

引言
大部分SLAM系統都應用了靜態環境假設,這使得它們難以在復雜動態環境中部署。此外,傳統的基于學習的SLAM方法往往都是利用目標檢測或語義分割剔除動態物體上的特征,但這樣有兩個弊端:其一是實際環境中的動態物體不一定被預訓練,另一是算法無法區分"動態物體"和"靜止但可能移動的物體"。
2. 摘要
基于學習的視覺里程計(VO)算法在常見的靜態場景中取得了顯著的性能,受益于高容量模型和大規模注釋數據,但在動態、人口稠密的環境中往往會失敗。語義分割主要用于在估計相機運動之前丟棄動態關聯,但是以丟棄靜態特征為代價,并且難以擴展到看不見的類別。
在本文中,我們利用相機自我運動和運動分割之間的相互依賴性,并表明這兩者可以在一個單一的基于學習的框架中共同優化。特別地,我們提出了DytanVO,第一個基于監督學習的VO方法來處理動態環境。它實時拍攝兩個連續的單目幀,并以迭代的方式預測相機的自我運動。
在真實動態環境中,我們的方法在ATE方面比最先進的VO解決方案平均提高了27.7%,甚至在優化后端軌跡的動態視覺SLAM系統中也具有競爭力。大量未知環境上的實驗也證明了該方法的普適性。
3. 算法分析
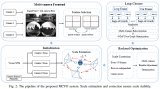
如圖1所示是作者提出的DytanVO的整體架構,整個網絡是基于TartanVO開發的。DytanVO由從兩幅連續圖像中估計光流的匹配網絡、基于無動態運動的光流估計位姿的位姿網絡和輸出動態概率掩碼的運動分割網絡組成。
匹配網絡僅向前傳播一次,而位姿網絡和分割網絡被迭代以聯合優化位姿估計和運動分割。停止迭代的標準很簡單,即兩個迭代之間旋轉和平移差異小于閾值,并且閾值不固定,而是預先確定一個衰減參數,隨著時間的推移,經驗地降低輸入閾值,以防止在早期迭代中出現不準確的掩碼,而在后期迭代中使用改進的掩碼。
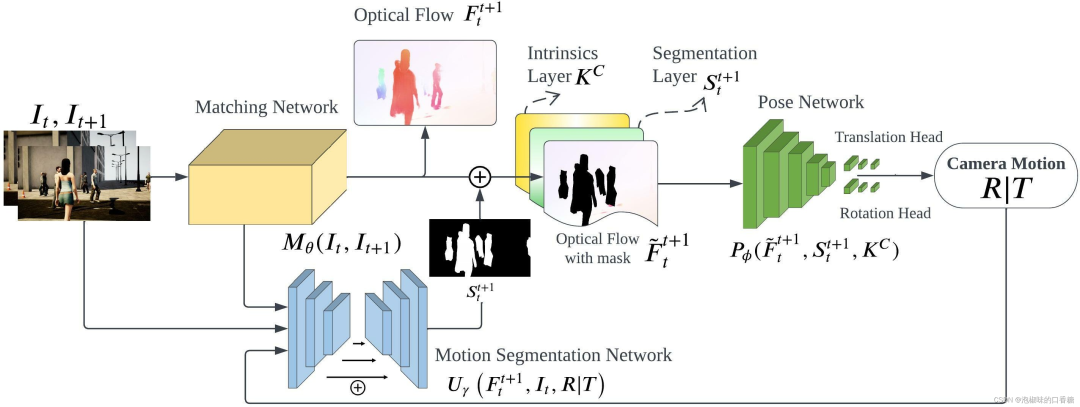
圖1 DytanVO架構總覽
如圖2所示是DytanVO是運行示例,包含兩個輸入的圖像幀、估計的光流、運動分割以及在高動態AirDOS-Shibuya數據集上的軌跡評估結果。結果顯示DytanVO精度超越TartanVO達到了最高,并且漂移量很小。
