 基于Transformer與覆蓋注意力機制建模的手寫數學公式識別
基于Transformer與覆蓋注意力機制建模的手寫數學公式識別
一、研究背景
手寫數學公式識別是將包含數學表達式的圖像轉換為結構表達式,例如LaTeX數學表達式或符號布局樹的過程。手寫數學表達式的識別已經帶來了許多下游應用,如在線教育、自動評分和公式圖像搜索。在在線教育場景下,手寫數學表達式的識別率對提高學習效率和教學質量至關重要。 對比于傳統的文本符號識別(Optical Character Recognition, OCR),公式識別具有更大的挑戰性。公式識別不僅需要從圖像中識別不同書寫風格的符號,還需要建模符號和上下文之間的關系。例如,在LaTeX中,模型需要生成“^”、“_”、“{”和“}”來描述二維圖像中符號之間的位置和層次關系。編碼器-解碼器架構由于可以編碼器部分進行特征提取,在解碼器部分進行語言建模,而在手寫數學公式識別任務(Handwritten Mathematical Expression Recognition, HMER)中被廣泛使用。 雖然Transformer在自然語言處理領域已經成為了基礎模型,但其在HMER任務上的性能相較于循環神經網絡(Recurrent Neural Network, RNN)還不能令人滿意。作者觀察到現有的Transformer與RNN一樣會受到缺少覆蓋注意力機制的影響,即“過解析”——圖像的某些部分被不必要地多次解析,以及“欠解析”——有些區域未被解析。RNN解碼器使用覆蓋注意機制來緩解這一問題。然而,Transformer解碼器所采用的點積注意力沒有這樣的覆蓋機制,作者認為這是限制其性能的關鍵因素。 不同于RNN,Transformer中每一步的計算是相互獨立的。雖然這種特性提高了Transformer中的并行性,但也使得在Transformer解碼器中直接使用以前工作中的覆蓋機制變得困難。為了解決上述問題,作者提出了一種利用Transformer解碼器中覆蓋信息的新模型,稱為CoMER。受RNN中覆蓋機制的啟發,作者希望Transformer將更多的注意力分配到尚未解析的區域。