") 深度學(xué)習(xí)技術(shù)在圖像處理領(lǐng)域的主要應(yīng)用
深度學(xué)習(xí)技術(shù)在圖像處理領(lǐng)域的主要應(yīng)用
導(dǎo)讀
圖像處理領(lǐng)域是深度學(xué)習(xí)和機(jī)器視覺(jué)領(lǐng)域重要的研究分支,本文第一部分將介紹深度學(xué)習(xí)中圖像處理的常用技巧,第二部分則會(huì)淺析深度學(xué)習(xí)中圖像處理的主流應(yīng)用。
導(dǎo)言
近年以來(lái),隨著深度學(xué)習(xí)在圖像識(shí)別領(lǐng)域取得巨大突破(以AI之父Geoffry Hinton在2012年提出的高精度AlexNet圖像識(shí)別網(wǎng)絡(luò)為代表),掀起了以神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的深度學(xué)習(xí)研究熱潮。目前為止,圖像處理已成為深度學(xué)習(xí)中重要的研究領(lǐng)域,幾乎所有的深度學(xué)習(xí)框架都支持圖像處理工具。
當(dāng)前深度學(xué)習(xí)在圖像處理領(lǐng)域的應(yīng)用可分為三方面:圖像處理(基本圖像變換)、圖像識(shí)別(以神經(jīng)網(wǎng)絡(luò)為主流的圖像特征提取)和圖像生成(以神經(jīng)風(fēng)格遷移為代表)。本文第一部分介紹深度學(xué)習(xí)中圖像處理的常用技巧,第二部分淺析深度學(xué)習(xí)中圖像處理的主流應(yīng)用,最后對(duì)本文內(nèi)容進(jìn)行簡(jiǎn)要總結(jié)。
一.深度學(xué)習(xí)中圖像處理的常見(jiàn)技巧
目前幾乎所有的深度學(xué)習(xí)框架均支持圖像處理工具包,包括Google開(kāi)發(fā)的Tensorflow、Microsoft的CNTK等。以操作簡(jiǎn)單的Keras前端,Tensorflow后端開(kāi)發(fā)框架為例介紹圖像處理中的常見(jiàn)操作技巧:
1. 數(shù)據(jù)增強(qiáng)
制約深度學(xué)習(xí)發(fā)展的三要素分別為算法、算力和數(shù)據(jù),其中算法性能由設(shè)計(jì)方式?jīng)Q定,算力供給的關(guān)鍵在于硬件處理器效能,算法和算力相同時(shí),數(shù)據(jù)量的多少直接決定模型性能的最終優(yōu)劣。進(jìn)行圖像識(shí)別時(shí),經(jīng)常出現(xiàn)因原始圖像數(shù)目不足而導(dǎo)致的輸出曲線過(guò)擬合,從而無(wú)法訓(xùn)練出能泛化到新圖像集上的模型。數(shù)據(jù)增強(qiáng)根據(jù)當(dāng)前已知的圖像數(shù)據(jù)集生成更多的訓(xùn)練圖像,具體實(shí)現(xiàn)是利用多種能夠生成可信圖像的隨機(jī)變換來(lái)增加原始圖像數(shù)量。數(shù)據(jù)增強(qiáng)前后的對(duì)比結(jié)果如圖1所示:

圖1a 原始圖像

圖1b 數(shù)據(jù)增強(qiáng)后的圖像
其中關(guān)鍵代碼如下(定義增強(qiáng)數(shù)據(jù)的操作,包括縮放,平移和旋轉(zhuǎn)等):

對(duì)比可知,數(shù)據(jù)增強(qiáng)的實(shí)質(zhì)是在未改變?cè)紙D像特征內(nèi)容的基礎(chǔ)上(例如上圖中的關(guān)鍵對(duì)象:貓、鐵籠、食物)對(duì)圖像數(shù)量的擴(kuò)充,從而避免因圖像不足而導(dǎo)致的模型過(guò)擬合與泛化性差等缺陷,在小型圖像數(shù)據(jù)集上進(jìn)行訓(xùn)練時(shí)尤其有效。
2. 圖像去噪
現(xiàn)實(shí)的圖像在傳播過(guò)程中,由于傳輸波動(dòng)和受外界噪聲干擾而很容易引起圖像質(zhì)量下降。圖像去噪是指濾除圖像包含的干擾信息而保留有用信息,常見(jiàn)去噪方法包括非局部平均過(guò)濾算法、高斯濾波算法和自適應(yīng)濾除噪聲的卷積神經(jīng)網(wǎng)絡(luò)等。簡(jiǎn)要介紹如下:
2.1 非局部平均過(guò)濾算法
非局部平均過(guò)濾算法的降噪原理如下:圖片中像素的設(shè)定通過(guò)與其周?chē)南袼攸c(diǎn)加權(quán)而成,也就是圖片中某點(diǎn)的像素設(shè)定和其周?chē)袼氐臋?quán)重設(shè)定有關(guān)。具體原理如下式所示:
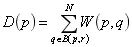
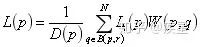
式中 代表 位置像素點(diǎn)受 位置像素點(diǎn)影響的權(quán)重大小, 代表選取像素 點(diǎn) 周?chē)霃綖?范圍內(nèi)的像素點(diǎn)作為加權(quán)參照。 和 分別代表像素點(diǎn)周?chē)?素權(quán)值的大小統(tǒng)計(jì)和像素點(diǎn)受周?chē)?半徑內(nèi)像素影響的加權(quán)總和。
對(duì)原始圖像添加噪聲,隨機(jī)設(shè)定3000個(gè)像素點(diǎn)為白色(RGB值均為255),可以看出添加噪聲后的圖像相對(duì)原始圖像增添了許多噪聲白斑,如圖2所示:

