 ECCV 2022 | CMU提出FKD:用于視覺識別的快速知識蒸餾框架!訓練加速30%!
ECCV 2022 | CMU提出FKD:用于視覺識別的快速知識蒸餾框架!訓練加速30%!
今天介紹一篇來自卡耐基梅隆大學等單位 ECCV 2022 的一篇關于快速知識蒸餾的文章,用基本的訓練參數配置就可以把 ResNet-50 在 ImageNet-1K 從頭開始 (from scratch) 訓練到 80.1% (不使用 mixup,cutmix 等數據增強),訓練速度(尤其是數據讀取開銷)相比傳統分類框架節省 16% 以上,比之前 SOTA 算法快 30% 以上,是目前精度和速度雙雙最優的知識蒸餾策略之一,代碼和模型已全部開源!

A Fast Knowledge Distillation Framework for Visual Recognition
論文和項目網址:http://zhiqiangshen.com/projects/FKD/index.html
代碼:https://github.com/szq0214/FKD
知識蒸餾(KD)自從 2015 年由 Geoffrey Hinton 等人提出之后,在模型壓縮,視覺分類檢測等領域產生了巨大影響,后續產生了無數相關變種和擴展版本,但是大體上可以分為以下幾類:vanilla KD,online KD,teacher-free KD 等。最近不少研究表明,一個最簡單、樸素的知識蒸餾策略就可以獲得巨大的性能提升,精度甚至高于很多復雜的 KD 算法。但是 vanilla KD 有一個不可避免的缺點:每次 iteration 都需要把訓練樣本輸入 teacher 前向傳播產生軟標簽 (soft label),這樣就導致很大一部分計算開銷花費在了遍歷 teacher 模型上面,然而 teacher 的規模通常會比 student 大很多,同時 teacher 的權重在訓練過程中都是固定的,這樣就導致整個知識蒸餾框架學習效率很低。 