") xenomai實時性的影響因素及優(yōu)化措施
xenomai實時性的影響因素及優(yōu)化措施
作者簡介
順剛(網(wǎng)名:沐多),一線碼農(nóng),從事工控行業(yè),目前在一家工業(yè)自動化公司從事工業(yè)實時現(xiàn)場總線開發(fā)工作,喜歡鉆研Linux內(nèi)核及xenomai,個人博客 wsg1100,歡迎大家關(guān)注!
[TOC]
本文講述一些有利于提高xenomai實時性的配置建議,部分針對X86架構(gòu),但它們的底層原理相通,同樣適用于其他CPU架構(gòu)和系統(tǒng),希望對你有用。
一、前言
1. 什么是實時
“實時”一詞在許多應(yīng)用領(lǐng)域中使用,人們它有不同的解釋,并不總是正確的。人們常說,如果控制系統(tǒng)能夠?qū)ν獠渴录龀隹焖俜磻?yīng),那么它就是實時運行的。根據(jù)這種解釋,如果系統(tǒng)速度快,則系統(tǒng)被認為是實時的。然而,“快”具有相對含義,并未涵蓋表征這些類型系統(tǒng)的主要屬性。
我們來看一下,在自然界中,生物在棲息地中的實時行為,這些行為與它們的速度無關(guān)。例如,烏龜對來自其棲息地的外部刺激的反應(yīng),與貓對其棲息地的外部反應(yīng)一樣有效。雖然烏龜比貓慢很多,但就絕對速度而言,它要處理的事件與它可以協(xié)調(diào)的動作成正比,這是任何動物在環(huán)境中生存的必要條件。
相反,如果生物系統(tǒng)所處的環(huán)境,引入了速度超過其處理能力的事件,其行為將不再有效,動物的生存也會受到損害。比如,一只蒼蠅可以被蒼蠅拍捕捉到,一只老鼠可以被陷阱捕捉到,或者一只貓可以被高速行駛的汽車撞倒。在這些例子中,蒼蠅拍、陷阱和汽車代表了動物的異常和異常事件,超出了它們的實時能力范圍,可能嚴重危及它們的生存。
前面的例子表明,實時并沒有人們想象的那樣快,而是與系統(tǒng)運行的環(huán)境嚴格相關(guān)。
實時系統(tǒng)是必須在設(shè)置的截止時間內(nèi)對環(huán)境中的事件做出反應(yīng)的系統(tǒng),否則會產(chǎn)生嚴重的后果。
再比如,船舶的制導(dǎo)系統(tǒng)可能看起來是一個非實時系統(tǒng),因為它的速度很低,而且通常有“足夠”的時間(大約幾分鐘)來做出控制決定。盡管如此,根據(jù)我們的定義,它實際上是一個實時系統(tǒng)。
2. 實時分類
根據(jù)錯過截止時間產(chǎn)生的后果,實時任務(wù)可以分為三類:
硬實時(Hard real time system)
如果在截止時間之后產(chǎn)生結(jié)果,可能對受控系統(tǒng)造成災(zāi)難性后果,則該任務(wù)是硬實時任務(wù)。
硬任務(wù)的例子可以在安全關(guān)鍵系統(tǒng)中找到,并且通常與傳感、驅(qū)動和控制活動有關(guān),例如:
-
汽車安全氣囊的檢測與控制;
-
反導(dǎo)彈系統(tǒng)要求硬實時。反導(dǎo)彈系統(tǒng)由一系列硬實時任務(wù)組成。反導(dǎo)系統(tǒng)必須首先探測所有來襲導(dǎo)彈,正確定位反導(dǎo)炮,然后在導(dǎo)彈來襲之前將其摧毀。所有這些任務(wù)本質(zhì)上都是硬實時的,如果反導(dǎo)彈系統(tǒng)有任何一個任務(wù)失敗都將無法成功攔截來襲導(dǎo)彈。
強實時(Firm real time system)
如果在截止日期之后產(chǎn)生結(jié)果對系統(tǒng)無用,但不會造成任何損害,則該任務(wù)是強實時任務(wù)。
在網(wǎng)絡(luò)應(yīng)用程序和多媒體系統(tǒng)中找到,在這些系統(tǒng)中,跳過一個數(shù)據(jù)包或一個視頻幀比長時間延遲處理更重要。因此,它們包括以下內(nèi)容:
-
視頻播放;
-
音/視頻編解碼中,沒有在設(shè)置的碼率時序范圍內(nèi)執(zhí)行完,產(chǎn)生結(jié)果都是無用的丟棄即可,繼續(xù)下一輪讀取;
-
在線圖像處理;
軟實時(Soft real time system)
如果實時任務(wù)在截止日期之后產(chǎn)生結(jié)果仍然對系統(tǒng)有用,盡管會導(dǎo)致性能下降,則該任務(wù)是軟實時任務(wù)。
軟任務(wù)通常與系統(tǒng)-用戶交互有關(guān),有點延遲什么的并不影響,只是體驗稍差點。因此,它們包括:
-
用戶界面的命令解釋器;
-
處理來自鍵盤的輸入數(shù)據(jù);
-
在屏幕上顯示消息;
-
網(wǎng)頁瀏覽等;
3.常見的RTOS
小型實時操作系統(tǒng) UCOS、FreeRTOS、RT-Thread…
大型實時操作系統(tǒng) RT linux、VxWorks、QNX、sylixOS…

4. latency和jitter
硬實時系統(tǒng)是必須在設(shè)置的截止時間內(nèi)對環(huán)境中的事件做出反應(yīng)的系統(tǒng)。硬實時操作系統(tǒng)應(yīng)具備的最重要特性之一是確定性、可預(yù)期性。
操作系統(tǒng)的實時性能通常用latency或jitter來表示。事件預(yù)期發(fā)生與實際發(fā)生的時間之間的時間稱為延遲(latency),實際發(fā)生的最大時間與最小時間之間的差值稱為抖動(Jitter),兩者均可表示實時性。根據(jù)實時性的定義,延遲必須是確定的,不能超過deadline,否則將會產(chǎn)生嚴重的后果。
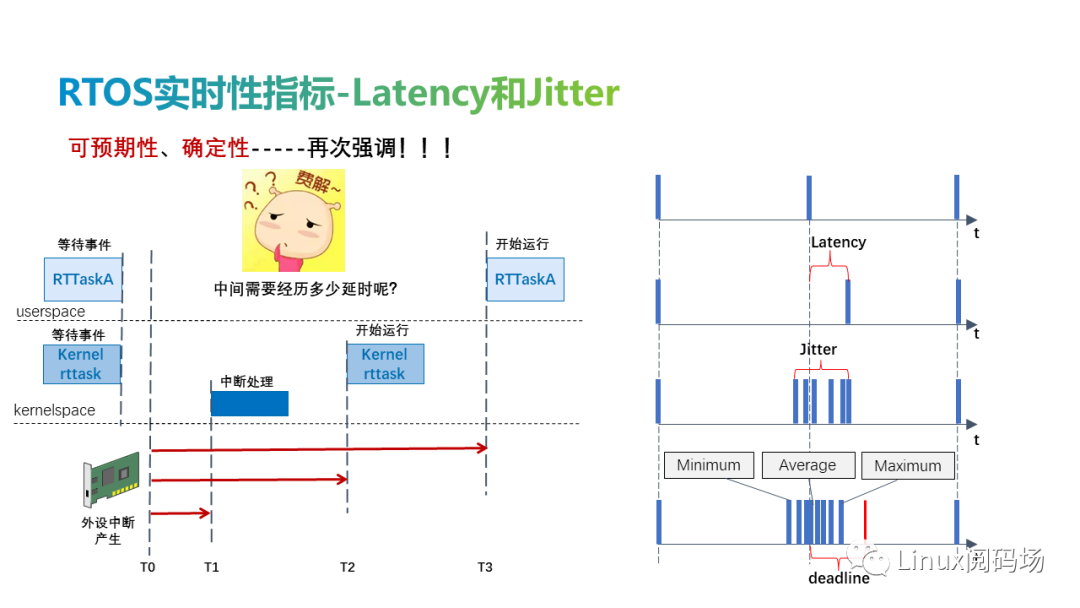
當我們針對實時應(yīng)用場景評估硬件和實時系統(tǒng)時,通常可以簡化為對實時性能和硬件資源的考量,即對于一個應(yīng)用場景,實時性滿足的情況下,硬件性能也滿足。
在否決定使用一個實時系統(tǒng)時,需要結(jié)合具體應(yīng)用場景來評估該實時系統(tǒng)是否符合,若不符合則需要考慮對現(xiàn)有系統(tǒng)優(yōu)化或者更換方案。
二、實時性的影響因素
硬實時操作系統(tǒng)應(yīng)具備的最重要特性之一是確定性、可預(yù)測性,系統(tǒng)應(yīng)該保證滿足所有關(guān)鍵時序約束。然而,這取決于一系列因素,這些因素涉及硬件的架構(gòu)特征、內(nèi)核中采用的機制和策略,以及用于實現(xiàn)應(yīng)用程序的編程語言、軟件設(shè)計等。
