

國雙數據科學團隊劉燕
對比 2020 和 2019 年 Gartner 發布的人工智能領域的技術“成熟度曲線”(Hype Cycle),在短短 1 年時間,知識圖譜的成熟度由創新觸發階段一躍達到預期膨脹高峰階段且非常接近最高點。
知識圖譜逐漸成為人工智能應用的強大助力。
曲線表示,知識圖譜的發展還需要5 - 10 年時間才能到達成熟的階段,知識圖譜依然有很大的發展空間。
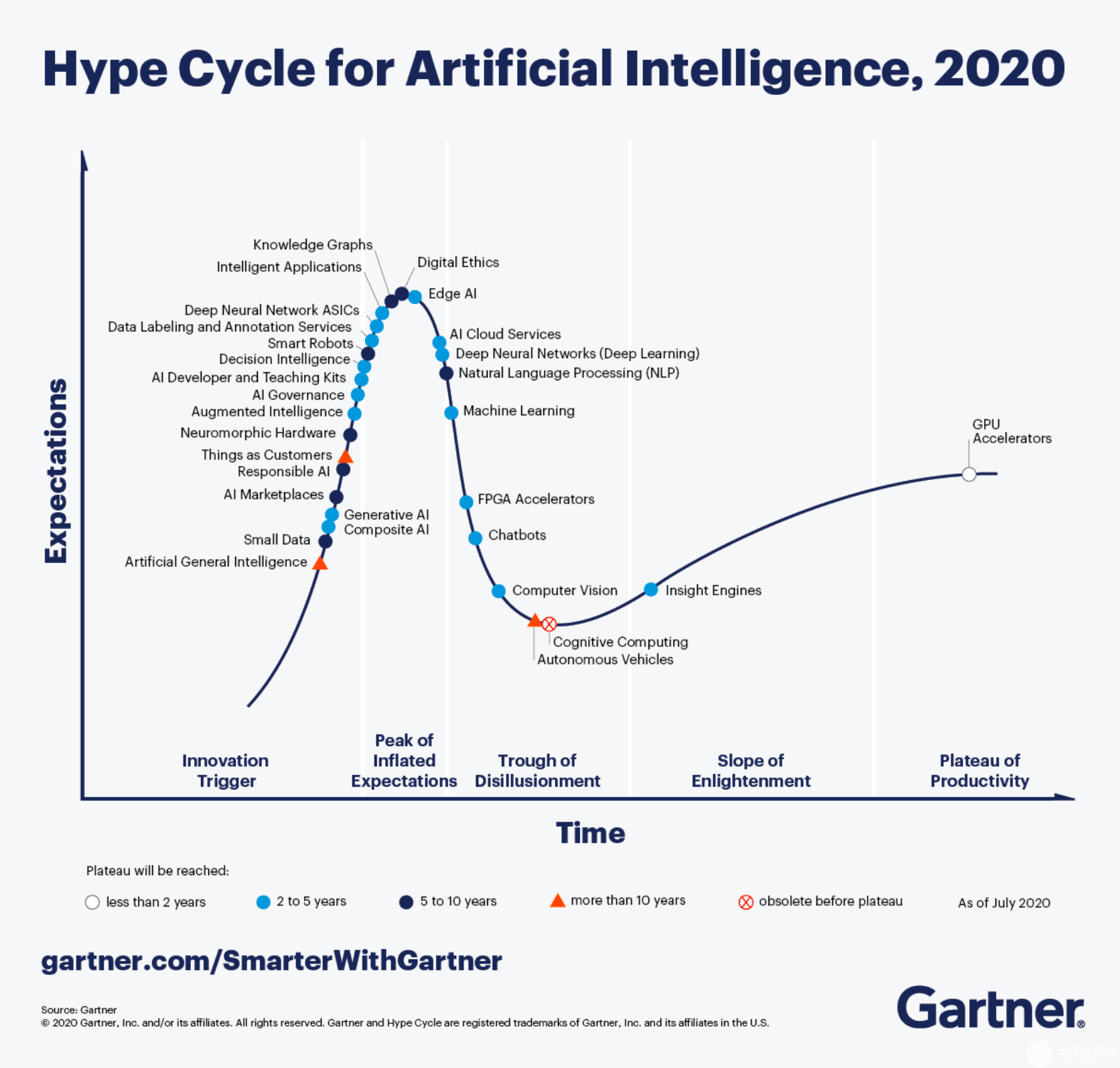
本文將從知識抽取、知識融合、知識推理的角度探索過去一年知識圖譜在自動構建領域的技術突破,并結合圖機器學習、圖數據庫探討相關領域的技術發展。
而在應用上,知識圖譜在 2020 年與產業互聯的結合更加緊密,除了在數據治理、搜索與推薦、問答等通用領域有所突破之外,在智能生產、智慧城市、智能管理、智能運維等眾多領域,以及工業、金融、司法、公安、醫療、教育等眾多行業也都有進一步的場景化落地的突破。
一、重要的技術發展
知識圖譜構建
2020 年,利用自然語言處理、機器學習等技術從多源異構的數據資源中自動構建知識圖譜的技術取得長足進展。
主要涉及到兩種方法:一種是基于語言規則的方法,另一種是基于統計分析的機器學習方法。自動構建的過程中,如果數據是結構化的 ( 例如圖表數據 ),已知屬性名稱、屬性間的層次結構等,構建知識圖譜相對較為容易。
如果缺乏以上信息,則只能通過文本信息等非結構化數據中提煉知識構建知識圖譜,技術上將面臨很多挑戰。
下面,我們從知識抽取、知識融合、知識推理這三方面來說明。
1.知識抽取
2020 年以來,更多知識抽取的研究工作被用來支撐更加復雜的應用場景。多學科多領域交叉研究成為一個新的特點。小樣本學習在業界逐漸為人所關注。整體來看呈現以下趨勢:
(1)多模態(Multimodal)。
多模態并非 2020 年提出的新概念,但是 2020 年對于多模態的研究熱度較往年相比提升了很多。
目前 NLP 領域多模態研究主要集中在跨語言和視覺的模態研究上,且多模態知識圖譜也逐步成為一個新的趨勢。多模態研究包括多模態信息對齊,多模態文本生成,多模態推理,多模態表示,基于語言的視覺導航等。
多模態研究的基礎是模態融合和語義對齊,現在有很多工作研究從圖片或文本中提取出結構化的知識,進行語義對齊。
目前多模態的相關研究還處于起步階段,什么場景使用以及如何使用還需要進一步探索。
(2)任務復雜化(Task complexity)。
2020 年以來,知識抽取任務更貼合實際應用場景,復雜化的知識抽取任務向我們提出了新的挑戰。
關系抽取任務已不滿足于抽取封閉的三元組關系,而更貼合實際情況,出現了很多復雜關系和開放關系的抽取任務。例如,2020LIC 比賽中關系抽取賽題相比 2019 年增加了復雜關系抽取;部分關系抽取工作從句子級別向篇章級別和多文本抽取過渡;很多研究開始探索如何利用深度學習模型自動發現實體間的新型關系,實現開放關系抽取等。
對于常規的信息抽取任務,已經逐步往語義理解上轉變,并基于此衍生出很多閱讀理解和知識推理的任務。
在實體融合和指代消解等任務上的研究,場景也更為復雜,逐步向深層次語義理解和知識推理演變。
