 FLAT的一種改進方案
FLAT的一種改進方案
許久沒有更新,今天來水一篇之前在arXiv上看到的論文,這篇NFLAT是對FLAT的改進(其實也是對TENER的改進),FLAT在文本后面掛單詞的方式可能會導致文本長度過長,論文中講長度平均會增加40%,從而導致:
self-attention的時候計算量和顯存占用量增大,限制了FLAT對更大更復雜的詞表的使用;
有一些冗余計算,比如“word-word”和“word-character”級別的self attention是沒有必要做的,因為在FLAT中word部分在解碼的時候會被mask掉(如下圖),不參與后續計算,所以只需要"character-character"和“character-word”級別的self-attention。
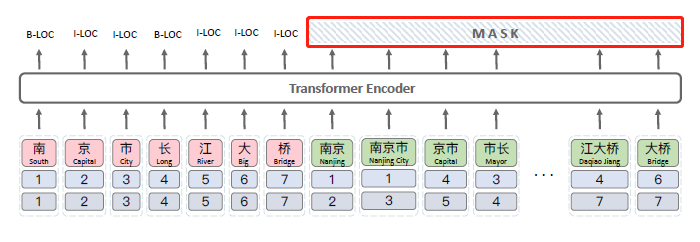 FLAT中word部分在解碼的時候會被MASK掉
FLAT中word部分在解碼的時候會被MASK掉
其實講到這里,相信讀者們也看出來了,改進思路已經比較明顯了:既然只要"character-character"和“character-word”級別的self-attention,那么就拆開搞,「不要把word往句子后面拼了,而是character有一個序列(原始文本序列),word有一個序列(原始文本序列在外部詞表中匹配出來的單詞序列)」:
先進行“character-word”的attention,獲得融合了word邊界和語義信息的character表征——論文中稱這部分叫「InterFormer」;
再做"character-character"級別的self-attention,獲取最終character表征——「Transformer Encoder」,論文這部分用的TENER對Transformer Encoder的改動,所以其實這篇論文也是對TENER的改進方案,「是TENER+外部詞典的解決方案」。
模型分為上面所說的三個模塊,接下來我們一個一個介紹。
模型
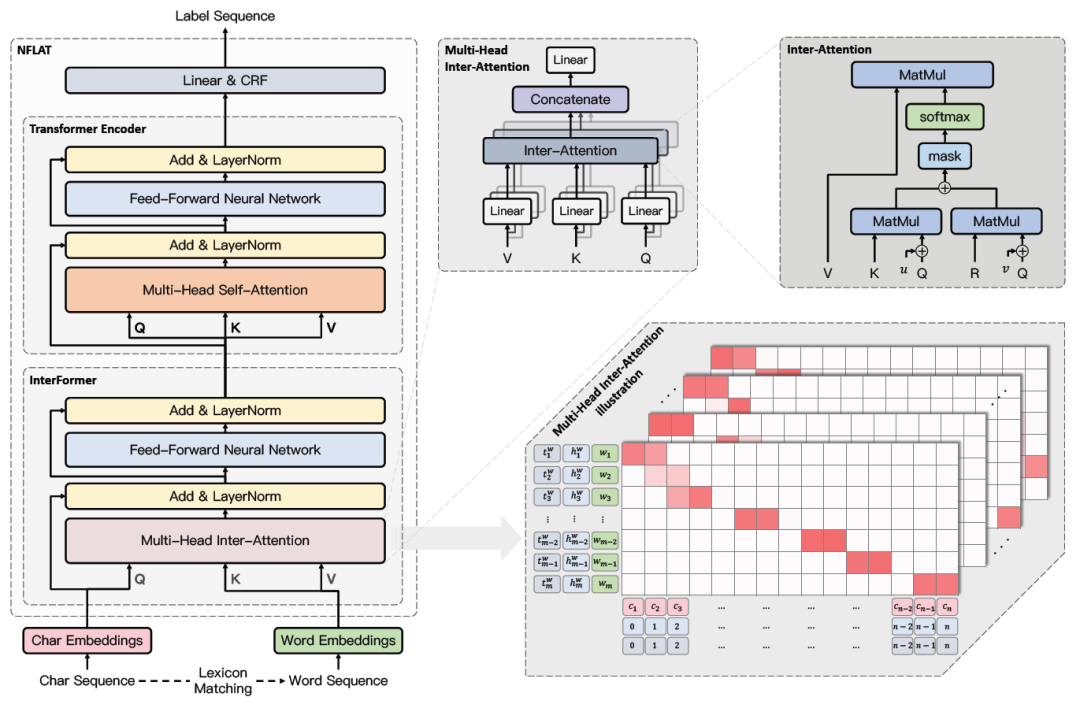 NFLAT模型結構
NFLAT模型結構
1. InterFormer
其實就是Transformer Encoder的改進版,InterFormer包含多頭inter-attention和一個FFN,目的是構建non-flat-lattice,可以同時對character和word兩個不同長度的序列進行建模,讓他們交互,從而獲得融合了word邊界和語義信息的character表征。
對Transformer Encoder的改進主要是:
「attention中query/key/value不再同源」,也就不再是self-attention,「character序列作為query的輸入,word序列作為key和value的輸入」。這樣的話attention在character序列中每個字上的輸出就是word序列中與這個字相關的word表征(value)的加權求和的結果。
他們在word序列中加入了一個標記
「參考了TransformerXL和FLAT中的相對位置編碼部分,同時做了一些改動」。
下面直接列公式了:
輸入:character序列embedding ,word序列embedding。
獲取QKV表征:
計算Inter-Attention
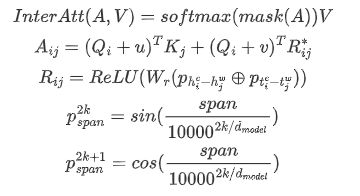
是attention中常規操作,就是對序列中padding部分的score賦一個很小的值,讓softmax后結果為0的;