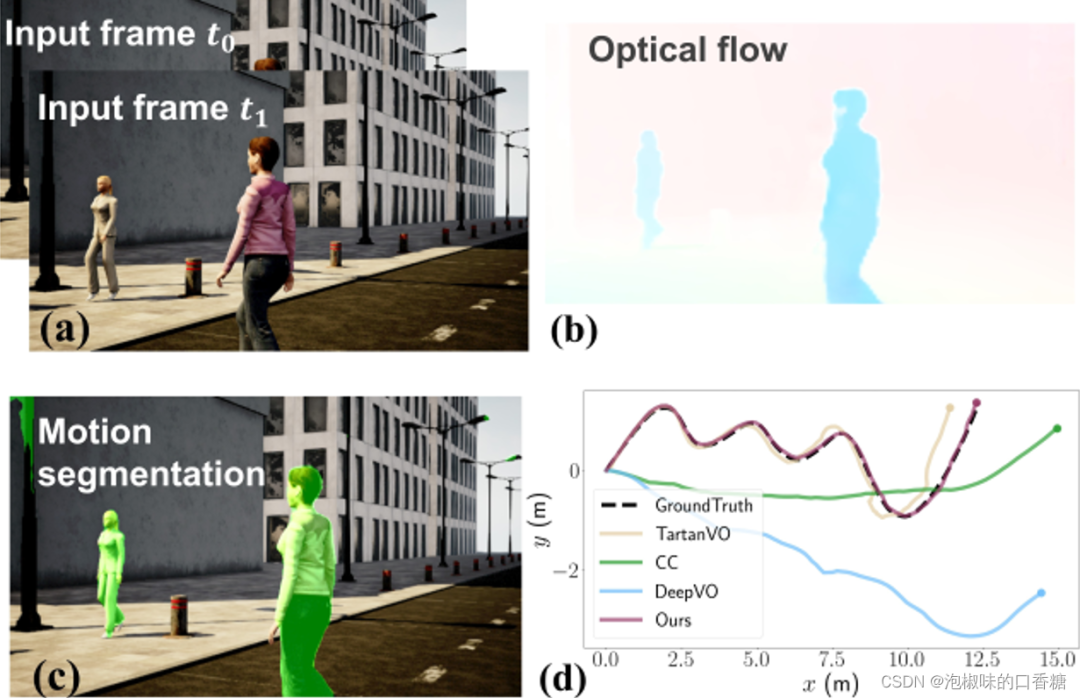
圖2 DytanVO運行示例
綜上所述,作者提出了第一個基于監督學習的動態環境的VO,主要貢獻如下:
(1) 引入了一種新的基于學習的VO來平衡相機自身運動、光流和運動分割之間的相互依賴關系。
(2) 引入了一個迭代框架,其中自我運動估計和運動分割可以在實時應用的時間限制內快速收斂。
(3) 在基于學習的VO解決方案中,DytanVO在真實世界動態場景中實現了最先進的性能,而無需微調。此外,DytanVO甚至可以與優化后端軌跡的視覺SLAM解決方案相媲美。
3.1 運動分割
早期使用運動分割的動態VO方法依賴于由對極幾何和剛性變換產生的純幾何約束,因此它們可以閾值化用于考慮運動區域的殘差光流。
然而,在兩種情況下,它們容易發生嚴重退化:
(1) 在3D移動中,沿著極線移動的點無法從單目圖像中識別出來;
(2) 純幾何學方法對噪聲光流和較不準確的相機運動估計沒有魯棒性。
因此,DytanVO通過光學擴展將2D光流升級到3D后,顯式地將代價地圖建模為分割網絡的輸入,該網絡根據重疊圖像塊的尺度變化估計相對深度。
3.2 相機運動迭代優化
在推理過程中,匹配網絡只前向傳播一次,而姿態網絡和分割網絡進行迭代,共同優化自運動估計和運動分割。在第一次迭代中,使用隨機初始化分割掩膜。直覺上會認為,在早期迭代過程中估計的運動不太準確,并導致分割輸出(對靜態區域賦予高概率)中的誤報。然而,由于光流圖仍然提供了足夠的對應關系,因此相機運動實際上較為合理。在以后的迭代中,估計越來越準確。
在實際應用中,3次迭代足以使相機運動和分割都得到細化。圖3所示是迭代過程中的可視化結果,第一次迭代時的掩碼包含了大量的假陽性,但在第二次迭代后迅速收斂。這也說明姿態網絡對分割結果中的假陽性具有魯棒性。
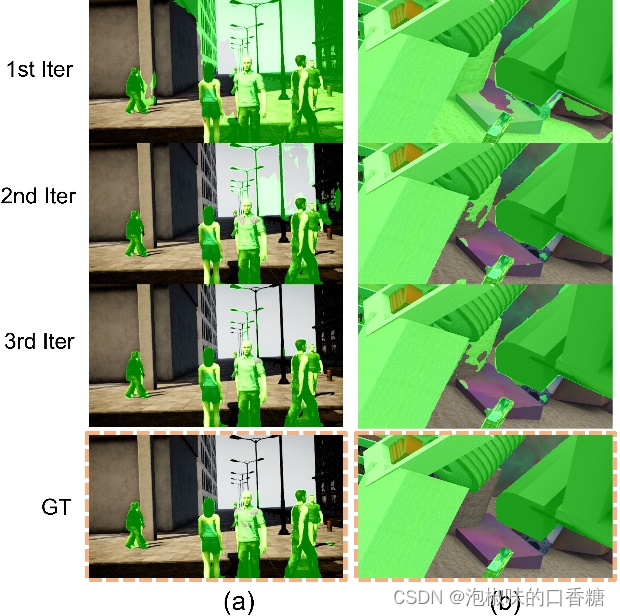
