 有趣!史記:數據壓縮算法列傳
有趣!史記:數據壓縮算法列傳
電腦里的數據壓縮其實類似于美眉們的瘦身運動,不外有兩大功用。
第一,可以節省空間。拿瘦身美眉來說,要是八個美眉可以擠進一輛出租車里,那該有多省錢啊!
第二,可以減少對帶寬的占用。例如,我們都想在不到 100Kbps 的 GPRS 網上觀看 DVD 大片,這就好比瘦身美眉們總希望用一尺布裁出七件吊帶衫,前者有待于數據壓縮技術的突破性進展,后者則取決于美眉們的恒心和毅力。
簡單地說,如果沒有數據壓縮技術,我們就沒法用 WinRAR 為 Email 中的附件瘦身;如果沒有數據壓縮技術,市場上的數碼錄音筆就只能記錄不到20 分鐘的語音;如果沒有數據壓縮技術,從 Internet上下載一部電影也許要花半年的時間……可是這一切究竟是如何實現的呢?數據壓縮技術又是怎樣從無到有發展起來的呢?
概率奇緣
一千多年前的中國學者就知道用“班馬”這樣的縮略語來指代班固和司馬遷,這種崇尚簡約的風俗一直延續到了今天的 Internet 時代:當我們在 BBS上用“ 7456 ”代表“氣死我了”,或是用“ B4 ”代表“ Before ”的時候,我們至少應該知道,這其實就是一種最簡單的數據壓縮呀。
嚴格意義上的數據壓縮起源于人們對概率的認識。當我們對文字信息進行編碼時,如果為出現概率較高的字母賦予較短的編碼,為出現概率較低的字母賦予較長的編碼,總的編碼長度就能縮短不少。遠在計算機出現之前,著名的 Morse電碼就已經成功地實踐了這一準則。在 Morse碼表中,每個字母都對應于一個唯一的點劃組合,出現概率最高的字母 e 被編碼為一個點“ 。 ”,而出現概率較低的字母 z 則被編碼為“ --”。顯然,這可以有效縮短最終的電碼長度。
信息論之父 C. E.Shannon第一次用數學語言闡明了概率與信息冗余度的關系。在 1948 年發表的論文“通信的數學理論( A Mathematical Theory of Communication )”中, Shannon 指出,任何信息都存在冗余,冗余大小與信息中每個符號(數字、字母或單詞)的出現概率或者說不確定性有關。Shannon 借鑒了熱力學的概念,把信息中排除了冗余后的平均信息量稱為“信息熵”,并給出了計算信息熵的數學表達式。這篇偉大的論文后來被譽為信息論的開山之作,信息熵也奠定了所有數據壓縮算法的理論基礎。從本質上講,數據壓縮的目的就是要消除信息中的冗余,而信息熵及相關的定理恰恰用數學手段精確地描述了信息冗余的程度。利用信息熵公式,人們可以計算出信息編碼的極限,即在一定的概率模型下,無損壓縮的編碼長度不可能小于信息熵公式給出的結果。
有了完備的理論,接下來的事就是要想辦法實現具體的算法,并盡量使算法的輸出接近信息熵的極限了。當然,大多數工程技術人員都知道,要將一種理論從數學公式發展成實用技術,就像僅憑一個 E=mc 2 的公式就要去制造核武器一樣,并不是一件很容易的事。
數學游戲
設計具體的壓縮算法的過程通常更像是一場數學游戲。開發者首先要尋找一種能盡量精確地統計或估計信息中符號出現概率的方法,然后還要設計一套用最短的代碼描述每個符號的編碼規則。統計學知識對于前一項工作相當有效,迄今為止,人們已經陸續實現了靜態模型、半靜態模型、自適應模型、 Markov模型、部分匹配預測模型等概率統計模型。相對而言,編碼方法的發展歷程更為曲折一些。
1948年,Shannon在提出信息熵理論的同時,也給出了一種簡單的編碼方法―― Shannon 編碼。1952 年, R. M. Fano 又進一步提出了 Fano編碼。這些早期的編碼方法揭示了變長編碼的基本規律,也確實可以取得一定的壓縮效果,但離真正實用的壓縮算法還相去甚遠。