圖2a 原始海灘背景圖像

圖2b 添加噪聲后的背景圖像
然后使用openCV內(nèi)置的非局部平均噪聲過(guò)濾算法濾除圖片噪聲,結(jié)果如圖3所示:

圖3 非局部平均噪聲濾波后得到的背景圖像
觀察非局部平均噪聲算法濾波前后的圖像,可知濾波后圖像的白斑噪聲點(diǎn)明顯減少,圖像的質(zhì)量得到有效提升,有利于后續(xù)的編碼處理和傳輸。
2.2 去噪神經(jīng)網(wǎng)絡(luò)
去噪神經(jīng)網(wǎng)絡(luò)通常是以CNN(卷積神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)),其實(shí)質(zhì)是:利用在無(wú)噪圖像集上訓(xùn)練完成的去噪模型,濾除預(yù)測(cè)圖像中包含的噪聲信息。使用圖像識(shí)別中最常見(jiàn)的mnist手寫(xiě)圖像庫(kù)為訓(xùn)練集,mnist包含6萬(wàn)張訓(xùn)練集圖像和1萬(wàn)張測(cè)試集圖像,其大小均為28*28,按照?qǐng)D像內(nèi)容的不同分為手寫(xiě)數(shù)字0-9,mnist數(shù)據(jù)庫(kù)內(nèi)置于keras中。搭建去噪神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),如圖4所示:
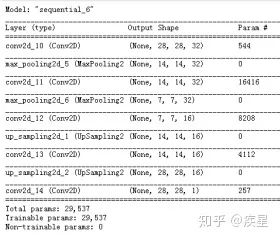
圖4 簡(jiǎn)單的去噪神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
使用去噪神經(jīng)網(wǎng)絡(luò)對(duì)mnist圖像庫(kù)中添加噪聲的圖像去噪,去噪前后對(duì)比結(jié)果如圖5、圖6所示,其中下標(biāo)相同的Noise與Fliter相對(duì)應(yīng):

