 智能邊緣解決方案面臨的挑戰和解決方案
智能邊緣解決方案面臨的挑戰和解決方案
無論您的組織是數據科學新手還是有成熟的戰略,許多人都有類似的認識:大多數數據并非源自核心。
科學家通常希望訪問大量的數據,而這些數據對于安全地實時傳輸到數據中心來說是不合理的。無論距離是 10 英里還是數千英里,傳統 IT 基礎設施的邊界根本就不是為了延伸到固定校園之外而設計的。
這使組織認識到,沒有邊緣戰略,任何數據科學戰略都是不完整的。
繼續閱讀以了解業界對耦合數據科學和邊緣計算的好處、面臨的挑戰、這些挑戰的解決方案的見解,并注冊以查看邊緣體系結構藍圖的演示。
邊緣架構
Edge computing 是一種 IT 體系結構,通常用于創建能夠容忍地理分布數據源和高延遲低帶寬互連的系統。
由于操作環境的限制,以這種方式設計的計算系統通常可以通過犧牲計算速度和高可用性來識別。
如今,組織通常使用三種邊緣體系結構:
流數據
邊緣預處理
自治系統
流數據
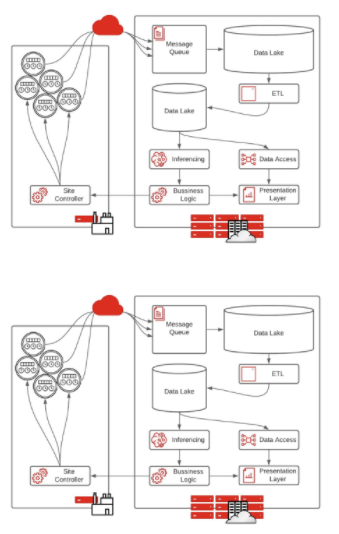
圖 1 。流式數據體系結構在邊緣收集數據并在云中進行處理
如今,流式數據,即經典的“大數據”體系結構,是剛剛開始實施邊緣戰略的組織最流行的原型體系結構。這種架構從物聯網設備開始,通常是傳感器,放置在工廠、醫院或零售店的任何位置。然后,數據通過云發送到 IT 系統。
隨著數據處理能力的提高,這種體系結構可能會成為一種障礙,因為需要的基礎設施水平以及需要從邊緣移動到核心的大量數據。
邊緣預處理
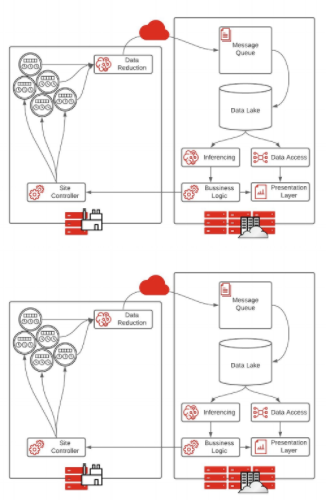
圖 2 。邊緣預處理模型是邊緣和云的混合模型
邊緣預處理模型是向邊緣過渡的組織最常見的體系結構。
傳感器數據不是直接輸入數據中心運行的管道,而是輸入智能數據簡化應用程序。這通常是一種智能機器學習算法,它決定哪些數據是重要的,哪些數據必須發送回數據中心。
提取、轉換和加載( ETL )過程在該體系結構中不太重要,因為數據縮減已經在邊緣發生。因此,不需要兩個數據湖,推理可以更快地進行。結果是更快地執行業務邏輯。
這是創建完全自治系統的良好墊腳石,允許無限量的數據壓縮。
自治系統
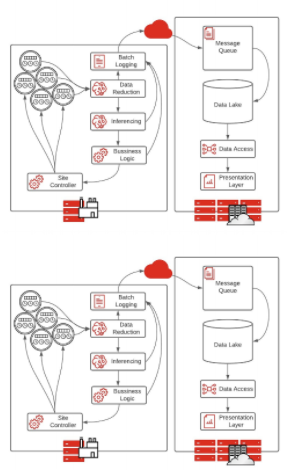
圖 3 。自治系統在邊緣處理數據,具有快速決策的特點
完全自治系統的特點是傳感器在邊緣收集數據,以低延遲快速做出決策。由于沒有時間將數據發送回數據中心或云以做出正確的決策,處理在邊緣進行,并自動采取行動。
使用此體系結構,管道的每一步都被發送到日志機制,以記錄在邊緣做出的決策。批記錄將消息發送到云或核心數據中心,以便對所做的決策進行分析和系統調整。
構建智能邊緣的行業見解
構建智能邊緣解決方案不僅僅是將一個容器推送到數十或數千個站點。雖然這似乎是一項微不足道的任務,但您的組織的成功在很大程度上取決于您所建立的基礎設施,而不僅僅是數據科學。
構建智能邊緣解決方案 運行時需要考慮許多復雜性,例如規模、互操作性和一致性。
構建智能解決方案的建議技術包括:
Linux 邊緣系統
容器
Kubernetes
消息傳遞協議( Kafka 、 MQTT 、 BYO )
實踐中的邊緣基礎設施
當組織希望滿足其業務需求并使數據科學能夠推動創新時,您的選擇不應局限于您的體系結構。實施邊緣體系結構可以幫助您針對新的用例和技術對平臺進行未來驗證。
雖然了解您的體系結構在 edge 實現的不同階段中所處的位置很有幫助,但通常最好是查看現場演示。
關于作者
Tiffany Yeung 是 NVIDIA Edge 和企業計算解決方案的產品營銷經理。 Tiffany 專注于利用 NVIDIA 邊緣解決方案使醫院、商店、倉庫、工廠等實現創新。在 NVIDIA 之前, Tiffany 的背景是創業,她曾為許多財富 500 強公司提供咨詢。
審核編輯:郭婷
-
傳感器
+關注
關注
2552文章
51383瀏覽量
756323 -
NVIDIA
+關注
關注
14文章
5075瀏覽量
103656 -
數據中心
+關注
關注
16文章
4855瀏覽量
72363
發布評論請先 登錄
相關推薦

7納米工藝面臨的各種挑戰與解決方案

大算力芯片面臨的技術挑戰和解決策略
芯片和先進封裝的制程挑戰和解決方案





 工商網監
工商網監
評論