(3)零次學習(zero-shot learning)和小樣本學習(few-shot learning)。
Zero-shot 和 few-shot 一直是知識抽取研究的難點,2020 年對于 zero-shot 和 few-shot 有了更多深入的研究,包括利用集成學習、多任務學習、預訓練模型、知識表示等方法結合深度學習模型進行的相關探索。
預訓練模型的發展使得很多知識抽取工作的瓶頸下降,但是相對來說,領域遷移和冷啟動問題還是目前的難點。近幾年出現了很多結合知識圖譜進行知識表征,添加多模態信息,結合多領域進行多任務學習等融合多源知識的相關方法和研究,并取得了一定進展。
除此之外,多學科多領域交叉也是 NLP 和知識圖譜領域在 2020 年比較大的特點。例如知識表示,包括文本表示、圖表示、多模態表示之間的交叉和結合研究。
同時在知識抽取的多種任務中,都有多領域多學科結合相互指導優化的發展趨勢,不同任務,不同學科之間的邊界變得越來越模糊。
總的來說,2020 年是知識抽取研究飛速發展的一年,科學研究者們已經不滿足于一些簡單的知識抽取任務的實現,開始探索更貼合實際的應用場景。對于任務的探索邊界也越來越不明顯,并出現了很多結合多源異構信息的相關探索。除此之外,多模態和知識圖譜表征仍然有很大發展空間。
2.知識融合
知識融合方面一直以來都面臨兩個重要的技術挑戰,一是數據規模的挑戰,數據量大,種類多樣性,存儲位置不同、結構不同;另一個是數據質量的挑戰,數據命名模糊,格式不同,數據缺失,噪音問題嚴重。
這兩個問題無論是以前,還是 2020 年度,一直都是知識融合方面面臨的嚴峻挑戰。
數據規模方面,行業算力的不斷提升使實用系統可以有效處理更大規模的圖譜數據。在多個知識圖譜聯合使用的知識融合方面,本年度 ACM SIGKDD 提出了 KGSF,通過互信息最大化,對齊不同圖譜中的語義空間,實現多知識圖譜的語義融合。這種方法使用多個知識圖譜打通了不同類型信息的語義鴻溝,在會話推薦系統的任務上起到了很好效果,也為融入多個外部的知識圖譜提供了一條可行之路。
數據質量方面,在處理不同知識圖譜對齊問題中,本年度提出了一種不同知識圖譜中語義相似的實體進行關聯時的噪音問題的解決方法。在現有方法大多都是面向干凈數據的前提下,帶有噪音檢測和基于噪音感知的實體融合方法探索出了一種魯棒的實體對齊方式,魯棒性的跨語言實體對齊模型,通過圖神經網絡建模知識圖譜中的實體對,得到噪音感知的實體對齊模塊,利用生成對抗網絡來生成噪音實體對并訓練一個噪音判別器,識別出干凈的實體對。
3.知識推理
知識推理方面,多種新穎觀點在頂級會議上被提出,例如:圖譜推理在圖像視頻描述生成領域的應用,以及垂直領域的推理任務等。
在常識問答方面,可以基于圖的上下文表示學習和基于圖的推理方法,利用不同結構的知識源進行常識問答。不針對于具體領域和具體任務,本年度還提出了一個 RNNLogic 的概率方法,該方法包括一個使用遞歸神經網絡生成邏輯規則的規則生成器,和一個帶有邏輯規則的推理預測器,并使用基于 EM 算法的優化,從學習邏輯規則的角度給出了一個知識圖譜推理的有效方案。
