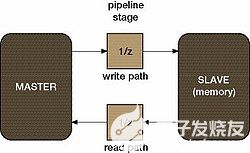
圖1顯示了一個示例系統(tǒng),在源(主)和目標(biāo)(從)設(shè)備之間的寫入(輸入)和讀取(輸出)路徑上有一個流水線級。該系統(tǒng)在兩個方向上都有 1 個循環(huán)方向;因此,請求-響應(yīng)循環(huán)至少需要 2 個等待周期。從屬(內(nèi)存)還可以執(zhí)行一些內(nèi)部管理,如刷新,這增加了等待狀態(tài)的總數(shù)。
圖1
您可以看到,圖 2 描述了給定示例的事務(wù)總線數(shù)據(jù)流圖,其中主站放置的三個讀取請求事務(wù)為 AD0、AD1 和 AD2,以及關(guān)聯(lián)的返回讀取響應(yīng)事務(wù)為 DO0、DO1 和 DO2。假設(shè)所有三個事務(wù)的信號 WE 都被清除,以指示讀取操作。事務(wù) AD0 和 AD1 是突發(fā)事務(wù),這意味著 AD1 = AD0 + 1,而 AD2 是同時觸發(fā)的獨(dú)立事務(wù),可能是加載其中斷向量的外部中斷的原因,依此類推。
圖2
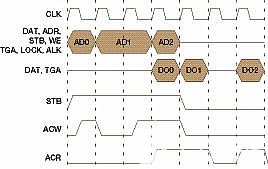
每個讀取請求事務(wù)由 ACW 信號確認(rèn),返回的讀取響應(yīng)事務(wù)由 ACR 信號標(biāo)記(確認(rèn))。請注意,由于其他更高優(yōu)先級的主節(jié)點(diǎn)或內(nèi)存刷新函數(shù)等原因,延遲順序可能不同。在前面的示例中,AD0 會立即得到確認(rèn),但需要 3 個等待周期才能返回 DO0;AD1 在 1 個周期后得到確認(rèn),而 DO1 僅在 2 個等待周期內(nèi)返回,DO2 再次需要 3 個等待周期。所有三筆交易都在 9 個周期內(nèi)完成;理論上,如果不添加兩個說明性等待周期,它們只會在 7 個周期內(nèi)完成。使用 Wishbone B.3 規(guī)范時,圖 3 顯示了相同的場景。
圖3
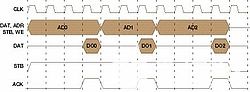
AD0和AD1再次為突發(fā),AD1 = AD0 + 1,AD2為獨(dú)立請求。所有三個事務(wù)都在 12 個周期內(nèi)完成,性能降低了 41%(在 Wishbone II 中至少 7 個周期),即使額外的硅成本,這是源和目標(biāo)兩端的內(nèi)存突發(fā)邏輯實(shí)現(xiàn)。
想象一下,當(dāng)系統(tǒng)中共存多個主站以發(fā)出第一個單詞時,連續(xù)突發(fā) Wishbone II 將在從屬端執(zhí)行 0 個等待周期(完全消除延遲)并且絕對沒有損失(再次是 0 個等待周期)。對于以 150 MHz 運(yùn)行的系統(tǒng)來說,更能說明問題,固定延遲為 2 個周期的長突發(fā)將產(chǎn)生 150 M 字的 Wishbone II 帶寬,而 Wishbone B.3 僅產(chǎn)生 50 Mwords 的帶寬。
讀寫周期和專用總線/地址鎖定
可以使用總線 LOCK 信號進(jìn)行讀-修改-寫循環(huán),方法是發(fā)出讀取請求和 LOCK 信號集,等待讀取響應(yīng),然后進(jìn)行寫入,最后釋放 LOCK。為了不使整個總線失速,Wishbone II 引入了使用 ALK 信號的每單元內(nèi)存鎖定功能,該功能的使用方式與 Wishbone LOCK 信號幾乎相同,只是它不會停止整個總線,而是授予對由源 TGA 區(qū)分的給定模塊的獨(dú)占權(quán)限。
叉骨II駛向未來
Wishbone II 總線為 FPGA 和 ASIC 的 SoC 設(shè)計(jì)提出了一種面向事務(wù)總線的高級架構(gòu),其中架構(gòu)寫入和讀取操作作為單獨(dú)的寫入和讀取事務(wù)處理。每個事務(wù)都存儲在一行中,多管道架構(gòu)充當(dāng) FIFO 緩沖區(qū),從多個源模塊和目標(biāo)模塊傳輸多個事務(wù)。先進(jìn)的鎖定機(jī)制使用臨時的每單元鎖定機(jī)制,防止整個總線因 RMW 周期而失速。通過這種方式,整體設(shè)計(jì)數(shù)據(jù)吞吐量提高到最大,同時設(shè)計(jì)成功集成了慢速和高速、低延遲和高延遲外設(shè)和 CPU。
審核編輯:郭婷
-
接口
+關(guān)注
關(guān)注
33文章
8884瀏覽量
152948 -
soc
+關(guān)注
關(guān)注
38文章
4300瀏覽量
220992 -
總線
+關(guān)注
關(guān)注
10文章
2935瀏覽量
89134
發(fā)布評論請先 登錄
相關(guān)推薦
請問canmv-k230支持雙核嗎?如何調(diào)用另一個核心工作?
I2C總線數(shù)據(jù)傳輸速度要求
EE-82:使用ADSP-2181 DSP的IO空間對另一個ADSP-2181進(jìn)行IDMA引導(dǎo)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論