

人工智能 (AI) 通過比人類專家更快、更準確地檢測和測量異常情況,從圖像中進行先進的醫學診斷。構建適用于人群的高質量 AI 模型對于改善患者預后和個性化治療至關重要。然而,人工智能模型最近需要大量數據,以及機器可以從中學習的復雜數據集標簽。
今天,被稱為弱監督學習的深度學習 (DL) 的一個分支正在幫助醫生通過減少對完整、準確和準確數據標簽的需求,以更少的努力獲得更多的洞察力。弱監督學習通過利用更容易獲得的粗略標簽(例如在圖像級別而不是圖像中感興趣的分割)來工作,并允許使用預先訓練的模型和常見的可解釋性方法。在下文中,我們將研究管理數據如何在弱監督學習中發揮作用。
標記在醫學成像中很困難
標記圖像在醫療行業中尤其具有挑戰性。首先,標記數據既有限又難以獲得,因為醫學圖像和有關結果/結果的數據通常存儲在單獨的系統中。例如,來自計算機斷層掃描 (CT) 或磁共振成像 (MRI) 的圖像可能在醫院數據中可用,但活檢或腫瘤切除的結果通常存儲在病理實驗室——通常是醫院外的私人診所。盡管可以協調某些數據的數據和標簽,但訪問和匯總數據可能會變得非常耗時,尤其是在涉及多個私人診所時。
此外,在圖像中發現和標記疾病及其進展的跡象(稱為生物標志物)一直非常耗時且復雜,因為必須逐個像素地標記數據,從而產生數千個標簽。在期望算法分割圖像區域或產生區域的特定定位(例如病變或手術邊界)的應用中尤其如此。這通常成本高昂,因為通常需要專業知識,并且需要三個維度的標簽,如 MRI 和 CT 圖像體積。將這兩個缺點加在一起,為成像數據生成標簽就成了一項昂貴的工作。這也限制了能夠外包標簽過程的可能性。
由于需要專業知識,標簽的質量可能會有所不同,并會影響 DL 模型的最終性能。標簽的準確性是這里的一個問題。通常,經驗不足的放射科醫生或住院醫師必須對數據進行注釋以進行培訓。與具有數十年工作經驗的臨床醫生相比,結果并不準確。讀者間和讀者內的可變性也發揮了作用。前者描述了讀者之間的注釋將如何略有不同。后者指的是當單個讀者要求在兩個不同的時間點分割圖像時,也會產生略有不同的結果。
最后,人工標記也會限制結果。機器學習的一個好處是該模型可以得出人類永遠無法獲得的見解,并且將標簽限制在人類輸入的內容上可能會限制結果。例如,人工智能只會學習復制人類對某些任務的想法,這意味著它們可以無意中復制特定人類的偏見。此外,輸入數據的其他區域中的其他特征可以預測但被丟棄,因為它們不直接落在選定的感興趣區域內。例如,疾病跡象可能在周圍組織或附近的不同器官中很明顯。
利用弱監督學習
在這些情況下,使用更粗略的標簽通常更有益,例如圖像是否包含癌癥或其他感興趣的疾病,并允許模型找到最具辨別力的特征(圖 1)。這就是弱監督學習的用武之地。
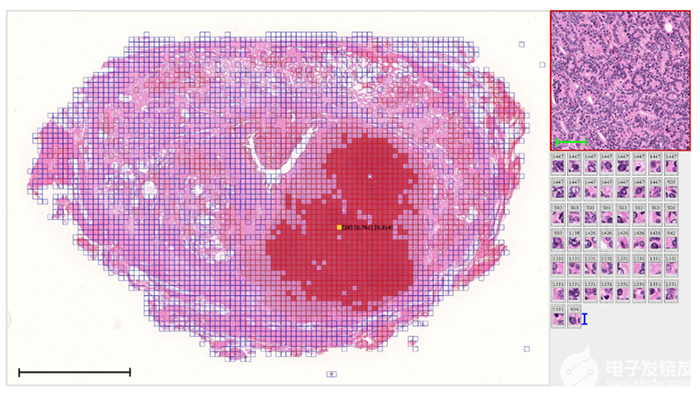
圖 1:使用弱監督學習的自動注釋示例,其中 AI 發現了病理學家未檢測到的預測特征。(來源:病理信息學團隊,RIKEN 高級智能項目中心)
弱監督學習描述了 DL 的一個分支,旨在減少生成性能良好的 DL 模型所需的標簽數量或詳細程度。這種方法可以大致分為三大類:不完整、不準確和不準確的標簽。此處使用“大致”一詞是因為可以在單個數據集中使用多種標記方法,并且弱監督標記旨在幫助根據需要進行任何組合:
當數據集的一部分被標記時,通常會出現不完整的標簽,而其余部分則沒有。
不精確的標簽包括使用圖像的整體結果而不需要分割特定的感興趣區域。
不準確的標簽,源于人類缺乏專業知識以及某些疾病指標之間的模糊或不確定性。
有趣的是,如果可以使用更粗略、更容易獲得的標簽來產生良好的結果,那么不精確的標簽可能比不完整或不準確的標簽更有用。不精確的標簽更容易正確,因為它們不需要與其他標簽相同的詳細程度,而且它們通常更容易獲得,例如從報告中提取癌癥階段作為標簽,以指示掃描中有癌癥作為與手動突出顯示 3D 成像上的癌變區域相反。對于不精確的標簽,數據集可能會有更多可用的標簽,并且準確度更高。特別是,這減少了對高水平專業知識的需求來突出所有相關像素。
在最常見的醫學成像用例(例如檢測和定位感興趣區域)中利用此類不精確標簽的流行方法使用兩步過程:
主干,例如訓練 DL 模型以預測由不精確標簽描述的類。
一旦開發用于預測特定掃描,使用像素歸因方法(也稱為顯著性或可解釋性方法)來突出模型決策的最相關區域。
圖 2說明了不同的基于梯度的像素歸因方法的示例。