第一個實用的編碼方法是由D. A. Huffman 在 1952 年的論文“最小冗余度代碼的構造方法( A Method for the Construction of Minimum Redundancy Codes )”中提出的。直到今天,許多《數據結構》教材在討論二叉樹時仍要提及這種被后人稱為 Huffman 編碼的方法。Huffman 編碼在計算機界是如此著名,以至于連編碼的發明過程本身也成了人們津津樂道的話題。據說, 1952 年時,年輕的 Huffman 還是麻省理工學院的一名學生,他為了向老師證明自己可以不參加某門功課的期末考試,才設計了這個看似簡單,但卻影響深遠的編碼方法。
Huffman編碼效率高,運算速度快,實現方式靈活,從 20 世紀 60 年代至今,在數據壓縮領域得到了廣泛的應用。例如,早期 UNIX 系統上一個不太為現代人熟知的壓縮程序 COMPACT 實際就是 Huffman 0 階自適應編碼的具體實現。20 世紀 80 年代初,Huffman 編碼又出現在 CP/M 和 DOS 系統中,其代表程序叫 SQ 。今天,在許多知名的壓縮工具和壓縮算法(如 WinRAR、 gzip 和 JPEG )里,都有 Huffman編碼的身影。不過, Huffman 編碼所得的編碼長度只是對信息熵計算結果的一種近似,還無法真正逼近信息熵的極限。正因為如此,現代壓縮技術通常只將 Huffman 視作最終的編碼手段,而非數據壓縮算法的全部。
科學家們一直沒有放棄向信息熵極限挑戰的理想。1968 年前后, P. Elias發展了 Shannon 和 Fano 的編碼方法,構造出從數學角度看來更為完美的 Shannon-Fano-Elias編碼。沿著這一編碼方法的思路, 1976 年, J. Rissanen 提出了一種可以成功地逼近信息熵極限的編碼方法――算術編碼。1982年, Rissanen 和 G. G. Langdon 一起改進了算術編碼。之后,人們又將算術編碼與 J. G. Cleary 和 I. H.Witten 于1984 年提出的部分匹配預測模型( PPM )相結合,開發出了壓縮效果近乎完美的算法。今天,那些名為 PPMC 、 PPMD 或PPMZ 并號稱壓縮效果天下第一的通用壓縮算法,實際上全都是這一思路的具體實現。
對于無損壓縮而言, PPM模型與算術編碼相結合,已經可以最大程度地逼近信息熵的極限。看起來,壓縮技術的發展可以到此為止了。不幸的是,事情往往不像想象中的那樣簡單:算術編碼雖然可以獲得最短的編碼長度,但其本身的復雜性也使得算術編碼的任何具體實現在運行時都慢如蝸牛。即使在摩爾定律大行其道, CPU速度日新月異的今天,算術編碼程序的運行速度也很難滿足日常應用的需求。沒辦法,如果不是后文將要提到的那兩個猶太人,我們還不知要到什么時候才能用上 WinZIP 這樣方便實用的壓縮工具呢。
異族傳說
逆向思維永遠是科學和技術領域里出奇制勝的法寶。就在大多數人絞盡腦汁想改進 Huffman 或算術編碼,以獲得一種兼顧了運行速度和壓縮效果的“完美”編碼的時候,兩個聰明的猶太人 J. Ziv 和 A. Lempel 獨辟蹊徑,完全脫離Huffman 及算術編碼的設計思路,創造出了一系列比 Huffman編碼更有效,比算術編碼更快捷的壓縮算法。我們通常用這兩個猶太人姓氏的縮寫,將這些算法統稱為 LZ 系列算法。
按照時間順序,LZ 系列算法的發展歷程大致是:Ziv 和 Lempel 于 1977 年發表題為“順序數據壓縮的一個通用算法( A Universal Algorithm for Sequential Data Compression )”的論文,論文中描述的算法被后人稱為 LZ77 算法。