針對這個問題,本文首先分析了為何沒法直接為每張輸入圖片產生單個軟標簽向量然后在不同 iterations 訓練過程中復用這個標簽,其根本原因在于視覺領域模型訓練過程數據增強的使用,尤其是 random-resize-cropping 這個圖像增強策略,導致不同 iteration 產生的輸入樣本即使來源于同一張圖片也可能來自不同區域的采樣,導致該樣本跟單個軟標簽向量在不同 iterations 沒法很好的匹配。本文基于此,提出了一個快速知識蒸餾的設計,通過特定的編碼方式來處理需要的參數,繼而進一步存儲復用軟標簽(soft label),與此同時,使用分配區域坐標的策略來訓練目標網絡。通過這種策略,整個訓練過程可以做到顯式的 teacher-free,該方法的特點是既快(16%/30% 以上訓練加速,對于集群上數據讀取緩慢的缺點尤其友好),又好(使用 ResNet-50 在 ImageNet-1K 上不使用額外數據增強可以達到 80.1% 的精度)。 首先我們來回顧一下普通的知識蒸餾結構是如何工作的,如下圖所示:
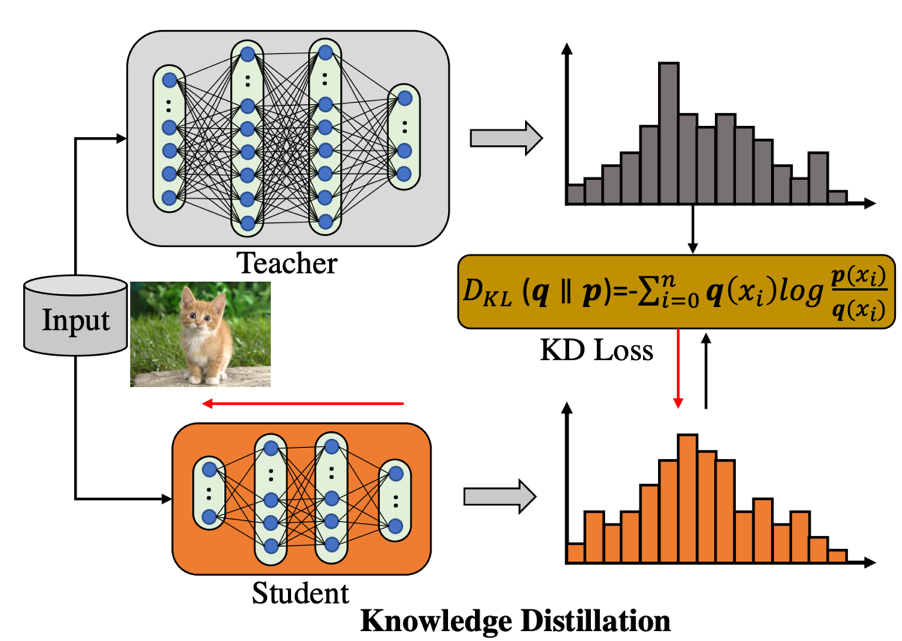
知識蒸餾框架包含了一個預訓練好的 teacher 模型(蒸餾過程權重固定),和一個待學習的 student 模型, teacher 用來產生 soft 的 label 用于監督 student 的學習。可以看到,這個框架存在一個比較明顯的缺點:當 teacher 結構大于 student 的時候,訓練圖像前饋產生的計算開銷已經超過 student,然而 teacher 權重并不是我們學習的目標,導致這種計算開銷本質上是 “無用的”。