

在文本理解任務(Natural Language Understanding)上,預訓練模型已經取得了質的飛躍,語言模型預訓練+下游任務fine-tune基本上已經成為標配。
很多人曾經嘗試將 BERT 等預訓練語言模型應用于文本生成任務(Natural Language Generation),然而結果并不理想。究其原因,是在于預訓練階段和下游任務階段的差異。
BART這篇文章提出的是一種符合生成任務的預訓練方法,BART的全稱是Bidirectional and Auto-Regressive Transformers,顧名思義,就是兼具上下文語境信息和自回歸特性的Transformer。那么它的細節和效果如何呢,就讓我們一起來看看吧
論文名稱:《BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation, and Comprehension》
論文鏈接:https://arxiv.org/pdf/1910.13461.pdf
1. 從GPT,BERT到BART
GPT:是一種 Auto-Regressive(自回歸)的語言模型。它也可以看作是Transformer model的Decoder部分,它的優化目標就是標準的語言模型目標:序列中所有token的聯合概率。GPT采用的是自然序列中的從左到右(或者從右到左)的因式分解。
BERT:是一種Auto-Encoding(自編碼)的語言模型。它也可以看作是Transformer model的Encoder部分,在輸入端隨機使用一種特殊的[MASK]token來替換序列中的token,這也可以看作是一種noise,所以BERT也叫Masked Language Model。
 表1. GPT和BERT的對比
表1. GPT和BERT的對比
BART:吸收了 BERT 的 bidirectional encoder 和 GPT 的 left-to-right decoder 各自的特點;是建立在標準的 seq2seq Transformer model 的基礎之上,這使得它比 BERT 更適合文本生成的場景;此外,相比GPT也多了雙向上下文語境信息。在生成任務上獲得進步的同時,它也可以在一些文本理解類任務上取得SOTA。
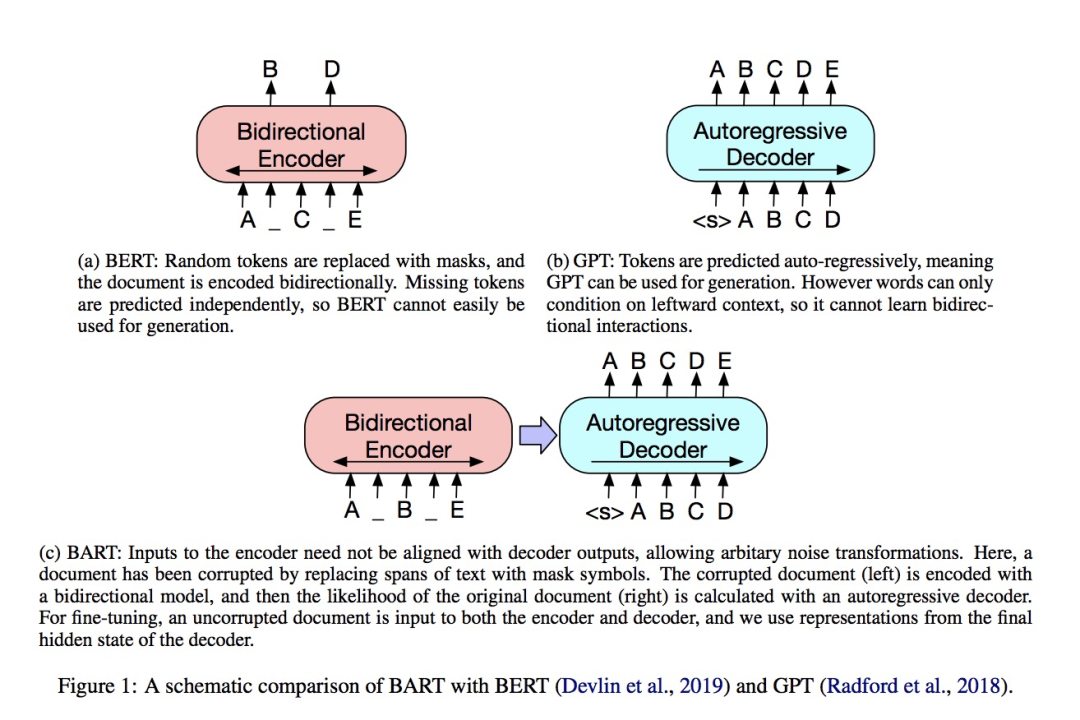 圖1. BERT、GPT和BART對比