1.硬件
CPU架構(gòu)
硬件方面,第一個影響調(diào)度可預(yù)測性的是處理器本身。處理器的內(nèi)部特性是不確定性的第一個原因,例如指令預(yù)取、流水線操作、分支預(yù)測、高速緩存存儲器和直接存儲器訪問(DMA)機制。這些特性雖然改善了處理器的平均性能,但它們引入了非確定性因素,這些因素阻止了對最壞情況執(zhí)行時間WCET(Worst-caseExecutionTime)的精確估計。
高端CPU,如I5、I7實時性不一定有低端的賽揚、atom系列的好,芯片的設(shè)計本身定位就是高吞吐量而不是實時性。
Cache
-
CPU 里的 L1 Cache 或者 L2 Cache,訪問延時是內(nèi)存的 1/15 乃至 1/100,想要追求極限性能,需要盡可能地多從 CPU Cache 里面拿數(shù)據(jù),減少cache miss,上面的分配CPU專門對實時任務(wù)服務(wù)就是對非共享的L1 、L2 Cache的充分優(yōu)化。
-
對于L3 Cache,多個cpu核與GPU共享,無法避免非實時任務(wù)及GUI爭搶L3 Cache對實時任務(wù)的影響。
為此intel 推出了資源調(diào)配技術(shù)(Intel RDT),提供了兩種能力:監(jiān)控和分配。Intel RDT提供了一系列分配(資源控制)能力,包括緩存分配技術(shù)(Cache Allocation Technology, CAT),代碼和數(shù)據(jù)優(yōu)先級(Code and Data Prioritization, CDP) 以及 內(nèi)存帶寬分配(Memory Bandwidth Allocation, MBA)。該技術(shù)旨在通過一系列的CPU指令從而允許用戶直接對每個CPU核心(附加了HT技術(shù)后為每個邏輯核心)的L2緩存、L3緩存(LLC--Last Level Cache )以及內(nèi)存帶寬進行監(jiān)控和分配。
RDT一開始是為解決云計算的問題,在云計算領(lǐng)域虛擬化環(huán)境中,宿主機的資源(包括CPU cache和內(nèi)存帶寬)都是共享的。這帶來一個問題就是:如果有一個過度消耗cache的應(yīng)用耗盡了L3緩存或者大量的內(nèi)存帶寬,將無法保障其他虛擬機應(yīng)用的性能。這種問題稱為 noisy neighbor。
同樣對于我們的實時系統(tǒng)也是類似:由于L3 Cache多核共享,如果有一個過度消耗cache的非實時應(yīng)用耗盡了L3緩存或者大量的內(nèi)存帶寬,將無法保障xenomai實時應(yīng)用的性能。
以往虛擬化環(huán)境中解決方法是通過控制虛擬機邏輯資源(cgroup)但是調(diào)整粒度太粗,并且無法控制處理器緩存這樣敏感而且稀缺的資源。為此Intel推出了RDT技術(shù)。在Intel中文網(wǎng)站的 通過英特爾 資源調(diào)配技術(shù)優(yōu)化資源利用視頻形象介紹了RDT的作用。
Intel的Fenghua Yu在Linux Foundation上的演講 Resource Allocation in Intel Resource Director Technology 可以幫助我們快速了解這項技術(shù)。
總的來說,RDT讓我們實現(xiàn)了控制處理器緩存這樣敏感而且稀缺的資源,對我們對實時性能提升有很大幫助(不僅限于xenomai,RTAI、PREEMPT-RT均適用)。
-
CAT(緩存分配技術(shù),Cache Alocation Technology),對最后一級緩存(L3 Cache)實現(xiàn)分區(qū),用戶可以通過限制每個核心能夠向其中分配緩存行的LLC數(shù)量,將LLC的部分分配給特定核心,使用該技術(shù)可以提升實時任務(wù)Cahe命中率,減少MSI延遲和抖動,進而提升實時性能。(不是所有intel處理器具有該功能,一開始只有服務(wù)器CPU提供該支持,據(jù)筆者了解,6代以后的CPU基本支持CAT。關(guān)于CAT 見github),對于大多數(shù)Linux發(fā)行版,可直接安裝使用該工具,具體的cache分配策略可根據(jù)后面的資源隔離情況進行。
sudoapt-getinstallintel-cmt-cat
TLB
與cache性質(zhì)一致。
分支預(yù)測
現(xiàn)代 CPU 的流水線級數(shù)非常長,一般都在10級以上,指令分支判斷錯誤(Branch Mispredict)的時間代價昂貴。如果判斷預(yù)測正確,可能只需要一個時鐘周期;如果判斷錯誤,就還是需要10-20 左右個時鐘周期來重新提取指令。
如下為對同一隨機組數(shù),排序與未排序情況下for循環(huán)測試:
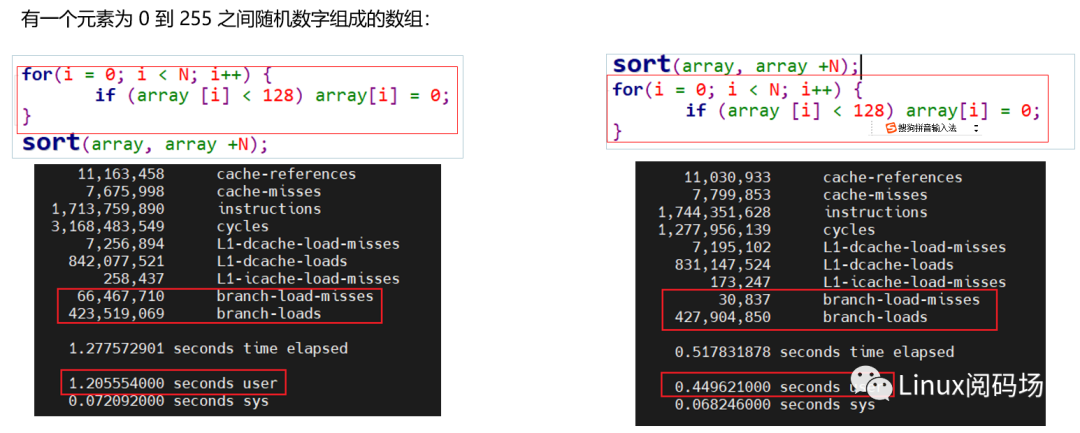
數(shù)據(jù)有規(guī)律和無規(guī)律兩種情況下同一段代碼執(zhí)行時間相差巨大。
現(xiàn)代 CPU 的分支預(yù)測正確率已經(jīng)可以在一般情況下維持在 95% 以上,所以當分支存在可預(yù)測的規(guī)律的時候,還是以性能測試的結(jié)果為最終的優(yōu)化依據(jù)。
Hyper-Threading
人們對CPU的性能的追求是無止境的,在CPU性能不斷優(yōu)化提高過程中,對于單一流水線,最佳情況下,IPC 也只能到 1。無論做了哪些流水線層面的優(yōu)化,即使做到了指令執(zhí)行層面的亂序執(zhí)行,CPU 仍然只能在一個時鐘周期里面取一條指令。
為使IPC>1,誕生了多發(fā)射(Mulitple Issue)和超標量(Superscalar)技術(shù),伴隨的是每個CPU流水線上各種運算單元的增加。但是當處理器在運行一個線程,執(zhí)行指令代碼時,一方面很多時候處理器并不會使用到全部的計算能力,另一方面由于CPU在代碼層面運行前后依賴關(guān)系的指令,會遇到各種冒險問題,這樣CPU部分計算能力就會處于空閑狀態(tài)。