本文的動機正是在研究如何在知識蒸餾訓練過程中避免或者說重復利用這種額外的計算結果,該文章的解決策略是提前保存每張圖片不同區域的軟監督信號(regional soft label)在硬盤上,訓練 student 過程同時讀取訓練圖片和標簽文件,從而達到復用標簽的效果。所以問題就變成了:soft label 怎么來組織和存儲最為有效?下面具體來看該文章提出的策略。 1. FKD 算法框架介紹 FKD 框架的核心部分包含了兩個階段,如下圖:(1)軟標簽(soft label)的生成和存儲;(2)使用軟標簽(soft label)進行模型訓練。
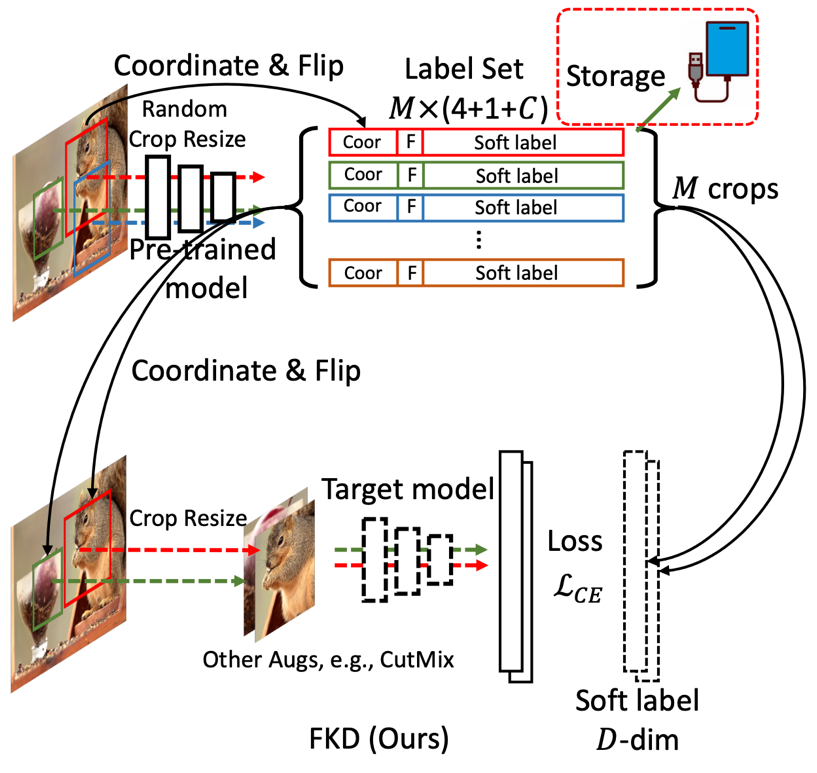
如圖所示,上半部分展示了軟標簽的生成過程,作者通過輸入多個 crops 進入預訓練好的 teacher 來產生需要的軟標簽向量,同時作者還保存了:(1)每個 crop 對應的坐標和(2)是否翻轉的 Boolean 值。下半部分展示了 student 訓練過程,作者在隨機采樣圖片的時候同時也會讀取它們對應的軟標簽文件,從中選取 N 個 crops 用于訓練,額外數據增強比如 mixup,cutmix 會放在這個階段,從而節省了由于引入更多數據增強參數帶來的額外存儲開銷。 2. 采樣策略 本文還提出了一個 multi-crop sampling 的策略,即在一個 mini-batch 里面每張圖片采樣多個樣本 crops。當總的訓練 epochs 不變的前提下,該采樣方式可以大大減少數據讀取的次數,對于一些數據讀取不是非常高效或者產生嚴重瓶頸的集群設備,這種策略的加速效果非常明顯(如下表格所示)。同時在一張圖片采樣多個 crops 可以減少訓練樣本間的方差,幫助穩定訓練,作者發現如果 crops 的數目不是太大的情況下可以明顯提升模型精度,但是一張圖片里面采樣太多 crops 數目會造成每個 mini-batch 里面訓練樣本的信息差異不足(過于相似),因此過度采樣會影響性能,所以需要設置一個合理的數值。 