

世界正在朝著交互設備的智能和分布式計算模型發展。這些設備中的智能將由機器學習算法驅動。然而,將機器學習擴展到邊緣并非沒有挑戰。本文將討論這些挑戰的前景,然后描述神經形態 - 大腦啟發 - 計算將如何實現廣泛的智能應用來應對這些挑戰。提供了該技術的示例,包括手寫識別和連續語音識別。
世界正在朝著智能和分布式計算模式發展,其中數百萬智能設備將直接與他們的世界以及彼此進行交互和通信,以實現更快,響應更快,更智能的未來。這個世界將使一種新型的邊緣設備和系統成為可能,從可穿戴設備、智能燈泡、智能鎖到智能汽車和建筑,對任何中央協調或處理實體(如云)的需求最小。這個智能世界的核心是機器學習算法,這些算法在處理器上運行,這些處理器直接對這些設備收集的數據進行操作,以學習進行智能推理,并在動態變化的環境中實時有效地對其世界采取行動。
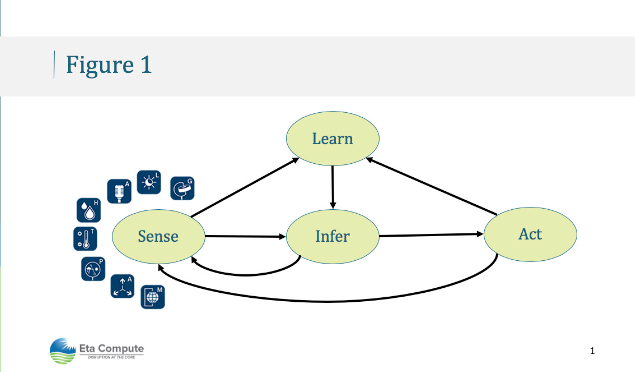
圖 1.具有學習、推理和快速交互能力的智能邊緣模型將使未來的智能設備成為可能。
在邊緣設備中啟用智能的模型基于在邊緣設備與環境和其他設備交互期間感知-學習-推斷-行動的能力(圖 1)。我們相信,使這些智能邊緣設備既敏捷(即快速響應)又高效(即從電源角度來看)的解決方案將主導這個動態變化和分布式的網絡傳感器和對象世界。但是,與任何新技術一樣,在邊緣提供低功耗智能時需要解決一些挑戰。我們回顧了一些關鍵挑戰,并討論了Eta計算如何努力解決這些問題。
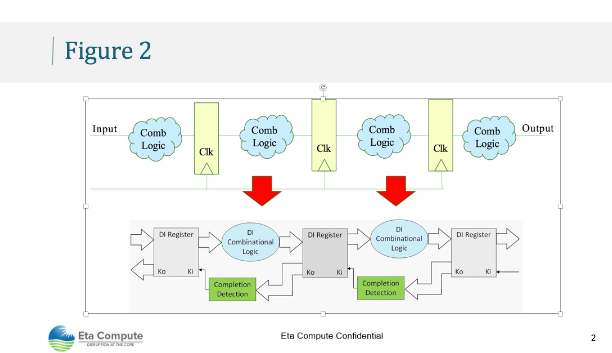
圖 2.DIAL技術可實現電壓調節,從而以無縫方式解決功耗和性能限制應用。
一個關鍵的挑戰是能夠在這些邊緣設備上使用非常有限的電源資源智能地處理數據。埃塔計算一直在開發一種名為DIAL的基礎技術。斷續器(即,延遲不敏感的異步邏輯)將傳統微處理器和數字信號處理器的操作從同步模式轉換為異步模式(即,沒有任何時鐘)。與傳統邏輯不同(參見圖 2),其基本原理是以事件驅動的方式運行處理器,在不通過握手協議使用時,可以按需喚醒以進行處理并進入睡眠狀態。此外,該處理器可以自動控制為以任務要求的最低頻率運行,并在該頻率下能夠將工作電壓縮放到盡可能小的值以運行任務。DIAL的一項重要創新是,電路設計中沒有面積損失,同時還提供了一種可正式驗證的方法來驗證電路功能是否正確。這些重要特性使 Eta Compute 能夠以業界最低的功率水平提供微處理器技術,并在工作頻率下提供約 10 μW/MHz 的擴展。執行電壓調節還可以實現高能效(即低功耗)和性能高效(即高吞吐量)計算任務之間的無縫轉換。
另一個重要的挑戰是能夠支持ML模型,這些模型可以直接在內存資源非常有限的設備上學習。此功能為許多應用程序提供了所需的隱私和安全性,同時還確保了與其環境的敏捷交互。今天解決這個問題的方法是使用深度學習模型和谷歌的TensorFlow等工具在云中訓練ML模型,然后將這些訓練的模型轉換為在邊緣運行的推理模型。
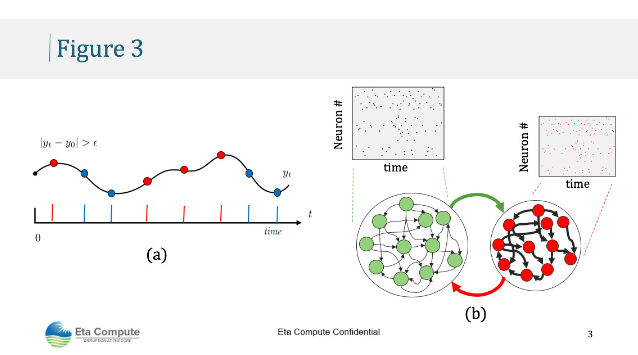
圖 3.SNN 模型中的核心思想。(a)從信息理論和能源效率的角度來看,基于事件的稀疏和離散的信號表示非常有效(b)興奮性(綠色)和抑制性(紅色)神經元之間的循環結構約束和平衡的峰值活動。
