 MCM應用于GPU還需要多久
MCM應用于GPU還需要多久
消費用戶市場,普通用戶都能用上16核甚至64核處理器的PC。這可不是單純堆核心就完事兒的。以當前CPU核心的規模,和可接受的成本,消費電子設備上一顆芯片就達到這種數量的核心數目,與chiplet的應用是分不開的。
Chiplet是這兩年業界的香餑餑。前不久的ISSCC會議上,chiplet也是今年的熱門議題。AMD從Zen架構開始,Ryzen系列處理器就全面應用了chiplet技術。Chiplet并不是什么新技術,更早提的MCM(multi-chip module)就是應用了chiplet的一種芯片方案。
簡單來說,MCM通常是指將多個die(多個IC或chips)封裝到一起的多芯片模組。構成MCM的一個個die,或者功能電路模塊,即是chiplet。多個chiplet之間能夠協作,構成更大的芯片,也就是MCM(有時,MCM/Multi-chip Package又被當做某一類封裝方式)。
不過本文探討的MCM/chiplet可能有一定程度的窄化,這里不探討類似Intel Kaby Lake G那一類方案,即便它算是典型的chiplet應用(以及像很多近代Intel處理器那樣只將處理器die和PCH die分開的那類chiplet,以及HBM存儲chiplet)。可能單純稱其為MCM會更合理。
以AMD的Ryzen 3000系列處理器為例,每4個核心(外加cache)組成一個CCX,兩個CCX就組成一個CCD——也就是一個die或chiplet。一顆處理器芯片上就會有多個這樣的CCD。另外還有個I/O die作為通訊中心(cIOD),連接各個die,如上圖所示。
值得一提的是,Ryzen 3000處理器的CCD部分制造采用7nm工藝,而cIOD則選擇了12nm工藝,這就很能體現chiplet在制造上物盡其用、節約成本的優越性了。
如果說處理器的chiplet/MCM商用已經全面落地,那么die size更大的GPU能不能也采用MCM的方案?這是本文要探討的話題,MCM應用于GPU還需要多久?借此也能窺見chiplet作為此類高算力芯片的技術方向時,半導體制造已經走到了哪里。
當GPU的die尺寸大到嚇人的程度時
如果只看消費市場,骨灰級玩家對GPU算力的追求是無止盡的。只怕算力不夠,不怕價格、功耗有多夸張。圖形算力的饑渴從未停止過:1998年3dfx引入SLI技術,即2個或者更多的顯卡一起上,實現更大規模的圖形并行計算。
SLI同類技術(包括AMD的CrossFire)并未大規模普適,主要是因為這樣的技術不僅有硬件級別的支持要求,而且對游戲開發者也有要求。在很多不支持多GPU并行計算的游戲中,此類方案甚至會令游戲體驗變差。不過多GPU擴展的方案,在當代數據中心還是比較常見的。
基于這個思路,如果將多GPU的層級下沉到多die——也就是一個GPU之上,有多個chiplet,堆砌更多的圖形計算單元,好像也是完全行得通的方案。只不過多GPU(或多芯顯卡)需要跨系統或者跨板級,而多die則是基于同一個基板的封裝級方案,延遲和帶寬理論上也比跨PCB板更有優勢才對。
那么為什么不直接將現在的GPU做得更大,在一顆die上堆更多的計算資源呢(也就是所謂的monolithic)?如果摩爾定律恒定持續,同面積內容納更多晶體管,則這種方案是可持續的。但在摩爾定律放緩的情況下,要在一顆die上塞下更多的圖形計算核心,尺寸和成本都是無法接受的。
目前的顯卡主流產品,AMD Radeon RX 6900XT的單die尺寸達到了519mm2,英偉達Geforce RTX 3090則達到628mm2。這種die尺寸也算是不惜血本的代表了,逐漸逼近光刻機可處理的最大尺寸(rectile limit, 858mm2)。未來再給GPU加計算核心,單die方案會有極大難度。這是GPU考慮MCM/chiplet方案的先決條件。