具體地說,作者提出了一種新穎的注意精煉模塊(Attention Refinement Module, ARM),它可以在不影響并行性的前提下,根據過去的對齊信息對注意權重進行精煉。同時為了充分利用來自不同層的過去對齊信息,作者提出了自覆蓋和交叉覆蓋,分別利用來自當前層和前一層的過去對齊信息。作者進一步證明,在HMER任務中,CoMER的性能優于標準Transformer解碼器和RNN解碼器。
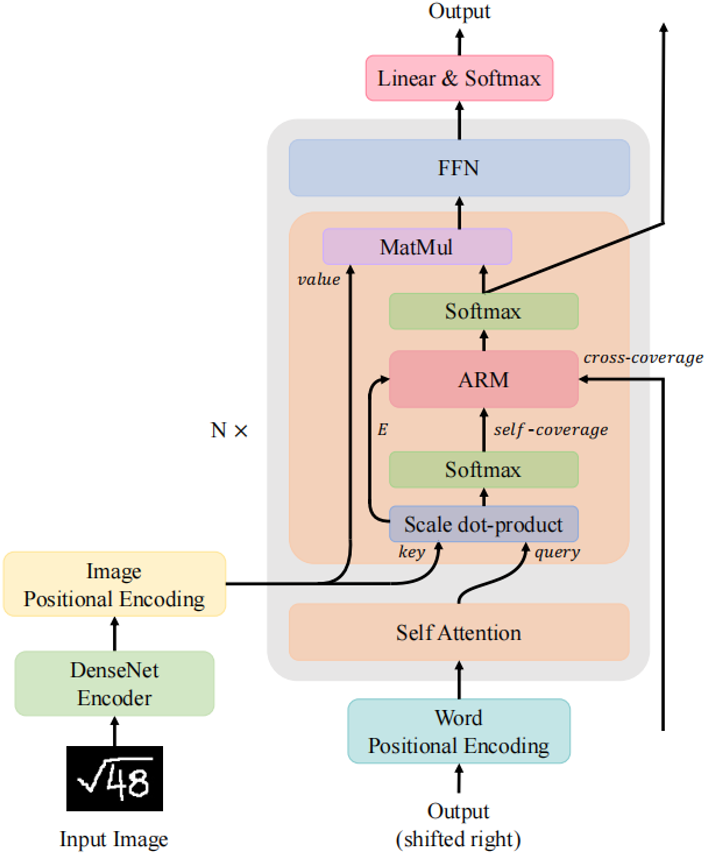
圖1 本文提出的具有注意力精煉模塊的Transformer模型
二、方法原理簡述
CNN編碼器在編碼器部分,本文使用DenseNet作為編碼器。相較于ResNet,DenseNet在不同尺度特征圖上的密集連接能夠更好地反映出不同大小字符的尺度特征,有利于后續解碼不同位置大小字符的含義。為了使DenseNet輸出特征與解碼器模型尺寸對齊,作者在編碼器的末端增加了1 × 1的卷積層,得到輸出圖像特征
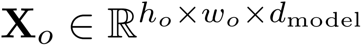 。
。
位置編碼與RNN解碼器不同,由于Transformer解碼器的Token之間不具有空間位置關系,額外的位置信息是必要的。在論文中,作者與BTTR[1]一致,同時使用圖像位置編碼和字符位置編碼。 對于字符位置編碼,作者使用Transformer[2]中引入的1D位置編碼。給定編碼維數d,位置p,特征維索引i,則字符位置編碼向量
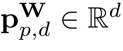
可表示為:
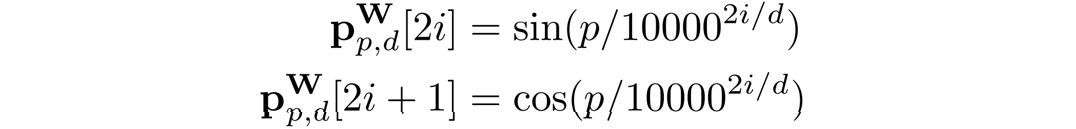
圖像位置編碼采用與[1,3]相同的二維歸一化位置編碼。由于模型需要關注的是相對位置,所以首先要將位置坐標歸一化。給定二維坐標元組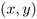 ,編碼維數為d,通過一維位置的拼接計算二維圖像位置編碼
,編碼維數為d,通過一維位置的拼接計算二維圖像位置編碼
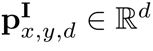 。
。