3. 加速比 作者在實驗部分跟標準的訓練方式以及 ReLabel 訓練進行了速度的比較,結果如下表格所示:可以看到,相比正常的分類框架,FKD 會快 16% 左右,而相比 ReLabel 則快了 30%,因為 ReLabel 相比正常訓練需要讀取雙倍的文件數目。需要注意的是這個速度對比實驗中,FKD crop 數目為 4,如果選取更大的 crop 數目可以得到更高的加速比。
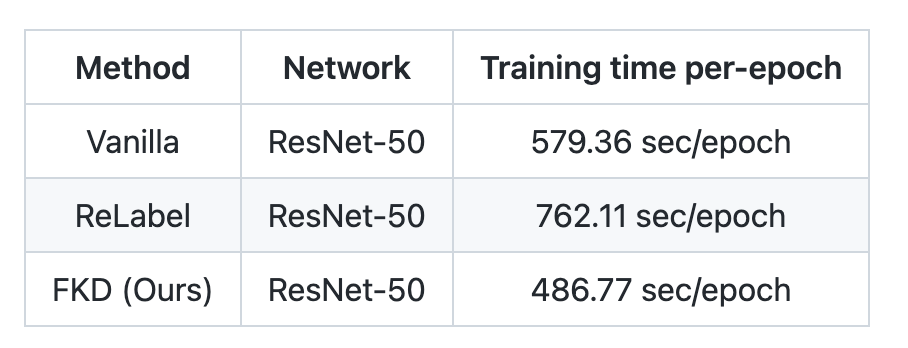
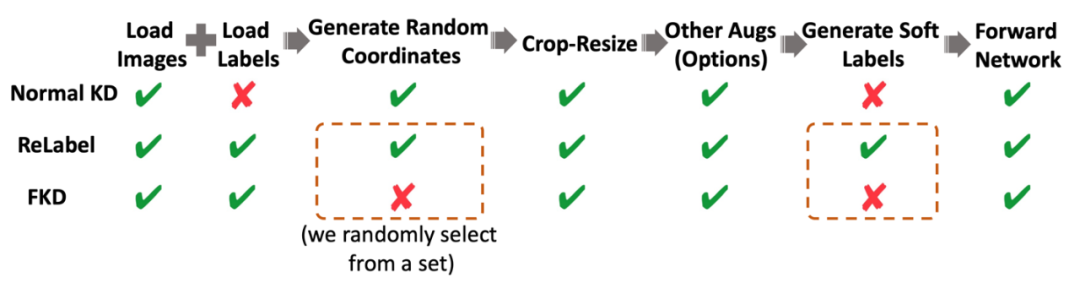
加速原因分析: 除了上述介紹的采用多個 crops 來進行加速外,作者還分析了其他一些加速的因素,如下圖所示,ReLabel 在訓練模型階段需要生成采樣數據的坐標,同時需要使用 RoI-Align 和 Softmax 來生成所需的軟標簽,相比而言,FKD 直接保存了坐標信息和最終軟標簽格式,因此讀取標簽文件之后不需要做任何額外的后處理就可以直接訓練,速度相比 ReLabel 也會更快。
4. 標簽質量分析 軟標簽質量是保證模型訓練精度的一項最重要的指標,作者通過可視化標簽分布以及計算不同模型預測之間的交叉熵(cross-entropy)來證明了所提出的方式擁有更好的軟標簽質量。
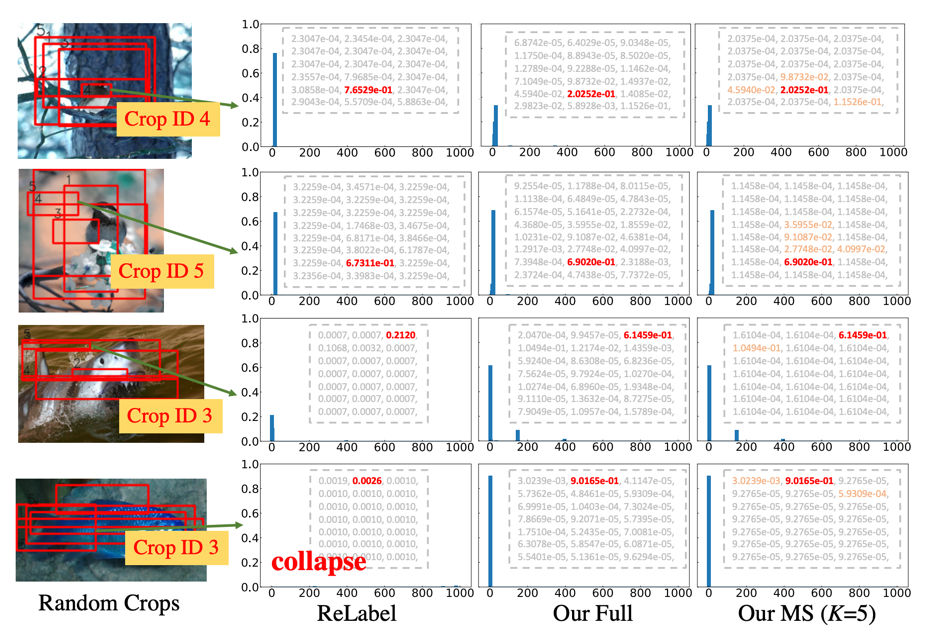
上圖展示了 FKD 和 ReLabel 軟標簽分布的情況對比,得到如下結論:
(第一行)FKD 相比 ReLabel 置信度更加平均也與輸入樣本內容更加一致,作者分析原因是 ReLabel 將全局圖像輸入到模型中,而不是局部區域,這使得生成的全局標簽映射編碼了更多全局類別信息同時忽略了背景信息,使得生成的軟標簽過于接近單個語義標簽。
