") project復(fù)現(xiàn)過程踩到坑對應(yīng)的解決方案
project復(fù)現(xiàn)過程踩到坑對應(yīng)的解決方案
最近做的一個 project 需要復(fù)現(xiàn) EMNLP 2020 Findings 的 TinyBERT,本文是對復(fù)現(xiàn)過程對踩到坑,以及對應(yīng)的解決方案和實現(xiàn)加速的一個記錄。
1. Overview of TinyBERT
BERT 效果雖好,但其較大的內(nèi)存消耗和較長的推理延時會對其上線部署造成一定挑戰(zhàn)。
在內(nèi)存消耗方面,一系列知識蒸餾的工作,例如 DistilBERT[2]、BERT-PKD[3] 和 TinyBERT 被提出來用以降低模型的參數(shù)(主要是層數(shù))以及相應(yīng)地減少時間;
在推理加速方面,也有 DeeBERT[4]、FastBERT[5] 及 CascadeBERT[6] 等方案提出,它們動態(tài)地根據(jù)樣本難度進行模型的執(zhí)行從而提升推理效率。其中較具備代表性的是 TinyBERT,其核心框架如下:
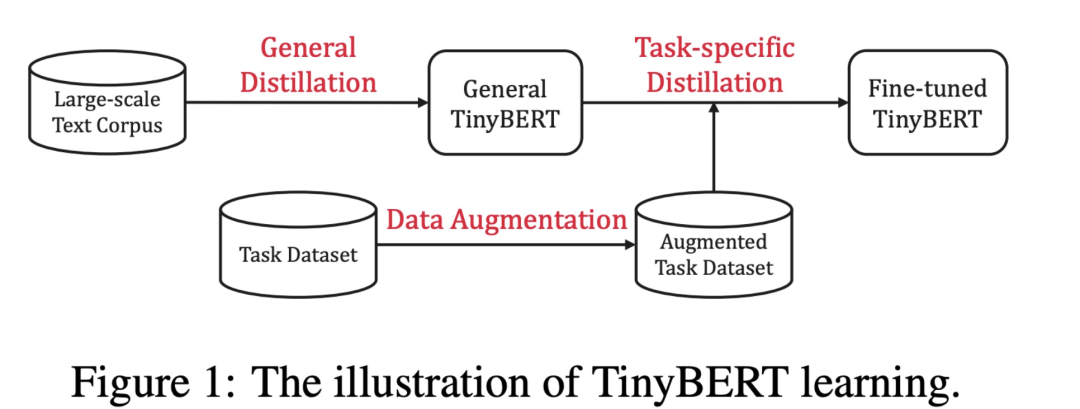
分為兩個階段:
General Distillation:在通用的語料,例如 BookCorpus, EnglishWiki 上進行知識蒸餾;目標函數(shù)包括 Transformer Layer Attention 矩陣以及 Layer Hidden States 的對齊;
Task Distillation:在具體的任務(wù)數(shù)據(jù)集上進行蒸餾,進一步分成兩個步驟:
Task Transformer Disitllation: 在任務(wù)數(shù)據(jù)集上對齊 Student 和已經(jīng) fine-tuned Teacher model 的 attention map 和 hidden states;
Task Prediction Distillation:在任務(wù)數(shù)據(jù)集上對 student model 和 teacher model 的 output distritbuion 利用 KL loss / MSE loss 進行對齊。
TinyBERT 提供了經(jīng)過 General Distillation 階段的 checkpoint,可以認為是一個小的 BERT,包括了 6L786H 版本以及 4L312H 版本。而我們后續(xù)的復(fù)現(xiàn)就是基于 4L312H v2 版本的。
值得注意的是,TinyBERT 對任務(wù)數(shù)據(jù)集進行了數(shù)據(jù)增強操作:通過基于 Glove 的 Embedding Distance 的相近詞替換以及 BERT MLM 預(yù)測替換,會將原本的數(shù)據(jù)集擴增到 20 倍。而我們遇到的第一個 bug 就是在數(shù)據(jù)增強階段。
2. Bug in Data Augmentation
我們可以按照官方給出的代碼對數(shù)據(jù)進行增強操作,但是在 QNLI 上會報錯:

造成數(shù)據(jù)增強到一半程序就崩潰了,為什么呢?