圖3 當未見數據上測試時每次迭代的運動分割輸出。(a) 使用DytanVO在多人向不同方向移動的情況下,對AirDOS-Shibuya中最難的序列進行推斷;(b) 從動態物體占據超過60%面積的FlyingThings3D推斷序列。
3.3 損失函數
DytanVO可以以端到端的方式進行訓練,損失函數包括光流損失LM,相機運動損失LP和運動分割損失LU。其中LM為預測流和真實流之間的L1范數,而LU是預測概率和分割標簽之間的二元交叉熵損失。具體表達形式為:
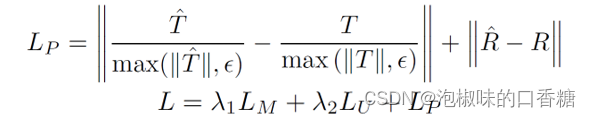
4. 實驗
4.1 數據集
DytanVO在TartanAir和SceneFlow上訓練,其中前者包含超過40萬個數據幀,具有僅在靜態環境中的光流和相機姿態真值。后者在高度動態的環境中提供了3.9萬幀,每個軌跡具有向后/向前通過、不同的對象和運動特征。雖然場景流不提供運動分割的真值,但可以通過利用其視差、光流和視差變化圖來恢復真值。而在評估方面,作者使用AirDOS-Shibuya和KITTI進行測試。
4.2 實施細節
DytanVO使用TartanVO的預訓練模型初始化匹配網絡,使用來自CVPR論文"Learning to segment rigid motions from two frames"的預訓練權重來固定運動分割網絡,使用ResNet50作為姿態網絡的backbone,并刪除了BN層,同時為旋轉和平移添加了兩個輸出頭。
DytanVO使用的深度學習框架為PyTorch,并在2臺NVIDIA A100上訓練。在推理時間方面作者在RTX 2080進行測試,不進行迭代的話推理時間為40ms,進行一次迭代推理時間為100ms,進行兩次迭代推理時間為160ms。
4.3 AirDOS-Shibuya數據集測試
如表1所示是關于迭代次數(iter)的消融實驗,數據使用來自AirDOS-Shibuya的三個序列。其中姿態網絡在第一次迭代后快速收斂,后續迭代顯示出較少的改進,這是因為AirDOS-Shibuya上的光流估計已經具有高質量。
表1 關于迭代次數的ATE消融實驗