(第二行)雖然存在一些樣本 ReLabel 和 FKD 之間的最大預測概率相似,但 FKD 包含更多標簽分布中的從屬類別概率,而 ReLabel 的分布中并沒有捕獲這些從屬類別的信息。
(第三行)對于某些異常情況,FKD 比 ReLabel 更加健壯,例如目標框含有松散邊界,或者只定位部分目標等。
(第四行)在有些情況下,ReLabel 的標簽分布意外的崩潰了(均勻分布),沒有產生一個主要的預測,而 FKD 仍然可以預測得很好。
5. 標簽壓縮、量化策略 1)硬化 (Hardening)。在該策略中,樣本標簽 Y_H 使用 teacher 預測的最大 logits 的索引。標簽硬化策略產生的依然是 one-hot 的標簽,如下公式所示:
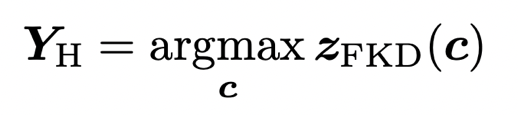
2)平滑 (Smoothing)。平滑量化策略是將上述硬化后的標簽 Y_H 替換為軟標簽和均勻分布的分段函數組合,如下所示:
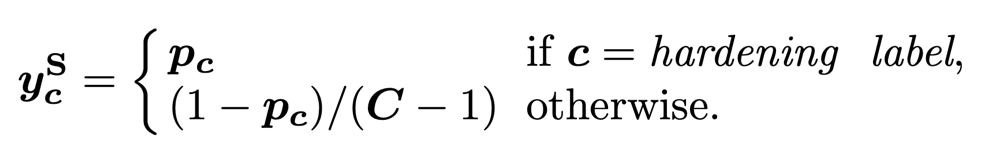
3)邊際平滑 (Marginal Smoothing with Top-K)。邊際平滑量化策略相比單一預測值保留了更多的邊際信息(Top-K)來平滑標簽 Y_S:
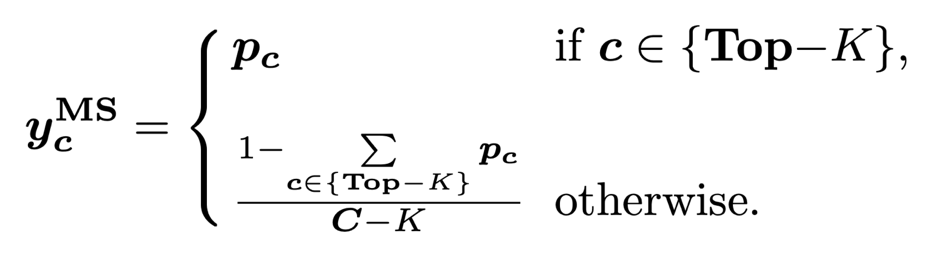
4)邊際平滑歸一化 (Marginal Re-Norm with Top-K)。邊際平滑歸一化策略會將 Top-K 預測值重新歸一化到和為 1,并保持其他元素值為零(FKD 使用歸一化來校準 Top-K 預測值的和為 1,因為 FKD 存儲的軟標簽是 softmax 處理之后的值):