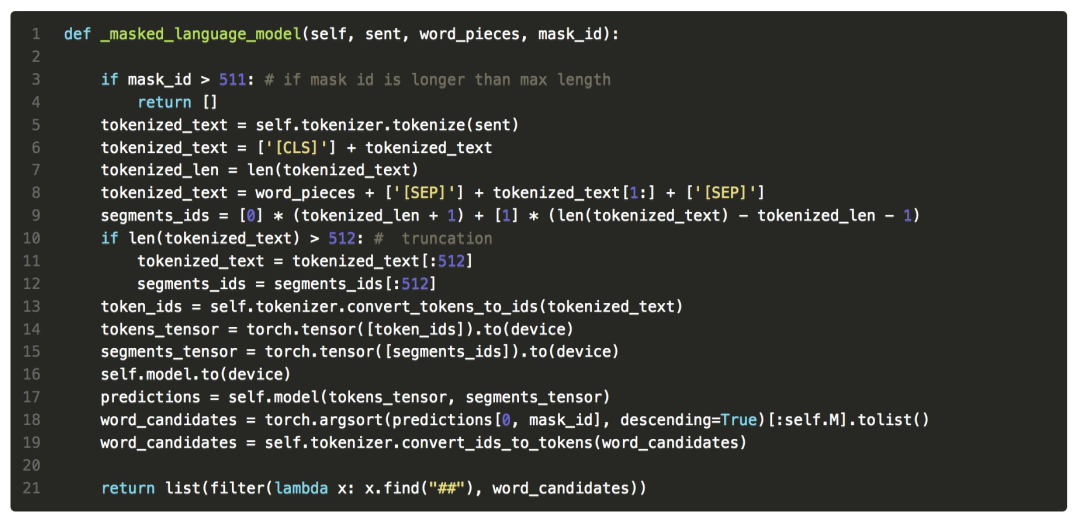
很簡單,因為數(shù)據(jù)增強代碼 BERT MLM 換詞模塊對于超長(> 512)的句子沒有特殊處理,造成下標越界,具體可以參考 #Issue50:error occured when apply data_augmentation on QNLI and QQP dataset[7]。
在對應(yīng)的函數(shù)中進行邊界的判斷即可:
3. Acceleration of Data Parallel
當我們費勁愉快地完成數(shù)據(jù)增強之后,下一步就是要進行 Task Specific 蒸餾里的 Step 1,General Distillation 了。
對于一些小數(shù)據(jù)集像 MRPC,增廣 20 倍之后的數(shù)據(jù)量依舊是 80k 不到,因此訓(xùn)練速度還是很快的,20 輪單卡大概半天也能跑完。但是對于像 MNLI 這樣 GLUE 中最大的數(shù)據(jù)集(390k),20 倍增廣后的數(shù)據(jù)集(增廣就花費了大約 2 天時間),如果用單卡訓(xùn)練個 10 輪那可能得跑上半個月了,到時候怕不是黃花菜都涼咯。
3.1 多卡訓(xùn)練初步嘗試
遂打算用多卡訓(xùn)練,一看,官方的實現(xiàn)就通過 nn.DataParal lel 支持了多卡。好嘛,直接 CUDA_VISIBLE_DEVICES="0,1,2,3" 來上 4 塊卡。不跑不知道,一跑嚇一跳:
加載數(shù)據(jù)(tokenize, padding )花費 1小時;
好不容易跑起來了,一開 nvidia-smi 發(fā)現(xiàn) GPU 的利用率都在 50% 左右;
再一看預(yù)估時間,大約 21h 一輪,10 epoch 那四舍五入就是一個半禮拜。
好家伙,這我還做不做實驗了?