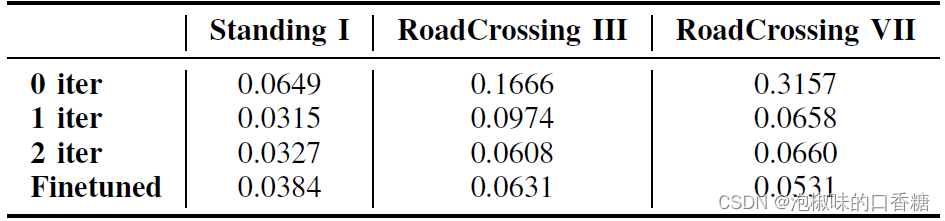
表2所示是在AirDOS-Shibuya的七個序列上,與現有的最先進的VO算法進行的定量對比結果。該基準涵蓋了更具挑戰性的多種運動模式。這七個序列分為三個難度等級:大多數人站著不動,很少人在路上走來走去,穿越(容易)包含多個人類進出相機的視野,而在穿越道路(困難)中,人類突然進入相機的視野。
除了VO方法之外,作者還將DytanVO與能夠處理動態場景的SLAM方法進行了比較。包括DROID-SLAM、AirDOS、VDO-SLAM以及DynaSLAM。
表2 來自AirDOS-Shibuya的動態序列的ATE (m)結果。最佳和次佳VO性能以粗體和下劃線顯示,"-"來表示初始化失敗
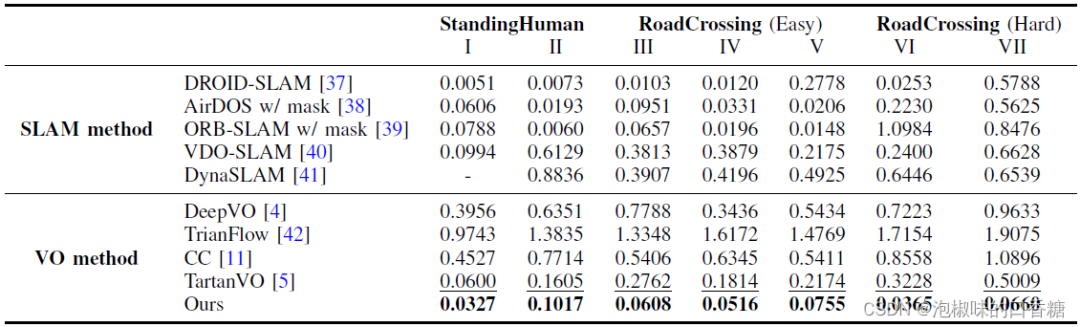
結果顯示,DytanVO在VO基線的所有序列中實現了最好的性能,甚至在SLAM方法中也是有競爭力的。DeepVO,TrianFlow和CC在AirDOS-Shibuya數據集上表現很差,因為它們只在KITTI上訓練,不能泛化。TartanVO表現更好,但它仍然容易受到動態對象的干擾。
DytanVO優于動態SLAM方法,如AirDOS,VDO-SLAM和dyna SLAM 80%以上。雖然DROID-SLAM在大部分時間都保持競爭力,但一旦行人占據了圖像中的大部分區域,它就會跟蹤失敗。此外,DytanVO的2次迭代每次推理0.16秒,但DROID- SLAM需要額外的4.8秒來優化軌跡。
4.4 KITTI數據集測試
表3所示是DytanVO和其他VO方法在KITTI數據集上的定量對比結果,DytanVO在8個動態序列中的6個中優于其他VO基線,比第二個最好的方法平均提高了27.7 %。注意,DeepVO、TrianFlow和CC是在KITTI中的部分序列上訓練的,而DytanVO沒有在KITTI上進行微調,純粹使用合成數據進行訓練。