為了進一步“壓榨”處理器,那就找沒有依賴關(guān)系的指令來運行好,即另一個程序。一個核可以分成幾個邏輯核,來執(zhí)行多個控制流程,這樣可以進一步提高并行程度,這一技術(shù)就叫超線程,又稱同時多線程(Simultaneous Multi-Threading,簡稱 SMT)。
由于超線程技術(shù)通過雙份的 PC 寄存器、指令寄存器、條件碼寄存器,在邏輯層面?zhèn)窝b為2個CPU,但指令譯碼器和ALU是公用的,這就造成實時任務(wù)運行時在CPU執(zhí)行層面的不確定性,造成非實時線程與實時線程在同一物理核上對CPU執(zhí)行單元的競爭,影響實時任務(wù)實時性。
電源管理與調(diào)頻
我們知道CPU場效應(yīng)晶體管FET構(gòu)成,其簡單示意圖如下。
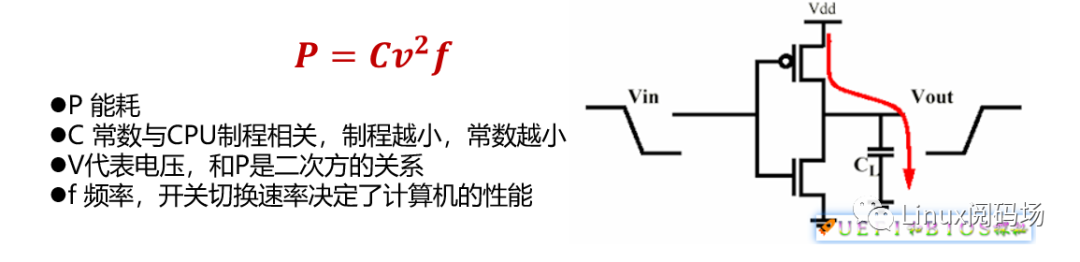
當輸入高低電平時,CL被充放電,假設(shè)充放電a焦耳的能量。因為CL很小,這個a也十分的小,幾乎可以忽略不計。為了提高CPU性能,不斷提高處理器的時鐘頻率,但如果我們以1GHz頻率翻轉(zhuǎn)這個FET,則能量消耗就是a × 10^9,這就不能忽略了,再加上CPU中有幾十億個FET,消耗的能量變得相當可觀。
詳細的參考:https://zhuanlan.zhihu.com/p/56864499
為了省電,讓操作系統(tǒng)隨著工作量不同,動態(tài)調(diào)節(jié)CPU頻率和電壓。但是調(diào)頻會導(dǎo)致CPU停頓(CPU停頓時間10us~500us不等),運行速度降低導(dǎo)致延遲增加,嚴重影響實時性能。
除了調(diào)頻以外,另一個嚴重影響實時性的是,系統(tǒng)進入更深層次的省電睡眠狀態(tài),這時的喚醒延遲長達幾十毫秒。
Multi-Core
接收 IRQ 的 CPU 可能不是響應(yīng)者休眠的 CPU,在這種情況下,前者必須向后者發(fā)送重新調(diào)度請求,以便它恢復(fù)響應(yīng)者。這通常是通過處理器間中斷完成的,也就是IPI,IPI的發(fā)送和處理進一步增加了延遲。
| 中斷周期及測試時長 | 最小 | 平均 | 最大 |
|---|---|---|---|
| 100us 21h | 0.086us | 0.184us | 4.288us |
此外,多核LLC共享,NUMA架構(gòu)遠端內(nèi)存訪問等,均會導(dǎo)致訪問延遲不確定。
other
其他影響因素有內(nèi)存、散熱。
提升內(nèi)存頻率可降低內(nèi)存訪問延時;使用雙通道內(nèi)存,這兩個內(nèi)存CPU可分別尋址、讀取數(shù)據(jù),從而使內(nèi)存的帶寬增加一倍,數(shù)據(jù)存取速度也相應(yīng)增加一倍(理論上),內(nèi)存訪問延時得到縮短,進而提升系統(tǒng)的實時性能;
處理器散熱設(shè)計不好,溫度過高時會引發(fā)CPU降頻保護,系統(tǒng)運行頻率降低影響實時性,熱設(shè)計應(yīng)確保在高工作量時的溫度不會引發(fā)降頻。
對于X86 CPU,雙通道內(nèi)存性能是單通道內(nèi)存的2. 5倍以上;正確的熱設(shè)計可使實時性提升1.4倍以上。
2.BISO(X86平臺)
BISO需要針對實時系統(tǒng)進行配置。優(yōu)化的BIOS設(shè)置與使用默認BISO設(shè)置的實時性能差距高達9倍。
3.軟件
-
資源的分配隔離:分配CPU專門對實時任務(wù)服務(wù)、將多余中斷隔離到非實時任務(wù)CPU上,分配CPU專門對實時任務(wù)服務(wù)可使L1 、L2 Cache只為實時任務(wù)服務(wù)。
-
實時任務(wù)的設(shè)計,良好的軟件設(shè)計能更好的發(fā)揮實時性能。
-
其他,虛擬化、GUI等 。
4. GPU
硬件上GPU與CPU共享L3 Cache ,因此GUI會影響實時任務(wù)的實時性。intel建議根據(jù)GUI任務(wù)的工作負載來固定GPU的運行頻率,且頻率盡可能低。減小GPU對實時任務(wù)實時性的影響。
三、優(yōu)化措施
原則:降低不確定性,提高可預(yù)期性,在此基礎(chǔ)上,再提高速度,降低延時。
比如,我們需要在確定的時間內(nèi)從廣州到深圳,如果駕車,途中會遇到多少個紅綠燈,有無堵車等等,有很多不確定性。但是如果我們換坐動車,就比駕車更具確定性,在此基礎(chǔ)上我們提高速度,換坐高鐵,廣州到深圳的延時將變得更小。
1. BIOS[x86]
| Disable Features |
Intela Hyper-Threading Technology. Intel SpeedStep. Intel Speed Shift Technology C-States: Gfx RC6. GT PM Support. PCH Cross Throttling. PCI Express* Clock Gating. Delay Enable DMI ASPM,DMI Link ASPM Control. PCle *ASPM and SATA Aggressive LPM Support. (For Skylake and Kaby Lake, also consider disabling Gfx Low Power Mode and USB Periodic SMl in BIOS.) |
| Enable Features | Legacy lO Low Latency |
| Gfx Frequency | Set to fixed value as low as possible according to proper workload |
| Memory Frequency | SA GV Fixed High |
2. 硬件
除處理器外,內(nèi)存方面,使用雙通道內(nèi)存,盡可能高的內(nèi)存頻率。
散熱當面,針對處理器工作負載設(shè)計良好的散熱結(jié)構(gòu), 否則芯片保護會強制降頻,頻率調(diào)整CPU會停頓幾十上百us。
3. Linux
xenomai基于linux,xenomai作為一個小的實時核與linux共存,xenomai并未提供完整的硬件管理機制,許多硬件配置是linux 驅(qū)動掌管的,必須讓linux配置好,給xenomai提供一個好的硬件環(huán)境,讓xenomai充分發(fā)揮其RTOS的優(yōu)勢,主要宗旨:盡可能的不讓linux非實時部分影響xenomai,無論是軟件還是硬件。