3.2 DDP 替換 DP
這時候就去翻看 PyTorch 文檔,發(fā)現(xiàn) PyTorch 現(xiàn)在都不再推薦使用 nn.DataParallel 了,為什么呢?主要原因在于:
DataParallel 的實現(xiàn)是單進程的,每次都是有一塊主卡讀入數(shù)據(jù)再發(fā)給其他卡,這一部分不僅帶來了額外的計算開銷,而且會造成主卡的 GPU 顯存占用會顯著高于其他卡,進而造成潛在的 batch size 限制;
此外,這種模式下,其他 GPU 算完之后要傳回主卡進行同步,這一步又會受限于 Python 的線程之間的 GIL(global interpreter lock),進一步降低了效率。
此外,還有多機以及模型切片等 DataParallel 不支持,但是另一個 DistributedDataParallel 模塊支持的功能。
所以得把原先 TinyBERT DP(DataParallel)改成 DDP(DistributedDataParallel)。把 DP 改成 DDP 可以參考知乎-當代研究生需要掌握的并行訓(xùn)練技巧[8]。核心的代碼就是做一下初始化,以及用 DDP 替換掉 DP:
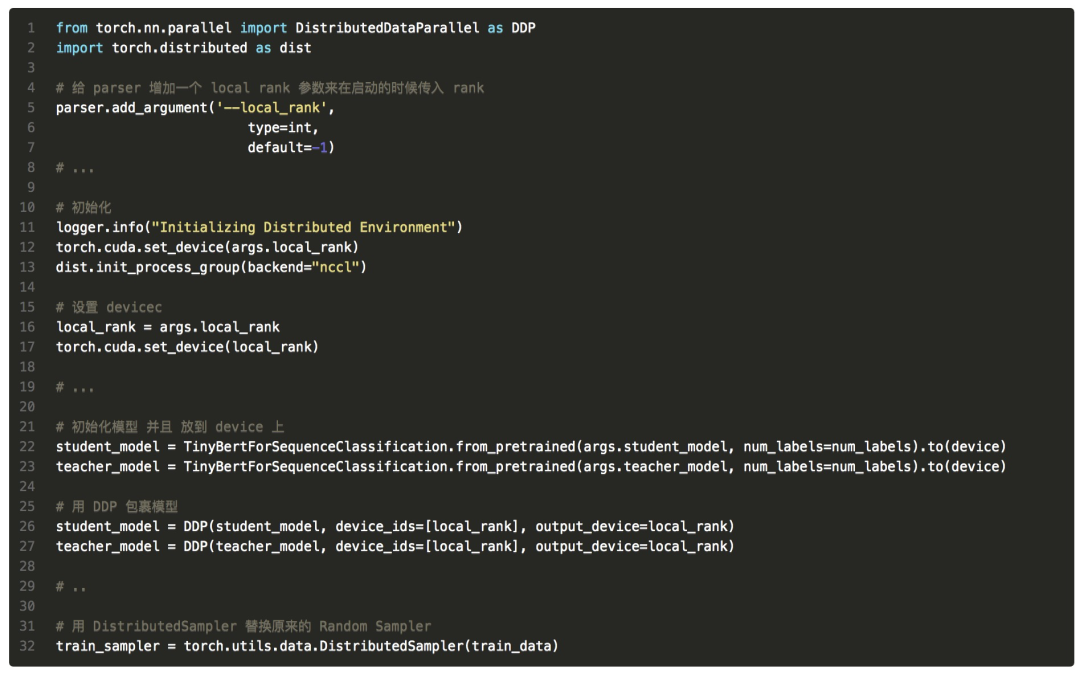
然后,大功告成,一鍵啟動:

啟動成功了嗎?模型又開始處理數(shù)據(jù)….
One hours later,機器突然卡住,程序的 log 也停了,打開 htop 一看:好家伙,256G 的內(nèi)存都滿了,程序都是 D 狀態(tài),這是咋回事?
