 如何在NVIDIA GPU上實現基于embedding 的深度學習模型
如何在NVIDIA GPU上實現基于embedding 的深度學習模型
Embedding 在深度學習推薦模型中起著關鍵作用。它們被用于將輸入數據中的離散特征映射到向量,以便下游的神經網絡進行處理。Embedding 通常構成深度學習推薦模型中的大部分參數,大小可以達到 TB 級。在訓練期間,很難將它們放入單個 GPU 的內存中。因此,現代推薦系統可能需要模型并行和數據并行的分布式訓練方法組合,以最佳利用 GPU 計算資源來實現最好的訓練性能。
NVIDIA Merlin Distributed-Embeddings,可以方便TensorFlow 2 用戶用短短幾行代碼輕松完成大規模的推薦模型訓練。
背景
在數據并行分布式訓練中,整個模型被復制到每個 GPU 上。在訓練過程中,一批輸入數據在多個 GPU 中分割,每張卡獨立處理其自己的數據分片,從而允許計算擴展到更大批量的數據。在反向傳播期間,計算的梯度通過 reduction 算子(例如, horovod.tensorflow.allreduce ) 來同步更新多個 GPU 間的參數。
另一方面,模型并行分布式訓練中,模型參數被分割到多個 GPU 上。這種方法更適合分布存儲大型 embedding。訓練中,每個 GPU 通過 alltoall 通信算子(例如, horovod.tensorflow.alltoall) 訪問不在本機中的參數。
在之前的相關文章中, 用 TensorFlow 2 在 DGX A100 上訓練 100B + 參數的推薦系統 , Tomasz 討論了如何將 1130 億參數的 DLRM 模型中的 embedding 分布到多個 NVIDIA GPU 進行訓練,并相比純 CPU 的方案實現 672 倍的性能提升。這一重大突破可以將訓練時間從幾天縮短到幾分鐘!這是通過模型并行 embedding 層和數據并行 MLP 層來實現的。和 CPU 方案相比,這種混合并行的方法能夠有效利用 GPU 的高內存帶寬加速內存受限的 embedding 查找,并同時利用多個 GPU 的算力加速 MLP 層。作為參考, NVIDIA A100-80GB GPU 具有超過 2 TB / s 的帶寬和 80 GB HBM2 存儲)。
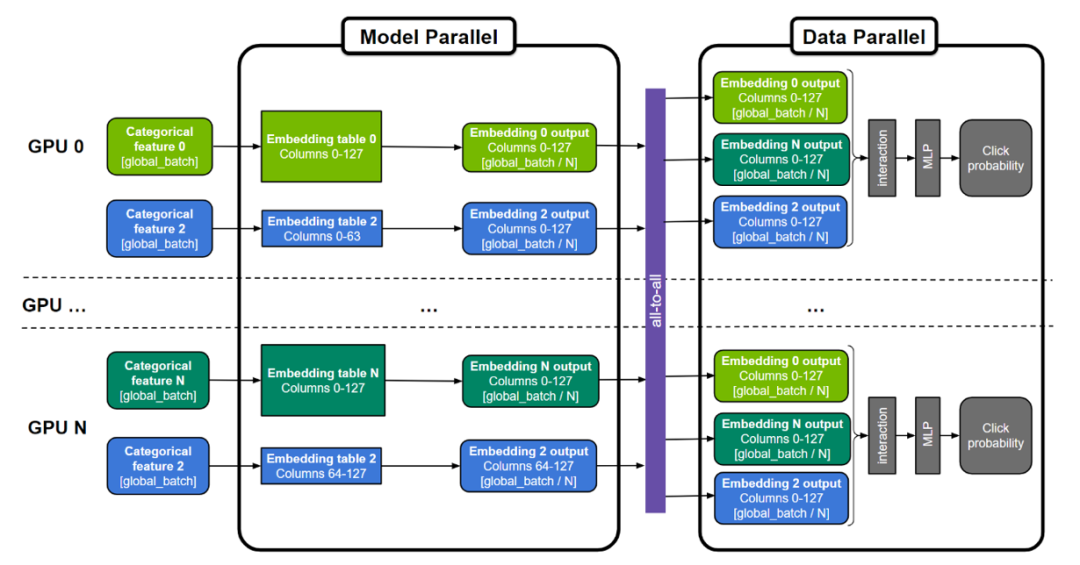