圖 2:兩個輸入圖像(金魚和熊)以及可用于在弱監督學習期間執行分割的基于梯度的像素歸因方法示例。(來源:Github 上的 TF Keras Vis)
卷積神經網絡作為主干
由于醫療用例經常使用成像數據,因此卷積神經網絡 (CNN) 是用作弱監督學習基礎的主要 DL 框架也就不足為奇了。CNN 通過學習減少醫學掃描中的數百萬像素來工作——通常將 3D 體積減少為低維表示——然后將其映射到類標簽。
在弱監督學習中,可以組合方法。例如,可以在您的數據集上訓練一個新網絡(這提供了其他類似數據源的好處)。預訓練的網絡可用于對新任務執行遷移學習。例如,ResNet50 和 VGG16 是在日常生活中發現的數百萬張圖像上訓練的兩種 CNN 架構。盡管它們沒有在醫學圖像上進行過訓練,但它們仍然很有用,因為在模型的早期層中學習到的卷積濾波器往往是通用特征,例如線條、形狀和紋理,這對醫學成像很有用。
使用這些模型之一進行遷移學習就像移除最終的類預測層并使用代表新醫學成像任務的類的層重新初始化它一樣簡單。盡管最終目標是獲得突出圖像中相關對象和感興趣區域的輸出,但第一步只是首先預測圖像中是否存在這些感興趣區域。
弱監督本地化的 AI 可解釋性
一旦 DL 主干經過訓練并且可以準確地預測感興趣的類別,下一步將是使用眾多 AI 可解釋性方法中的一種來生成感興趣區域的分割。開發這些可解釋性方法(也稱為像素歸因方法)是為了深入了解深度學習模型在做出特定預測時在圖像中查看的內容。輸出是某種形式的可視化——通常稱為顯著性圖——可以根據最終目標以幾種不同的方式計算。
最流行的方法之一是使用基于梯度的顯著圖。在其核心,這涉及進行輸出預測并檢查構成該輸出的所有神經元。根據方法的不同,這種檢查可以一直追溯到第一個輸入層——Vanilla Gradients。或者它可以停止在稍后的某個層,例如神經網絡架構中的最后一個卷積層——GradCAM(圖 3)。其他變體做不同的事情,例如產生更平滑的感興趣區域,改善簡單變體的限制,或者圍繞所需特征生成更緊密的分割。
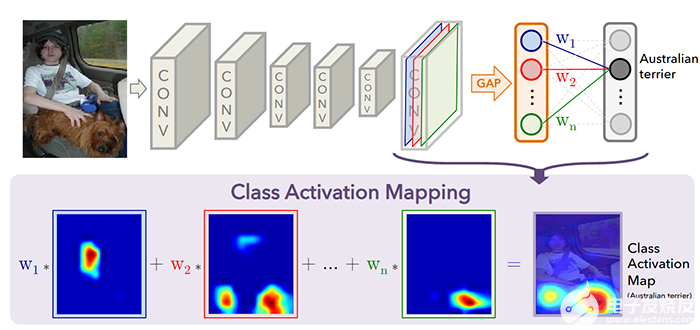
圖 3:GradCAM 是一種 ML 可解釋性方法,可用于在弱監督學習中分割特征,它采用與最后一個卷積層有關的輸出類的梯度。(來源:麻省理工學院計算機科學與人工智能實驗室的 Zhou 等人)
結論
直到最近,識別醫學圖像中的生物標志物還需要大量復雜標記的成像數據。然而,弱監督學習等技術減少了對完整、準確和準確的數據標簽的需求,并減少了在時間和專業知識方面成本太高而無法獲得的洞察力。弱監督學習通過利用更容易獲得的粗標簽來工作——例如在圖像級別而不是圖像中感興趣的分割。它允許重復使用預訓練的 CNN 模型,然后使用常見的可解釋性方法根據預測的類突出顯示感興趣的區域。這兩點允許在沒有廣泛的像素級注釋的情況下為各種應用程序對醫學成像數據進行訓練的模型。
編輯6.20
審核編輯 黃昊宇
-
AI
+關注
關注
87文章
33442瀏覽量
273993 -
人工智能
+關注
關注
1803文章
48405瀏覽量
244586 -
醫學成像
+關注
關注
0文章
55瀏覽量
14974
發布評論請先 登錄
相關推薦
傳音重構全膚色影像技術體系,開拓影像膚色成像技術新領域

東軟醫療光子計數CT取得突破性進展
三維測量在醫療領域的應用
東軟發布新一代醫學影像解決方案
時空引導下的時間序列自監督學習框架

Dell PowerScale數據湖助力醫研一體化建設

【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
醫學影像存儲與傳輸系統源碼,PACS系統源碼
圖像識別技術在醫療領域的應用
神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
利用NVIDIA的nvJPEG2000庫分析DICOM醫學影像的解碼功能





 工商網監
工商網監

評論