圖5 對(duì)原始圖像添加噪聲
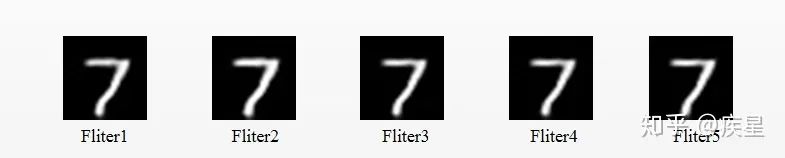
圖6 使用去噪神經(jīng)網(wǎng)絡(luò)濾除噪聲
觀察去噪前后圖片可知,去噪神經(jīng)網(wǎng)絡(luò)通過(guò)特征提取和監(jiān)督學(xué)習(xí)等方式,對(duì)Mnist手寫(xiě)圖像集實(shí)現(xiàn)了非必要噪聲信息濾除,是簡(jiǎn)單常用的圖像去噪器。
2.3 圖像超分辨率重建(SR,Super Resolution)
SR是圖像處理中的經(jīng)典應(yīng)用,是圖像增強(qiáng)領(lǐng)域的重要技術(shù)。其基本思想是通過(guò)提取低分辨率的原始圖像特征來(lái)重構(gòu)高分辨率的圖像。按照其參考低分辨率圖像種類(lèi)和數(shù)目的不同,主要分為以下兩種:
Image SR:特點(diǎn)是重構(gòu)圖像時(shí),可供參考的原始低分辨率圖像少,通常不依賴(lài)于其他圖像而只參考當(dāng)前的低分辨率圖像,也稱(chēng)為單圖超分辨率(SISR,single image super resolution)。
Video SR:特點(diǎn)是重構(gòu)圖像需要參照多個(gè)不同的原始低分辨率圖像,也稱(chēng)為多幀超分辨率(MFSR,multi-frame super resolution)。通常MFSR相對(duì)SISR具有更高的重構(gòu)質(zhì)量和更多的特征匹配,代價(jià)是計(jì)算資源的更多消耗。
SR重構(gòu)質(zhì)量可通過(guò)圖像質(zhì)量評(píng)估的參考標(biāo)準(zhǔn)PSNR和SSIM進(jìn)行評(píng)價(jià),PSNR值和SSIM值越高,代表重建圖像像素值與標(biāo)準(zhǔn)值越接近。其中PSNR定義如下(MSE代表圖像評(píng)估中的均方誤差):
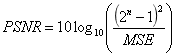 其中MSE的定義如下:
其中MSE的定義如下:
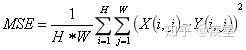
SSIM定義簡(jiǎn)化如下(其中代表 均值, 代表均方差):
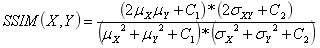
近年以來(lái),圖像超分辨率重建技術(shù)逐漸成為深度學(xué)習(xí)領(lǐng)域的研究熱點(diǎn),先后涌現(xiàn)出SRCNN(Super-Resolution Convontional Netural Network,超分辨率卷積神經(jīng)網(wǎng)絡(luò))和FSRCNN(Fast Super-Resolution Convontional Netural Network,快速超分辨卷積神經(jīng)網(wǎng)絡(luò))等超分辨率重構(gòu)結(jié)構(gòu),分別介紹如下:
SRCNN:SRCNN是香港中文大學(xué)在2014年提出的一種Image SR重構(gòu)網(wǎng)絡(luò),核心結(jié)構(gòu)是利用CNN網(wǎng)絡(luò)對(duì)原始的低分辨率圖像進(jìn)行特征提取和映射,最后完成高分辨率圖像重構(gòu),其實(shí)質(zhì)是利用深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)稀疏自編碼器。SRCNN網(wǎng)絡(luò)核心結(jié)構(gòu)如圖7所示:
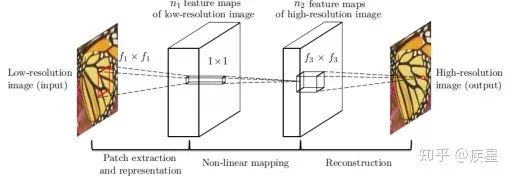
圖7 SRCNN網(wǎng)絡(luò)的結(jié)構(gòu)示意圖
如圖7所示,SRCNN網(wǎng)絡(luò)完成圖像超分辨率轉(zhuǎn)換的過(guò)程分為三部分:首先通過(guò)插值法對(duì)原始低分辨率圖像進(jìn)行維度擴(kuò)展,目標(biāo)是保證輸入網(wǎng)絡(luò)的圖像與目標(biāo)圖像尺寸相同;然后將拓展后的原始圖像通過(guò)卷積網(wǎng)絡(luò)擬合的非線性映射進(jìn)行特征提取,完成低分辨率特征圖到高分辨率特征圖的映射。CNN特征提取網(wǎng)絡(luò)是SRCNN網(wǎng)絡(luò)的關(guān)鍵結(jié)構(gòu),文中采用的特征提取網(wǎng)絡(luò)為3層堆疊的CNN;最后根據(jù)獲得的高分辨率圖像特征對(duì)目的圖片進(jìn)行維度與內(nèi)容的組合重建,輸出生成的高分辨率圖像。
對(duì)比SRCNN網(wǎng)絡(luò)與同類(lèi)算法進(jìn)行的高分辨率圖像重構(gòu),結(jié)果如圖8所示:

圖8a 對(duì)相同的圖像使用不同超分辨率方法重構(gòu)