3.1 Kernel CMDLINE
cpu隔離
多核情況下,設(shè)置內(nèi)核參數(shù) isolcpus=[cpu列表],將列表中的CPU從linux內(nèi)核SMP平衡和調(diào)度算法中剔除,將剔除的CPU用于RT應(yīng)用。如4核CPU平臺將第3、4核隔離來做RT應(yīng)用。
CPU編號從"0"開始,列表的表示方法有三種:numA,numB,...,numNnumA-numN以及上述兩種表示方法的組合:numA,...,numM-numN例如:isolcpus=0,3,4-7表示隔離CPU0、3、4、5、6、7.
GRUB_CMDLINE_LINUX="isolcpus=2,3"
?
以上只是linux不會調(diào)度普通任務(wù)到CPU2和3上運行,這是基礎(chǔ),此時還需要設(shè)置xenomai方面的CPU隔離,方法一,任務(wù)通過函數(shù) pthread_attr_setaffinity_np()設(shè)置xenomai任務(wù)只在CPU3和4上調(diào)度,隔離后的CPU的L1、L2緩存命中率相應(yīng)的也會得到提高
cpu_set_t cpus;CPU_ZERO(&cpus);CPU_SET(2, &cpus);//將線程限制在指定的cpu2上運行CPU_SET(3, &cpus);//將線程限制在指定的cpu3上運行ret=pthread_attr_setaffinity_np(&tattr,sizeof(cpus),&cpus);
方法二,向xenomai設(shè)置內(nèi)核參數(shù) supported_cpus,指定xenomai支持的CPU,xenomai任務(wù)會自動放到cpu2、cpu3上運行。
xenomai 內(nèi)核參數(shù)
supported_cpus與linux不同,supported_cpus是一個16進制數(shù),每bit置位表示支持該CPU,要支持CPU2、CPU3,需要置置位bit2、bit3,即supported_cpus=0x06(00000110b)。
GRUB_CMDLINE_LINUX="isolcpus=2,3 xenomai.supported_cpus=0x06"
注:linux內(nèi)核參數(shù) isolcpus=CPU編號列表是基礎(chǔ),否則若不隔離linux任務(wù),后面的xenomai設(shè)置將沒任何意義。
Full Dynamic Tick
將CPU2、CPU3作為xenomai使用后,由于xenomai調(diào)度是完全基于優(yōu)先級的調(diào)度器,并且我們已將linux任務(wù)從這兩個cpu上剔除,CPU上Tick也就沒啥用了,避免多余的Tick中斷影響實時任務(wù)的運行,需要將這兩個cpu配置為Full Dynamic Tick模式,即關(guān)閉tick。通過添加linux內(nèi)核參數(shù) nohz_full=[cpu列表]配置。
nohz_full=[cpu列表]在使用 CONFIG_NO_HZ_FULL=y構(gòu)建的內(nèi)核中才生效。
GRUB_CMDLINE_LINUX="isolcpus=2,3xenomai.supported_cpus=0x06nohz_full=2,3"
為什么是linux內(nèi)核參數(shù)呢?雙核下時間子系統(tǒng)中分析過,每個CPU的時鐘工作方式是linux初始化并配置工作模式的,xenomai最后只是接管而已,所以這里是通過linux內(nèi)核參數(shù)配置。
注意:boot CPU(通常是0號CPU)會無條件的從列表中剔除。這是一個坑~
start_kerel()->tick_init()->tick_nohz_init()void __init tick_nohz_init(void){.......cpu = smp_processor_id();if (cpumask_test_cpu(cpu, tick_nohz_full_mask)) {pr_warn("NO_HZ: Clearing %d from nohz_full range for timekeeping ",cpu);cpumask_clear_cpu(cpu, tick_nohz_full_mask);}......}
Offload RCU callback
從引導(dǎo)選擇的CPU上卸載RCU回調(diào)處理,使用內(nèi)核線程 “rcuox / N”代替,通過linux內(nèi)核參數(shù) rcu_nocbs=[cpu列表]指定的CPU列表設(shè)置。這對于HPC和實時工作負載很有用,這樣可以減少卸載RCU的CPU上操作系統(tǒng)抖動。
"rcuox / N",N表示CPU編號,‘x’:'b'是RCU-bh的b,'p'是RCU-preempt,‘s’是RCU-sched。
rcu_nocbs=[cpu列表]在使用 CONFIG_RCU_NOCB_CPU=y構(gòu)建的內(nèi)核中才生效。除此之外需要設(shè)置RCU內(nèi)核線程 rcuc/n和 rcub/n線程的SCHEDFIFO優(yōu)先級值RCUKTHREADPRIO,RCUKTHREADPRIO設(shè)置為高于最低優(yōu)先級線程的優(yōu)先級,也就是說至少要使該優(yōu)先級低于xenomai實時應(yīng)用的優(yōu)先級,避免xenomai實時應(yīng)用遷移到linux后,由于優(yōu)先級低于RCUKTHREAD的優(yōu)先級而實時性受到影響,如下配置RCUKTHREADPRIO=0。
General setup --->RCU Subsystem --->(0) Real-time priority to use for RCU worker threads[*] Offload RCU callback processing from boot-selected CPUs(X) No build_forced no-CBs CPUs( ) CPU 0 is a build_forced no-CBs CPU( ) All CPUs are build_forced no-CBs CPUsGRUB_CMDLINE_LINUX="isolcpus=2,3 xenomai.supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3"