1978 年,二人又發表了該論文的續篇“通過可變比率編碼的獨立序列的壓縮( Compression of Individual Sequences via Variable Rate Coding )”,描述了后來被命名為 LZ78 的壓縮算法。1984 年, T. A. Welch 發表了名為“高性能數據壓縮技術( A Technique for High Performance Data Compression )”的論文,描述了他在 Sperry 研究中心(該研究中心后來并入了 Unisys 公司)的研究成果,這是 LZ78 算法的一個變種,也就是后來非常有名的 LZW 算法。1990 年后, T. C. Bell 等人又陸續提出了許多 LZ 系列算法的變體或改進版本。
說實話, LZ 系列算法的思路并不新鮮,其中既沒有高深的理論背景,也沒有復雜的數學公式,它們只是簡單地延續了千百年來人們對字典的追崇和喜好,并用一種極為巧妙的方式將字典技術應用于通用數據壓縮領域。通俗地說,當你用字典中的頁碼和行號代替文章中每個單詞的時候,你實際上已經掌握了 LZ系列算法的真諦。這種基于字典模型的思路在表面上雖然和 Shannon 、 Huffman 等人開創的統計學方法大相徑庭,但在效果上一樣可以逼近信息熵的極限。而且,可以從理論上證明, LZ系列算法在本質上仍然符合信息熵的基本規律。
LZ系列算法的優越性很快就在數據壓縮領域里體現了出來,使用 LZ 系列算法的工具軟件數量呈爆炸式增長。UNIX 系統上最先出現了使用 LZW算法的 compress程序,該程序很快成為了 UNIX 世界的壓縮標準。緊隨其后的是 MS-DOS 環境下的 ARC 程序,以及PKWare 、 PKARC 等仿制品。20 世紀 80 年代,著名的壓縮工具 LHarc 和 ARJ 則是 LZ77 算法的杰出代表。
今天, LZ77 、 LZ78 、 LZW 算法以及它們的各種變體幾乎壟斷了整個通用數據壓縮領域,我們熟悉的 PKZIP 、WinZIP 、 WinRAR 、 gzip 等壓縮工具以及 ZIP 、 GIF 、 PNG等文件格式都是 LZ 系列算法的受益者,甚至連 PGP 這樣的加密文件格式也選擇了 LZ 系列算法作為其數據壓縮的標準。
沒有誰能否認兩位猶太人對數據壓縮技術的貢獻。我想強調的只是,在工程技術領域,片面追求理論上的完美往往只會事倍功半,如果大家能像 Ziv 和 Lempel 那樣,經常換個角度來思考問題,沒準兒你我就能發明一種新的算法,就能在技術方展史上揚名立萬呢。
音畫時尚
LZ系列算法基本解決了通用數據壓縮中兼顧速度與壓縮效果的難題。但是,數據壓縮領域里還有另一片更為廣闊的天地等待著我們去探索。Shannon的信息論告訴我們,對信息的先驗知識越多,我們就可以把信息壓縮得越小。換句話說,如果壓縮算法的設計目標不是任意的數據源,而是基本屬性已知的特種數據,壓縮的效果就會進一步提高。這提醒我們,在發展通用壓縮算法之余,還必須認真研究針對各種特殊數據的專用壓縮算法。比方說,在今天的數碼生活中,遍布于數碼相機、數碼錄音筆、數碼隨身聽、數碼攝像機等各種數字設備中的圖像、音頻、視頻信息,就必須經過有效的壓縮才能在硬盤上存儲或是通過 USB電纜傳輸。實際上,多媒體信息的壓縮一直是數據壓縮領域里的重要課題,其中的每一個分支都有可能主導未來的某個技術潮流,并為數碼產品、通信設備和應用軟件開發商帶來無限的商機。
讓我們先從圖像數據的壓縮講起。通常所說的圖像可以被分為二值圖像、灰度圖像、彩色圖像等不同的類型。每一類圖像的壓縮方法也不盡相同。
傳真技術的發明和廣泛使用促進了二值圖像壓縮算法的飛速發展。CCITT (國際電報電話咨詢委員會,是國際電信聯盟 ITU下屬的一個機構)針對傳真類應用建立了一系列圖像壓縮標準,專用于壓縮和傳遞二值圖像。這些標準大致包括 20 世紀 70 年代后期的 CCITT Group 1 和 Group 2 , 1980 年的 CCITT Group 3 ,以及 1984 年的 CCITT Group 4 。