另外也有基于知識圖譜的向量嵌入技術,完全基于向量操作進行推理演算;基于 Neural Logic Programming 框架,在數值推理問題方面也向前邁進了一步。
圖機器學習
圖機器學習領域目前剛剛到達圖論和機器學習的交叉點。包括圖上深度學習的啟發式應用到圖模型范圍等問題都在進行廣泛和深入的研究。
同時,知識圖譜與機器學習相結合的研究也逐漸增多,相關研究成果在頂級會議上的提交率有所增長:
1.在圖嵌入方向,學者提出了一種新的 KGE 框架自動實體類型表示(AutoETER)[21],通過將每個關系看作是兩個實體類型之間的轉換(translation)操作來學習每個實體的潛在類型嵌入,并利用關系感知映射機制來學習每個實體的潛在類型嵌入;
2.知識推理方向,學者提出了一種新的框架,用于嵌入學習和跨多個特定語言的 KG 進行集成知識遷移。該框架將所有 KG 嵌入到一個共享的嵌入空間中,在那里基于自學習捕獲實體之間的關聯。然后,進行集成推理,合并來自多個特定語言 KG 嵌入的預測結果;
3.知識圖譜與推薦系統結合方向,學者首先算出圖中各類型節點的嵌入,結合注意力機制,利用鄰居節點為中心節點提供更豐富的信息,然后利用傳統的“頭結點+關系=目標節點”的方法訓練最終的圖嵌入表示,最后接入下游的推薦系統模型。此外,圖神經網絡 GNN 被廣泛應用于圖機器學習。前沿的關于圖機器學習的研究對 GNN 有更扎實的理論理解。
圖數據庫
2020 年以來,為了滿足強關聯和網絡型數據的存儲、查詢和大規模圖分析的性能需求,圖數據庫在其底層數據結構的設計上也盡量貼合關系數據的搜索模式,減少磁盤的 I/O 操作時間。傳統關系型數據庫的 B+樹數據結構在數據檢索和隨機數據讀取上有優秀的性能,而對于關系數據的遍歷則顯得相形見絀了。
分布式圖數據庫在對圖分割上有以點分割和以邊分割 2 種方案。在 2020 年越來越多的新型分布式圖數據庫會選擇以邊分割的方案,甚至是把圖節點的屬性和邊同樣對待,統稱為謂詞。相同的謂詞會存在同一臺或幾臺機器上。這樣很多查詢,特別是多跳查詢可以集中在少量的機器上完成,大大減少數據傳輸帶來的網絡開銷。新型的分布式圖數據庫在百億數據量的規模下, 單點的多跳查詢能做到毫秒級返回。
二、主要應用
知識圖譜是把人類的知識和經驗代碼化的有效工具,賦予機器認知智能以構建智能體在不同應用場景中代替或幫助人類解決實際問題。
接下來,我們將從通用和垂直兩個層面探討其應用。
首先,知識圖譜在通用領域的應用:
1.數據治理
2020 年,知識圖譜被逐漸應用在數據治理中。政務、金融、審計等行業均有嘗試。
部分企業提出數據、管理、業務的三層圖譜概念。也有企業從場景落地出發,提出“數據”與“知識”雙驅動:即,從生產、經營、管理等實際業務場景出發,將業務、流程、指標中的知識構建成知識圖譜。
一方面,應用知識圖譜將業務場景與數據關聯起來,讓機器知道什么業務場景需要什么數據,這些數據必須達到怎樣的標準和質量,進而幫助數據治理;另一方面,通過數據治理所形成的業務發現沉淀到知識圖譜里,在數字化轉型中釋放價值。