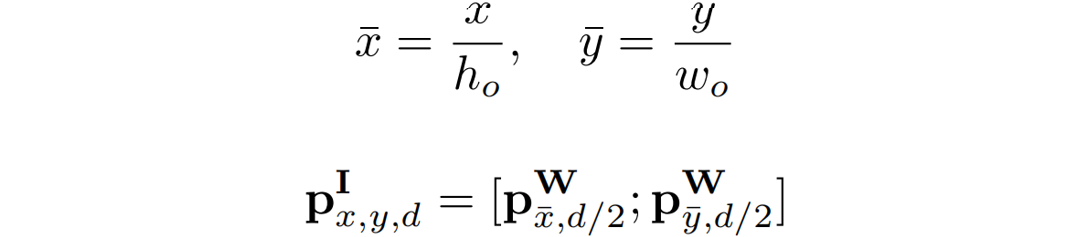
其中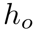 和
和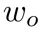 代表了輸入圖像特征的尺寸。注意力精煉模塊(ARM)如果在Transformer中直接采用RNN式的覆蓋注意力機制。那么將會產生一個具有
代表了輸入圖像特征的尺寸。注意力精煉模塊(ARM)如果在Transformer中直接采用RNN式的覆蓋注意力機制。那么將會產生一個具有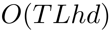 空間復雜度的覆蓋矩陣
空間復雜度的覆蓋矩陣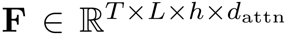 ,這樣的大小是難以接受的。問題的瓶頸在于覆蓋矩陣需要先與其他特征向量相加,再乘以向量
,這樣的大小是難以接受的。問題的瓶頸在于覆蓋矩陣需要先與其他特征向量相加,再乘以向量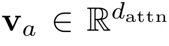 。如果我們可以先將覆蓋矩陣與
。如果我們可以先將覆蓋矩陣與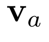 相乘,再加上LuongAttention[4]的結果,空間復雜度將大大降低到。因此作者將注意力機制修改為:
相乘,再加上LuongAttention[4]的結果,空間復雜度將大大降低到。因此作者將注意力機制修改為:
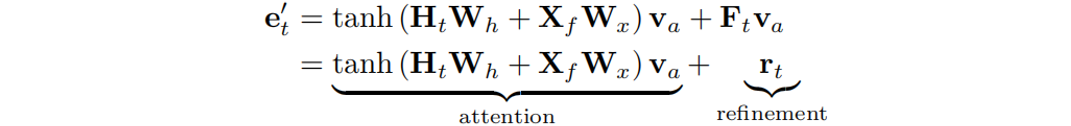
其中相似向量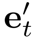 可分為注意項和精煉項
可分為注意項和精煉項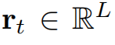 。需要注意的是,精煉項可以通過覆蓋函數直接由累積
。需要注意的是,精煉項可以通過覆蓋函數直接由累積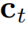 向量生成,從而避免了具有為維數為