圖 1. 用于訓練大型推薦系統的通用“混合并行”方法
embedding 表可以按表為分割單位(圖中表 0 和 N ),按“列”分割(圖中表 2),或者按”行”分割。MLP 層跨所有 GPU 復制,而數字特征則可以直接輸入 MLP 層。
然而,實現這種復雜的混合并行訓練方法并不簡單,需要領域內專家設計數百行底層代碼來開發和優化。為了使其更普適,NVIDIA Merlin Distributed-Embeddings 提供了一些易于使用的 TensorFlow 2 的封裝,讓所有人都只需三行 Python 代碼即可輕松實現模型并行。它提供了一些涵蓋并拓展原生 TensorFlow 功能的高性能 embedding 查找算子。在此基礎上,它提供了一個可規模化的模型并行封裝函數,幫助用戶自動將 embedding 分布于多個 GPU 上。下面將展示它如何實現混合并行。
分布式模型并行
NVIDIA Merlin Distributed-Embeddings 提供了
distributed_embeddings.dist_model_parallel 模塊。它有助于在多個 GPU 之間分布embedding而無需任何復雜的代碼來處理跨GPU間的通信(如 all2all )。下面的代碼示例顯示了此 API 的用法:

要使用 Horovod 以數據并行方式運行 MLP 層,請將 Horovod的 Distributed GradientTape 和 broadcast 方法替換成 NVIDIA Merlin Distributed-Embeddings 里同等的 API。以下示例直接取自 Horovod 文檔,并進行了相對應修改。
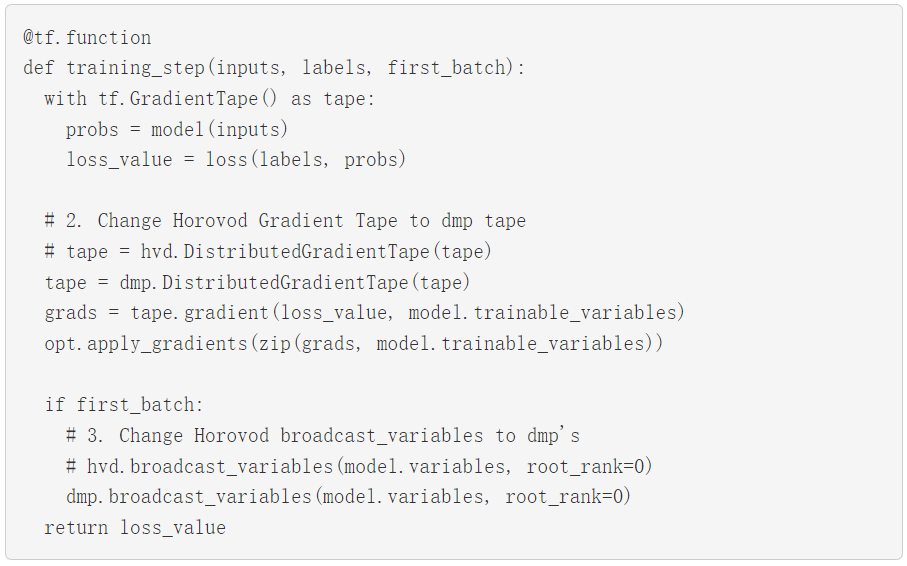
通過這些微小的改變,您就可以使用混合并行訓練了!
我們還提供了以下完整示例: 使用 Criteo 1TB 點擊日志數據訓練 DLRM 模型以及擴展到 22.8 TiB 的合成數據模型。
性能
為了展示 NVIDIA Merlin Distributed-Embeddings 的性能,我們在 Criteo 1TB 數據集 DLRM 模型和最高達到 3 TiB embedding 的合成模型上進行了模型訓練的基準測試。
Criteo 數據集上的 DLRM 模型基準測試