這樣一來,一些傳統數據治理中的難題得到進一步解決:通過知識、模型以及圖結構的應用,一些錯誤的、不一致的信息可以被發現、統一;基于業務規則定義,可識別潛在的數據關聯關系,進一步補充信息。
知識圖譜將業務數據、產業知識、通用常識、機理模型、決策網絡、機器學習模型進行混合存儲,實現知識和數據沉淀賦能智能應用。在業務場景的驅動下,應用知識圖譜可以有效實現數據治理與業務治理的迭代閉環。
2.搜索與推薦
隨著知識圖譜的深層應用,2020 年,搜索與推薦更加智能,并在消費領域之外的生產、管理等方向不斷下沉。
在面向生產、管理等垂直業務領域,領域知識、事件圖譜的應用提升了檢索效率與質量。一些非結構化或半結構化數據應用較多的專業,如審計、醫療、金融、司法、各類型研究結構等,文書、文獻、案例/判例、研究成果、專家經驗被引入到領域知識圖譜的構建中。通過對不同層次知識分析、加工、結構化處理,在常規檢索之外,實現知識的鉆取和深度挖掘。
在這個過程中,一些企業通過知識標注工具,將業務實體、屬性和關聯關系標記出來,把標記的實體和關系存入知識庫,并把它們沉淀成自動知識抽取模型的訓練語料;也有一些企業通過映射、連接及各類 D2R 操作,將結構化數據庫的數據字典、表結構、關系及數據庫內容轉換為知識圖譜的本體、業務實體、實體間關系組成的三元組,以便于人們從研究對象、研究主題、業務分類等多個維度檢索出相關結果。
其次,知識圖譜在垂直領域的應用:
1.智慧生產
工業知識圖譜是知識圖譜的重點發展方向。今年人們對知識圖譜在生產領域的探索貫穿了產品生產的各個環節:
以石油化工業領域的應用為例。考慮到石化產業具有易燃易爆、工藝復雜等特點,現實中有大量無法通過機理模型或模擬軟件解釋的現象。為方便生產線工人的日常作業,人們通過構建產業鏈知識圖譜,在短時間內從眾多影響因子的因果變化關系中進行生產操作前的模擬:如工人準備改變某可操作變量時,可通過圖譜預測操作帶來的變化;如工人試圖達到某結果時,可通過圖譜提前預判操作步驟。
(2)產品研發:
在知識圖譜的支撐下可以圍繞產品發展趨勢為新產品市場定位提供決策知識;可以識別新產品在不同使用場景下的使用方法和使用要求,推送其他產品的應用案例;還可以提供已有的相似產品、相關技術、領域專家和信息化工具軟件等信息。
(3)產品質量提升:
通過監控生產過程中的實時參數曲線構建核心部件的健康指數模型,在識別關鍵因素的基礎上進行參數推薦,提升良品率。
(4)生產預測:
在機理模型與經驗模型融合的基礎上,結合生產知識圖譜實現圖迭代計算,計算出某因子發生變化時整個關系網絡達到穩定后各個產物節點的狀態值,實現更準確的生產預測[26]。
(5)供應鏈風險管理及零部件選型:
可以匯集產品知識、物流知識、采購知識、制造知識、交通信息等等構建供應鏈及零部件圖譜,將采購、物流、制造聯系起來,通過語義網(關系網)實現供應鏈風險管理與零部件選型。
(6)節能減排:
集成、分析物聯網傳感器和系統的信息,打通建筑物管理、居住舒適度調節、電源監控等數據孤島,構建智能建筑領域的物聯網知識圖譜。降低開發者和工程師的工作量,實現最優化的智能建筑運營。
(7)設備故障預警與安全生產:
以石油領域為例,油田聯合站承擔原油處理、存儲與外輸任務,是一級防火、甲級防爆單位。通過設備知識圖譜和決策知識圖譜,一方面可以將設備的生產參數變化轉換為狀態變化和各種生產現象,模擬專家分析設備運行過程,對設備運行狀態進行預測;此外,還能基于不同生產現象的變化在決策圖譜中自動選擇最優措施方案,生成決策建議,通知現場管理人員進行現場作業和處理。
2.智能營銷
消費者、商品的圖譜構建更加深入、完善。
(1)消費者:
數據進一步打通。除用戶基本信息、行為特征之外,興趣、場景、需求等內容也逐漸豐富到消費者圖譜內。用戶價值模型、購買驅動因素模型等模型應用也擴展了圖譜內容。
(2)商品:
一些企業通過構建事件圖譜、視頻理解圖譜強化對事件、場景的感知,嘗試從文本到多媒體的跨越,豐富產品構建內容;在消費品領域,消費者對產品的別稱、昵稱、縮寫等非常豐富,制約了圖譜構建效率,還有一些企業在圖融合領域不斷探索,提升實體的自動化對齊效果。
部分應用:
(1)自動撰文:
挖掘主競品文章中對業務有價值的高頻詞語和短語,形成實體庫;通過本體及實體的挖掘找到人群與需求、人群與場景的關系;挖掘屬性和評價詞語,與相關實體關聯,形成實體的評價印象;解析句子的語法結構以及與本體、實體的關聯,使機器撰寫更接近人的行文習慣。
(2)購買意向預測與內容推薦:
結合機器感知、特征標簽和業務經驗對用戶特征進行價值挖掘,把用戶特征輸出成參數,用模型篩選出適合參加某些活動的人群;通過聚類,利用 K-means 對具有較高購買可能性的人群進行類別劃分;針對不同群體的需求,如價格、興趣、場景等傳遞不同的內容信息,提升內容推薦效果。
3.AIOps(智能運維)
主要是將知識圖譜與根因分析相結合,進一步提升運維效率和質量。
今年比較流行的做法是:通過應用業務日志、CMDB 配置系統等數據構建異常事件圖譜;再運用推導模型進行根因定位,對存在異常的子系統及其相關的 IP、DCN、服務信息進行提取,對異常事件知識圖譜進行裁剪;最后,再應用規則引擎推導出根因結論。
一些企業會針對告警數據進行分類,利用軟硬件知識圖譜將有關聯的物理機、虛擬機和軟件數據匯聚為一組,便于后續建模和應用;一些企業對不同時間粒度的樣本構建因果圖,通過對算法構建的因果圖構建告警知識圖譜,讓運維人員在快速查詢故障設備信息的基礎上進一步了解故障發生原因以及后續處理步驟;
還有一些企業嘗試將基于專家規則的推理與基于描述邏輯的推理、基于分布式表示的表示學習推理、本體推理、復合推理相結合,利用知識圖譜讓系統自動采取相應的恢復手段、維護策略,實現網絡的 “自維護”。
4.智能管理
這里,我們主要介紹在政府管理中的應用。
我們知道,在政府日常管理中,政務數據與政府、企業、非盈利組織和公民等多角色密切相關,需要依據各類規章制度,涉及大量單據、文檔材料等非結構化、半結構化與結構化數據。由于政務業務的變動和對數據的認知變化導致的數據類別上的增加或變化的發生頻率很高,知識圖譜的本體自動構建技術和基于動態知識圖譜的數據集成方案技術非常必要。