從成本來看,這個問題大概會更明朗。即便不考慮切割大面積晶圓可能造成良率低下的問題,更小die也能帶來更高的成本效益。300mm的wafer滿打滿算造114片22x22mm(接近Vega 64尺寸)片單die;如果切分成更小的11x11mm,即原有每片die可獲得4片更小的die,則很大程度減少了晶圓切割邊緣浪費,就能造488片die——如果這些die在理想情況下每4片組成一顆MCM芯片,則產量就高了大約8%。
當然這其中并未考慮wafer不同形狀的優化方案,也沒有考慮制造缺陷之類的問題,而且MCM芯片還需要耗費更多的die來做專門的通訊(比如前文提到Ryzen處理器的I/O die)。但chiplet/MCM能夠實現的成本節約仍然是顯著的。
EE Times專欄作者Don Scansen前不久撰文提到,“AMD計算出,以Chiplet方法制作EPYC處理器時,會需要比單一芯片多出10%的硅晶圓面積做為裸晶對裸晶(die-to-die)的通訊功能區塊、冗余邏輯(redundant logic)以及其他附加功能,但最后整個chiplet形式處理器的芯片成本,比單芯片處理器節省了41%。”
總結一句話,chiplet/MCM本質上是在摩爾定律止步不前的當下,為進一步提高芯片算力,采用的一種控制成本的方案。這里的成本控制實際上還表現在IP的復用和彈性,chiplet有時可以“復制粘貼”的模塊化方式,靈活地存在于芯片之上。AMD如今的Ryzen處理器能夠如此便捷地堆核心,并且在多線程性能表現出對Intel的碾壓優勢,和chiplet是分不開的。
GPU應用chiplet的阻礙
不過GPU要應用chiplet卻并不是一件簡單的事,就好像顯卡SLI(或雙芯顯卡)經過了這么多年,都并未普及開一樣。Raja Koduri此前還在AMD的時候提過,GPU可能會采用Infinity Fabric方案(AMD Ryzen處理器的一種互聯方案);這在當時被認為是MCM型GPU提出的依據。不過眾所周知Raja Koduri后來就離開了AMD,此間規劃的延續性是未知的。
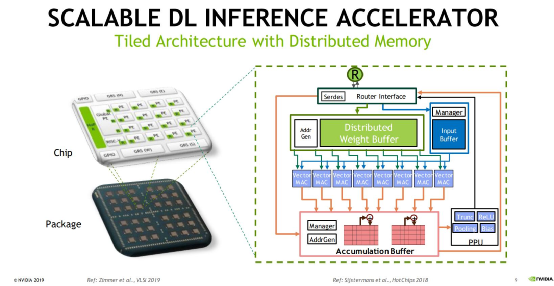
2019年英偉達宣布實驗室打造一款名為RC18的AI處理器。這顆處理器采用16nm工藝,更重要的是選擇了多die解決方案。芯片整體包含36個小型模塊,每個模塊主要由16個PE(Processing Elements)構成,外加RISC-V核及對應的緩存,另外還有英偉達的GRS(Ground-Referenced Signaling)互聯。當時英偉達提到,RC18的存在表明很多技術的可行性,包括可擴展的深度學習架構,以及高效的die-to-die方案。
這顆芯片對于未來的chiplet型GPU而言可能是個重要模板。不過對于圖形計算的GPU而言,在同一顆芯片上渲染畫面幀,要分配到不同chiplet之上,難度還是會比這類AI芯片更大的。2018年AMD RTG團隊高級副總裁David Wang在接受PCGamesN采訪時,曾經提到過MCM GPU要實現起來并不簡單。“我們在看MCM型的實現方法,但目前尚無法定論,傳統游戲圖形計算會應用類似技術。”
“從某種角度來看,其實這也就是在單一封裝上去做CrossFire(AMD版的SLI方案)。其挑戰在于,我們需要能夠做到在硬件層面對開發者不可見,否則其發展就不會順利。”而且,“GPU在NUMA(非一致性內存訪問)架構以及一些特性方面有著一定的限制……”,尤其相比CPU,圖形計算負載的這種設定會更有難度。