此外,DytanVO在VO和SLAM中的3個序列上實現了最佳的ATE,無需任何優化。圖4中提供了關于快速移動的車輛或動態物體在圖像中占據大片區域的四個具有挑戰性的序列的定性結果。注意,從經過的高速車輛開始的序列01,ORB-SLAM和DynaSLAM都無法初始化,而DROID-SLAM從一開始就跟蹤失敗。在序列10中,當一輛巨大的貨車占據圖像中心的顯著區域時,DytanVO是唯一保持穩健跟蹤的VO。
表3 KITTI里程計動態序列的ATE (m)結果
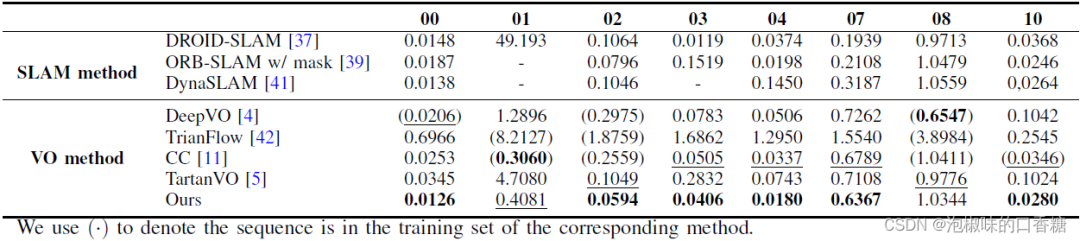
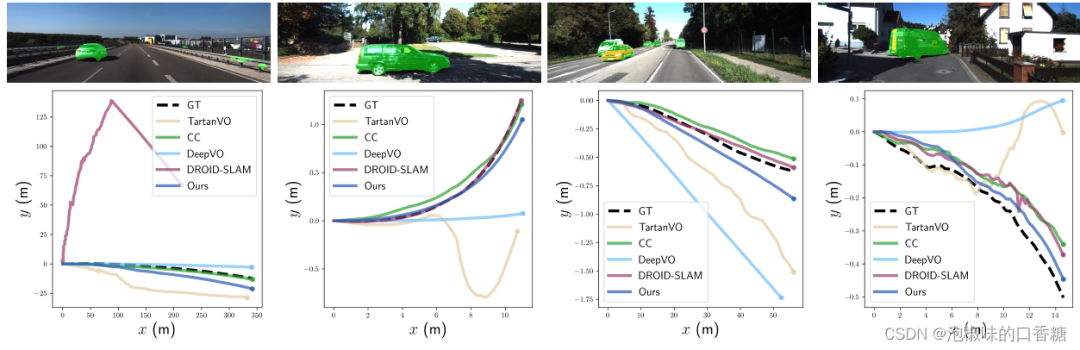
圖4 KITTI里程計01、03、04和10中動態序列的定性結果
5. 結論
作者提出了一種基于學習的動態VO (DytanVO),它可以聯合優化相機姿態的估計和動態物體的分割。作者證明了自運動估計和運動分割都可以在實時應用的時間約束內快速收斂,并在KITTI和AirDOS-Shibuya數據集上評估了DytanVO,還展示了在動態環境中的一流性能,無需在后端進行微調或優化。DytanVO為動態視覺SLAM算法引入了新的方向。
審核編輯:劉清
-
SLAM
+關注
關注
23文章
430瀏覽量
32155 -
ATE
+關注
關注
5文章
143瀏覽量
26935
原文標題:DytanVO:動態環境中視覺里程計和運動分割的聯合優化
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何理解SLAM用到的傳感器輪式里程計IMU、雷達、相機的工作原理與使用場景?精選資料分享
如何去實現一種送餐機器人產品設計
基于全景視覺與里程計的移動機器人自定位方法

視覺里程計的研究和論文資料說明免費下載
視覺里程計的詳細介紹和算法過程
視覺語義里程計的詳細資料說明

計算機視覺方向簡介之視覺慣性里程計
基于單個全景相機的視覺里程計
輪式移動機器人里程計分析
介紹一種基于編碼器合成里程計的方案

基于相機和激光雷達的視覺里程計和建圖系統
在城市地區使用低等級IMU的單目視覺慣性車輪里程計
用于任意排列多相機的通用視覺里程計系統





 工商網監
工商網監

評論