 CUDA簡介:CUDA編程模型和接口
CUDA簡介:CUDA編程模型和接口
本項目為CUDA官方手冊的中文翻譯版,有個人翻譯并添加自己的理解。主要介紹CUDA編程模型和接口。
1.1 我們為什么要使用GPU
GPU(Graphics Processing Unit)在相同的價格和功率范圍內,比CPU提供更高的指令吞吐量和內存帶寬。許多應用程序利用這些更高的能力,在GPU上比在CPU上運行得更快(參見GPU應用程序)。其他計算設備,如FPGA,也非常節能,但提供的編程靈活性要比GPU少得多。
GPU和CPU在功能上的差異是因為它們的設計目標不同。雖然 CPU 旨在以盡可能快的速度執行一系列稱為線程的操作,并且可以并行執行數十個這樣的線程。但GPU卻能并行執行成千上萬個(攤銷較慢的單線程性能以實現更大的吞吐量)。
GPU 專門用于高度并行計算,因此設計時更多的晶體管用于數據處理,而不是數據緩存和流量控制。
下圖顯示了 CPU 與 GPU 的芯片資源分布示例。
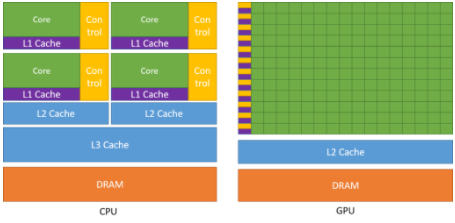
將更多晶體管用于數據處理,例如浮點計算,有利于高度并行計算。GPU可以通過計算隱藏內存訪問延遲,而不是依靠大數據緩存和復雜的流控制來避免長時間的內存訪問延遲,這兩者在晶體管方面都是昂貴的。
1.2 CUDA?:通用并行計算平臺和編程模型
2006 年 11 月,NVIDIA? 推出了 CUDA?,這是一種通用并行計算平臺和編程模型,它利用 NVIDIA GPU 中的并行計算引擎以比 CPU 更有效的方式解決許多復雜的計算問題。
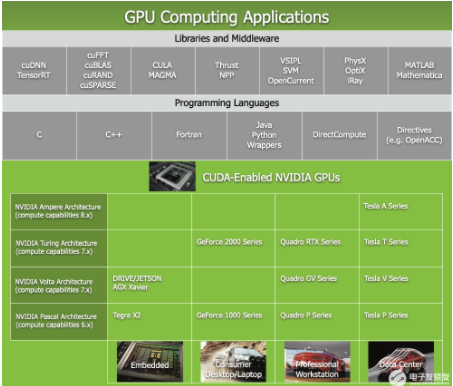
CUDA 附帶一個軟件環境,允許開發人員使用 C++ 作為高級編程語言。 如下圖所示,支持其他語言、應用程序編程接口或基于指令的方法,例如 FORTRAN、DirectCompute、OpenACC。
1.3 可擴展的編程模型
多核 CPU 和眾核 GPU 的出現意味著主流處理器芯片現在是并行系統。挑戰在于開發能夠透明地擴展可并行的應用軟件,來利用不斷增加的處理器內核數量。就像 3D 圖形應用程序透明地將其并行性擴展到具有廣泛不同內核數量的多核 GPU 一樣。
CUDA 并行編程模型旨在克服這一挑戰,同時為熟悉 C 等標準編程語言的程序員保持較低的學習曲線。
其核心是三個關鍵抽象——線程組的層次結構、共享內存和屏障同步——它們只是作為最小的語言擴展集向程序員公開。
這些抽象提供了細粒度的數據并行和線程并行,嵌套在粗粒度的數據并行和任務并行中。它們指導程序員將問題劃分為可以由線程塊并行獨立解決的粗略子問題,并將每個子問題劃分為可以由塊內所有線程并行協作解決的更精細的部分。
這種分解通過允許線程在解決每個子問題時進行協作來保留語言表達能力,同時實現自動可擴展性。實際上,每個線程塊都可以在 GPU 內的任何可用multiprocessor上以亂序、并發或順序調度,以便編譯的 CUDA 程序可以在任意數量的多處理器上執行,如下圖所示,并且只有運行時系統需要知道物理multiprocessor個數。
這種可擴展的編程模型允許 GPU 架構通過簡單地擴展multiprocessor和內存分區的數量來跨越廣泛的市場范圍:高性能發燒友 GeForce GPU ,專業的 Quadro 和 Tesla 計算產品 (有關所有支持 CUDA 的 GPU 的列表,請參閱支持 CUDA 的 GPU)。
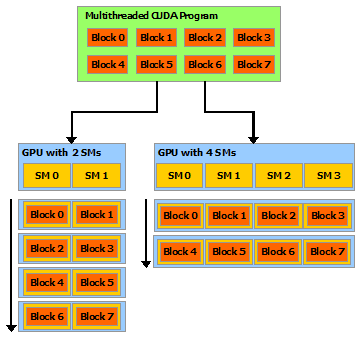
注意:GPU 是圍繞一系列流式多處理器 (SM: Streaming Multiprocessors) 構建的(有關詳細信息,請參閱硬件實現)。 多線程程序被劃分為彼此獨立執行的線程塊,因此具有更多multiprocessor的 GPU 將比具有更少多處理器的 GPU 在更短的時間內完成程序執行。
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5039瀏覽量
103309 -
gpu
+關注
關注
28文章
4754瀏覽量
129100 -
人工智能
+關注
關注
1792文章
47458瀏覽量
239083
發布評論請先 登錄
相關推薦
FacenetPytorch人臉識別方案--基于米爾全志T527開發板
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
怎么在TMDSEVM6678: 6678自帶的FFT接口和CUDA提供CUFFT函數庫選擇?
打破英偉達CUDA壁壘?AMD顯卡現在也能無縫適配CUDA了
英國公司實現英偉達CUDA軟件在AMD GPU上的無縫運行
軟件生態上超越CUDA,究竟有多難?
借助NVIDIA Aerial CUDA增強5G/6G的DU性能和工作負載整合
英偉達CUDA-Q平臺推動全球量子計算研究
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

Keil使用AC6編譯提示CUDA版本過高怎么解決?
英偉達AI霸主地位遭巨頭聯手挑戰,CUDA壟斷遭破局
摩爾線程MUSA/MUSIFY與英偉達CUDA無依賴,開發者無憂
GPU CUDA 編程的基本原理是什么





 工商網監
工商網監
評論