 一文詳解8b/10b編碼
一文詳解8b/10b編碼
1. 什么是8b/10b編碼?
8b/10b最常見的是應用于光纖通訊和LVDS信號的。由于光模塊光模塊只能發送亮或者不亮,也就是0或者1這兩種狀態這種單極性碼,那么這會存在一個問題,如果傳輸中出現較長的連0或者連1(例如111111100000000),那么接收端將沒有辦法正確的采樣識別信號,另外還會由于單極性碼含有直流分量,這種直流成分會隨數據中1和0的隨機變化也呈現隨機性,這會引起接收端的基線漂移導致接收端誤判。LVDS信號一樣會存在這個問題,隨著線路上的信號頻率越來越高,如果線路上的0和1數量不均衡(直流不平衡)那么線路上的基電壓會出現偏移,一樣會導致解碼錯誤。
總之一句話,8b/10b是為了解決直流平衡而推出的。
8B/10B編碼是加擾二進制碼的一種,在此之前這種技術已得到應用,只是沒有像8B10B那么普遍。目前采用8b/10b編碼的串行高速接口總線有IEEE 1394b、SATA、PCI Express、Infini-band、Fiber Channel、RapidIO、USB3.0、MIPI M-phy 等。
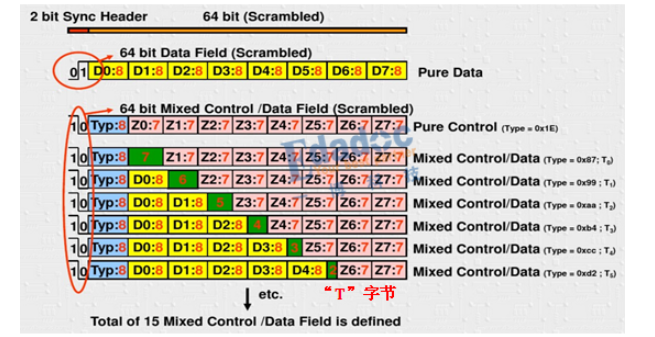
將8bit編碼成10bit后,連續的1或者0不能超過5位,所以10b中0和1的位數只可能出現3中情況:
? 有5個0和5個1
? 有6個0和4個1
? 有4個0和6個1
**不均等性:**這樣引出了一個新術語“不均等性”(Disparity),就是1的位數和0的位數的差值,根據上面3種情況就有對應的3個Disparity0、-2、+2。
2. 為什么引入8b/10b編碼?
首先,為什么要編碼?原來的碼型有什么不好的地方嗎?其中最主要的原因用下面這個圖來進行解釋:
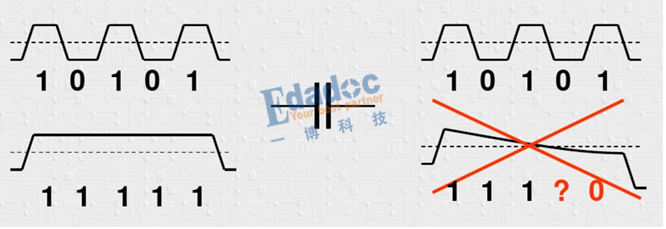
大家看明白了吧,由于我們的串行鏈路中會有交流耦合電容,我們知道理想電容的阻抗公式是Zc=1/2πf*C,因此信號頻率越高,阻抗越低,反之頻率越低,阻抗越高。因此上面的情況,當碼型是高頻的時候,基本上可以不損耗的傳輸過去,但是當碼型為連續“0”或者“1”的情況時,電容的損耗就很大,導致幅度不斷降低,帶來的嚴重后果是無法識別到底是“1”還是“0”。因此編碼就是為了盡量把低頻的碼型優化成較高頻的碼型,從而保證低損耗的傳輸過去。
3. 8b/10b的編碼算法
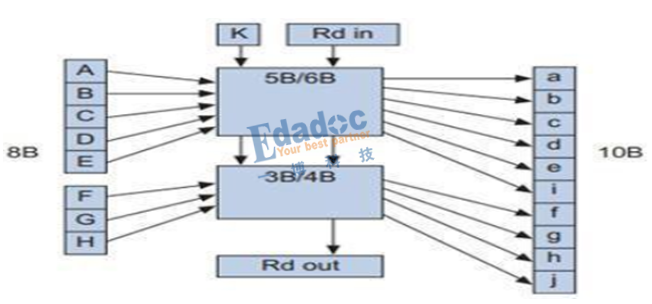
如上圖,關于8B/10B編碼算法有下面幾點需要理解:
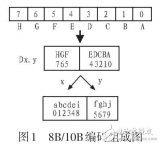
1, 低5位(ABCDE)中間加一位,進行5B/6B編碼,高三位(FGH)中間加一位,進行3B/4B編碼;
2, 編碼后的bit僅會出現這三種情況:5個“0”與5個“1”、4個“0”與6個“1”、6個“0”與4個“1”;
3, 有兩個術語要知道:不均等性(disparity)和極性偏差(running disparity,RD)。
不均等性是指編碼后的碼型數據是“1”多還是“0”多,如果是“1”多,則極性偏差RD為RD-,如果是“0”多則為RD+。
那定義+/-RD有什么意義呢?+/-RD代表著同一個碼型的兩種編碼方式。我們本身就是編碼的目標就是為了緩解長“0”或長“1”的影響,因此在編碼后如果“1”多的話,我們下一次的編碼就要把這種碼型做一個修正,因此從-RD碼型變成+RD碼型。如果是“0”和“1”一樣多,極性則不用變,如下圖:

4, 我們怎么知道編碼后映射成什么碼型呢?因此會有一個專門的編碼表,我們只需要在上面找到我們的原始碼型,然后就一目了然了。編碼表如下所示(部分截圖):
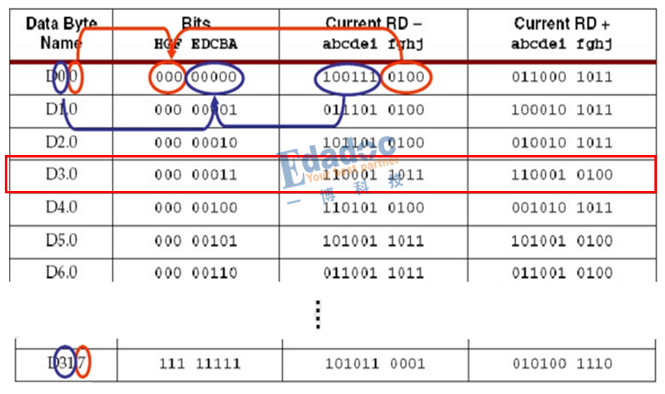
說了那么多,還不如舉個例子更直觀。
我們以上面的D3.0碼型進行仿真驗證:
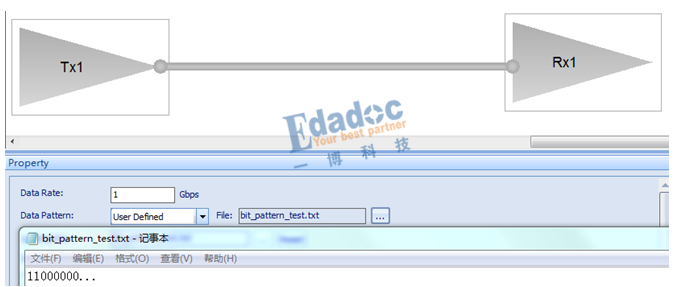
原始的碼型如下:
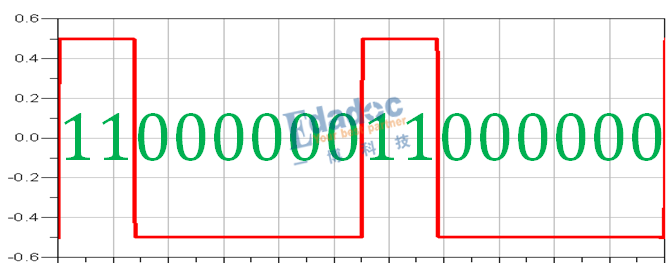
仿真得到8B/10B編碼后的碼型如下:

對照上面的編碼表,結果完全相同,從RD-的模型出發,編碼后RD-的碼型“1”比較多,因此極性變成RD+的編碼碼型,接著RD+的編碼碼型“0”比較多,極性又變回RD-,因此碼型就是RD-和RD+之間循環下去。
-
lvds
+關注
關注
2文章
1043瀏覽量
65821 -
編碼
+關注
關注
6文章
944瀏覽量
54840
原文標題:8b/10b編碼
文章出處:【微信號:硬件測試雜談,微信公眾號:硬件測試雜談】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
USB3.0與USB2.0編碼方式的區別
8b10b編碼verilog實現
Aurora 8b/10b IP核問題
收發器向導中啟用8b/10b編碼器的方法是什么?
如何使用Aurora 8B / 10B建立僅傳輸?
怎么禁用Aurora IP Core 8B / 10B中的時鐘補償功能?
基于FPGA的8B/10B編解碼設計
基于PRBS的8B/10B編碼器誤碼率為0設計
基于Virtex-6 的Aurora 8B/10B,PCIe2.0,SRIO 2.0三種串行通信協議分析
淺談高速信號的64B/66B編碼方式
高速串行通信常用的編碼方式-8b/10b編碼/解碼解析





 工商網監
工商網監
評論