今年,一些企業正在基于聚類算法和強化學習結合的模式開發 schema 自動構建和根據反饋調整知識圖譜的能力來滿足業務動態變化的需求,以減少工作成本,提升效率。還有一些企業利用動態知識譜圖技術,將模型與數據進行解耦,降低大規模數據集成場景下知識圖譜變化帶來的計算壓力。
通過知識圖譜的應用,一方面打破了數據孤島,將大規模、碎片化的多源政務數據關聯起來,以實體為基本單位對政務數據進行挖掘,揭示各實體間的復雜關系,實現知識層面的數據融合與集成。同時,也更大程度的釋放了政務數據價值,為政府部門、企業、非營利組織、公民提供更高水準的服務,提高政府監管效率和效能。
三、知識圖譜行業和技術發展的展望
1、技術發展趨勢展望
知識圖譜主要技術包括知識獲取、知識表示、知識存儲、知識建模、知識融合、知識計算、知識運維等七個方面,盡管目前已取得了很多成就,但仍在快速演進當中。
例如,在知識獲取方面,資源缺乏、面向開放域、跨語言及跨媒體等方向的知識抽取正在成為未來的研究方向;
在知識表示方面,符號與表示學習的融合統一、面向事理邏輯的知識表示、融合時空間維度的知識表示、融合跨媒體元素的知識表示正在成為未來的研究方向;
在知識存儲方面,基于 RDF 和 LPG 知識表示的分布式存儲、涉及高適應性的知識存儲、基于 LOD(Linked Open Data)的知識存儲、Hyper Graph 的進一步研究和應用正在成為未來的研究方向。
2、應用趨勢展望
目前,大規模知識圖譜的應用場景還比較有限,其在智能語義搜索、深度問答(包括基于信息檢索的問答系統、基于語義分析的問答系統)、演化分析、對話理解等方面的應用也處于初級階段,仍具有廣闊的應用與推廣前景。
從知識圖譜應用發展趨勢來看,當前正在從通用知識圖譜應用向領域或行業知識圖譜應用拓展,如金融、醫療、公安、醫療、司法、電商等,依托知識圖譜強大知識庫的深度知識推理能力和逐步擴展的認知能力,幫助相關行業從業者對特定的問題進行分析、推理、輔助決策。
3、標準化趨勢展望
隨著 ISO/IEC JTC1/SC42、W3C、IEEE、全國信息技術標準化技術委員會、國家人工智能標準化總體組等國內外標準化組織或機構對知識圖譜標準化的關注與推動,《知識圖譜技術架構》等多項知識圖譜相關國際、國家標準獲得立項或提出討論。
未來,知識圖譜領域基礎共性及關鍵技術標準將不斷涌現,依托正在研制的知識圖譜技術架構等標準,通過聚焦核心標準化需求逐步建立基本的知識圖譜標準體系并孵化典型行業中的知識圖譜應用標準,形成國際標準、國家標準、行業標準和團體標準良性互動的局面。
4、技術開發與應用相關建議
(1)加強知識圖譜核心關鍵技術支持與突破:
突破知識圖譜基礎理論及關鍵核心技術瓶頸,以算法為核心,以數據和硬件為基礎,以大規模知識庫的構建與應用為導向,實施重大關鍵技術攻關工程。
(2)加強知識圖譜優秀解決方案/產品展示與推廣:
通過梳理知識圖譜在典型行業的優秀案例并形成案例集,建設開放性實驗室,推出優質培訓課程等方式加強知識圖譜優秀平臺或產品的展示與推廣,打破知識圖譜開發企業、研究院所、高校與各領域企業間的溝通屏障。
(3)加強通用和領域知識圖譜開放平臺建設:
開放的通用知識圖譜和領域知識圖譜平臺是推動知識圖譜技術在各行業融合應用的重要基礎設施,能夠避免企業在建設知識圖譜過程中從零開始或重復建設,也可降低知識圖譜項目實施方的設計開發成本。