測試表明,我們使用更簡單的 API 取得了近似于專家代碼的性能。NVIDIA 深度學習 DLRM TensorFlow 2 示例代碼現已更新為使用 NVIDIA Merlin Distributed-Embeddings 進行分布式混合并行訓練,更多信息請參閱我們之前的文章, 用 TensorFlow 2 在 DGX A100 上訓練 100B + 參數的推薦系統。README 中的基準測試部分提供了對性能結果的更多詳述。
我們對 1130 億個參數( 421 個 GiB 大小)的 DLRM 模型在 Criteo TB 點擊日志數據集上用三種不同的硬件設置進行了訓練:
僅 CPU 的解決方案。
單 GPU 解決方案,其中 CPU 內存用于存儲最大的 embedding 表。
使用 NVIDIA DGX A100-80GB 的 8 GPU 的混合并行解決方案。此方案利用了 NVIDIA Merlin Distributed-Embeddings 里提供的模型并行 api 和 embedding API 。
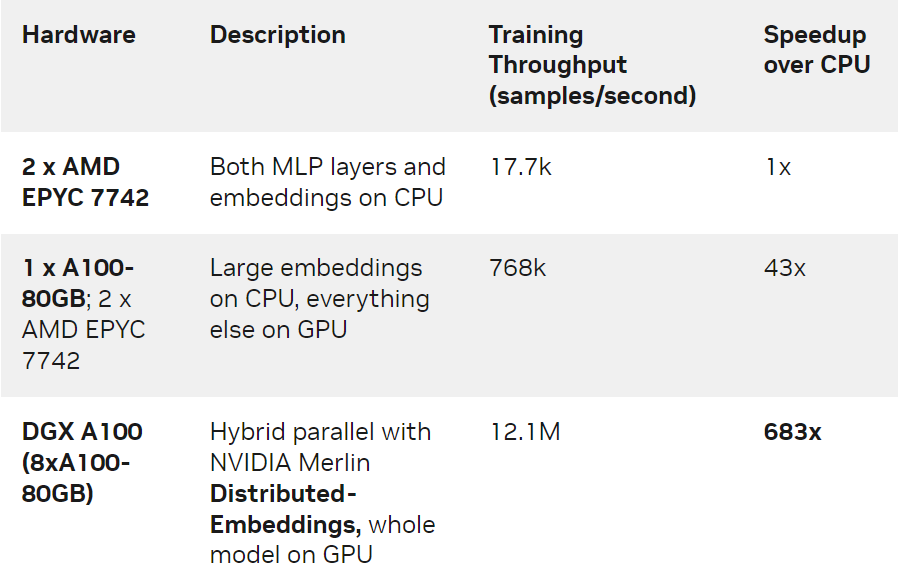
表 1. 各種設置的培訓吞吐量和加速
我們觀察到, DGX-A100 上的 NVIDIA Merlin Distributed-Embeddings 方案比僅使用 CPU 的解決方案提供了驚人的 683 倍的加速!我們還注意到與單 GPU 方案相比,混合并行的性能也有顯著提升。這是因為在 GPU 顯存中存儲所有 embedding 避免了通過 CPU-GPU 接口查找 embedding 的開銷。
合成模型基準測試
為了進一步演示方案的可規模化,我們創建了不同大小的合成數據以及對應的 DLRM 模型(表 2 )。有關模型生成方法和訓練腳本的更多信息,請參見 GitHub NVIDIA-Merlin/distributed-embeddings 代碼庫。
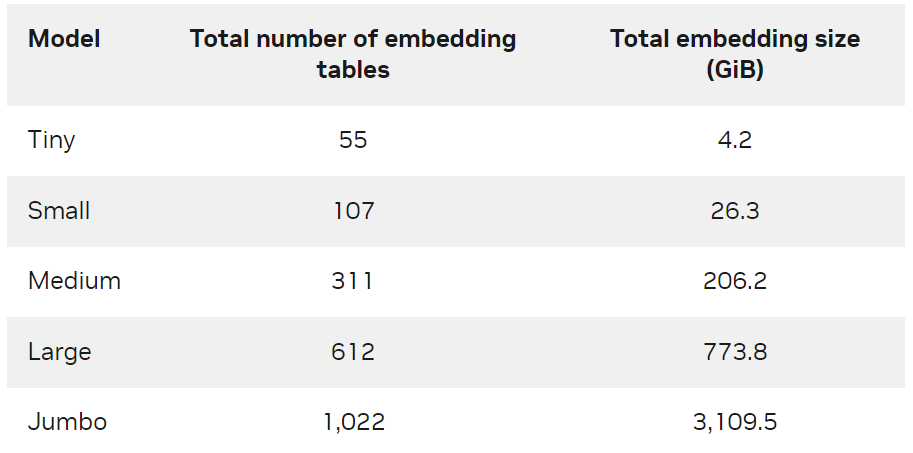
表 2. 合成模型尺寸
每個合成模型使用一個或多個 DGX-A100-80GB 節點進行訓練,全局數據 batch 大小為 65536 ,并使用 Adagrad 優化器。從表 3 中可以看出, NVIDIA Merlin Distributed-Embeddings 可以在數百個 GPU 上輕松訓練 TB 級模型。