向量生成,從而避免了具有為維數為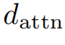 的中間項。作者將上式命名為注意力精煉框架。
的中間項。作者將上式命名為注意力精煉框架。
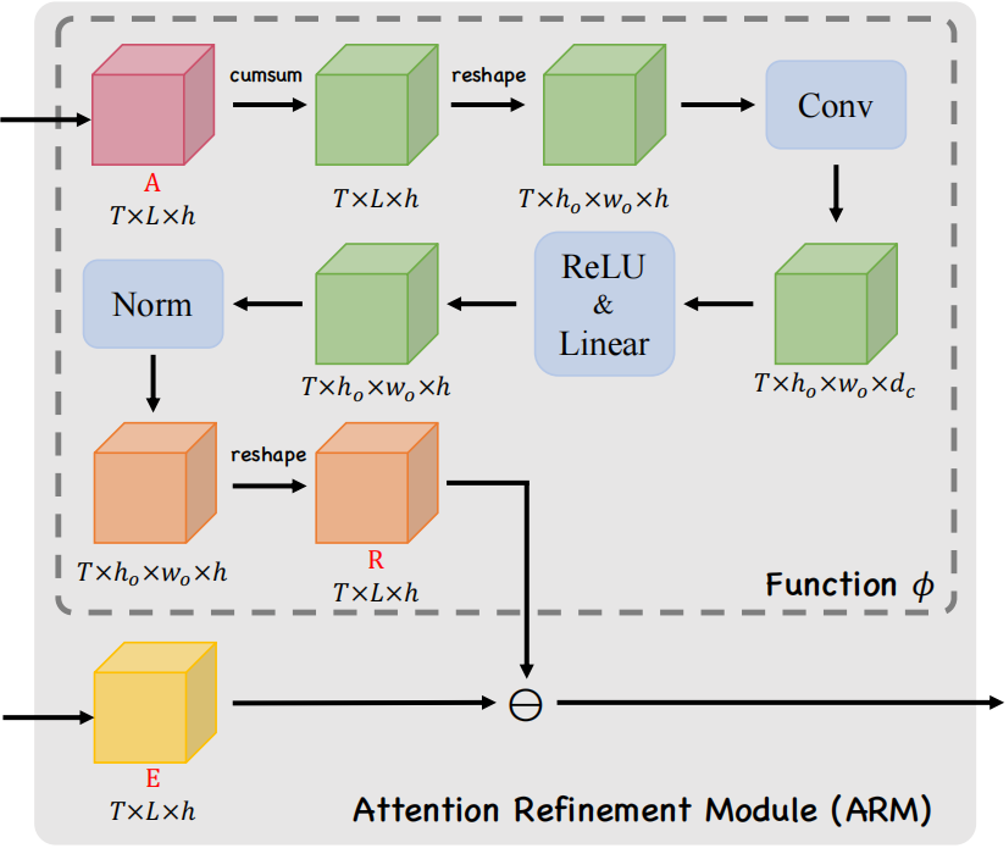
圖2 注意精煉模塊(ARM)的整體結構 為了在Transformer中使用這一框架,作者提出了如圖2所示的注意精煉模塊(ARM)。可以將Transformer中的點積矩陣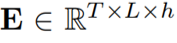 作為注意項,精煉項矩陣R需要從經過Softmax后的注意權值A中計算出來。作者使用了注意權值A來提供歷史對齊信息,具體的選擇會在下一小節介紹。 作者定義了一個將注意力權重
作為注意項,精煉項矩陣R需要從經過Softmax后的注意權值A中計算出來。作者使用了注意權值A來提供歷史對齊信息,具體的選擇會在下一小節介紹。 作者定義了一個將注意力權重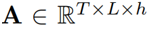 作為輸入,輸出為精煉矩陣
作為輸入,輸出為精煉矩陣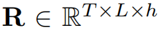 的函數
的函數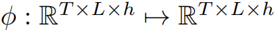 :
:
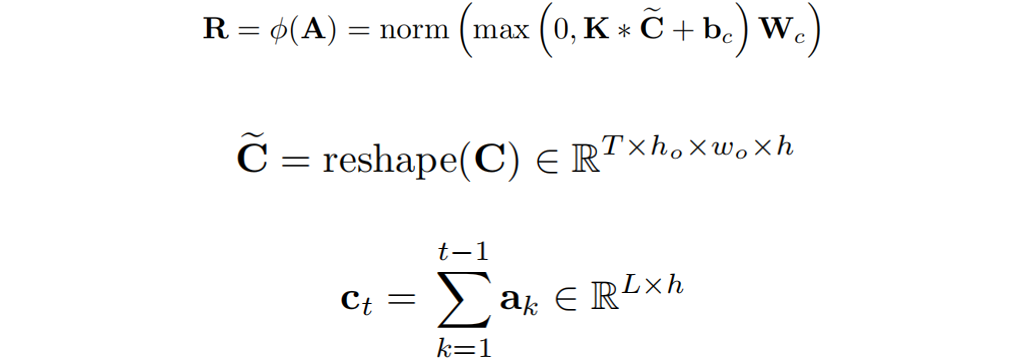
其中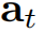 是在時間步
是在時間步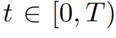 時的注意力權重。
時的注意力權重。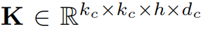 代表一個卷積核,*代表卷積操作。
代表一個卷積核,*代表卷積操作。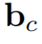 是一個偏置項,
是一個偏置項,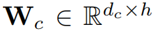 是一個線性投影矩陣。 作者認為函數