圖8b 常見(jiàn)超分辨重構(gòu)方法的PSNR和SSIM標(biāo)準(zhǔn)評(píng)估
如圖8所示,相同條件下SRCNN網(wǎng)絡(luò)的SSIM和PSNR值絕大多數(shù)情況下優(yōu)于傳統(tǒng)算法,說(shuō)明SRCNN網(wǎng)絡(luò)的編碼質(zhì)量相對(duì)傳統(tǒng)算法有所提升。與傳統(tǒng)超分辨算法相比,SRCNN網(wǎng)絡(luò)具有結(jié)構(gòu)原理簡(jiǎn)單、重構(gòu)質(zhì)量高等優(yōu)點(diǎn),不足之處在于圖像的轉(zhuǎn)換重構(gòu)速率較低。
FSRCNN:FSRCNN網(wǎng)絡(luò)同樣由SRCNN開(kāi)發(fā)團(tuán)隊(duì)提出,目的是針對(duì)SRCNN網(wǎng)絡(luò)圖像轉(zhuǎn)換速率低的缺點(diǎn)進(jìn)行改進(jìn)。改進(jìn)后網(wǎng)絡(luò)的圖像轉(zhuǎn)換速率較SRCNN網(wǎng)絡(luò)大幅提升,圖像重構(gòu)質(zhì)量稍有提升。FSRCNN網(wǎng)絡(luò)對(duì)SRCNN網(wǎng)絡(luò)添加的改變總結(jié)如下:
維度變換上: 原始SRCNN網(wǎng)絡(luò)從圖片輸入網(wǎng)絡(luò)開(kāi)始即對(duì)其進(jìn)行插值變換,以完成與目的圖像維度匹配的維度拓展。這樣使得網(wǎng)絡(luò)開(kāi)頭增加的張量維度參與到端與端間的所有變換運(yùn)算,大大增加了網(wǎng)絡(luò)計(jì)算復(fù)雜度和運(yùn)算開(kāi)銷(xiāo)。改進(jìn)后的FSRCNN網(wǎng)絡(luò)將維度拓展的結(jié)構(gòu)放置于網(wǎng)絡(luò)終端,避免了引入網(wǎng)絡(luò)內(nèi)部的非必要運(yùn)算消耗,提高了圖像的轉(zhuǎn)換速率。
運(yùn)算結(jié)構(gòu)上: FSRCNN改進(jìn)了特征映射中的非線性映射方式,并且減小了卷積運(yùn)算時(shí)的卷積核維度,結(jié)果使得網(wǎng)絡(luò)運(yùn)算和特征提取的參數(shù)數(shù)量大幅減少、圖像的高分辨率重構(gòu)效率大為提升。由于網(wǎng)絡(luò)內(nèi)部結(jié)構(gòu)的改變,F(xiàn)SRCNN重構(gòu)圖像質(zhì)量相對(duì)SRCNN略有提升。FSRCNN與SRCNN的對(duì)比結(jié)果如圖9所示,改進(jìn)后FSRCNN網(wǎng)絡(luò)編碼質(zhì)量和效率相對(duì)傳統(tǒng)SRCNN網(wǎng)絡(luò)均有所提升。
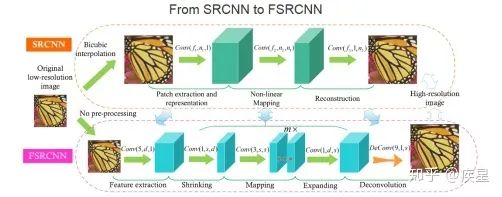
圖9a SRCNN與FSRCNN的結(jié)構(gòu)對(duì)比
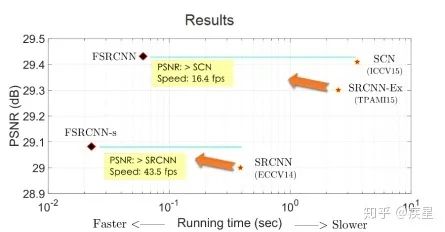
圖9b FSRCNN與SRCNN的質(zhì)量及效率對(duì)比
二.深度學(xué)習(xí)中的圖像處理應(yīng)用
當(dāng)前深度學(xué)習(xí)在圖像處理方面的應(yīng)用和發(fā)展主要?dú)w納為三方面:圖像變換、圖像識(shí)別和圖像生成,分別從這三方面進(jìn)行介紹:
1. 圖像變換
指對(duì)圖片進(jìn)行的常規(guī)操作,包括圖像縮放、復(fù)制等簡(jiǎn)單操作和上文提及的去噪、提升超分辨率等常見(jiàn)操作,其目的是提升圖片質(zhì)量,得到理想的目標(biāo)圖片。總體來(lái)說(shuō),深度學(xué)習(xí)進(jìn)行的圖像變換依賴(lài)于內(nèi)置工具的強(qiáng)大功能,使用者可根據(jù)不同需求學(xué)習(xí)對(duì)應(yīng)圖像處理工具的使用,此處不再贅述。
2. 圖像識(shí)別
計(jì)算機(jī)視覺(jué)(CV,Computering Version)已成為深度學(xué)習(xí)領(lǐng)域的重要發(fā)展方向,CV的主要內(nèi)容就是進(jìn)行目標(biāo)識(shí)別,圖像作為生活中的常見(jiàn)目標(biāo)一直是CV方向研究熱點(diǎn)。使用深度學(xué)習(xí)進(jìn)行圖像識(shí)別的通常方法是:構(gòu)建識(shí)別對(duì)象為圖像的神經(jīng)網(wǎng)絡(luò),達(dá)到圖像識(shí)別的高精度與低運(yùn)算資源消耗。
簡(jiǎn)要介紹使用神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像識(shí)別,以2013年Kaggle競(jìng)賽提供的貓狗圖像集為例,構(gòu)建圖10所示的貓狗圖像集識(shí)別神經(jīng)網(wǎng)絡(luò):
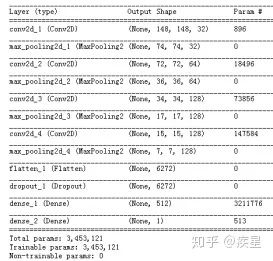
圖10 簡(jiǎn)單的貓狗圖像識(shí)別神經(jīng)網(wǎng)絡(luò)
設(shè)定訓(xùn)練輪數(shù)epochs為50,對(duì)4000張貓狗圖像進(jìn)行分類(lèi),得到圖像識(shí)別網(wǎng)絡(luò)對(duì)貓狗圖像集進(jìn)行訓(xùn)練過(guò)程中損失和精度的變化趨勢(shì),如圖11所示:
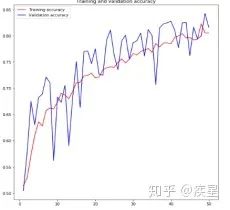
圖a 圖像識(shí)別過(guò)程中的精度變化
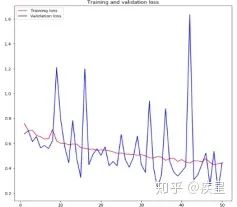
圖b 圖像識(shí)別中的損失變化
圖11 構(gòu)建圖像識(shí)別網(wǎng)絡(luò)對(duì)貓狗數(shù)據(jù)集的識(shí)別結(jié)果
由圖11可知,構(gòu)建的簡(jiǎn)單圖像識(shí)別網(wǎng)絡(luò)經(jīng)50輪迭代后,對(duì)目標(biāo)圖像集達(dá)成了80%以上的識(shí)別精度。雖然識(shí)別過(guò)程中存在過(guò)擬合現(xiàn)象,并且識(shí)別精度不盡人意,但結(jié)果證明神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像識(shí)別的簡(jiǎn)便性與可行性。圖像過(guò)擬合帶來(lái)的負(fù)面影響可以通過(guò)減少網(wǎng)絡(luò)參數(shù)量(數(shù)據(jù)削弱等)和訓(xùn)練圖像量等方法減小,目標(biāo)圖像的識(shí)別精度可以通過(guò)添加預(yù)訓(xùn)練模型等方法進(jìn)行提升。
當(dāng)前神經(jīng)網(wǎng)絡(luò)構(gòu)建的高精度圖像識(shí)別已廣泛應(yīng)用于人臉識(shí)別等智能領(lǐng)域,相關(guān)實(shí)例可上網(wǎng)查閱自行了解,本文不再贅述。

