

摘要
大家好,今天為大家?guī)淼奈恼?Deep Patch VisualOdometry 我們提出了一種新的單目視覺里程計深度學習系統(tǒng)(Deep Patch Visual Odometry, DPVO)。DPVO在一個RTX-3090 GPU上僅使用4GB內(nèi)存,以2 -5倍的實時速度運行時是準確和健壯的。我們在標準基準上進行評估,并在準確性和速度上超越所有之前的工作(經(jīng)典的或?qū)W習過的)。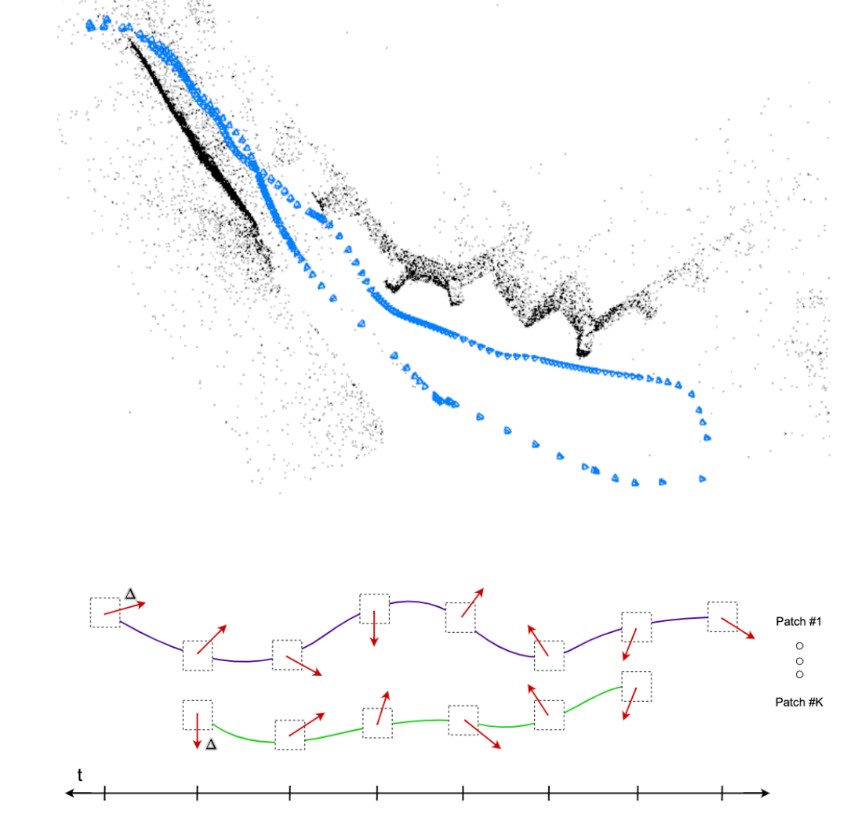
圖1 深度斑塊視覺里程計(DPVO)。相機姿態(tài)和稀疏三維重建(上)是通過迭代修正補丁軌跡隨著時間
主要工作與貢獻
與之前的深度學習系統(tǒng)相比,我們的方法的新穎之處在于在單一體系結(jié)構(gòu)中緊密集成了三個關(guān)鍵成分:(1)基于補丁關(guān)聯(lián),(2)循環(huán)迭代更新,(3)可微束調(diào)整。基于補丁的關(guān)聯(lián)提高了密集流的效率和魯棒性。循環(huán)迭代更新和可區(qū)分的bundle調(diào)整允許端到端學習可靠的特征匹配。 DPVO準確、高效、實現(xiàn)簡單。
在顯卡(RTX-3090)上,它只需要4GB內(nèi)存就能運行2倍實時。我們還提供了一個在EuRoC數(shù)據(jù)集[2]上以100fps運行的模型,同時仍然優(yōu)于之前的工作。對于每一幀,運行時間是恒定的,不依賴于相機運動的程度。該系統(tǒng)的實現(xiàn)非常簡單,代碼量非常少。無需對底層VO實現(xiàn)或邏輯進行任何必要的更改,就可以輕松地交換新的網(wǎng)絡(luò)架構(gòu)。我們希望DPVO可以作為未來深度VO和SLAM系統(tǒng)發(fā)展的試驗臺。