是一個線性投影矩陣。 作者認為函數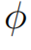 可以提取局部覆蓋特征來檢測已解析區域的邊緣,并識別傳入的未解析區域。最終,作者通過減去精煉項R來達到精煉注意力項E的目的。覆蓋注意力本節將介紹注意權重A的具體選擇。作者提出了自覆蓋、交叉覆蓋以及融合覆蓋三種模式,以利用不同階段的對齊信息。自覆蓋: 自覆蓋是指使用當前層生成的對齊信息作為注意精煉模塊的輸入。對于當前層j,首先計算注意權重
可以提取局部覆蓋特征來檢測已解析區域的邊緣,并識別傳入的未解析區域。最終,作者通過減去精煉項R來達到精煉注意力項E的目的。覆蓋注意力本節將介紹注意權重A的具體選擇。作者提出了自覆蓋、交叉覆蓋以及融合覆蓋三種模式,以利用不同階段的對齊信息。自覆蓋: 自覆蓋是指使用當前層生成的對齊信息作為注意精煉模塊的輸入。對于當前層j,首先計算注意權重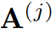 ,并對其進行精煉。
,并對其進行精煉。
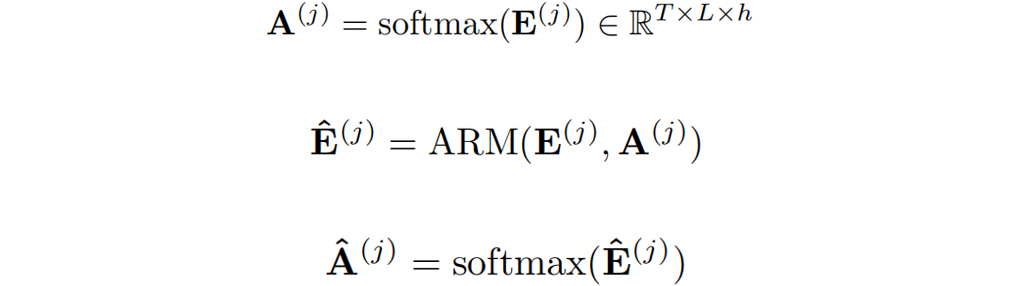
其中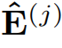 代表了精煉后的點積結果。
代表了精煉后的點積結果。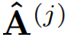 代表在j層精煉后的注意力權重。交叉覆蓋:作者利用Transformer中解碼層相互堆疊的特性,提出了一種新的交叉覆蓋方法。交叉覆蓋使用前一層的對齊信息作為當前層ARM的輸入。j為當前層,我們使用精煉后的注意力權重
代表在j層精煉后的注意力權重。交叉覆蓋:作者利用Transformer中解碼層相互堆疊的特性,提出了一種新的交叉覆蓋方法。交叉覆蓋使用前一層的對齊信息作為當前層ARM的輸入。j為當前層,我們使用精煉后的注意力權重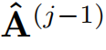 之前
之前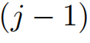 層來精煉當前層的注意力項。
層來精煉當前層的注意力項。