圖1. BERT、GPT和BART對比
1.1. 關于BART的討論
Loss Function 就是重構損失, 也就是decoder的輸出和原文ground truth之間的交叉熵。
BART 的結構在上圖中已經很明確了:就是一個BERT+GPT的結構;但是不同之處在于(也是作者通篇在強調的),相對于BERT中單一的noise類型(只有簡單地用[MASK] token進行替換這一種noise),BART在encoder端嘗試了多種noise。其原因和目的也很簡單:
BERT的這種簡單替換導致的是encoder端的輸入攜帶了有關序列結構的一些信息(比如序列的長度等信息),而這些信息在文本生成任務中一般是不會提供給模型的。
BART采用更加多樣的noise,意圖是破壞掉這些有關序列結構的信息,防止模型去“依賴”這樣的信息。
1.2. BART中的多種Noise
Token Masking: 就是BERT的方法----隨機將token替換成[MASK]。
Token Deletion: 隨機刪去token。
Text Infilling: 隨機將一段連續的token(稱作span)替換成一個[MASK],span的長度服從 的泊松分布。注意span長度為0就相當于插入一個[MASK]。
Sentence Permutation: 將一個document的句子打亂。
Document Rotation: 從document序列中隨機選擇一個token,然后使得該token作為document的開頭。
 表2. 不同noise及其作用
表2. 不同noise及其作用
注意這里不同的noising變換方式還可以組合。
2. BART在下游任務上的應用
2.1. Sequence Classification Task
將該序列同時輸入給encoder端和decoder端,然后取decoder最后一個token對應的final hidden state作為label,輸入給一個線性多分類器。
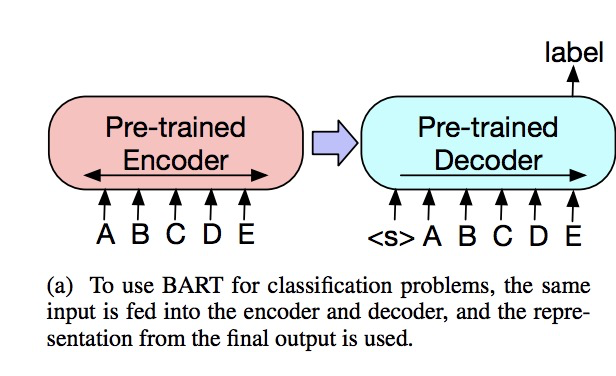 圖2. BART用于序列分類任務
圖2. BART用于序列分類任務
注意在序列的最后要加一個token,保證seq2seq模型輸出的label包含序列中每一個token的信息,這是因為decoder的輸入是right-shifted的,不這樣做的話label將不包含最后一個token的信息。
2.2. Token Classification Task