算法流程
我們的網(wǎng)絡(luò)是在線訓練和評估的。一個接一個地添加新的幀,并在關(guān)鍵幀的局部窗口中進行優(yōu)化。我們的方法有兩個主要模塊:patch提取器(3.1)和更新模塊(3.2)。補丁提取器從傳入幀中提取稀疏的圖像補丁集合。更新模塊試圖通過使用循環(huán)神經(jīng)網(wǎng)絡(luò)跟蹤這些補丁與包調(diào)整交替迭代更新。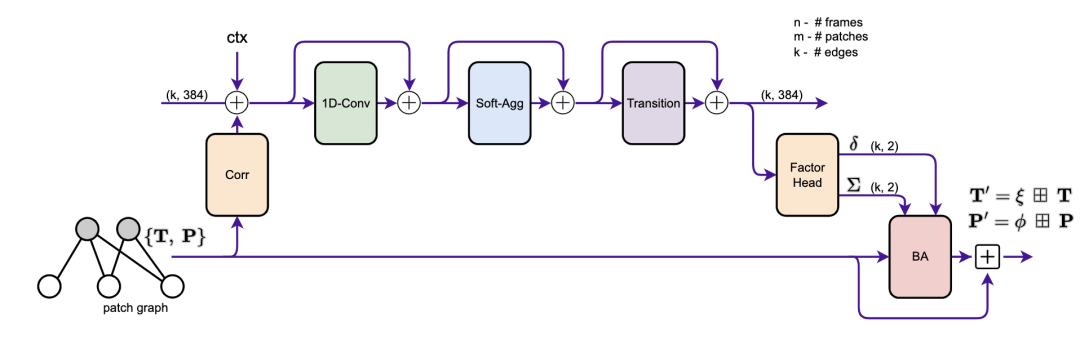
圖2 更新操作符的原理圖。從補丁圖的邊緣提取相關(guān)特征,并與上下文特征一起注入到隱藏狀態(tài)中。我們應(yīng)用了卷積、消息傳遞和轉(zhuǎn)換塊。因子頭產(chǎn)生軌跡修正,由束調(diào)整層用于更新相機姿勢和補丁深度。
2. 方法
我們介紹了DPVO,一種新的基于補丁的深度VO系統(tǒng),它克服了這些限制。我們方法的核心部分是深度補丁表示(圖1)。我們使用神經(jīng)網(wǎng)絡(luò)從傳入幀中提取補丁集合。然后使用循環(huán)神經(jīng)網(wǎng)絡(luò)跟蹤每個補丁通過時間交替補丁軌跡更新與可微束調(diào)整層。我們在合成數(shù)據(jù)上對整個系統(tǒng)進行端到端訓練,但在真實視頻上表現(xiàn)出很強的泛化能力。
2.1 特征和補丁提取
我們使用一對殘差網(wǎng)絡(luò)從輸入圖像中提取特征。一個網(wǎng)絡(luò)提取匹配特征,另一個網(wǎng)絡(luò)提取上下文特征。每個網(wǎng)絡(luò)的第一層是一個跨步2的7 × 7卷積,后面是兩個1/2分辨率的剩余塊(維64)和兩個1/4分辨率的剩余塊(維128),這樣最終的特征映射是輸入分辨率的1/4。匹配網(wǎng)絡(luò)和上下文網(wǎng)絡(luò)的結(jié)構(gòu)是相同的,除了匹配網(wǎng)絡(luò)使用實例規(guī)格化,而上下文網(wǎng)絡(luò)不使用規(guī)格化。