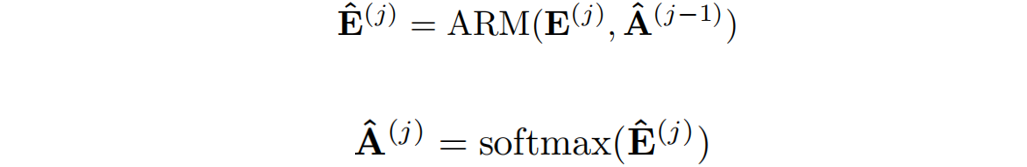
融合覆蓋:將自覆蓋和交叉覆蓋相結合,作者提出了一種新的融合覆蓋方法,充分利用從不同層生成的過去對齊信息。
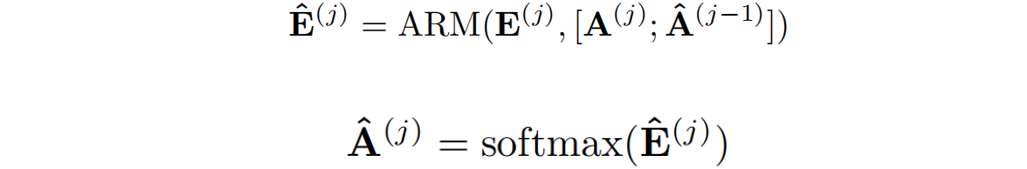
其中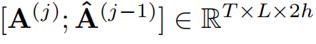 表示來自當前層的注意權重與來自前一層的精煉注意權重進行拼接。
表示來自當前層的注意權重與來自前一層的精煉注意權重進行拼接。
三、主要實驗結果及可視化結果
表1 與先前工作在CROHME數據集上的效果的比較
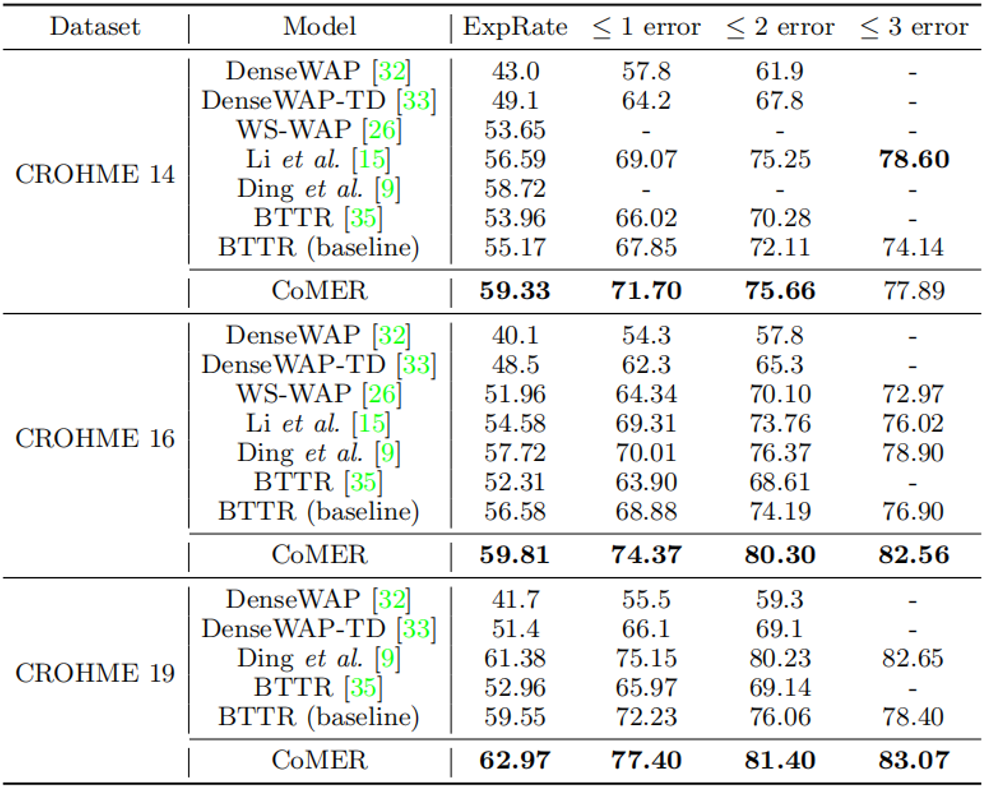
從表1中可以看出,與使用覆蓋注意力機制的RNN的模型相比,CoMER在每個CROHME測試集上的性能優于Ding等人[5]提出的先前最先進的模型。在完全正確率ExpRate中,與之前性能最好的基于RNN的模型相比,CoMER平均提高了1.43%。與基于Transformer的模型相比,作者提出的帶有ARM和融合覆蓋的CoMER顯著提高了性能。具體而言,CoMER在所有指標上都優于基準“BTTR”,在ExpRate中平均領先基準“BTTR”3.6%。
表2 各模塊消融實驗
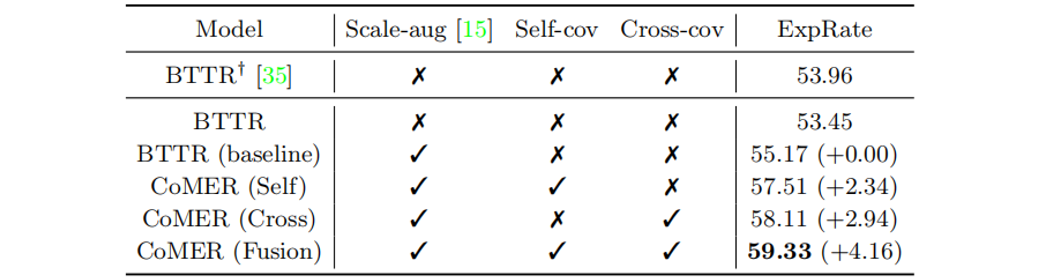
在表2中,“Scale -aug”表示是否采用尺度增廣[6]。“Self-cov”和“Cross-cov”分別表示是否使用自覆蓋和交叉覆蓋。與BTTR相比,采用ARM和覆蓋機制的CoMER的性能有了明顯的提高。
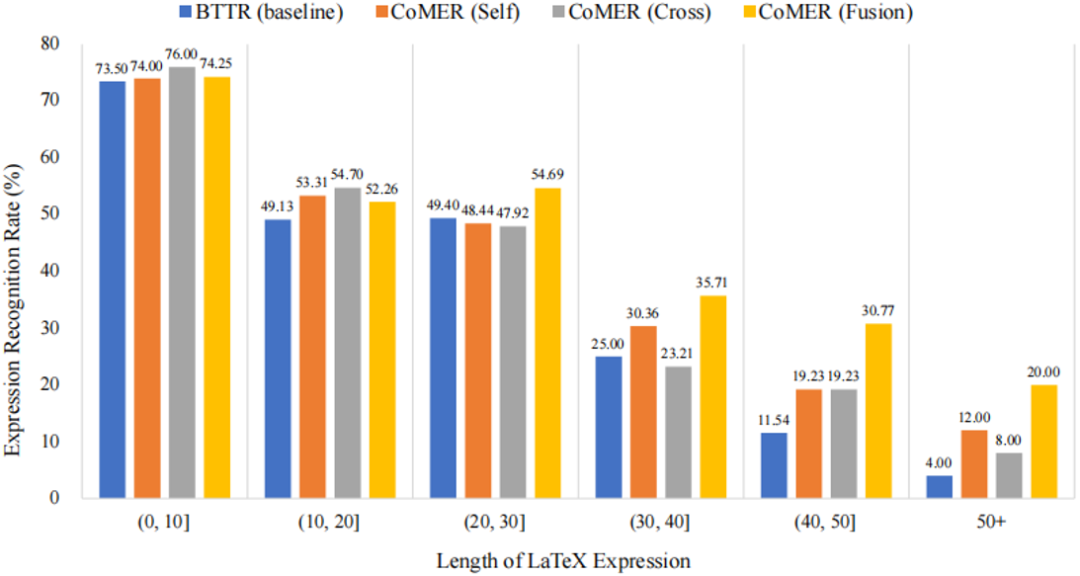
圖3 不同算法在CROHME 2014數據集上不同長度正確率的對比 從圖3中可以看到,相較于基準方法與本文提出的三種覆蓋方法,融合覆蓋可以大大增強模型對長公式的識別率。這也驗證了覆蓋機制能夠更好地引導注意力對齊歷史信息。
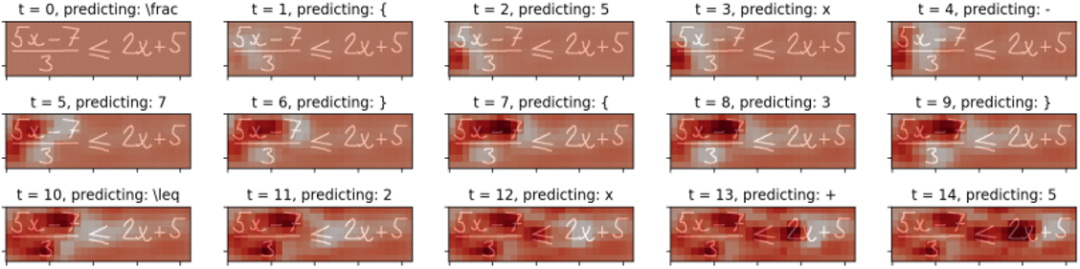
圖4 公式圖像識別中的精煉項R可視化。