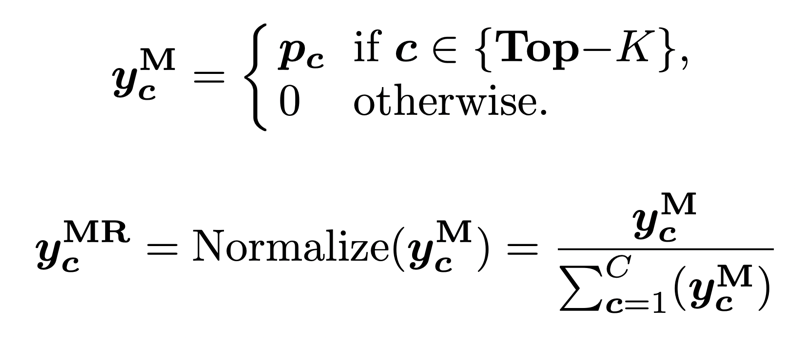
具體對應上述各種量化策略的圖示如下圖所示:
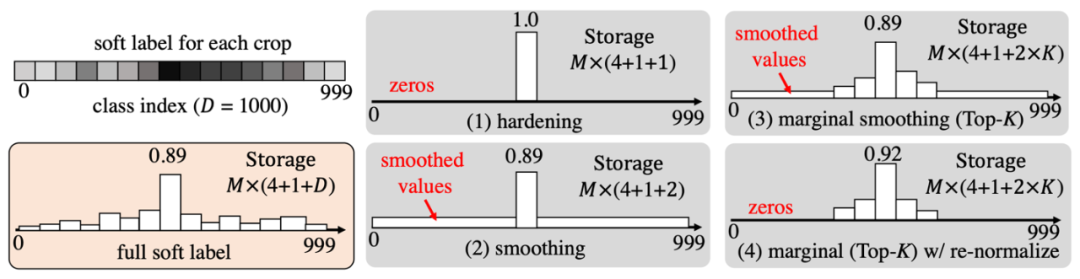
6. 不同標簽量化 / 壓縮策略的存儲大小比較 不同標簽壓縮方法需要的存儲空間如下表格所示,所使用的數據集為 ImageNet-1K,其中 M 是軟標簽生成階段每張圖像被采樣的數目,這里作者選取了 200 作為示例。Nim 是圖像數量, ImageNet-1K 數據集為 1.2M,SLM 是 ReLabel 標簽矩陣的大小,Cclass 是類的數量,DDA 是需要存儲的數據增強的參數維度。

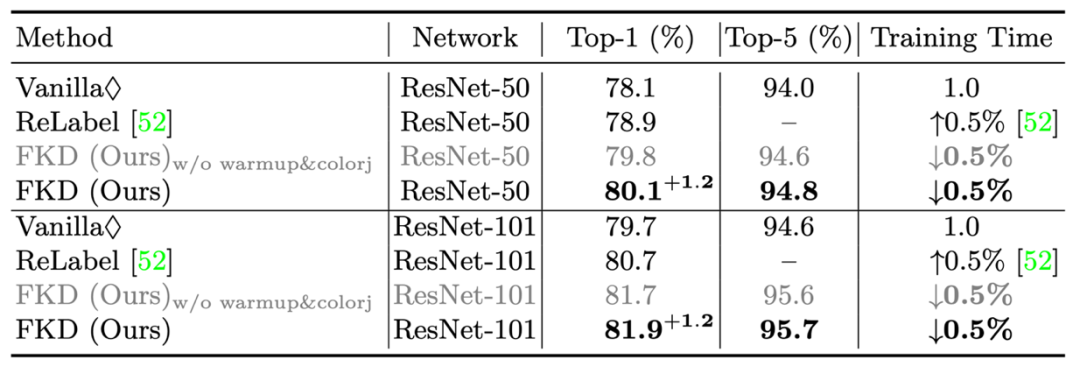
從表格中可以看到,在不做任何壓縮的情況下 FKD 軟標簽需要的存儲空間為 0.9T,這在實際使用中顯然是不現實的,標簽數據的大小已經遠遠超過訓練數據本身了。通過標簽壓縮可以極大減少存儲大小,同時后面實驗也證明了合適的壓縮方式并不會損害模型精度。 7. 自監督學習任務上的應用 FKD 的訓練方式也可以應用于自監督學習任務。作者使用自監督算法比如 MoCo,SwAV 等來預訓練 teacher 模型,然后按照上述方式生成用于自監督的軟標簽(unsupervised soft label),這個步驟跟監督學習得到的 teacher 很相似。生成標簽過程會保留原始自監督模型中 projection head 并使用之后的最終輸出向量,然后將這個向量作為軟標簽保存下來。得到該軟標簽后,可以使用同樣的監督式的訓練方式來學習對應的 student 模型。 8. 實驗結果 1)首先是在 ResNet-50 和 ResNet-101 上的結果,如下表所示,FKD 取得了 80.1%/ResNet-50 和 81.9%/ResNet-101 的精度。同時訓練時間相比普通訓練和 ReLabel 都快了很多。