我們正在探索一種基于大腦計算或神經形態計算原理的新方法[1],既能夠直接從數據流中學習,又可以通過有限數量的訓練示例和有限的記憶要求來存儲所學知識。這里的基本思想是明確地表示數據/信號(圖3),方法是以動作電位或尖峰的形式合并時間,然后將芯片操作的異步模式(如上所述)與使用尖峰學習的異步模式相結合。峰值神經網絡 (SNN) 計算提供了非常稀疏的數據表示,并且使用 DIAL 實現起來非常節能,因為計算僅在出現峰值事件時才發生。此外,學習僅使用具有稀疏連接的本地學習規則來啟用,因此不像傳統的ML模型那樣參數密集,從而節省了存儲所需的內存和訓練模型所需的時間[2]。SNN的最后一個但同樣重要的方面是利用結構約束(圖3)對事件序列的存儲器進行編碼,以便快速學習,而無需在訓練期間進行多個數據演示。將模型的這些方面與由DIAL提供支持的處理器相結合,可以產生一個可以互換學習和推理的邊緣設備,從而實現敏捷的感知 - 學習 - 推斷 - 行為模型。
Eta Compute正在使用這項技術開發用于模式識別的實際應用程序,我們將討論兩個這樣的例子。首先是使用語音命令數據集 [3] 中的數據連續識別語音數字。此數據集由來自 2,300 個不同揚聲器的個位數音頻片段組成,總共 60000 個話語。我們的 SNN 使用每個訓練樣本的單次通過進行訓練,同時在測試集上實現了 95.2% 的準確率,可與其他 ML 模型相媲美。從模型效率的角度來看,我們的 SNN 模型的效率提高了幾個數量級(通過所需的訓練樣本數量和要學習的網絡參數數量來衡量),同時執行的準確性相當。
SNN還能夠泛化以在連續模式下穩健地識別數字,這是由于固有的短期記憶,可以可靠地檢測10位數話語的開頭,即使由于其他數字而重疊的頻譜圖也是如此。此模型已移植到我們的異步 Eta 核心芯片上。音頻從麥克風捕獲,并使用片上低功耗ADC進行數字化,數字化信號被轉換為頻譜圖,然后使用DSP編碼為尖峰。ARM M3 執行 SNN 計算(圖 4(a))。該型號的總內存為36 KB。從數據到決策(即包括I/O、DSP和M3)的總功耗為2 mW,推理速率為6-8字/秒。
同樣的原理應用于基于MNIST基準測試[4]的訓練數據的手寫數字識別問題。二進制圖像由 DSP 直接轉換為尖峰,同時在 M3 上執行 SNN 學習(圖 4(b))。該芯片在MNIST測試設備上實現了98.3%的精度,需要64 KB的內存。該解決方案需要 1 mW 的功率從數據到決策,吞吐量為 8 張圖像/秒。
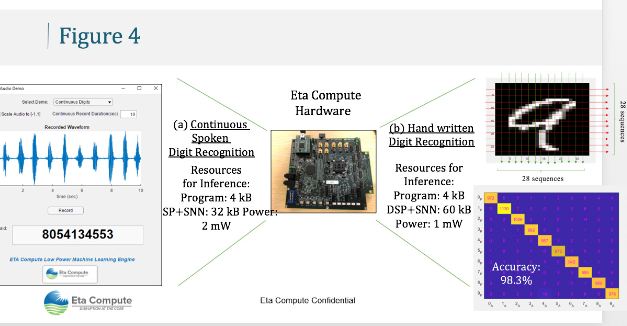
圖 4.我們的連續語音數字和手寫數字識別芯片實現具有很高的功率和內存效率,同時在準確性方面可與傳統ML模型相媲美。(a) 連續語音數字識別 (b) 手寫數字識別。
這些結果表明,正如 Gartner 集團所預測的那樣,實現智能、敏捷和高效的邊緣設備的潛力將推動快速擴張的物聯網市場,到 2020 年將有超過 250 億臺設備投入使用[5]。例如,其他基礎設施的共同開發,如設備互操作性標準和5G無線技術,可以使新的健身追蹤器能夠可靠地檢測用戶狀態,例如入睡,然后自動關燈。未來似乎正在向由智能和高效邊緣設備提供支持的智能和分布式計算模型邁進,Eta Compute正在開發新技術,以在其中發揮關鍵作用。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19723瀏覽量
232746 -
機器學習
+關注
關注
66文章
8478瀏覽量
133815
發布評論請先 登錄
相關推薦





 工商網監
工商網監

評論