這一類問題意思是,將序列的所有token都看作獨立的選項,序列長度為M,那么選項的個數就是M,在序列的所有token中選擇k個。屬于這類的經典問題有SQuAD,即answer endpoint classification。
將該序列同時輸入給encoder端和decoder端,使用decoder的final hidden states作為每個token的向量表征,該向量表征作為分類問題的輸入,輸入到分類系統中去。
2.3. Sequence Generation Task
由于BART本身就是在sequence-to-sequence的基礎上構建并且預訓練的,它天然比較適合做序列生成的任務,比如概括性的問答,文本摘要,機器翻譯等。
2.4. Machine Translation
具體的做法是將BART的encoder端的embedding層替換成randomly initialized encoder,新的encoder也可以用不同的vocabulary。
通過新加的Encoder,我們可以將新的語言映射到BART能解碼到English(假設BART是在English的語料上進行的預訓練)的空間。具體的finetune過程分兩階段:
第一步只更新randomly initialized encoder + BART positional embedding + BART的encoder第一層的self-attention 輸入映射矩陣。
第二步更新全部參數,但是只訓練很少的幾輪。
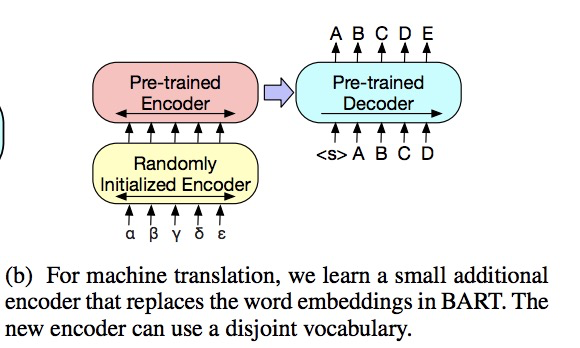 圖3. BART用于機器翻譯
圖3. BART用于機器翻譯
3. 實驗1: 不同預訓練目標的比較
論文對不同的pretrain objective,在多個下游任務上進行了比較嚴謹詳盡的實驗對比。模型結構: Transformer-base。
不同的Pre-train Objective有:
GPT: (Auto-Regressive) Language model
XLNET: Permuted Language Model
BERT: Masked Language Model
UniLM: Multitask Masked Language Model
MASS: Masked Seq-to-Seq
對比實驗涉及的下游任務有:
SQuAD: 將context和question連在一起輸入Encoder和Decoder,輸出的是context中的span。
MNLI: 將2個句子連在一起輸入Encoder和Decoder(中間加上[EOS]表示隔開),模型輸出的是兩個句子之間的關系,是典型的序列分類問題。
ELI5: 抽象的問答,將context和question連在一起輸入,模型輸出抽象摘要文本。
XSum: 新聞摘要生成任務
ConvAI2: 對話生成任務
CNN/DM:摘要生成任務
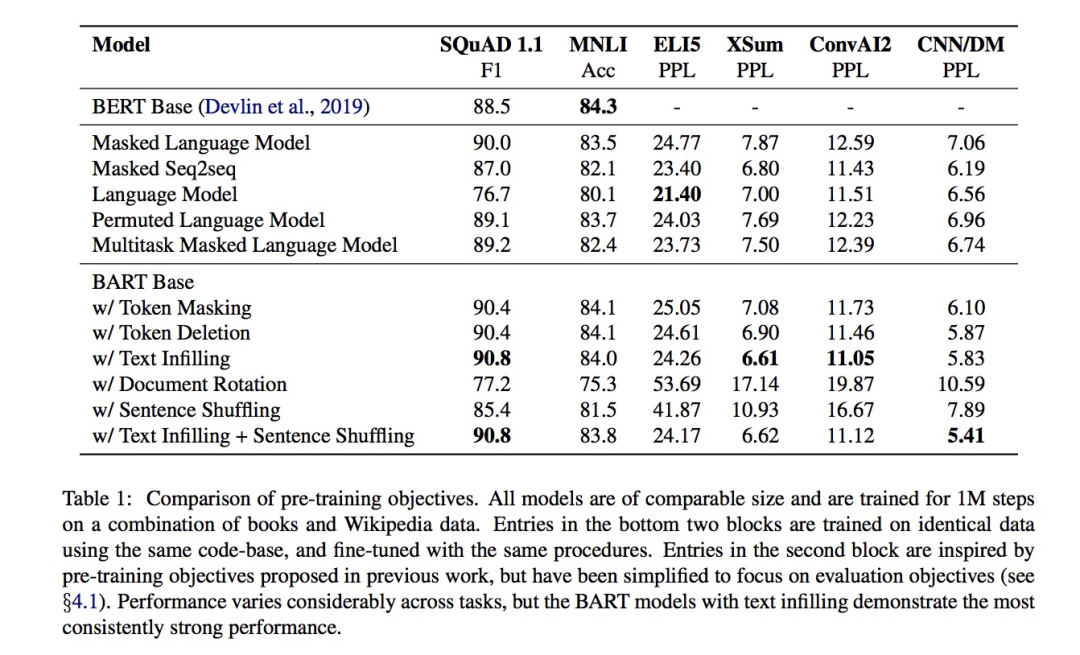
3.1 結論
不同預訓練方法各有千秋,在不同下游任務上的效果差異很大:比如說Language Model在ELI5任務上最好,但是在SQuAD任務上是最差的。
BART預訓練中的Token Masking作用很關鍵:Token Masking包括Token Masking,Token Deletion,Text Infilling。從表中可以看出,只做Document Rotation / Sentence Shuffling的預訓練模型效果很差。另外,Deletion比Masking效果好。
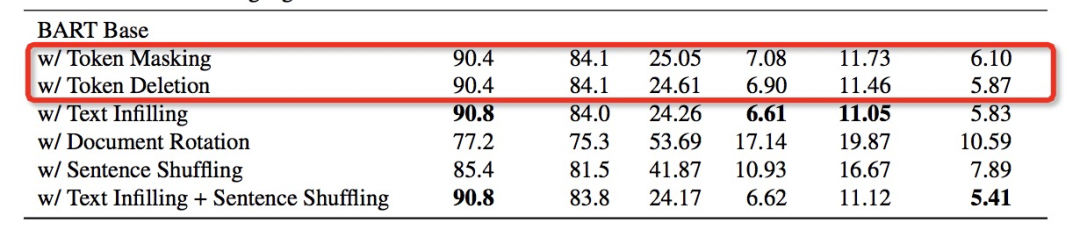
Left-to-Right Pretraining會提升生成任務的效果:和Masked Language Model和Permuted Language Model相比,包含Left-to-Right預訓練的模型在生成任務上表現更好。
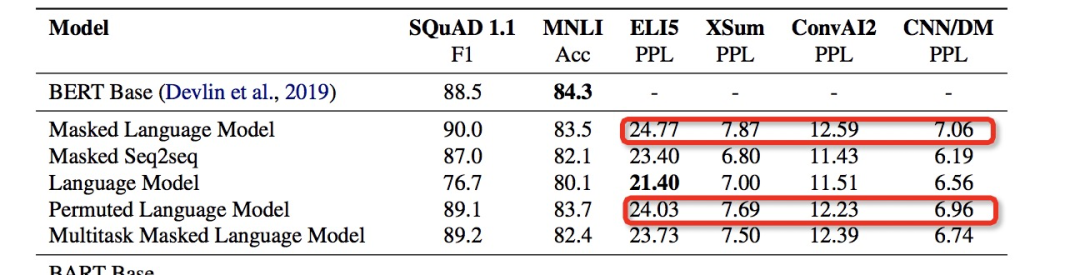 Masked Language Model和Permuted Language Model相比于包含Left-to-Right Auto-regressive Pre-training的模型,在生成任務上明顯表現要差一些
Masked Language Model和Permuted Language Model相比于包含Left-to-Right Auto-regressive Pre-training的模型,在生成任務上明顯表現要差一些
雙向的encoder對于SQuAD任務很重要
ELI5任務上單純的Language Model (Left-to-Right AR Language Model)表現最好,一個可能的解釋是該任務的輸出和輸入關系不大,因此BART沒有優勢。