為 了適應不同類型的傳真圖像,這些標準所用的編碼方法包括了一維的 MH 編碼和二維的 MR 編碼,其中使用了行程編碼( RLE )和 Huffman 編碼等技術。今天,我們在辦公室或家里收發傳真時,使用的大多是 CCITT Group 3 壓縮標準,一些基于數字網絡的傳真設備和存放二值圖像的 TIFF 文件則使用了 CCITT Group 4 壓縮標準。1993 年, CCITT 和 ISO(國際標準化組織)共同成立的二值圖像聯合專家組( Joint Bi-level Image Experts Group , JBIG )又將二值圖像的壓縮進一步發展為更加通用的 JBIG 標準。
實際上,對于二值圖像和非連續的灰度、彩色圖像而言,包括 LZ 系列算法在內的許多通用壓縮算法都能獲得很好的壓縮效果。例如,誕生于 1987 年的GIF 圖像文件格式使用的是 LZW 壓縮算法, 1995 年出現的 PNG 格式比 GIF 格式更加完善,它選擇了 LZ77 算法的變體zlib 來壓縮圖像數據。此外,利用前面提到過的 Huffman 編碼、算術編碼以及 PPM模型,人們事實上已經構造出了許多行之有效的圖像壓縮算法。
但是,對于生活中更加常見的,像素值在空間上連續變化的灰度或彩色圖像(比如數碼照片),通用壓縮算法的優勢就不那么明顯了。幸運的是,科學家們發現,如果在壓縮這一類圖像數據時允許改變一些不太重要的像素值,或者說允許損失一些精度(在壓縮通用數據時,我們絕不會容忍任何精度上的損失,但在壓縮和顯示一幅數碼照片時,如果一片樹林里某些樹葉的顏色稍微變深了一些,看照片的人通常是察覺不到的),我們就有可能在壓縮效果上獲得突破性的進展。這一思想在數據壓縮領域具有革命性的地位:通過在用戶的忍耐范圍內損失一些精度,我們可以把圖像(也包括音頻和視頻)壓縮到原大小的十分之一、百分之一甚至千分之一,這遠遠超出了通用壓縮算法的能力極限。也許,這和生活中常說的“退一步海闊天空”的道理有異曲同工之妙吧。
這種允許精度損失的壓縮也被稱為有損壓縮。在圖像壓縮領域,著名的JPEG標準是有損壓縮算法中的經典。JPEG 標準由靜態圖像聯合專家組( Joint Photographic Experts Group ,JPEG )于 1986 年開始制定, 1994 年后成為國際標準。JPEG以離散余弦變換( DCT )為核心算法,通過調整質量系數控制圖像的精度和大小。對于照片等連續變化的灰度或彩色圖像, JPEG在保證圖像質量的前提下,一般可以將圖像壓縮到原大小的十分之一到二十分之一。如果不考慮圖像質量, JPEG甚至可以將圖像壓縮到“無限小”。
JPEG標準的最新進展是 1996 年開始制定, 2001 年正式成為國際標準的 JPEG 2000。與 JPEG 相比, JPEG 2000 作了大幅改進,其中最重要的是用離散小波變換( DWT )替代了 JPEG 標準中的離散余弦變換。在文件大小相同的情況下, JPEG 2000壓縮的圖像比 JPEG 質量更高,精度損失更小。作為一個新標準, JPEG 2000暫時還沒有得到廣泛的應用,不過包括數碼相機制造商在內的許多企業都對其應用前景表示樂觀, JPEG 2000在圖像壓縮領域里大顯身手的那一天應該不會特別遙遠。
JPEG標準中通過損失精度來換取壓縮效果的設計思想直接影響了視頻數據的壓縮技術。CCITT 于 1988 年制定了電視電話和會議電視的 H.261 建議草案。H.261的基本思路是使用類似 JPEG 標準的算法壓縮視頻流中的每一幀圖像,同時采用運動補償的幀間預測來消除視頻流在時間維度上的冗余信息。在此基礎上, 1993 年, ISO通過了動態圖像專家組( Moving Picture Experts Group , MPEG )提出的 MPEG-1標準。MPEG-1 可以對普通質量的視頻數據進行有效編碼。我們現在看到的大多數 VCD 影碟,就是使用 MPEG-1 標準來壓縮視頻數據的。