的計算方法參考了TransformerXL,只是相對距離的表征的計算方式不太一樣,是參考FLAT,但也做了一些改動,FLAT中計算了四種位置距離表征:head-head, head-tail, tail-head, tail-tail,但這里只有兩種位置距離:character head - word head ()和 character tail - word tail ()。
同樣這個Inter-attention也可以做成multi-head attention的方式:
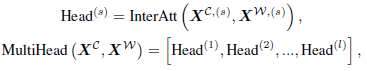
然后是FFN、殘差連接、PostNorm
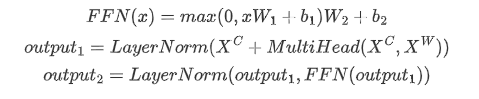
通過上面的這一系列操作,我們就獲得了“「融合了word邊界和語義信息的character表征」”。
2. Transformer Encoder
然后進行"character-character"級別的上下文編碼,用TENER中改造的Transformer Encoder,也就是兩部分改動:
Un-scaled Dot-Product Attention,TENER中發現不進行scale的attention比進行了scale的在NER上的效果要好;
使用了對方向和距離敏感的相對位置編碼,其實和上面Inter-attention中相對位置編碼差不多,就是就只有query位置-value位置。
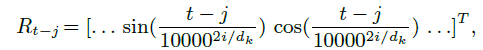
所以NFLAT其實就是在TENER前面加了一個模塊。
3. 最后就是CRF層
實驗結果
數據:
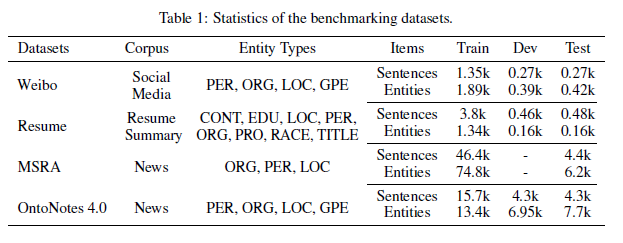 數據集
數據集
外部詞表:
外部詞表他們主要采用了:https://github.com/jiesutd/RichWordSegmentor
結果:
如下圖,可以看到,NFLAT在4個數據集上效果都還挺好的,達到了SOTA。
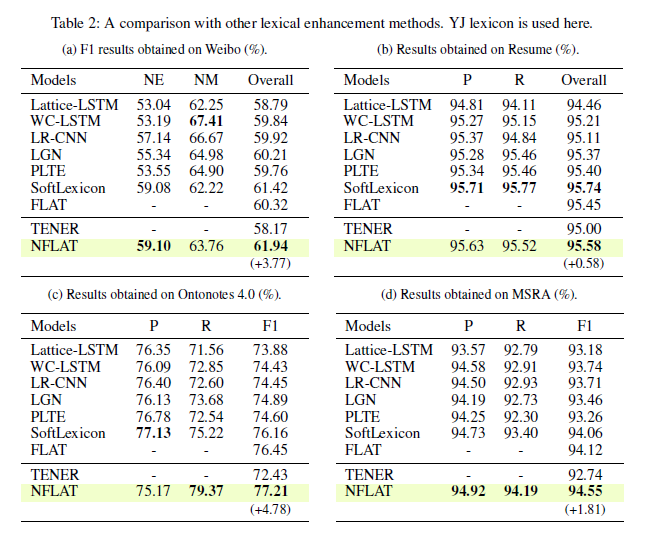 實驗結果
實驗結果
效率分析
時間復雜度:
n是character序列長度,m是word序列的長度,一般n越長,m越長,所以看復雜度的話NFLAT還是降低了許多了,作者們還做了相關的實驗,每種長度挑選1000個句子,用batch_size=1計算跑完1k條句子的時間(3090的卡),發現句子長度大于400的時候,NFLAT與FLAT的速度才會有差距。
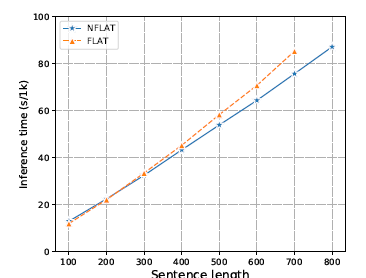 運行時間對比
運行時間對比
FLAT:
NFLAT:
空間復雜度:
顯存占用還是有明顯差別的:
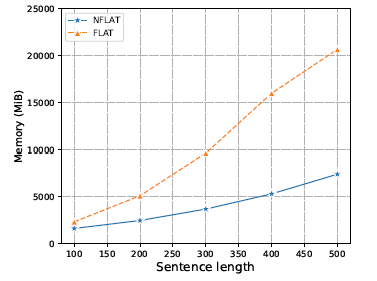 顯存占用對比
顯存占用對比
FLAT:O((n+m)^{2})
NFLAT:
差不多,這篇論文就到這里吧。
-
解碼
+關注
關注
0文章
181瀏覽量
27405 -
顯存
+關注
關注
0文章
110瀏覽量
13675 -
數據集
+關注
關注
4文章
1208瀏覽量
24737
原文標題:中文NER | 江南大學提出NFLAT:FLAT的一種改進方案
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分享一種DTMF信號檢測器工程的應用方案
一種消息恢復型數字簽名方案的改進
一種改進的強代理簽名方案
一種離線模式下CRL機制的改進方案
一種改進的TPM檢測方案
一種改進的各向異性高斯濾波算法
Whirlpool的一種改進算法





 工商網監
工商網監
評論