中斷
-
中斷隔離
xenomai用戶態(tài)實時應(yīng)用運行時,中斷優(yōu)先級最高,CPU必須響應(yīng)中斷,雖然有ipipe會簡單將非實時設(shè)備中斷掛起,但是頻繁的非實時設(shè)備中斷產(chǎn)生可能引入無限延遲,也會影響實時任務(wù)的運行。
因此多,核情況下,通過內(nèi)核參數(shù) irqaffinity==[cpu列表],設(shè)置linux設(shè)備中斷的親和性,設(shè)置后,默認由這些cpu核來處理中斷。避免了非實時linux中斷影響cpu2、cpu3上的實時應(yīng)用,將linux中斷指定到cpu0、cpu1處理,添加參數(shù):
GRUB_CMDLINE_LINUX="isolcpus=2,3xenomai.supported_cpus=0x06nohz_full=2,3rcu_nocbs=2,3irqaffinity=0,1"
以上只是設(shè)置linux中斷的affinity,只能確保運行實時任務(wù)的CPU2、cpu3不會收到linux非實時設(shè)備的中斷請求,保證實時性。
要指定cpu來處理xenomai實時設(shè)備中斷,需要在實時驅(qū)動代碼中通過函數(shù) xnintr_affinity()設(shè)置,綁定實時驅(qū)動中斷由CPU2、CPU3處理代碼如下。
cpumask_t irq_affinity;...cpumask_clear(&irq_affinity);cpumask_set_cpu(2, &irq_affinity);cpumask_set_cpu(3, &irq_affinity);...if (!cpumask_empty(&irq_affinity)){xnintr_affinity(&pIp->irq_handle,irq_affinity); /*設(shè)置實時設(shè)備中斷的affinity*/}
雖然ipipe會保證xenomai 實時中斷在任何CPU都會優(yōu)先處理,在實時設(shè)備中斷比較少的場合,我覺得把linux中斷與實時中斷分開比較好;如果實時設(shè)備中斷數(shù)量較多,如果隔離就會造成實時中斷間相互影響中斷處理的實時性,這時候不指定實時中斷處理CPU比較好。
-
編寫xenomai實時設(shè)備驅(qū)動程序時,中斷處理程序需要盡可能的短。
禁用irqbanlance
linux irqbalance 用于優(yōu)化中斷分配,它會自動收集系統(tǒng)數(shù)據(jù)以分析使用模式,并依據(jù)系統(tǒng)負載狀況將工作狀態(tài)置于 Performance mode 或 Power-save mode。簡單來說irqbalance 會將硬件中斷分配到各個CPU核心上處理。
-
處于 Performance mode 時,irqbalance 會將中斷盡可能均勻地分發(fā)給各個 CPU core,以充分利用 CPU 多核,提升性能。
-
處于 Power-save mode 時,irqbalance 會將中斷集中分配給第一個 CPU,以保證其它空閑 CPU 的睡眠時間,降低能耗。
禁用irqbanlance,避免不相干中斷發(fā)生在RT任務(wù)核。發(fā)行版不同,配置方式不同,以Ubuntu為例,停止/關(guān)閉開機啟動如下。
systemctl stop irqbalance.servicesystemctldisableirqbalance.service
必要的話直接卸載irqbalance。
apt-getremoveirqbalance
x86平臺還可添加參數(shù)acpi_irq_nobalance禁用ACPI irqbalance.
GRUB_CMDLINE_LINUX="isolcpus=2,3xenomai.supported_cpus=0x06nohz_full=2,3rcu_nocbs=2,3irqaffinity=0,1acpi_irq_nobalancenoirqbalance"
intel 核顯配置[x86]
主要針對intel CPU的核顯,配置intel核顯驅(qū)動模塊i915,內(nèi)核參數(shù)如下。
GRUB_CMDLINE_LINUX="i915.enable_rc6=0i915.enable_dc=0i915.disable_power_well=0i915.enable_execlists=0i915.powersave=0"
nmi_watchdog[x86]
NMI watchdog是Linux的開發(fā)者為了debugging而添加的特性,但也能用來檢測和恢復(fù)Linux kernel hang,現(xiàn)代多核x86體系都能支持NMI watchdog。
NMI(Non Maskable Interrupt)即不可屏蔽中斷,之所以要使用NMI,是因為NMI watchdog的監(jiān)視目標是整個內(nèi)核,而內(nèi)核可能發(fā)生在關(guān)中斷同時陷入死循環(huán)的錯誤,此時只有NMI能拯救它。
Linux中有兩種NMI watchdog,分別是I/O APIC watchdog(nmiwatchdog=1)和Local APIC watchdog(nmiwatchdog=2)。它們的觸發(fā)機制不同,但觸發(fā)NMI之后的操作是幾乎一樣的。一旦開啟了I/O APIC watchdog(nmi_watchdog=1),那么每個CPU對應(yīng)的Local APIC的LINT0線都關(guān)聯(lián)到NMI,這樣每個CPU將周期性地接到NMI,接到中斷的CPU立即處理NMI,用來悄悄監(jiān)視系統(tǒng)的運行。如果系統(tǒng)正常,它啥事都不做,僅僅是更改 一些時間計數(shù);如果系統(tǒng)不正常(默認5秒沒有任何普通外部中斷),那它就閑不住了,會立馬跳出來,且中止之前程序的運行。該出手時就出手。
避免周期中斷的NMI watchdog影響xenomai實時性需要關(guān)閉NMI watchdog,傳遞內(nèi)核參數(shù) nmi_watchdog=0.