4. Acceleration of Data Loading
我先試了少量數(shù)據(jù),降采樣到 10k,程序運行沒問題, DDP 速度很快;我再嘗試了單卡加載,雖然又 load 了一個小時,但是 ok,程序還是能跑起來,那么,問題是如何發(fā)生的呢?
單卡的時候我看了一眼加載全量數(shù)據(jù)完畢之后的內(nèi)存占用,大約在 60G 左右,考慮到 DDP 是多進程的,因此,每個進程都要獨立地加載數(shù)據(jù),4 塊卡 4個進程,大約就是 250 G 的內(nèi)存,因此內(nèi)存爆炸,到后面數(shù)據(jù)的 io 就卡住了(沒法從磁盤 load 到內(nèi)存),所以造成了程序 D 狀態(tài)。
看了下組里的機器,最大的也就是 250 G 內(nèi)存,也就是說,如果我只用 3 塊卡,那么是能夠跑的,但是萬一有別的同學(xué)上來開程序吃了一部分內(nèi)存,那么就很可能爆內(nèi)存,然后就是大家的程序都同歸于盡的局面,不太妙。
一種不太優(yōu)雅的解決方案就是,把數(shù)據(jù)切塊,然后讀完一小塊訓(xùn)練完,再讀下一塊,再訓(xùn)練,再讀。咨詢了一下組里資深的師兄,還有一種辦法就是實現(xiàn)一種把數(shù)據(jù)存在磁盤上,每次要用的時候才 load 到內(nèi)存的數(shù)據(jù)讀取方案,這樣就能夠避免爆內(nèi)存的問題。行吧,那就干吧,但是總不能從頭造輪子吧?
臉折師兄提到 huggingface(yyds) 的 datasets[9] 能夠支持這個功能,check 了一下文檔,發(fā)現(xiàn)他是基于 pyarrow 的實現(xiàn)了一個 memory map 的數(shù)據(jù)讀取[10],以我的 huggingface transformers 的經(jīng)驗,似乎是能夠?qū)崿F(xiàn)這個功能的,所以摩拳擦掌,準備動手。
首先,要把增廣的數(shù)據(jù) load 進來,datasets 提供的 load_dataset 函數(shù)最接近的就是 load_dataset('csv', data_file),然后我們就可以逐個 column 的拿到數(shù)據(jù)并且進行預(yù)處理了。
寫了一會,發(fā)現(xiàn)總是報讀取一部分數(shù)據(jù)后 columns 數(shù)目不對的錯誤,猜測可能原始 MNLI 數(shù)據(jù)集就不太能保證每個列都是在的,檢查了一下 MnliProcessor 里處理的代碼,發(fā)現(xiàn)其寫死了 line[8] 和 line[9] 作為 sentence_a 和 sentence_b。無奈之下,只能采取最粗暴地方式,用 text mode 讀進來,每一行是一個數(shù)據(jù),再 split:
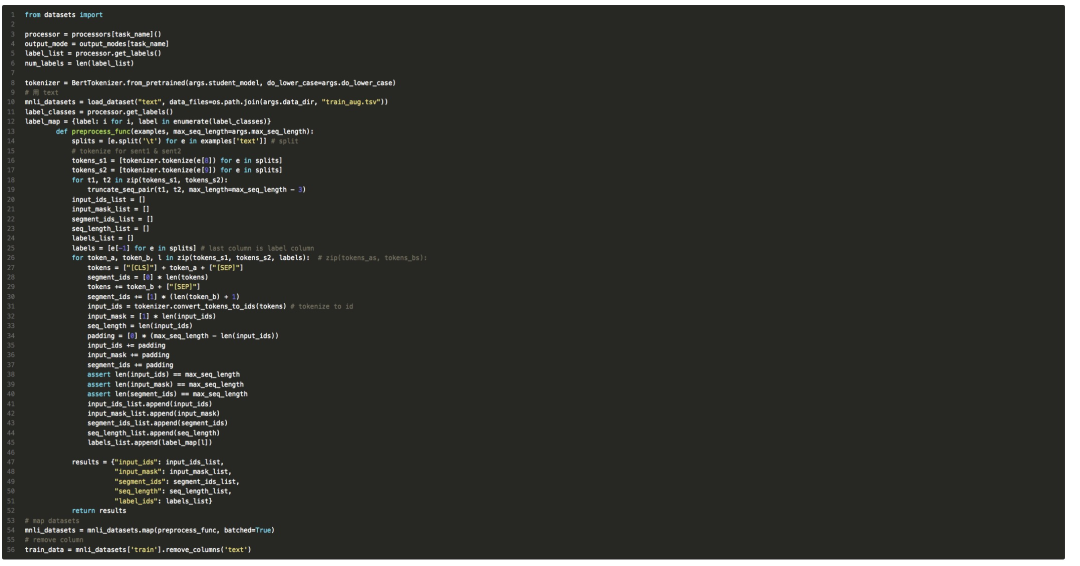
寫完這個 preprocess_func ,我覺得勝利在望,但還有幾個小坑需要解決s:
map 完之后,返回的還是一個 DatasetDict,得手動取一下 train set;