我們用一個四乘四步濾波器對匹配特征進行平均池化,構(gòu)建了一個兩級特征金字塔。我們?yōu)槊恳粠鎯ζヅ涞奶卣鳌4送猓覀冞€從匹配和上下文特征映射中提取補丁。在隨機抽取斑塊質(zhì)心的基礎(chǔ)上,采用雙線性插值方法進行特征提取。 與DROID-SLAM不同的是,我們從未顯式地構(gòu)建相關(guān)卷。相反,我們同時存儲幀和補丁特征映射,這樣相關(guān)特征就可以實時計算
2.2 更新操作
更新操作符的目的是更新姿勢和補丁。這是通過修改patch軌跡來實現(xiàn)的,如圖1所示。我們在圖2中提供了操作符的概覽示意圖,并詳細介紹了下面的各個組件。圖中的每個“+”操作都是一個殘留連接,然后是層歸一化。更新操作符作用于補丁圖,補丁圖中的每條邊都用一個隱藏狀態(tài)(維度為384)進行擴充。當添加一條新邊時,隱藏狀態(tài)初始化為0。
2.2.1 關(guān)聯(lián)操作
對于補丁圖中的每條邊(i, j),我們計算相關(guān)特征。我們首先使用Eqn. 2對幀j中的patch i進行重投影:xij = ωij(T, P)。給定patch特征g∈Rp×p×D,幀特征f∈RH×W ×D,對于patch i中的每個像素(u, v),我們計算其與幀j中像素(u, v)重投影為中心的像素網(wǎng)格的相關(guān)性,使用內(nèi)積: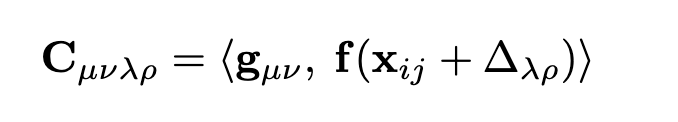
2.2.2 可微的束調(diào)整
圖2中的這一層在補丁圖上全局運行,并輸出深度和相機姿勢的更新。預測因子(δ, Σ)用于定義優(yōu)化目標 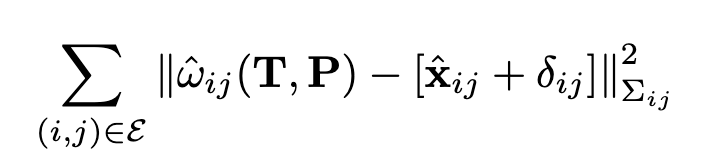