11月11-15日
一、知識圖譜概論
1.1知識圖譜的起源和歷史
1.2知識圖譜的發展史——從框架、本體論、語義網、鏈接數據到知識圖譜
1.3知識圖譜的本質和價值
1.4知識圖譜VS傳統知識庫VS關系數據庫
1.5經典的知識圖譜
二、知識圖譜應用
2.1知識圖譜應用場景
2.2知識圖譜應用簡介
三、知識表示與知識建模
3.1知識表示概念
3.2 知識表示方法
3.3典型知識庫項目的知識表示
3.4知識建模方法學
3.5知識表示和知識建模實踐
四、知識抽取與挖掘
4.1知識抽取基本問題
4.2數據采集和獲取
4.3面向結構化數據的知識抽取
4.4面向半結構化數據的知識抽取
4.5.面向非結構化數據的知識抽取
4.6.知識挖掘
4.7知識抽取上機實踐
五、知識融合
5.1知識融合背景
5.2知識異構原因分析
5.3知識融合解決方案分析
5.4.本體對齊基本流程和常用方法
5.5實體匹配基本流程和常用方法
5.6 知識融合上機實踐
六、存儲與檢索
6.1.知識圖譜的存儲與檢索概述
6.2.知識圖譜的存儲
6.3.知識圖譜的檢索
6.4.上機實踐案例:利用GraphDB完成知識圖譜的存儲與檢索
七、知識推理
7.1.知識圖譜中的推理技術概述
7.2.歸納推理:學習推理規則
上機實踐案例:利用AMIE+算法完成Freebase數據上的關聯規則挖掘
7.3.演繹推理:推理具體事實
7.4.基于分布式表示的推理
7.5.上機實踐案例:利用分布式知識表示技術完成Freebase上的鏈接預測
八、語義搜索
8.1.語義搜索概述
8.2.搜索關鍵技術
8.3.知識圖譜搜索
8.4.知識可視化
8.5.上機實踐案例:SPARQL搜索
九、知識問答
9.1.知識問答概述
9.2.知識問答基本流程
9.3.相關測試集:QALD、WebQuestions等
9.4.知識問答關鍵技術
9.5.上機實踐案例:DeepQA、TemplateQA
審核編輯 黃昊宇
-
知識圖譜
+關注
關注
2文章
132瀏覽量
7833
發布評論請先 登錄
相關推薦
江西萬年芯通過數字化轉型成熟度星級評估

數字化賦能!德明利智能制造基地榮獲三級成熟度評估認證

東軟獲《電信和互聯網軟件供應鏈安全能力成熟度模型》第三等級認證
有方科技參編的信息技術團體標準發布
傳音旗下人工智能項目榮獲2024年“上海產學研合作優秀項目獎”一等獎

傳音旗下小語種AI技術榮獲2024年“上海產學研合作優秀項目獎”一等獎


三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
普華基礎軟件通過軟件能力成熟度5級認證
持續領跑 涂鴉智能再度入圍Gartner《 中國智慧城市和可持續發展技術成熟度曲線》報告
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
華為鴻蒙內核獲中國信通院自主成熟度A級認證
卡諾模型助力AI騰飛:人工智能發展新視角
智能制造能力成熟度模型是什么?





 工商網監
工商網監

評論