如圖4所示,作者將識別過程中的精煉項R可視化。可以看到,經過解析的區域顏色較深,這表明ARM將抑制這些解析區域的注意權重,鼓勵模型關注未解析區域。可視化實驗表明,作者提出的ARM可以有效地緩解覆蓋不足的問題。
四、總結及討論
作者受RNN中覆蓋注意力的啟發,提出將覆蓋機制引入到Transformer解碼器中。提出了一種新的注意精煉模塊(ARM),使得在Transformer中進行注意力精煉的同時不損害其并行計算特性成為可能。同時還提出了自覆蓋、交叉覆蓋和融合覆蓋的方法,利用來自當前層和前一層的過去對齊信息來優化注意權重。實驗證明了作者提出的CoMER緩解了覆蓋不足的問題,顯著提高了長表達式的識別精度。作者認為其提出的注意精煉框架不僅適用于手寫數學表達式識別。ARM可以幫助精煉注意權重,提高所有需要動態對齊的任務的對齊質量。為此,作者打算將解碼器中的ARM擴展為一個通用框架,用于解決未來工作中的各種視覺和語言任務(例如,機器翻譯、文本摘要、圖像字幕)。
原文作者: Wenqi Zhao, Liangcai Gao
審核編輯:郭婷
-
解碼器
+關注
關注
9文章
1143瀏覽量
40755 -
ARM
+關注
關注
134文章
9098瀏覽量
367691 -
編碼器
+關注
關注
45文章
3645瀏覽量
134568
發布評論請先 登錄
相關推薦
一種基于因果路徑的層次圖卷積注意力網絡

Llama 3 模型與其他AI工具對比
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
llm模型有哪些格式
Transformer模型在語音識別和語音生成中的應用優勢
神經網絡在數學建模中的應用
Transformer 能代替圖神經網絡嗎?

【大規模語言模型:從理論到實踐】- 閱讀體驗
采用單片超構表面與元注意力網絡實現快照式近紅外光譜成像

視覺Transformer基本原理及目標檢測應用
基于Transformer的多模態BEV融合方案
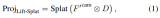
labview公式波形里的公式
語言模型的弱監督視頻異常檢測方法





 工商網監
工商網監
評論