2.2 訓練與監(jiān)督
DPVO是使用PyTorch實現(xiàn)的。我們用TartanAir數(shù)據(jù)集訓練我們的網(wǎng)絡(luò)。在每個訓練序列上,我們使用地面真值姿態(tài)和深度來預計算所有幀對之間的光流大小。在訓練過程中,我們對幀對幀光流大小在16px到72px之間的軌跡進行采樣。這確保了訓練實例通常是困難的,但不是不可能的。 我們對姿態(tài)和光流(即軌跡更新)進行監(jiān)督,監(jiān)督更新操作符的每個中間輸出,并在每次更新之前從梯度帶中分離姿態(tài)和補丁。
2.2.2 pose監(jiān)督
我們使用Umeyama對齊算法[30]縮放預測軌跡以匹配地面真相。然后對每一對姿態(tài)(i, j)進行誤差監(jiān)督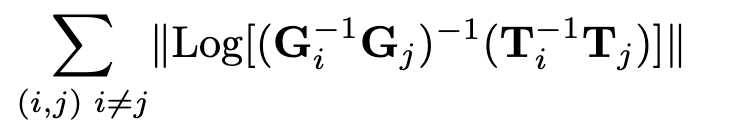
2.2.3 Flow監(jiān)督
此外,我們還監(jiān)測了每個補丁和幀之間的誘導光流和地真光流之間的距離,從每個補丁被提取的幀的兩個時間戳。每個補丁誘導一個p×p流場。我們?nèi)∷衟 × p誤差中的最小值。
2.2.4訓練
我們訓練長度為15的序列。前8幀用于初始化,后7幀每次添加一幀。我們在訓練期間展開更新操作符的18次迭代。對于前1k的訓練步驟,我們用地面真相固定姿勢,只要求網(wǎng)絡(luò)估計補丁的深度。然后,該網(wǎng)絡(luò)被要求估計姿勢和深度。 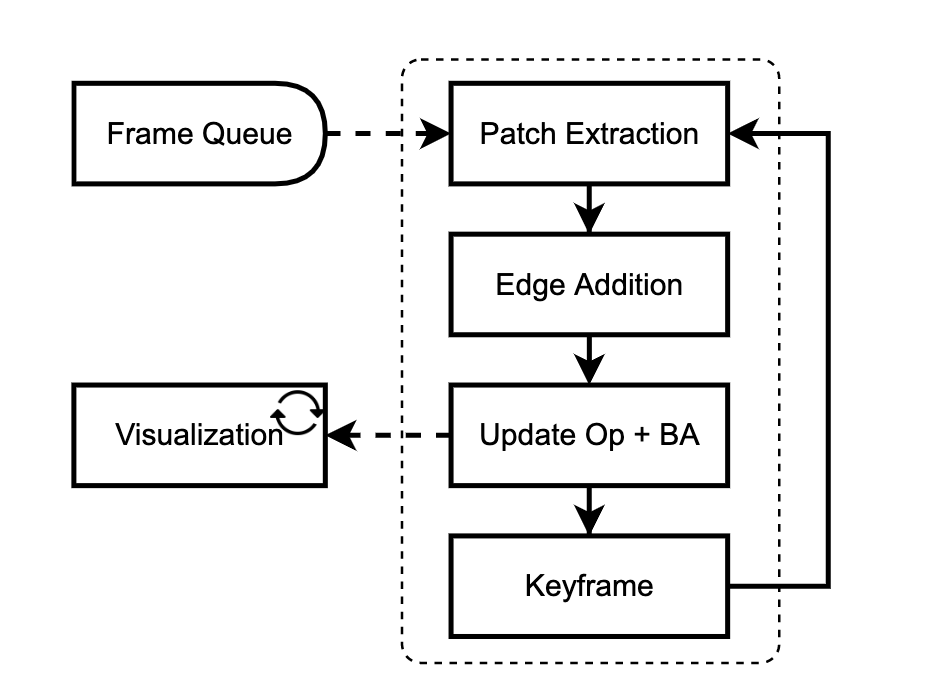
圖3 VO系統(tǒng)概述。
2.3 VO System