對于原先存在的列,map 函數(shù)并不會去除掉,所以如果不用的列,需要手動 .remove_columns()
在配合 DDP 使用的時候,因為 DistributedSample 取數(shù)據(jù)的維度是在第一維取的,所以取到的數(shù)據(jù)可能是個 seq_len 長的列表,里面的 tensor 是 [bsz] 形狀的,需要在交給 model 之前 stack 一下:

至此,只要把之前代碼的 train_data 都換成現(xiàn)在的版本即可。
此外,為了進一步加速,我還把混合精度也整合了進來,現(xiàn)在 Pytorch 以及自帶對混合精度的支持,代碼量也很少,但是有個坑就是loss 的計算必須被 auto() 包裹住,同時,所有模型的輸出都要參與到 loss 的計算,這對于只做 prediction 或者是 hidden state 對齊的 loss 很不友好,所以只能手動再額外計算一項為系數(shù)為 0 的 loss 項(這樣他參與到訓(xùn)練但是不會影響梯度)。
總結(jié)
最后,改版過的代碼在我的 GitHubfork[11]版本中,我不要臉地起名為fast_td。實際上,改版后的有點有一下幾個:
數(shù)據(jù)加載方面:第一次加載/處理 780w 大約耗時 50m,但是不會多卡都消耗內(nèi)存,實際占用不到 2G;同時,得益于 datasets 的支持,后續(xù)加載不會重復(fù)處理數(shù)據(jù)而是直接讀取之前的 cache;
模型訓(xùn)練方面:得益于 DDP 和 混合精度,在 MNLI 上訓(xùn)增強數(shù)據(jù) 10 輪,3 塊卡花費的時間大約在 20h 左右,提速了 10 倍。
-
模型
+關(guān)注
關(guān)注
1文章
3274瀏覽量
48953 -
project
+關(guān)注
關(guān)注
0文章
35瀏覽量
13301 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24744
原文標題:4. Acceleration of Data Loading
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦

IAP功能實現(xiàn)過程遇到的坑
Linux學(xué)習(xí)過程踩過的坑與如何解決踩坑
mongoose開發(fā)中遇到的坑及解決方案
STC8H8K64U芯片學(xué)習(xí)過程中遇到的問題及對應(yīng)解決方案
分享基于STM32 4x4鍵盤掃描嘗試過程中踩到的雷
在RT-Thread開發(fā)過程中引入watchdog踩到的坑
記錄一個在使用BlackBox中parameter踩到的坑
記錄BL808 BSP添加GPIO驅(qū)動時踩到的一些坑及解決方案
光端機在使用過程中遇到的常見問題及對應(yīng)的解決方案
使用Redis時可能遇到哪些「坑」?
模型調(diào)優(yōu)和復(fù)現(xiàn)算法遇到的一些坑
RLHF實踐中的框架使用與一些坑 (TRL, LMFlow)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論