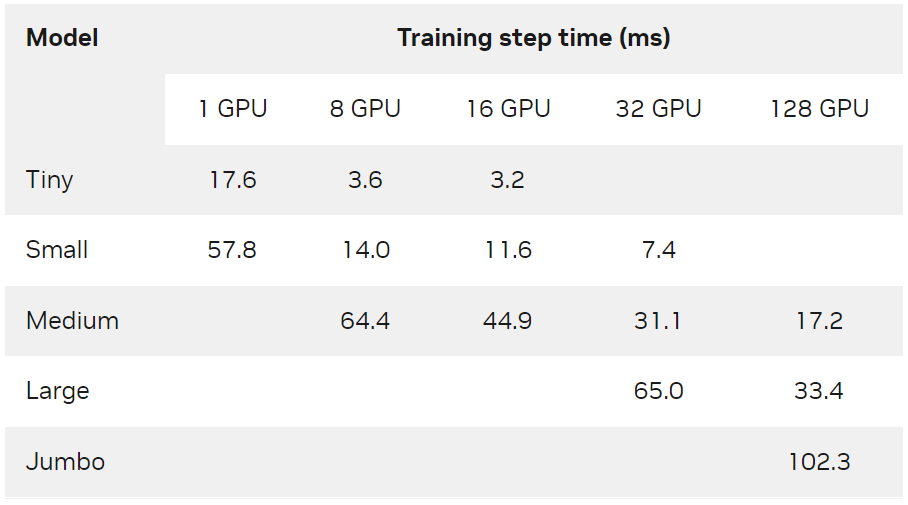
表 3. 各種硬件配置下合成模型的訓練步長時間( ms )
另一方面,與傳統的數據并行相比,即使對于可以容納在單個 GPU 中的模型,多 GPU 分布式模型并行仍然提供了顯著加速。表 4 顯示了上述 Tiny 模型在 DGX A100-80GB 上的性能對比。
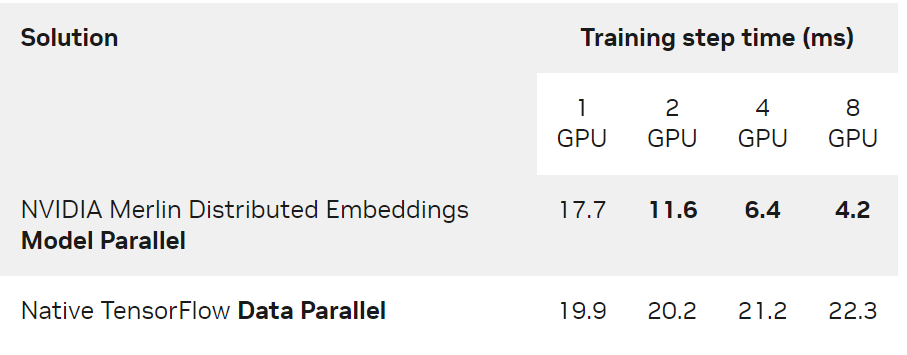
表 4. Tiny模型( 4.2GiB )的訓練步長時間( ms )比較 NVIDIA Merlin Distributed-Embeddings 模型并行和原生 TensorFlow 數據并行
本實驗使用了 65536 的全局批量和 Adagrad 優化器。
結論
在這篇文章中,我們介紹了 NVIDIA Merlin Distributed-Embeddings,僅需幾行代碼即可在 NVIDIA GPU 上實現基于 embedding 的深度學習模型,并進行可規模化,高效率地模型并行訓練。歡迎嘗試以下使用合成數據的可擴展訓練示例和基于 Criteo 數據訓練 DLRM 模型示例。
-
NVIDIA
+關注
關注
14文章
4981瀏覽量
102999 -
gpu
+關注
關注
28文章
4729瀏覽量
128902 -
模型
+關注
關注
1文章
3229瀏覽量
48813 -
深度學習
+關注
關注
73文章
5500瀏覽量
121118
原文標題:NVIDIA Merlin Distributed-Embeddings 輕松快速訓練 TB 級推薦模型
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在深度學習應用中或將取代GPU
如何在vGPU環境中優化GPU性能
labview調用深度學習tensorflow模型非常簡單,附上源碼和模型
Nvidia GPU風扇和電源顯示ERR怎么解決
在Ubuntu上使用Nvidia GPU訓練模型
Mali GPU支持tensorflow或者caffe等深度學習模型嗎
什么是深度學習?使用FPGA進行深度學習的好處?
NVIDIA GPU加快深度神經網絡訓練和推斷
何時使用機器學習或深度學習
深度學習如何挑選GPU?

學習資源 | NVIDIA TensorRT 全新教程上線






 工商網監
工商網監
評論