在本節(jié)中,我們將介紹將我們的網(wǎng)絡(luò)變成一個完整的可視化里程表系統(tǒng)所必需的幾個關(guān)鍵實現(xiàn)細節(jié)。系統(tǒng)的邏輯主要用Python實現(xiàn),瓶頸操作如包調(diào)整和可視化用c++和CUDA實現(xiàn)。與其他VO系統(tǒng)相比,DPVO非常簡單,需要最少的設(shè)計選擇
初始化:我們使用8幀進行初始化。我們添加新的補丁和幀,直到累積了8幀,然后運行更新操作符的12次迭代。需要一些相機運動進行初始化;因此,我們只在前一幀中積累平均流量大小至少為8像素的幀。
擴展:當添加一個新框架時,我們提取特征和補丁。新框架的姿態(tài)初始化使用恒速運動模型。補丁的深度初始化為從前3幀中提取的所有補丁的中值深度。
優(yōu)化:在添加邊緣之后,我們運行更新操作符的一次迭代,然后是兩次包調(diào)整迭代。除了最后10個關(guān)鍵幀,我們修復了所有的姿勢。所有補丁的逆深度都是自由參數(shù)。一旦補丁落在優(yōu)化窗口之外,將從優(yōu)化中刪除。
關(guān)鍵幀:最近的3幀總是被作為關(guān)鍵幀。在每次更新之后,我們計算關(guān)鍵幀t?5和t?3之間的光流大小。如果小于64px,我們刪除t?4處的關(guān)鍵幀。當一個關(guān)鍵幀被移除時,我們在它的鄰居之間存儲相對的姿態(tài),這樣完整的姿態(tài)軌跡可以被恢復以進行評估
可視化:使用單獨的可視化線程交互式地可視化重構(gòu)。我們的可視化工具是使用穿山甲庫實現(xiàn)的。它直接從PyTorch張量中讀取,避免了所有不必要的內(nèi)存拷貝從CPU到GPU。這意味著可視化工具的開銷非常小——僅僅使整個系統(tǒng)的速度降低了大約10%。
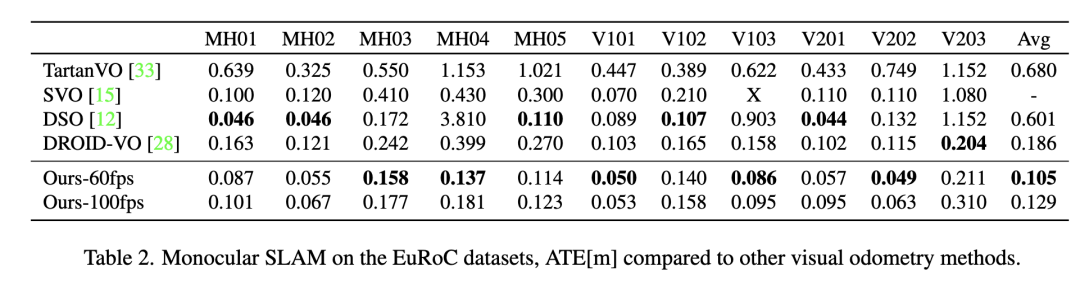
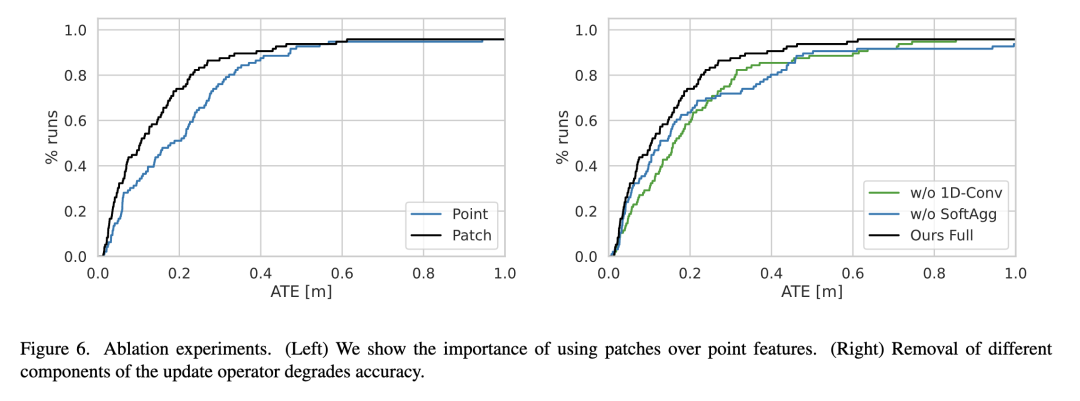
實驗結(jié)果
 ?
? 