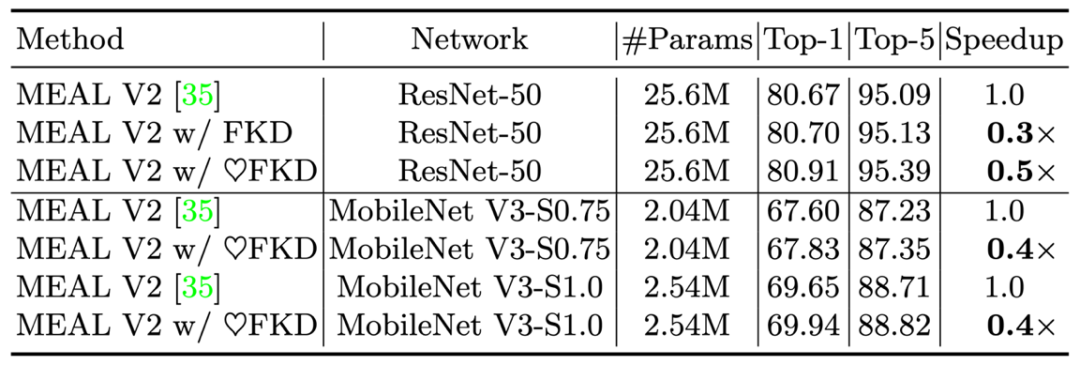
2)作者還測試了 FKD 在 MEAL V2 上的結果,同樣得到了 80.91% 的結果。
3)Vision Transformer 上的結果: 接下來作者展示了在 vision transformer 上的結果,在不使用額外數據增強的情況下,FKD 就可以比之前知識蒸餾方法得到將近一個點的提升,同時訓練速度快了 5 倍以上。
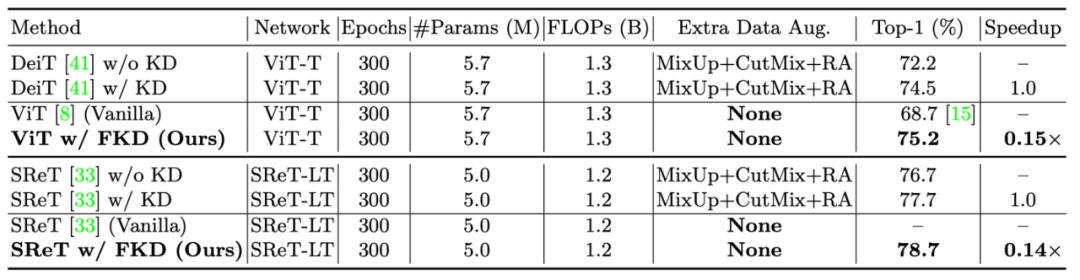
4)Tiny CNNs 上的結果:

5)消融實驗:
首先是不同壓縮策略,綜合考慮存儲需求和訓練精度,邊際平滑策略是最佳的。

接下來是訓練階段不同 crop 數目的對比,MEAL V2 由于使用了 pre-trained 的參數作為初始化權重,因此不同 crop 數目下性能都比較穩定和接近。而 vanilla 和 FKD 在 crop=4 的時候表現得最好。尤其 vanilla,相比 crop=1 精度提升了一個點,crop 大于 8 之后精度下降明顯。
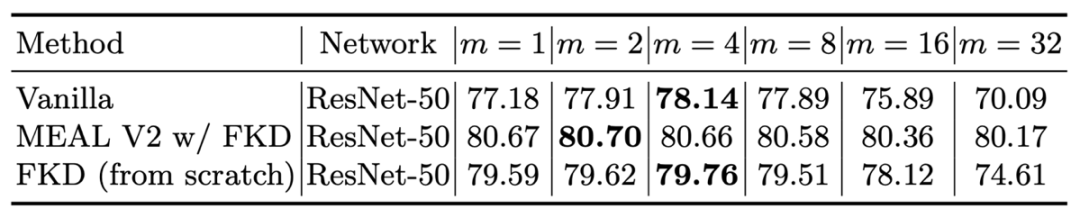
6)自監督任務上的結果: 如下表所示,在自監督學習任務上 FKD 方式還是可以很好的學習目標模型,同時相比雙子結構自監督網絡訓練和蒸餾訓練,可以加速三到四倍。

9. 下游任務 下表給出了 FKD 模型在 ImageNet ReaL 和 ImageNetV2 兩個數據集上的結果,可以看到,FKD 在這些數據集上取得了穩定的提升。

下表是 FKD 預訓練模型在 COCO 目標檢測任務上的結果,提升同樣明顯。
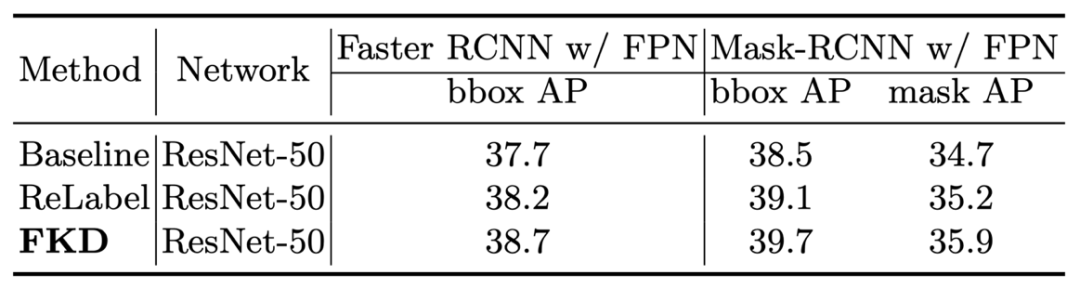