GRUB_CMDLINE_LINUX="isolcpus=2,3xenomai.supported_cpus=0x06nohz_full=2,3rcu_nocbs=2,3irqaffinity=0,1acpi_irq_nobalancenoirqbalancei915.enable_rc6=0i915.enable_dc=0i915.disable_power_well=0i915.enable_execlists=0i915.powersave=0nmi_watchdog=0"
nosoftlockup
linux內(nèi)核參數(shù),禁用 soft-lockup檢測器。
GRUB_CMDLINE_LINUX="isolcpus=2,3xenomai.supported_cpus=0x06nohz_full=2,3rcu_nocbs=2,3irqaffinity=0,1acpi_irq_nobalancenoirqbalancei915.enable_rc6=0i915.enable_dc=0i915.disable_power_well=0i915.enable_execlists=0i915.powersave=0nmi_watchdog=0nosoftlockup"
CPU特性[x86]
intel處理器相關(guān)內(nèi)核參數(shù):
-
nosmap -
nohalt。告訴內(nèi)核在空閑時,不要使用省電功能PALHALTLIGHT。這增加了功耗。但它減少了中斷喚醒延遲,這可以提高某些環(huán)境下的性能,例如聯(lián)網(wǎng)服務(wù)器或?qū)崟r系統(tǒng)。 -
mce=ignore_ce,忽略machine checkerrors (MCE). -
idle=poll,不要使用HLT在空閑循環(huán)中進行節(jié)電,而是輪詢以重新安排事件。這將使CPU消耗更多的功率,但對于在多處理器基準測試中獲得稍微更好的性能可能很有用。它還使使用性能計數(shù)器的某些性能分析更加準確。 -
clocksource=tsc tsc=reliable,指定tsc作為系統(tǒng)clocksource. -
intel_idle.max_cstate=0禁用intelidle并回退到acpiidle. -
processor.max_cstate=0intel.max_cstate=0processor_idle.max_cstate=0限制睡眠狀態(tài)c-state。
GRUB_CMDLINE_LINUX="isolcpus=2,3 xenomai.supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3 irqaffinity=0,1 acpi_irq_nobalance noirqbalance i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0 i915.enable_execlists=0 nmi_watchdog=0 nosoftlockup processor.max_cstate=0 intel.max_cstate=0 processor_idle.max_cstate=0 intel_idle.max_cstate=0 clocksource=tsc tsc=reliable nmi_watchdog=0 nosoftlockup intel_pstate=disable idle=poll nohalt nosmap mce=ignore_ce"
3.2 內(nèi)核構(gòu)建配置
系統(tǒng)構(gòu)建時,除以上提到的配置外(CONFIGNOHZFULL = y、CONFIGRCUNOCBCPU=y、RCUKTHREADPRIO=0),其他實時性相關(guān)配置如下:
CONFIGMIGRATION=n、CONFIGMCORE2=y[x86]、CONFIGPREEMPT=y、ACPIPROCESSOR =n[x86]、CONFIGCPUFREQ =n、CONFIGCPUIDLE =n;
經(jīng)過以上配置后可以使用latency測試,觀察配置前后的變化。關(guān)于latency,需要注意的是,測試timer-IRQ的latency時,即用 latency-t2命令來測試時,xenomai默認使用cpu0的timer,上面提到boot CPU(通常是0號CPU)會無條件的從 nohz_full=[cpu列表]列表中剔除,所以 latency-t2測試時你會發(fā)現(xiàn)沒什么變化,還可能會變差了(最壞情況差不多一致,平均值變大了),另外我們將linux中斷affinity全都設(shè)置為CPU0處理,這些中斷或多或少也會影響timer-IRQ的latency。
2021.5添加-- 最近發(fā)現(xiàn)xenomai內(nèi)核定時器affinity為cpu0的問題已被社區(qū)修復(fù)。
四、軟件方面
-
使用靜態(tài)編譯語言
-
編寫高性能的代碼
-
盡量讓分支有規(guī)律性,使用likely()/unlikely()或編寫無分支代碼
-
利用cache局部性原理,防止偽共享
-
合理分配任務(wù)優(yōu)先級等待
-
驅(qū)動程序中斷處理盡可能短等等
五、優(yōu)化結(jié)果對比
筆者對以上各個條件配置前后對比過實時性改善效果,均有不同程度的優(yōu)化效果,大家有興趣也可自行測試。