圖12 使用神經(jīng)網(wǎng)絡(luò)進(jìn)行人臉識(shí)別的結(jié)果
3. 圖像生成
圖像生成是指從已知圖像中學(xué)習(xí)特征后進(jìn)行組合,生成新圖像的過(guò)程。不同于圖像的高分辨率重建,圖像生成通常需要學(xué)習(xí)不同圖像的特征并進(jìn)行組合,生成的圖像是所有被學(xué)習(xí)圖像特征的結(jié)合。常見(jiàn)的圖像生成應(yīng)用包括神經(jīng)風(fēng)格遷移、Google公司開(kāi)發(fā)的Deep Dream算法和變分自編碼器等,分別介紹如下:
3.1. Deep Dream
由Google公司在2015年夏首次發(fā)布,使用早期常見(jiàn)的Caffe架構(gòu)編寫(xiě)實(shí)現(xiàn),由于其生成的圖像布滿了算法式的迷幻錯(cuò)覺(jué)偽影而引起轟動(dòng)。DeepDeram生成圖像的顯著特征是鳥(niǎo)羽毛和狗眼睛數(shù)量較多,原因是DeepDream學(xué)習(xí)的原始圖像庫(kù)為鳥(niǎo)樣本和狗樣本特別多的ImageNet(Google開(kāi)源的大型數(shù)據(jù)庫(kù),常用作預(yù)訓(xùn)練模型的權(quán)重訓(xùn)練)。
Deep Dream與傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)可視化過(guò)程思路相同,均為對(duì)卷積神經(jīng)網(wǎng)絡(luò)的輸入進(jìn)行梯度上升,以便將靠近網(wǎng)絡(luò)輸出端的某個(gè)過(guò)濾器可視化;區(qū)別在于Deep Dream算法直接從現(xiàn)有的圖像提取特征,并且嘗試最大化激活神經(jīng)網(wǎng)絡(luò)中所有層的激活。使用Deep Dream算法,在Keras框架上對(duì)已知圖像進(jìn)行特征遷移,結(jié)果如圖13所示,Deep Dream生成的圖像相對(duì)原圖增添了許多特征(主要是鳥(niǎo)羽波紋和狗眼睛):