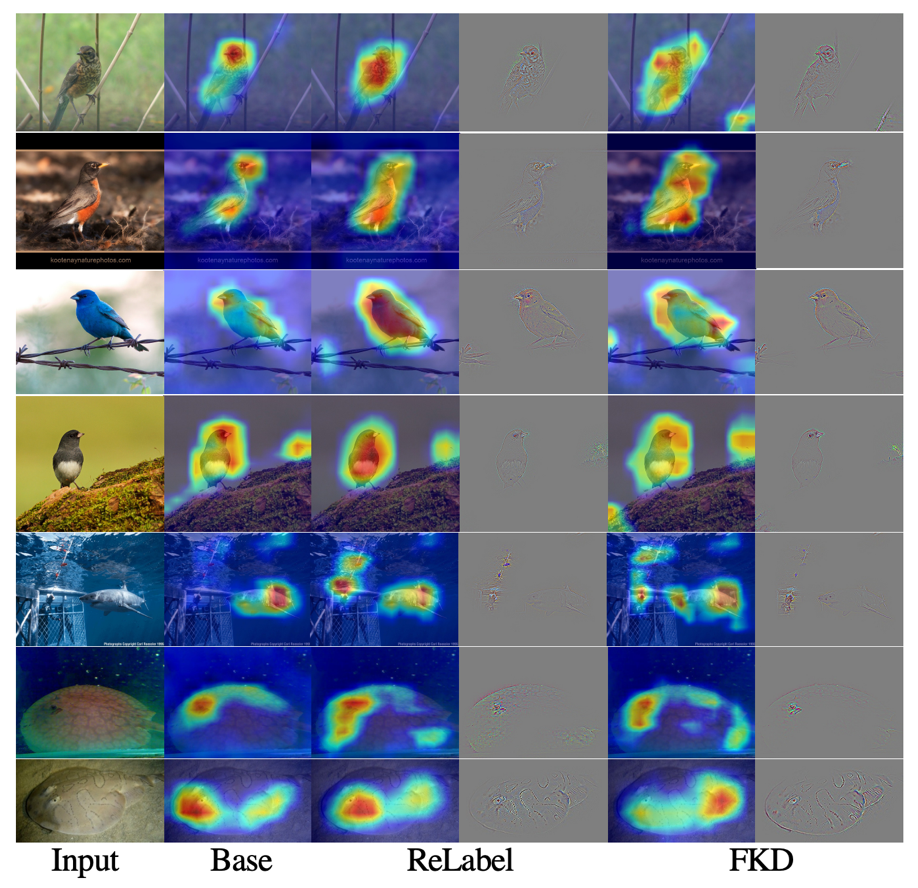
10. 可視化分析 如下兩張可視化圖所示,作者通過可視化中間特征層(attention map)的方式探索 FKD 這種 region-based 訓練方式對模型產生的影響,作者對比了三種不同訓練方式得到的模型:正常 one-hot label,ReLabel 和本文提出的 FKD。 (i) FKD 的預測的概率值相比 ReLabel 更加小(soft),因為 FKD 訓練過程引入的上下文以及背景信息更多。在 FKD 隨機 crop 的訓練策略中,許多樣本采樣于背景(上下文)區域,來自 teacher 模型的軟預測標簽更能真實的反映出實際輸入內容,并且這些軟標簽可能與 one-hot 標簽完全不同,FKD 的訓練機制可以更好的利用上下文中的額外信息。 (ii) FKD 的特征可視化圖在物體區域上具有更大的高響應值區域,這表明 FKD 訓練的模型利用了更多區域的線索進行預測,進而捕獲更多差異性和細粒度的信息。 (iii)ReLabel 的注意力可視化圖與 PyTorch 預訓練模型更加接近,而 FKD 的結果跟他們相比具有交大差異性。這說明 FKD 方式學習到的注意力機制跟之前模型有著顯著的差別,從這點出發后續可以進一步研究其有效的原因和工作機理。

審核編輯 :李倩
-
算法
+關注
關注
23文章
4622瀏覽量
93060 -
視覺識別
+關注
關注
3文章
89瀏覽量
16766 -
模型
+關注
關注
1文章
3268瀏覽量
48926
原文標題:ECCV 2022 | CMU提出FKD:用于視覺識別的快速知識蒸餾框架!訓練加速30%!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論