這話的意思是指,第一,如果MCM GPU需要游戲開發者去花額外的時間做開發上的調整,或者增加開發難度,則成為推廣MCM GPU的阻礙。第二,不同die之間互聯效率、數據一致性問題:包括在chiplet之間切分圖形計算管線,以及彼此之間存儲訪問的差異性,都會給設計帶來更高的復雜度。
SLI——即以前的多GPU(或板級多芯片GPU)方案實際上是這兩個問題的放大版本。面向開發者時開發難度大;不同GPU之間的工作部署有難度。(而且多GPU方案非常依賴于多層級的系統互聯,這個過程中的數據遷移、同步帶來的功耗問題也比較大;所以最終互聯,達成的有效帶寬和每比特消耗的能量都不盡人意)
其中后一個問題也是chiplet技術演進探討的熱門議題,即便已經商用的chiplet CPU產品,依舊在互聯方面有著持續改進的空間。
Chiplet即將應用于GPU的幾個先兆
MCM GPU真正在這兩年呼聲特別高也不是沒有原因的。其中有幾件標志性事件可能表明MCM GPU離我們并不遙遠了——即便最早一批MCM GPU可能會是面向數據中心的,并在后續才逐漸下放到游戲和圖形計算市場。
首先是Intel這邊,Raja Koduri(沒錯,就是之前AMD的那位)今年一月份在Twitter上發布了一條推文,展示Intel即將推向市場的Xe HPC,如上圖所示——有關Xe GPU,此前介紹十一代酷睿的核顯文章曾大致談到過。Xe面向HPC高性能計算時,作為獨立GPU形態存在。
這枚代號為Ponte Vecchio的芯片看起來還是蔚為壯觀的。就這張圖片來看,這顆GPU計算核心可能主要由上下兩個chiplet構成,圍繞四周的應該是HBM存儲,還有I/O或者其他屬于Xe特性的組成部分。Chiplet之間可能采用Intel的EMIB(Embedded Multi-die Interconnect Bridge)連接。此前Intel也提過Ponte Vecchio之上應用了Foveros 3D堆疊技術,具體情況未知。不過chiplet在GPU上的應用,或者說真正的MCM GPU,在此也是初見端倪的。
除此之外,2019年底Twitter傳出一則泄露消息,稱英偉達新一代Hopper架構(Ampere后續架構)GPU將以MCM的形態問世。
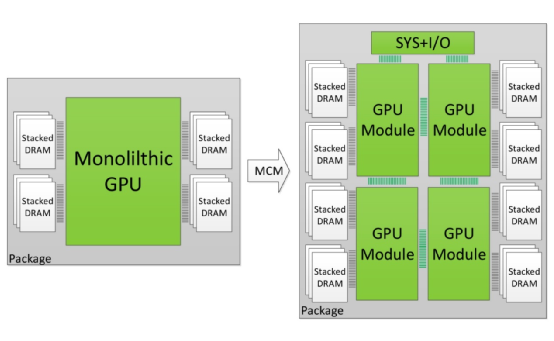
來源:MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability, Nvidia
事實上,英偉達在2017年的ISCA上就發表過一篇題為MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability的paper。雖然這篇paper中提到的方法,只是在英偉達實驗室里以模擬的方式將MCM GPU,與單die GPU和多GPU方案進行比較,不過表明英偉達的確是有在探討其可行性的。
這篇paper有具體探討不同層級的多芯片方案,比如SLI那樣的多顯卡方案,以及板級多芯方案、同封裝下的多die方案、單die方案等,互聯帶寬和開銷問題;并且認定當代技術儲備,比如說substrate尺寸、die之間信號通訊技術(如英偉達的GRS)都正走向成熟,給MCM GPU的實現開創了技術條件。

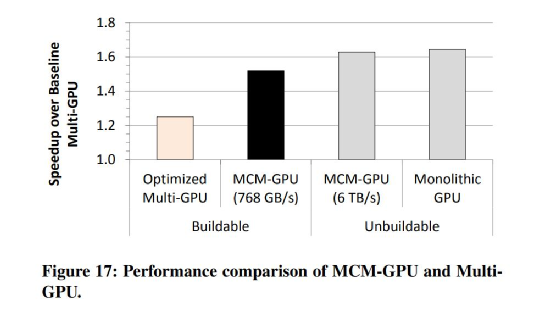