預訓練目標不是唯一的重要因素,比如表中的Permuted Language Model的效果不如XLNet,作者提到,可能的原因有XLNet中有一些結構上的改進(比如relative-position embedding和segment-level recurrence)
4. 實驗2: 大規模實驗
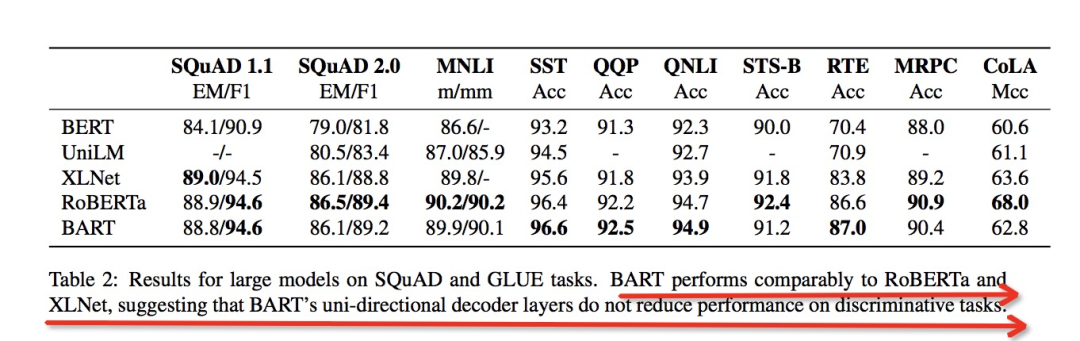
實驗發現,在discriminative任務(NLU)上和RoBERTa/XLNet效果持平,在生成任務上顯著高于BERT, UniLM, XLNet, RoBERTa等模型
4.1. Discriminative Tasks
BART并沒有因為單向的decoder而影響在文本理解類任務上的效果:
4.2. Generation Tasks
BART得益于單向的decoder,在三大類生成任務上效果拔群:
摘要生成:
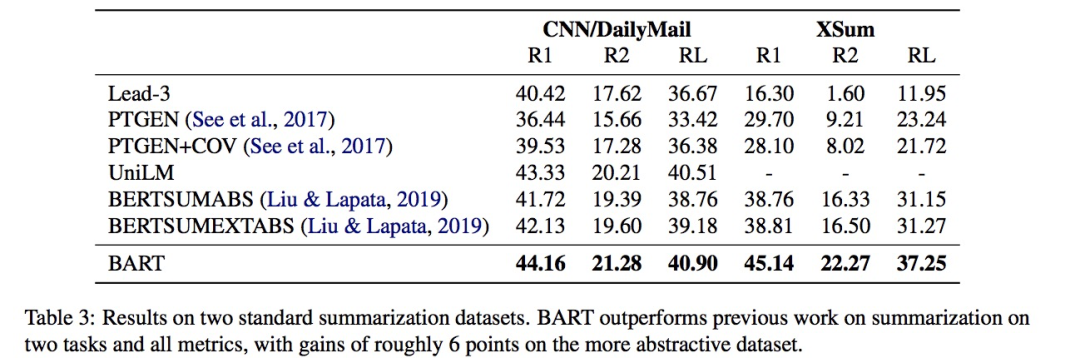 摘要任務上的對比
摘要任務上的對比
對話生成:
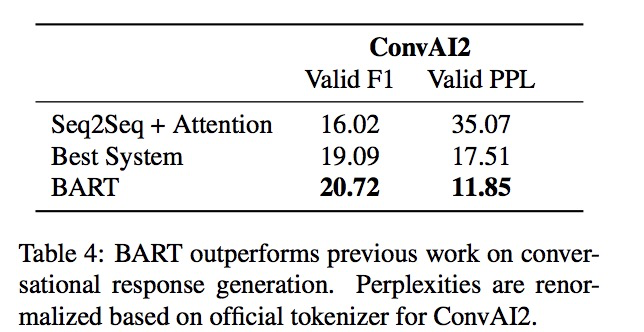 對話生成任務上的對比
對話生成任務上的對比
抽象問答
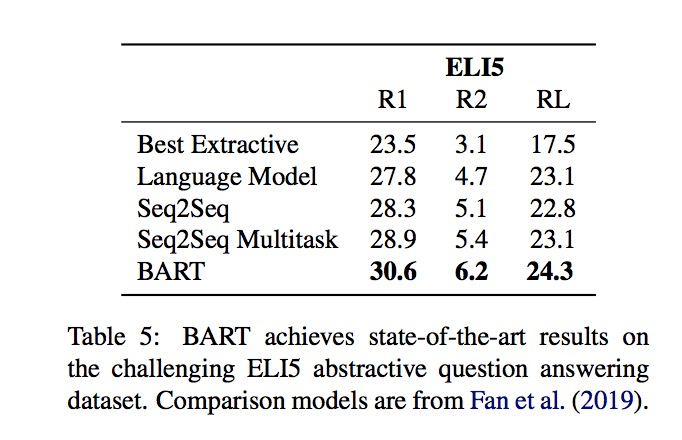 抽象問答任務上的對比
抽象問答任務上的對比
4.3. 翻譯

-
語言模型
+關注
關注
0文章
557瀏覽量
10586 -
機器翻譯
+關注
關注
0文章
140瀏覽量
15089 -
Transformer
+關注
關注
0文章
147瀏覽量
6316
原文標題:4. 實驗2: 大規模實驗
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
adxl加速度mems測量低頻振動的效果如何?
如何更改ABBYY PDF Transformer+界面語言
PDF Transformer+“調整亮度”警告消息解決辦法
如何更改ABBYY PDF Transformer+旋轉頁面
VL53L1水下使用效果如何?
空調制熱效果如何?空調制熱多少度最合適?
EE-26:AD184x Sigma Delta轉換器:它們使用直流輸入的效果如何?

我們可以使用transformer來干什么?
Go項目中引入中間件的目的和效果如何
基于Transformer的目標檢測算法






 工商網監
工商網監

評論