為了支持更清晰的視頻圖像,特別是支持數字電視等高端應用,ISO 于 1994 年提出了新的 MPEG-2 標準(相當于 CCITT 的 H.262 標準)。MPEG-2 對圖像質量作了分級處理,可以適應普通電視節目、會議電視、高清晰數字電視等不同質量的視頻應用。在我們的生活中,可以提供高清晰畫面的 DVD影碟所采用的正是 MPEG-2 標準。
Internet的發展對視頻壓縮提出了更高的要求。在內容交互、對象編輯、隨機存取等新需求的刺激下, ISO 于 1999 年通過了 MPEG-4 標準(相當于CCITT 的 H.263 和 H.263+標準)。MPEG-4 標準擁有更高的壓縮比率,支持并發數據流的編碼、基于內容的交互操作、增強的時間域隨機存取、容錯、基于內容的尺度可變性等先進特性。Internet上新興的 DivX 和 XviD 文件格式就是采用 MPEG-4 標準來壓縮視頻數據的,它們可以用更小的存儲空間或通信帶寬提供與 DVD不相上下的高清晰視頻,這使我們在 Internet 上發布或下載數字電影的夢想成為了現實。
就像視頻壓縮和電視產業的發展密不可分一樣,音頻數據的壓縮技術最早也是由無線電廣播、語音通信等領域里的技術人員發展起來的。這其中又以語音編碼和壓縮技術的研究最為活躍。自從 1939 年H. Dudley 發明聲碼器以來,人們陸續發明了脈沖編碼調制( PCM )、線性預測( LPC )、矢量量化( VQ )、自適應變換編碼(ATC )、子帶編碼( SBC)等語音分析與處理技術。這些語音技術在采集語音特征,獲取數字信號的同時,通常也可以起到降低信息冗余度的作用。像圖像壓縮領域里的 JPEG一樣,為獲得更高的編碼效率,大多數語音編碼技術都允許一定程度的精度損失。而且,為了更好地用二進制數據存儲或傳送語音信號,這些語音編碼技術在將語音信號轉換為數字信息之后又總會用 Huffman 編碼、算術編碼等通用壓縮算法進一步減少數據流中的冗余信息。
對于電腦和數字電器(如數碼錄音筆、數碼隨身聽)中存儲的普通音頻信息,我們最常使用的壓縮方法主要是MPEG 系列中的音頻壓縮標準。例如, MPEG-1 標準提供了Layer I 、 Layer II 和 Layer III 共三種可選的音頻壓縮標準, MPEG-2 又進一步引入了 AAC ( Advanced Audio Coding )音頻壓縮標準, MPEG-4標準中的音頻部分則同時支持合成聲音編碼和自然聲音編碼等不同類型的應用。在這許多音頻壓縮標準中,聲名最為顯赫的恐怕要數 MPEG-1 Layer III ,也就是我們常說的 MP3 音頻壓縮標準了。從 MP3 播放器到 MP3 手機,從硬盤上堆積如山的 MP3 文件到 Internet上版權糾紛不斷的 MP3 下載, MP3 早已超出了數據壓縮技術的范疇,而成了一種時尚文化的象征了。
很顯然,在多媒體信息日益成為主流信息形態的數字化時代里,數據壓縮技術特別是專用于圖像、音頻、視頻的數據壓縮技術還有相當大的發展空間――畢竟,人們對信息數量和信息質量的追求是永無止境的。
回到未來
從信息熵到算術編碼,從猶太人到 WinRAR ,從 JPEG 到 MP3,數據壓縮技術的發展史就像是一個寫滿了“創新”、“挑戰”、“突破”和“變革”的羊皮卷軸。也許,我們在這里不厭其煩地羅列年代、人物、標準和文獻,其目的只是要告訴大家,前人的成果只不過是后人有望超越的目標而已,誰知道在未來的幾年里,還會出現幾個 Shannon ,幾個Huffman 呢?