圖4 示例重建:TartanAir(左)和ETH3D(右)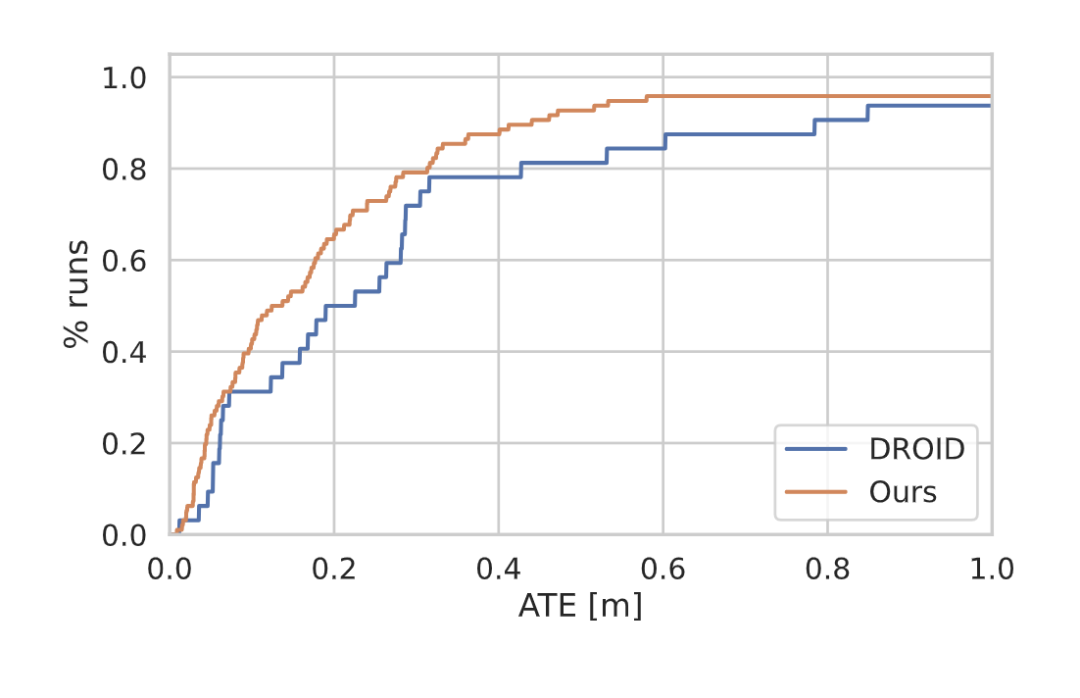
圖5 TartanAir[34]驗證分離的結(jié)果。我們的方法的AUC為0.80,而DROID-SLAM的AUC為0.71,運行速度是DROID-SLAM的4倍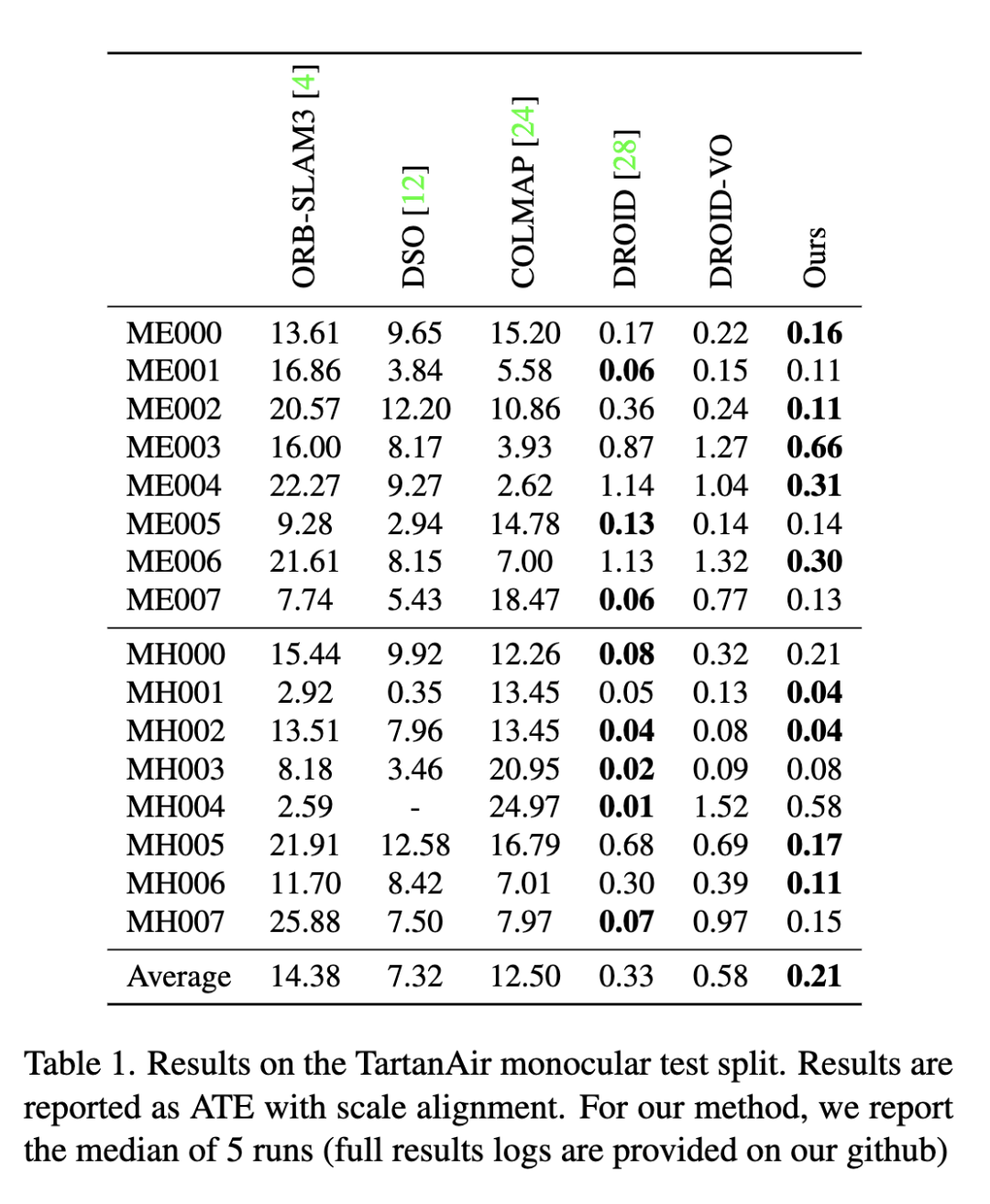
 ?
?
審核編輯:劉清
-
濾波器
+關(guān)注
關(guān)注
162文章
8004瀏覽量
180418 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4797瀏覽量
102222 -
gpu
+關(guān)注
關(guān)注
28文章
4881瀏覽量
130360 -
SLAM
+關(guān)注
關(guān)注
23文章
430瀏覽量