此外這篇paper提到了幾個優化方案,包括引入L1.5 cache,不同chiplet之間線程調度和數據劃分方案。從這套方案的結果來看(如上圖),雖然某些測試項有不盡人意之處,但整體上MCM GPU能夠實現在性能上比多GPU方案的顯著領先(且功耗遙遙領先,0.5 pJ/bit vs 10 pJ/bit),而且性能較同計算硬件資源的單die方案,并沒有太大損失(而且需要注意,這種單die方案現實中是造不出來的)。而相比目前能夠制造的最大單die方案(128 SM單元),英偉達預設中的這套方案有45.5%的性能優勢。
文中提及將這樣的方案應用在HPC大規模集群中,能夠極大提升性能密度,系統層級減少機柜數量,以及對應的系統級網絡、通訊規模變小。最終實現通訊、供電、制冷系統的耗電量極大節約。只不過這篇paper,整體上更多仍停留于紙面和模擬。
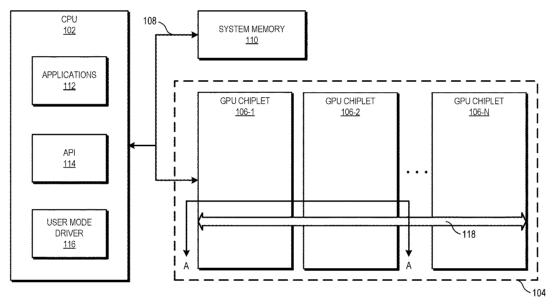
最后AMD作為已經在CPU之上推開chiplet的市場玩家,今年年初浮現一則其2019年申請的專利,名為”GPU Chiplets using High Bandwidth Crosslinks”。這項專利的很大一部分,旨在解決MCM GPU在開發層面困難的問題。
這項專利提到系統中包含一個CPU。它在通訊上與GPU chiplet陣列的第一顆chiplet連接。CPU和這顆GPU chiplet通過一條總線連接;而這顆GPU chiplet和后面的chiplet則通過一種passive crosslink連接。這里的passive crosslink實際上是個被動interposer die,專門用于chiplet之間的通訊,以及負責將SoC功能切分成更小的chiplet。(如上圖所示)
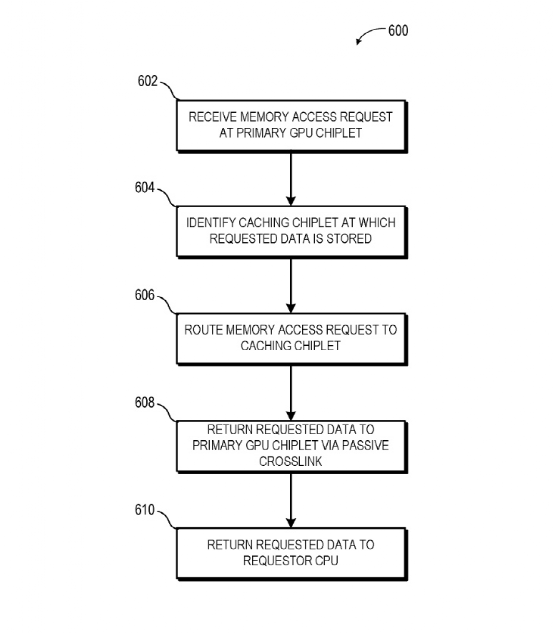
針對存儲一致性問題,每顆GPU chiplet都會有其各自的LLC(last-level cache),也就是L3 cache。LLC跨所有的chiplet實現一致性,也是實現跨chiplet存儲一致性乃至提升MCM GPU效率的關鍵。
這套系統中,僅第一顆GPU chiplet接收來自CPU的請求,這樣一來對CPU而言,GPU就好像是傳統的單die方案一樣,對圖形計算開發也就比較友好了。未知AMD是否已將這項專利付諸實現,GPU本身內部的通訊延遲理論上可能會更高。
不過如前所述,MCM GPU最早應用的理論上可能還是數據中心、HPC這些領域。畢竟如英偉達在paper中所述,這樣的設計對于數據中心具備了更天然的替代優勢。而在技術逐步準備就緒之際,MCM GPU的出現的確只是時間問題,包括下放到游戲市場。Intel、AMD和英偉達,哪家將率先踏出這一步,也是值得拭目以待的。
-
處理器
+關注
關注
68文章
19349瀏覽量
230324 -
gpu
+關注
關注
28文章
4754瀏覽量
129083 -
MCM
+關注
關注
1文章
68瀏覽量
22353
原文標題:GPU越做越大,快到極限了怎么辦?
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADC324x的CLK和SYSREF信號由CDCE62005提供合適嗎?是否還需要向FPGA提供SYSREF信號?
ADS1293EVM如果用ubs連接電腦,還需要外部供電嗎?
請問DP83822IRHB該PHY要配成RGMII時,到底還需要哪些配置?
DAC5681z從FPGA讀數據,為什么還需要一個DCLKP/N呢?
企業上云后還需要數據庫運維嗎?真實答案看過來!
通過DSP6455的MCBSP配置TLV320AIC20,如果想使用LINEI和LINEO,還需要哪些別的配置嗎?
為什么FPGA屬于硬件,還需要搞算法?

有了MES、ERP,為什么還需要QMS?





 工商網監
工商網監
評論