1-3 在已裁剪桌面下,壓力加了內(nèi)存。
1. 原始性能測試。
只使用了xenomai,CONFIGMIGRATION=n、CONFIGMCORE2=y[x86]、CONFIGPREEMPT=y、ACPIPROCESSOR =n[x86]、CONFIGCPUFREQ =n、CONFIGCPUIDLE =n。
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | NO |
| Linux | NO |
| Full Dynamic Tick | NO |
| Offload RCU callback | NO |
| Full desktop | NO |
| stress | -c 10 -m 4 |
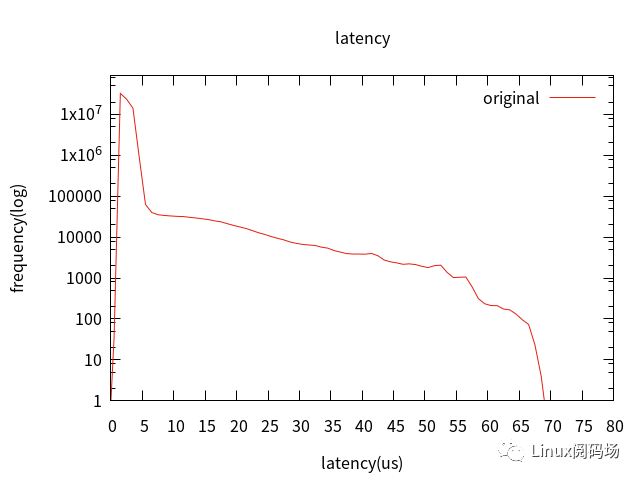
2. 優(yōu)化BIOS設(shè)置。
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | YES |
| Linux | NO |
| Full Dynamic Tick | NO |
| Offload RCU callback | NO |
| Full desktop | NO |
| stress | -c 10 -m 4 |
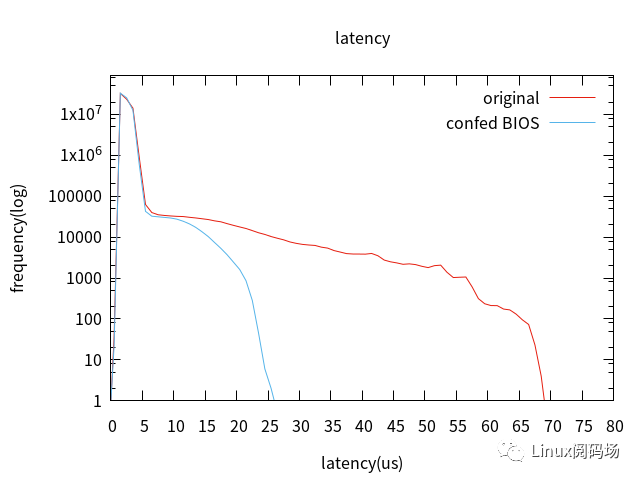
3. Linux配置優(yōu)化。
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | YES |
| Linux | YES |
| Full Dynamic Tick | YES |
| Offload RCU callback | YES |
| Full desktop | NO |
| stress | -c 10 -m 4 |
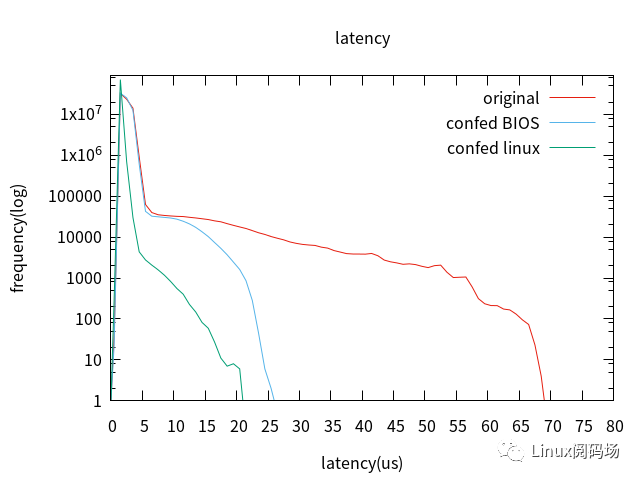
4-6 未添加內(nèi)存壓力
4. 裁剪桌面。
保留完整Ubuntu桌面前,且經(jīng)所有配置:
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | YES |
| Linux | YES |
| Full Dynamic Tick | YES |
| Offload RCU callback | YES |
| Full desktop | NO—>YES |
| stress | -c 10 |
裁剪桌面后:
裁剪前后對比:
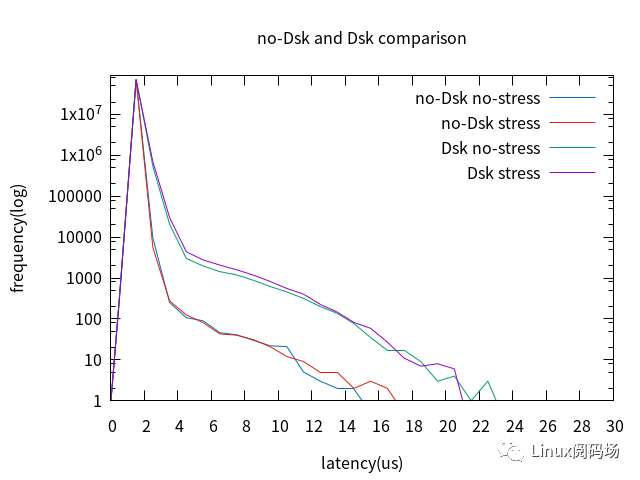
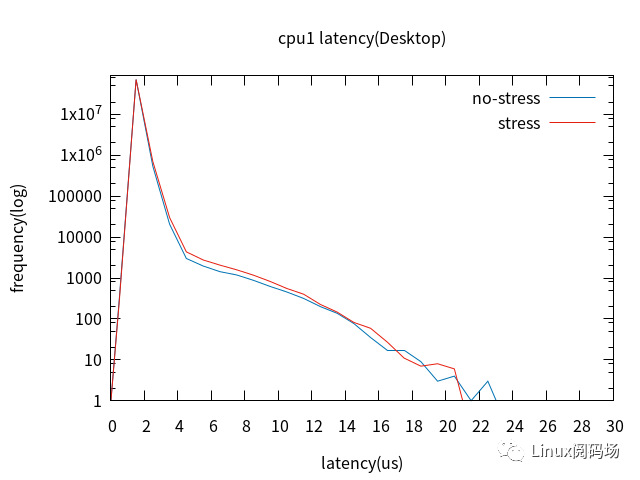
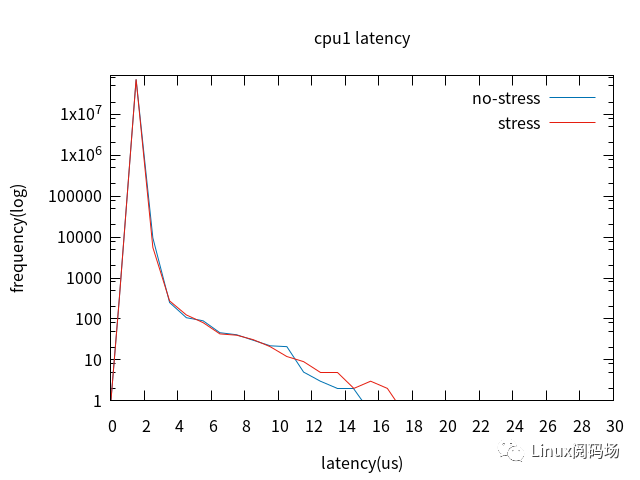
5. Full Dynamic Tick啟用前后對比
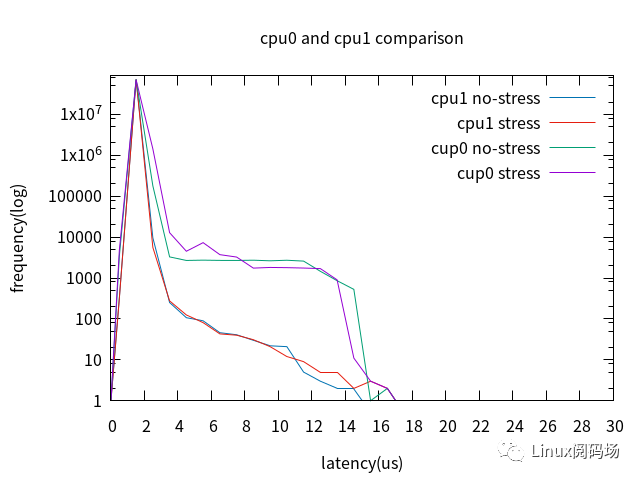
裁剪桌面后,配置cpu0未啟用Full Dynamic Tick,cpu1啟用Full Dynamic Tick,加壓與未加壓對比。
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | YES |
| Linux | YES |
| Full Dynamic Tick | CPU0:NO |
| ;CPU1:YES | |
| Offload RCU callback | CPU0==NO;CPU1: |
| NO== | |
| Full desktop | NO |
| stress | -c 10 |
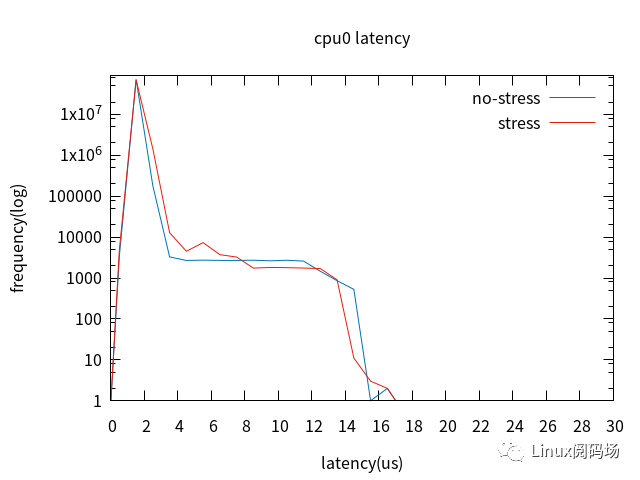
對比cpu0與cpu1,最壞情況沒有改善,但4us以上的latency改善明顯。
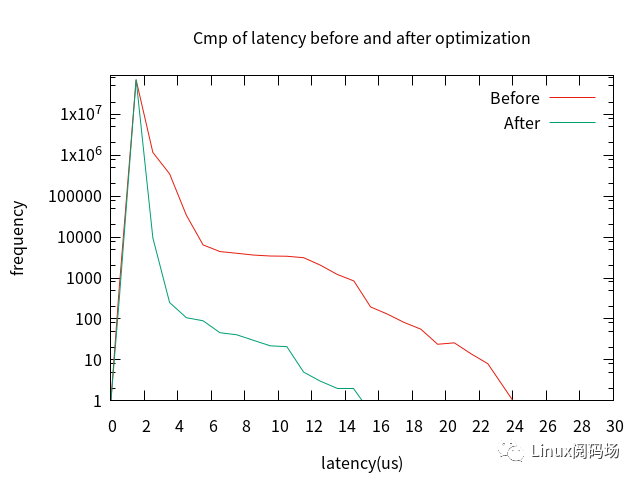
6.桌面、rcu、tick前后比對
帶桌面、未啟用rcunocb、未啟用Full Dynamic Tick-------->裁桌面、啟用rcunocb、啟用Full Dynamic Tick;
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | YES --> YES |
| Linux | YES --> YES |
| Full Dynamic Tick | NO --> YES |
| Offload RCU callback | NO-->YES |
| Full desktop | YES - >NO |
| stress | -c 10 |
7.總對比
| 優(yōu)化項 | 配置與否 |
|---|---|
| BISO | NO --> YES |
| Linux | NO --> YES |
| Full Dynamic Tick | NO --> YES |
| Offload RCU callback | NO --> YES |
| Full desktop | YES --> NO |
| stress | -c 10-m 4 |
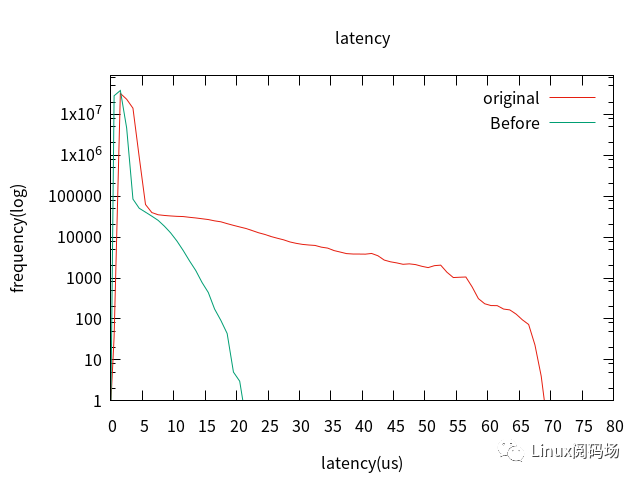
六、實時性能測試
下面直接給出最終的應(yīng)用空間任務(wù)Jitter測試結(jié)果,使用的環(huán)境如下:
| CPU | intel 賽揚 3865U@1.8GHZ |