圖13a 原始貓圖像

圖13b Deep Dream貓圖像

圖13c 原始狗圖像

圖13d Deep Dream 狗圖像
圖13 使用Deep Dream算法生成的圖像
3.2. 神經(jīng)風(fēng)格遷移(NST,Neural Style Transfe)
神經(jīng)風(fēng)格遷移是指將參考圖像的風(fēng)格應(yīng)用于目標(biāo)圖像,同時(shí)保留目標(biāo)圖像的內(nèi)容。風(fēng)格是指圖像中不同空間尺度的紋理,顏色和視覺(jué)圖案,內(nèi)容則是指圖像的高級(jí)宏觀結(jié)構(gòu)。
實(shí)現(xiàn)神經(jīng)風(fēng)格遷移的思路與尋常深度學(xué)習(xí)方法相同,均為實(shí)現(xiàn)定義損失的最小化。不同于通常的深度學(xué)習(xí)算法,神經(jīng)風(fēng)格遷移的損失函數(shù)與圖像內(nèi)容和風(fēng)格的數(shù)學(xué)定義有關(guān),具體定義如下式所示:

式中 Loss 代表定義的參考圖像與生成圖像損失,由 Style 風(fēng)格損失和 Content 內(nèi)容損失兩部分構(gòu)成。Style 和 Content 分別定義為風(fēng)格損失函數(shù)和內(nèi)容損失函數(shù)。
內(nèi)容損失函數(shù)由神經(jīng)網(wǎng)絡(luò)中更靠近頂層的網(wǎng)絡(luò)激活 L2 范數(shù)對(duì)參考圖像和生成圖像計(jì)算差值得到,由于選取的網(wǎng)絡(luò)層更靠近輸出端,可認(rèn)為內(nèi)容損失函數(shù)得到的差值代表目的圖像和生成圖像中更加全局抽象的圖片內(nèi)容差異。
風(fēng)格損失函數(shù)的定義則使用神經(jīng)網(wǎng)絡(luò)的多個(gè)層,目的是保證風(fēng)格參考圖像和生成圖像間在神經(jīng)網(wǎng)絡(luò)中各層激活保存相似的內(nèi)部關(guān)系。不同于內(nèi)容損失函數(shù)只關(guān)注更全局、更主要的圖像內(nèi)容,風(fēng)格損失函數(shù)需要在網(wǎng)絡(luò)較高層和較低層保持類(lèi)似的相互關(guān)系,從而在根本上保證參考圖片的風(fēng)格不隨特征提取進(jìn)行而變化。
實(shí)現(xiàn)神經(jīng)風(fēng)格遷移的流程分為三個(gè)步驟:
加載預(yù)訓(xùn)練網(wǎng)絡(luò),創(chuàng)建能夠同時(shí)計(jì)算風(fēng)格參考圖像、目標(biāo)圖像和生成圖像預(yù)訓(xùn)練網(wǎng)絡(luò)激活的神經(jīng)網(wǎng)絡(luò)。
使用三張圖像上計(jì)算的對(duì)應(yīng)層激活來(lái)定義內(nèi)容損失與風(fēng)格損失,得到總體損失函數(shù)。
設(shè)置批量梯度下降,最小化目標(biāo)損失。
使用Keras內(nèi)置的VGG19預(yù)訓(xùn)練模型實(shí)現(xiàn)神經(jīng)風(fēng)格遷移,目標(biāo)是實(shí)現(xiàn)2015年提出的原始神經(jīng)風(fēng)格遷移算法,遷移結(jié)果如圖13所示:

星空原始圖像

荷池原始圖像
圖14a 實(shí)現(xiàn)神經(jīng)風(fēng)格遷移的原始圖像

繁星荷池

荷池繁星
圖14b 交換參考圖像和目標(biāo)圖像得到的遷移結(jié)果
觀察圖13可知,遷移式神經(jīng)網(wǎng)絡(luò)成功完成了風(fēng)格參考圖像到目標(biāo)圖像的風(fēng)格遷移,并且保留了目標(biāo)圖像的內(nèi)容。分別以星空和荷池作為參考對(duì)象,得到目標(biāo)圖像繁星荷池和荷池繁星。合理選取原始圖像和定義遷移參數(shù),就能生成一系列美輪美奐的圖像。
3.3 變分式自編碼器(VAE,Variational autoencoder)
變分自編碼器由Kingma和Welling在2013年12月首次提出,是一種利用深度學(xué)習(xí)中生成式模型構(gòu)建的自編碼器,特點(diǎn)是將深度學(xué)習(xí)思想和貝葉斯推斷結(jié)合在一起,以完成輸入目標(biāo)向低維向量空間的編碼映射和向高維向量空間的反解碼。經(jīng)典的圖像自編碼器首先使用編碼器模塊編碼接收的圖像,將其映射到包含圖片特征的概念向量構(gòu)成的潛在向量空間;然后通過(guò)解碼器模塊將其解碼為與目標(biāo)圖片同維度大小的輸出,經(jīng)典自編碼器的工作流程如圖15所示。
實(shí)踐中,由于經(jīng)典自編碼器不具備良好結(jié)構(gòu)的潛在學(xué)習(xí)空間而常常導(dǎo)致生成圖像不連續(xù),未達(dá)成對(duì)原始訓(xùn)練圖像特征的高效提取。變分式自編碼器在經(jīng)典自編碼器上基礎(chǔ)上改變了其編解碼方式,得到學(xué)習(xí)連續(xù)、高度結(jié)構(gòu)化的潛在空間。VAE不是將輸入圖像壓縮成潛在空間中的固定編碼,而是將圖像轉(zhuǎn)換為統(tǒng)計(jì)分布參數(shù)(平均值和方差)。然后,VAE使用這兩個(gè)參數(shù)從分布中隨機(jī)采樣一個(gè)元素并將其解碼到原始輸入。這個(gè)過(guò)程的隨機(jī)提高了其穩(wěn)健性,并迫使?jié)撛诳臻g的任何位置都對(duì)應(yīng)有意義的表示,即潛在空間采樣的每個(gè)點(diǎn)都能解碼為有效的輸出,變分自編碼器的工作流程如圖16所示。
圖像變分自編碼器與一般的深度學(xué)習(xí)模型相同,采用和輸入圖像相同類(lèi)型大小的圖片來(lái)訓(xùn)練模型,以完成對(duì)輸入圖像的特征提取和目標(biāo)圖像的自動(dòng)重構(gòu)生成。可以通過(guò)指定編碼器的輸出來(lái)限制編碼器學(xué)習(xí)的具體特征。
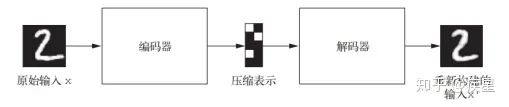
圖15 經(jīng)典自編碼器的工作流程示意圖
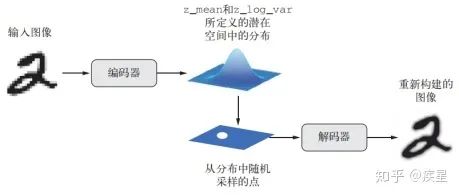
圖16 變分自編碼器的工作流程(z_mean和z_log_var分別代表潛在圖像通過(guò)編碼器映射后的均值和方差)
使用mnist數(shù)據(jù)集作為變分自編碼器訓(xùn)練數(shù)據(jù)集,生成的圖像如圖17所示:

圖17 VAE生成的手寫(xiě)數(shù)字圖像
3.4 生成式對(duì)抗網(wǎng)絡(luò)(GAN,Generative adversarial network)
GAN由Goodfello等人于 2014 年提出,它可以替代VAE來(lái)學(xué)習(xí)圖像的潛在空間,其生成的圖像與真實(shí)圖像在統(tǒng)計(jì)上幾乎無(wú)法區(qū)分,從而生成相當(dāng)逼真的合成圖像。
GAN結(jié)構(gòu)由一個(gè)偽造者網(wǎng)絡(luò)和一個(gè)專(zhuān)家網(wǎng)絡(luò)組成,二者訓(xùn)練的目的都是為了打敗彼此。生成器網(wǎng)絡(luò)(generator network)以一個(gè)隨機(jī)向量(潛在空間中的一個(gè)隨機(jī)點(diǎn))作為輸入,并將其解碼為一張合成圖像。判別器網(wǎng)絡(luò)(discriminator network)又稱(chēng)為對(duì)手網(wǎng)絡(luò)(adversary),以一張圖像(真實(shí)或合成均可)作為輸入,并預(yù)測(cè)該圖像來(lái)自訓(xùn)練集還是生成器網(wǎng)絡(luò)。訓(xùn)練生成器網(wǎng)絡(luò)的目的是使其能夠欺騙判別器網(wǎng)絡(luò),因此隨著訓(xùn)練的進(jìn)行,它能夠逐漸生成越來(lái)越逼真的圖像,即看起來(lái)與真實(shí)圖像無(wú)法區(qū)分的人造圖像,以至于判別器網(wǎng)絡(luò)無(wú)法區(qū)分二者。GAN工作流程如圖18所示:
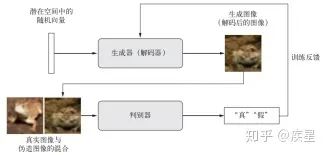
圖18 GAN網(wǎng)絡(luò)的訓(xùn)練流程示意圖
訓(xùn)練GAN和調(diào)節(jié)GAN實(shí)現(xiàn)的過(guò)程非常困難,此處不再贅述,讀者可自行查閱相關(guān)資料了解,使用GAN生成的人臉圖像如圖19所示:

圖19 GAN在人臉圖像集上訓(xùn)練生成的圖像
三.總結(jié)
本文第一部分介紹了深度學(xué)習(xí)領(lǐng)域中圖像處理的常用技巧,主要包括數(shù)據(jù)增強(qiáng)、圖像去噪以及圖像增強(qiáng)領(lǐng)域中的圖像高分辨率重建技術(shù)(SR,Super Resolution)。數(shù)據(jù)增強(qiáng)能根據(jù)原始圖像生成內(nèi)容、風(fēng)格相似的更多訓(xùn)練圖像,可有效解決因訓(xùn)練圖像不足帶來(lái)的曲線過(guò)擬合;圖像去噪技術(shù)的代表是常見(jiàn)的高斯濾波算法和去噪神經(jīng)網(wǎng)絡(luò),其共同特征是有效過(guò)濾圖片傳輸中受到的干擾波動(dòng),有利于后續(xù)的圖像處理;圖像高分辨率重建是圖像增強(qiáng)領(lǐng)域的顯著代表,其基本思想是通過(guò)提取原始低分辨率圖片的特征,變換映射得到高分辨率圖片。這種技術(shù)不僅完整保留了原始圖片的內(nèi)容和風(fēng)格(圖像的有效信息),也提升了變換后的圖片質(zhì)量。
本文第二部分簡(jiǎn)要分析深度學(xué)習(xí)技術(shù)在圖像處理領(lǐng)域的主要應(yīng)用,按照不同功能劃分為圖像變換、圖像識(shí)別和圖像生成三個(gè)領(lǐng)域。圖像變換是圖像處理最簡(jiǎn)單、基本的操作;圖像識(shí)別是計(jì)算機(jī)視覺(jué)的重要分支研究領(lǐng)域,目的是達(dá)到深度學(xué)習(xí)圖像識(shí)別網(wǎng)絡(luò)識(shí)別精度和效率的提升,實(shí)際應(yīng)用于人臉識(shí)別和遙感圖像識(shí)別等方面;最后概述了圖像生成應(yīng)用的幾個(gè)分支:包括神經(jīng)風(fēng)格遷移(NST,Neural Style Transfer)和變分自編碼器(VAE,Variational autoencode)等。Deep Dream可以看做訓(xùn)練集為Image Net的神經(jīng)風(fēng)格遷移網(wǎng)絡(luò),它們的共同特點(diǎn)是:從參考圖像中進(jìn)行內(nèi)容和風(fēng)格的提取組合后,根據(jù)要求生成不同種類(lèi)的目標(biāo)圖片。圖像生成領(lǐng)域的另一個(gè)重要分支為生成式對(duì)抗網(wǎng)絡(luò)(GAN,Generative adversarial network),可以生成與原始圖像非常相似的目標(biāo)圖像,感興趣的讀者可以自行了解。
圖像處理領(lǐng)域是深度學(xué)習(xí)和機(jī)器視覺(jué)領(lǐng)域重要的研究分支,相信在未來(lái)必將得到蓬勃的發(fā)展。本文涉及的圖像和代碼可在https://github.com/asbfighting/-.git中下載和訪問(wèn)。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101129 -
圖像處理
+關(guān)注
關(guān)注
27文章
1300瀏覽量
56874 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5512瀏覽量
121494
原文標(biāo)題:淺析深度學(xué)習(xí)在圖像處理中的應(yīng)用趨勢(shì)及常見(jiàn)技巧
文章出處:【微信號(hào):機(jī)器視覺(jué)沙龍,微信公眾號(hào):機(jī)器視覺(jué)沙龍】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU在深度學(xué)習(xí)中的應(yīng)用 GPUs在圖形設(shè)計(jì)中的作用
NPU在深度學(xué)習(xí)中的應(yīng)用
GPU深度學(xué)習(xí)應(yīng)用案例
激光雷達(dá)技術(shù)的基于深度學(xué)習(xí)的進(jìn)步
FPGA在圖像處理領(lǐng)域的優(yōu)勢(shì)有哪些?
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
圖像識(shí)別技術(shù)在醫(yī)療領(lǐng)域的應(yīng)用
利用Matlab函數(shù)實(shí)現(xiàn)深度學(xué)習(xí)算法
基于Python的深度學(xué)習(xí)人臉識(shí)別方法
深度學(xué)習(xí)中的無(wú)監(jiān)督學(xué)習(xí)方法綜述
計(jì)算機(jī)視覺(jué)在人工智能領(lǐng)域有哪些主要應(yīng)用?
深度學(xué)習(xí)在視覺(jué)檢測(cè)中的應(yīng)用
深度學(xué)習(xí)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的應(yīng)用
基于TOF深度相機(jī)的圖像處理專(zhuān)利獲授權(quán)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論