談到未來,我們還可以補充一些與數據壓縮技術的發展趨勢有關的話題。
1994年,M. Burrows和D. J. Wheeler共同提出了一種全新的通用數據壓縮算法。這種算法的核心思想是對字符串輪轉后得到的字符矩陣進行排序和變換,類似的變換算法被稱為 Burrows-Wheeler 變換,簡稱 BWT 。與 Ziv 和 Lempel 另辟蹊徑的做法如出一轍, Burrows 和 Wheeler 設計的 BWT 算法與以往所有通用壓縮算法的設計思路都迥然不同。如今, BWT 算法在開放源碼的壓縮工具bzip 中獲得了巨大的成功, bzip 對于文本文件的壓縮效果要遠好于使用 LZ系列算法的工具軟件。這至少可以表明,即便在日趨成熟的通用數據壓縮領域,只要能在思路和技術上不斷創新,我們仍然可以找到新的突破口。
分形壓縮技術是圖像壓縮領域近幾年來的一個熱點。這一技術起源于B. Mandelbrot 于 1977 年創建的分形幾何學。M. Barnsley 在 20 世紀 80 年代后期為分形壓縮奠定了理論基礎。從 20 世紀 90 年代開始, A. Jacquin等人陸續提出了許多實驗性的分形壓縮算法。今天,很多人相信,分形壓縮是圖像壓縮領域里最有潛力的一種技術體系,但也有很多人對此不屑一顧。無論其前景如何,分形壓縮技術的研究與發展都提示我們,在經過了幾十年的高速發展之后,也許,我們需要一種新的理論,或是幾種更有效的數學模型,以支撐和推動數據壓縮技術繼續向前躍進。
人工智能是另一個可能對數據壓縮的未來產生重大影響的關鍵詞。既然 Shannon認為,信息能否被壓縮以及能在多大程度上被壓縮與信息的不確定性有直接關系,假設人工智能技術在某一天成熟起來,假設計算機可以像人一樣根據已知的少量上下文猜測后續的信息,那么,將信息壓縮到原大小的萬分之一乃至十萬分之一,恐怕就不再是天方夜譚了。
回顧歷史之后,人們總喜歡暢想一下未來。但未來終究是未來,如果僅憑你我幾句話就可以理清未來的技術發展趨勢,那技術創新的工作豈不就索然無味了嗎?依我說,未來并不重要,重要的是,趕快到 Internet 上下載幾部大片,然后躺在沙發里,好好享受一下數據壓縮為我們帶來的無限快樂吧。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7080瀏覽量
89177 -
算法
+關注
關注
23文章
4620瀏覽量
93047 -
編碼
+關注
關注
6文章
946瀏覽量
54870
原文標題:有趣!史記:數據壓縮算法列傳
文章出處:【微信號:EngicoolArabic,微信公眾號:電子工程技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
EE-257:面向Blackfin處理器的引導壓縮/解壓縮算法

【BearPi-Pico H3863星閃開發板體驗連載】LZO壓縮算法移植
PolarDB-MySQL引擎層的索引前綴壓縮能力的技術實現和效果
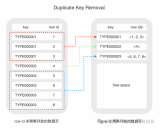
Huffman壓縮算法概述和詳細流程
鴻蒙原生應用元服務開發-Web歷史記錄導航
ECU刷寫流程之壓縮刷寫技術解析

華為云GaussDB數據庫基礎版發布:旗艦性能、價格下降超60%
【RTC程序設計:實時音視頻權威指南】音視頻的編解碼壓縮技術
FPGA壓縮算法有哪些

基于門控線性網絡(GLN)的高壓縮比無損醫學圖像壓縮算法
高性能無損數據解壓縮FPGA IP,LZO無損數據解壓縮IP
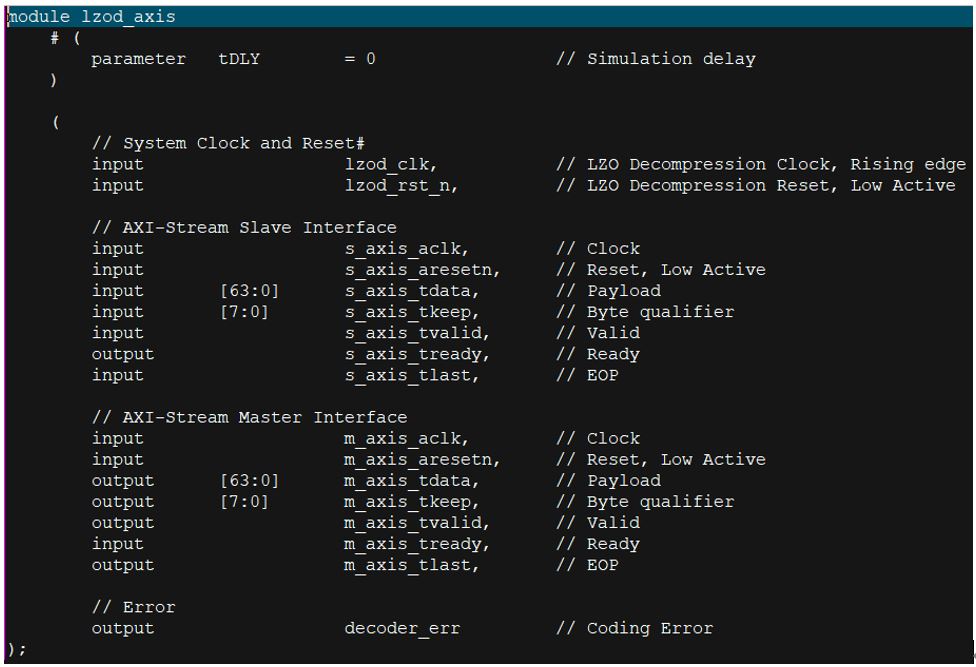
高性能無損數據壓縮FPGA IP,LZO無損數據壓縮IP





 工商網監
工商網監
評論