| Kernel | Linux 4.4.200 |
| 操作系統(tǒng) | Ubuntu 16.04 |
| 內(nèi)存 | 8GB DDR3-1600 雙通道 |
| 存儲 | 64GB EMMC |
測試條件:在stress壓力下測試,同時一個QT應(yīng)用程序繪制2維曲線圖,QT CPU占用率99%。
stress-c10-m4
測試時間:21155測試命令:
latency-t0-p100-P99-h-gresult.txt
測試應(yīng)用空間程序,優(yōu)先級99,任務(wù)周期100us,測試結(jié)果輸出到文件result.txt。經(jīng)過接近10天的測試后,文件result.txt中l(wèi)atency分布結(jié)果如下:
# 21155 (periodic user-mode task, 100 us period, priority 99)# ----lat min|----lat avg|----lat max|-overrun|---msw|# 0.343| 1.078| 23.110| 0| 0|# Xenomai version: Xenomai/cobalt v3.1# Linux 4.4.200-xeno......# I-pipe releagese #20 detected# Cobalt core 3.1 detected# Compiler: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.12)# Build args: --enable-smp --enable-pshared --enable-tlsPKG_CONFIG_PATH=:/usr/xenomai/lib/pkgconfig:/usr/xenomai/lib/pkgconfig0 10.5 15993570371.5 16211301062.5 566187533.5 43869854.5 38485315.5 35567046.5 33536497.5 30332188.5 25601339.5 203507510.5 151686611.5 103898912.5 68081513.5 41712414.5 22429615.5 11516516.5 5807517.5 2766918.5 1164819.5 464820.5 164621.5 46722.5 3823.51
其中第一列數(shù)據(jù)表示latency的值,第二列表示該值與上一個值之間這個范圍的latency出現(xiàn)的次數(shù),最小0.343us,平均latency 1.078us,最大23.110us。可見xenomai的實時性還是挺不錯的。以上只是xenomai應(yīng)用空間任務(wù)的實時性表現(xiàn),如果使用內(nèi)核空間任務(wù)會更好。當然這只能說明操作系統(tǒng)能提供的實時性能,具體的還要看應(yīng)用程序的設(shè)計等。
此外,該測試基于X86平臺,X86處理器的實時性與BIOS有很大關(guān)系,通常BIOS配置CPU具有更高的吞吐量,例如超線程、電源管理、CPU頻率等,畢竟BIOS不是普通開發(fā)者能接觸到的,如果能讓BIOS對CPU針對實時系統(tǒng)配置的話,實時性會更好。如下圖所示,平均抖動幾乎在100納秒以內(nèi)。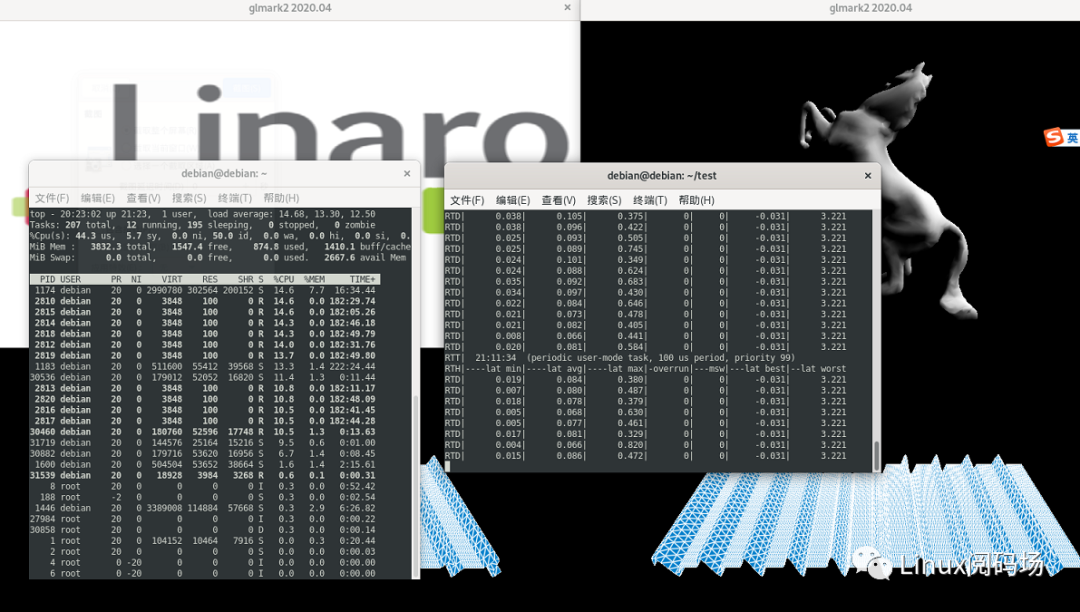
原文標題:有利于提高xenomai 實時性的一些配置建議
文章出處:【微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
Linux
+關(guān)注
關(guān)注
87文章
11322瀏覽量
209867 -
RTOS
+關(guān)注
關(guān)注
22文章
817瀏覽量
119725 -
實時性
+關(guān)注
關(guān)注
0文章
21瀏覽量
10078 -
Xenomai
+關(guān)注
關(guān)注
0文章
10瀏覽量
7988
原文標題:有利于提高xenomai 實時性的一些配置建議
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Linux + Xenomai實時操作系統(tǒng)創(chuàng)建方案
迅為RK3588開發(fā)板實時系統(tǒng)編譯-Preemption系統(tǒng)/ Xenomai系統(tǒng)編譯-獲取Linux源碼包
關(guān)于系統(tǒng)打實時補丁,以及l(fā)inux&u-boot移植方面的問題
提高MES系統(tǒng)數(shù)據(jù)采集傳輸實時性的辦法及措施
Linux實時性能的改善措施有哪些呢
Zephyr與FreeRTOS實時性測試比較
實時系統(tǒng)Preempt RT與Xenomai之爭!誰更主流,誰更實時?
為什么選擇Linux操作系統(tǒng)?制約標準Linux操作系統(tǒng)實時性的因素
xenomai組成結(jié)構(gòu)和源碼
如何區(qū)分xenomai、linux系統(tǒng)調(diào)用/服務(wù)
在實時控制系統(tǒng)中使用傳感器優(yōu)化數(shù)據(jù)可靠性的3個技巧






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論