32238
原文標題:DPVO:深度patch視覺里程計(arXiv 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
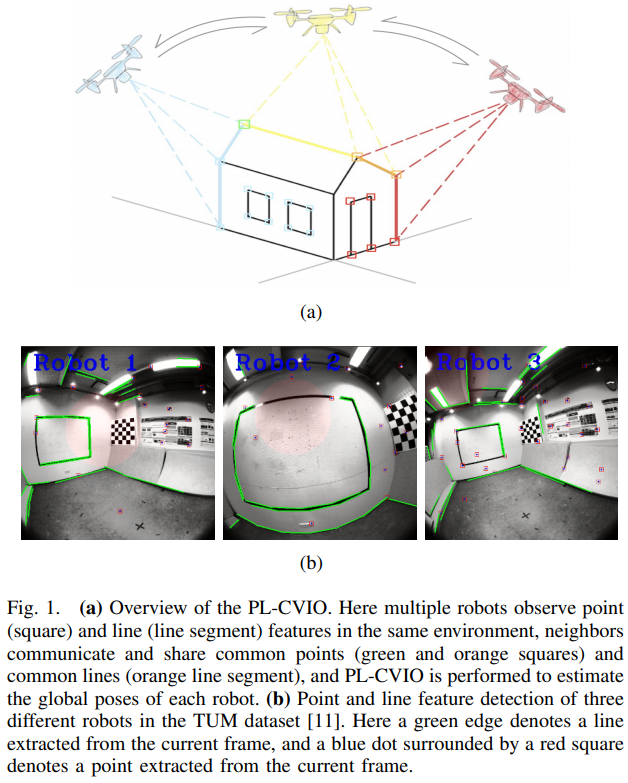
一種基于點、線和消失點特征的單目SLAM系統(tǒng)設(shè)計

【AIBOX 應(yīng)用案例】單目深度估計

用于任意排列多相機的通用視覺里程計系統(tǒng)
NPU在深度學習中的應(yīng)用
一種基于深度學習的二維拉曼光譜算法

基于旋轉(zhuǎn)平移解耦框架的視覺慣性初始化方法

AI干貨補給站 | 深度學習與機器視覺的融合探索

AI大模型與深度學習的關(guān)系
一種完全分布式的點線協(xié)同視覺慣性導航系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論